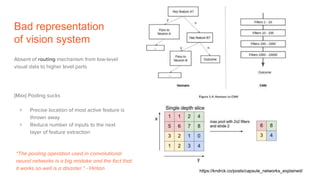
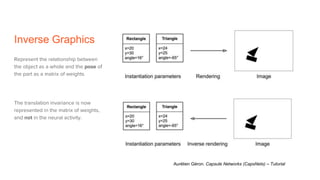
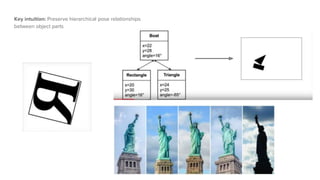
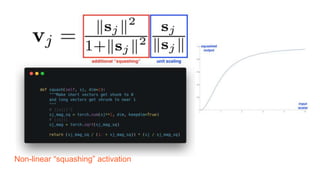
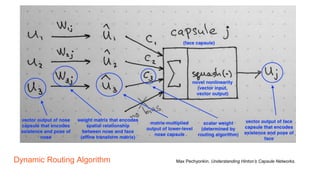
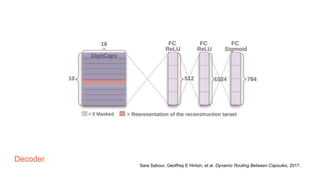
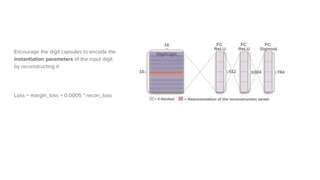
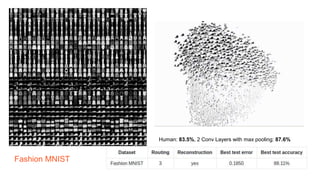
Capsule networks aim to address limitations of CNNs like lack of spatial awareness and equivariance. Capsule networks represent objects as capsules that encode the probability and instantiation parameters of an entity. They use a routing mechanism between capsule layers to determine which higher level capsules an input should be routed to based on agreement. This preserves hierarchical relationships between objects and parts. Capsule networks have shown promise for tasks like segmentation and detection by encoding pose and position but training is slower and performance has only matched CNNs on MNIST, with work still needed on other datasets.


























![[PR12] Capsule Networks - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12capsulenetworks-jaejunyoo-171217144319-thumbnail.jpg?width=640&height=640&fit=bounds)




































