STUDENT NAME :BOOPATHI K
REGISTER NUMBER : 422323106004
INSTITUTION : TCET - VANDAVASI
DEPARTMENT : ECE – II ND YEAR
DATE OF SUBMISSION : 09-05-2025
GITHUB REPOSITORY LINK:
• Aim: Tobuild a movie recommendation system based on
‘Kaggle’ dataset using machine learning.
We wish to integrate the aspects of personalization of user with the overallfeatures
of movie such as genre, popularity etc.
The goal of the project is to recommend a movie to the user on the basis of rating,
genre using cosine similarity
Providing related content out of relevant and irrelevant collection of items to users of
online service providers.
PROBLEM STATEMENT
4.
The goal ofour project is to develop a movie recommendation system for binge
watchers to help and recommend them good quality of movies.
The ObjectivesAre :
❖ Improving theAccuracy of the recommendation system
❖ Improve the Quality of the movie Recommendation system
❖ Improving the Scalability.
❖ Enhancing the user experience.
PROJECT OBJECTIVES
5.
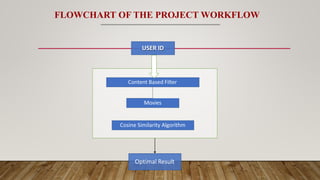
USER ID
Content BasedFilter
Movies
Cosine Similarity Algorithm
Optimal Result
FLOWCHART OF THE PROJECT WORKFLOW
6.
Hardware Requirements
• APC with Windows/Linux OS
• Processor with 1.7-2.4gHz speed
• Minimum of 8gb RAM
• 2gb Graphic card
Software Requirements
• Text Editor (VS-code)
• Streamlit
• Dataset
• Jupyter(Editor)
• Python libraries
DATA DESCRIPTION
7.
DATA PREPROCESSING
• Arecommendation system or recommendation engine is a model used for
information filtering where it tries to predict the preferences of a user and
provide suggests based on these preferences.
• Movie Recommendation Systems helps us to search our preferred movies
among all of these different types of movies and hence reduce the trouble of
spending a lot of time searching our favourable movies.
• Recommendation systems have several benefits, the most important being
customer satisfaction and revenue.
8.
EXPLORATORY DATA
ANALYSIS (EDA)
ExploratoryData Analysis (EDA) is a crucial step in data
analysis, focusing on understanding data patterns, trends, and
relationships. Tools like Python libraries (Pandas, NumPy,
Matplotlib, Seaborn, Plotly), R, and data visualization
platforms (Tableau, Power BI) are commonly used for
EDA. These tools help in tasks like data cleaning.
9.
• Provides relevantcontent to user.
• It saves time and money.
• It increases customer engagement.
• Specially designed for binge watchers
FEATURE ENGINEERING
10.
#to read csvfile
#to print all details of 10 movies
#to calculate statiscal data like count, mean,std,
#to print all columns and nonull and data types
#returns the number of missing values in the dataset
import pandas as pd
movies = pd.read_csv('dataset.csv’)
movies.head(10)
movies.describe()
movies.info()
movies.isnull().sum()
movies.columns
#it will combine the genre and overview column
movies=movies[['id', 'title', 'overview', 'genre']]
movies
movies['tags'] = movies['overview']+movies['genre’]
movies
new_data = movies.drop(columns=['overview', 'genre'])
new_data
MODEL BUILDING
11.
from sklearn.feature_extraction.text importCountVectorizer #method to convert text to numerical data.
cv=CountVectorizer(max_features=10000, stop_words='english')
cv
vector=cv.fit_transform(new_data['tags'].values.astype('U')).toarray()
vector.shape
from sklearn.metrics.pairwise import cosine_similarity
similarity=cosine_similarity(vector)
similarity
new_data[new_data['title']=="The Godfather"].index[0]
distance = sorted(list(enumerate(similarity[2])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]:
print(new_data.iloc[i[0]].title)
12.
def recommend(movies):
index=new_data[new_data['title']==movies].index[0]
distance =sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]: #to print only top 5 movies
print(new_data.iloc[i[0]].title)
import pickle
pickle.dump(new_data, open('movies_list.pkl', 'wb'))
pickle.dump(similarity, open('similarity.pkl', 'wb'))
pickle.load(open('movies_list.pkl', 'rb'))
import streamlit.components.v1 ascomponents
imageCarouselComponent = components.declare_component("image-carousel-
component", path="frontend/public")
#imageCarouselComponent(imageUrls=imageUrls, height=200)
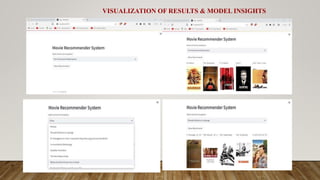
selectvalue=st.selectbox("Select movie from dropdown", movies_list)
def recommend(movie):
index=movies[movies['title']==movie].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True,
key=lambda vector:vector[1])
recommend_movie=[]
recommend_poster=[]
for i in distance[1:6]:
movies_id=movies.iloc[i[0]].id
recommend_movie.append(movies.iloc[i[0]].title)
recommend_poster.append(fetch_poster(movies_id))
return recommend_movie, recommend_poster
if st.button("Show Recommend"):
movie_name, movie_poster = recommend(selectvalue)
col1,col2,col3,col4,col5=st.columns(5)
with col1:
st.text(movie_name[0])
st.image(movie_poster[0])
with col2:
st.text(movie_name[1])
st.image(movie_poster[1])
with col3:
st.text(movie_name[2])
st.image(movie_poster[2])
with col4:
st.text(movie_name[3])
st.image(movie_poster[3])
with col5:
st.text(movie_name[4])
st.image(movie_poster[4])
16.
To build recommendationsystem there are many approach that can be used to build good
recommendation system
Content based recommendation system and collaborative filtering.
Youtube also used content based recommended system, we also used content based recommendation
system in our project and cosine similarity algorithm.
Cosine Similarity
Cosine similarity is used as a metric in different machine learning algorithms like the KNN for
determining the distance between the neighbors, in recommendation systems, it is used to recommend
movies with the same similarities and for textual data, it is used to find the similarity of texts in the
document.
For webhosting we use Streamlit
Streamlit is a promising open-source Python library, which enables developers to build attractive user
interfaces in no time. Streamlit is the easiest way especially for people with no front-end knowledge to put
their code into a web application: No front-end (html, js, css) experience or knowledge is required
TOOLS AND TECHNOLOGIES USED
17.
TEAMS MEMBERS ANDCONTRIBUTIONS
• BOOPATHI K : PROBLEM STATEMENT & OBJECTIVE , FLOWCHART OFTHE
• PROJECT FLOWCHART , DATA CLEANING
• SRIRAGAVI J : DATA DESCRIPTION & PREPROCESSING , EDA
• VENNILAVAN K : MODEL BUILDING &VISUALIZATION & MODEL INSIGHTS
• TOOLS AND TECHNOLOGIES USED








![#to read csv file
#to print all details of 10 movies
#to calculate statiscal data like count, mean,std,
#to print all columns and nonull and data types
#returns the number of missing values in the dataset
import pandas as pd
movies = pd.read_csv('dataset.csv’)
movies.head(10)
movies.describe()
movies.info()
movies.isnull().sum()
movies.columns
#it will combine the genre and overview column
movies=movies[['id', 'title', 'overview', 'genre']]
movies
movies['tags'] = movies['overview']+movies['genre’]
movies
new_data = movies.drop(columns=['overview', 'genre'])
new_data
MODEL BUILDING](https://image.slidesharecdn.com/boopathik-250511033418-eacdb612/85/Personalised-movie-recommendations-USING-10-320.jpg)
![from sklearn.feature_extraction.text import CountVectorizer #method to convert text to numerical data.
cv=CountVectorizer(max_features=10000, stop_words='english')
cv
vector=cv.fit_transform(new_data['tags'].values.astype('U')).toarray()
vector.shape
from sklearn.metrics.pairwise import cosine_similarity
similarity=cosine_similarity(vector)
similarity
new_data[new_data['title']=="The Godfather"].index[0]
distance = sorted(list(enumerate(similarity[2])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]:
print(new_data.iloc[i[0]].title)](https://image.slidesharecdn.com/boopathik-250511033418-eacdb612/85/Personalised-movie-recommendations-USING-11-320.jpg)
![def recommend(movies):
index=new_data[new_data['title']==movies].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True, key=lambda vector:vector[1])
for i in distance[0:5]: #to print only top 5 movies
print(new_data.iloc[i[0]].title)
import pickle
pickle.dump(new_data, open('movies_list.pkl', 'wb'))
pickle.dump(similarity, open('similarity.pkl', 'wb'))
pickle.load(open('movies_list.pkl', 'rb'))](https://image.slidesharecdn.com/boopathik-250511033418-eacdb612/85/Personalised-movie-recommendations-USING-12-320.jpg)
![import streamlit as st
import pickle
import requests
def fetch_poster(movie_id):
url = "https://api.themoviedb.org/3/movie/{}?api_key=43c2c7148a22f65595a5dcc10a9d6c8b".format(movie_id)
data=requests.get(url)
data=data.json()
poster_path = data['poster_path']
full_path = "https://image.tmdb.org/t/p/w500/"+poster_path
return full_path
movies = pickle.load(open("movies_list.pkl", 'rb'))
similarity = pickle.load(open("similarity.pkl", 'rb'))
movies_list=movies['title'].values
st.header("Movie Recommender System")](https://image.slidesharecdn.com/boopathik-250511033418-eacdb612/85/Personalised-movie-recommendations-USING-13-320.jpg)
![import streamlit.components.v1 as components
imageCarouselComponent = components.declare_component("image-carousel-
component", path="frontend/public")
#imageCarouselComponent(imageUrls=imageUrls, height=200)
selectvalue=st.selectbox("Select movie from dropdown", movies_list)
def recommend(movie):
index=movies[movies['title']==movie].index[0]
distance = sorted(list(enumerate(similarity[index])), reverse=True,
key=lambda vector:vector[1])
recommend_movie=[]
recommend_poster=[]
for i in distance[1:6]:
movies_id=movies.iloc[i[0]].id
recommend_movie.append(movies.iloc[i[0]].title)
recommend_poster.append(fetch_poster(movies_id))
return recommend_movie, recommend_poster
if st.button("Show Recommend"):
movie_name, movie_poster = recommend(selectvalue)
col1,col2,col3,col4,col5=st.columns(5)
with col1:
st.text(movie_name[0])
st.image(movie_poster[0])
with col2:
st.text(movie_name[1])
st.image(movie_poster[1])
with col3:
st.text(movie_name[2])
st.image(movie_poster[2])
with col4:
st.text(movie_name[3])
st.image(movie_poster[3])
with col5:
st.text(movie_name[4])
st.image(movie_poster[4])](https://image.slidesharecdn.com/boopathik-250511033418-eacdb612/85/Personalised-movie-recommendations-USING-15-320.jpg)








































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)















