
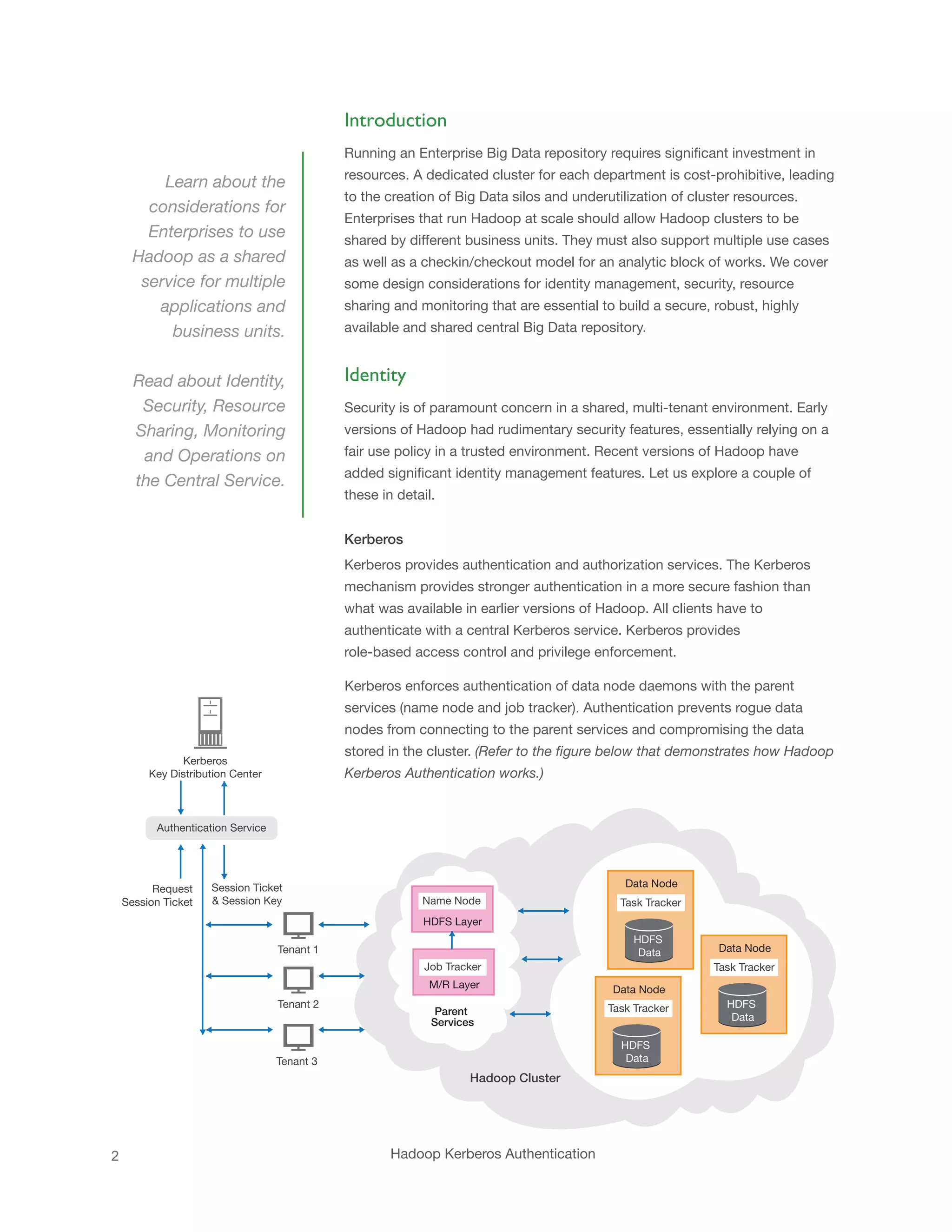




This white paper discusses the design considerations for enterprises to use Hadoop as a shared service for multiple departments, emphasizing the need for identity management, security, resource sharing, and monitoring. It highlights the benefits of using tools like Kerberos for authentication and the capacity scheduler for optimal resource management in a multi-tenant environment. The document outlines the importance of operational excellence and proactive service to successfully manage shared Hadoop clusters.















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







