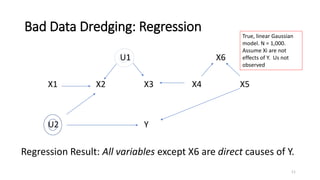
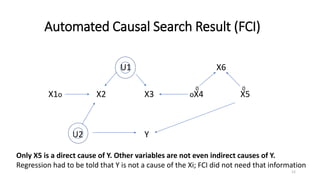
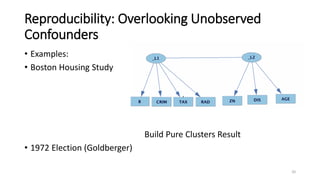
The document discusses the concept of data dredging, emphasizing the distinction between good and bad practices in hypothesis generation and evaluation within empirical studies in social and behavioral sciences. It argues that good data dredging, characterized by serious testing and a rigorous approach, has historically contributed to significant scientific discoveries, highlighting the need for comprehensive methods to account for numerous possible causal relations. The author critiques common statistical methods for their limitations and advocates for improved causal search techniques that more effectively identify relationships among variables.