

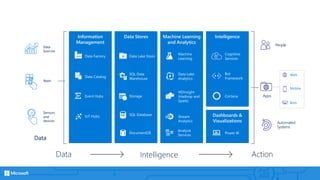


















![Types of user-defined operators
User defined
operators
Outputters [~ Writer of non standard data]
Processors [~Transform / Derrive]
Appliers [~ Table valued function]
Reducers [~ Selfdefined Agg. on Rows]
Combiners [~ Selfdefined Join]
Extractors [~ Reader of non standard data]](https://image.slidesharecdn.com/adla-170628155933/85/C-SQL-Big-Data-27-320.jpg)








This document provides an overview of Azure Data Lake Analytics (ADLA) and its capabilities. It describes the key components of ADLA including U-SQL for querying data, job execution, custom extractors and operators, external data sources, and job diagnostics. The document also includes examples of creating credentials and data sources for querying external databases, implementing a custom extractor, and job execution details.



















































































