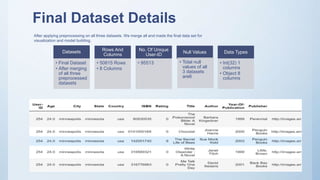
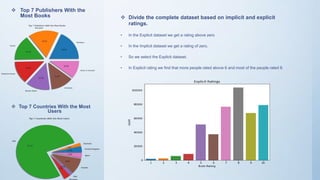
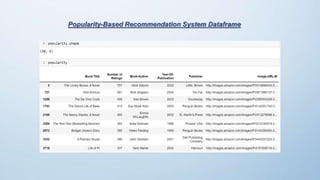
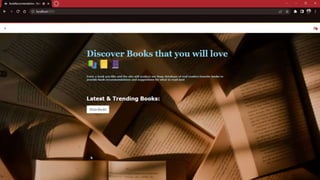
The document outlines the development of a book recommendation system, detailing its architecture, dataset details, data preprocessing, visualization techniques, and different recommendation methods such as popularity-based, content-based, and collaborative filtering. It describes the datasets used, preprocessing steps taken to clean the data, and the visualization methods for analyzing it. The document also discusses the challenges faced during the project and the deployment of the application using Streamlit.









































![Presentation 2 (1)[1].pptx project pptx](https://cdn.slidesharecdn.com/ss_thumbnails/presentation211-250923084931-9f144da3-thumbnail.jpg?width=640&height=640&fit=bounds)





























