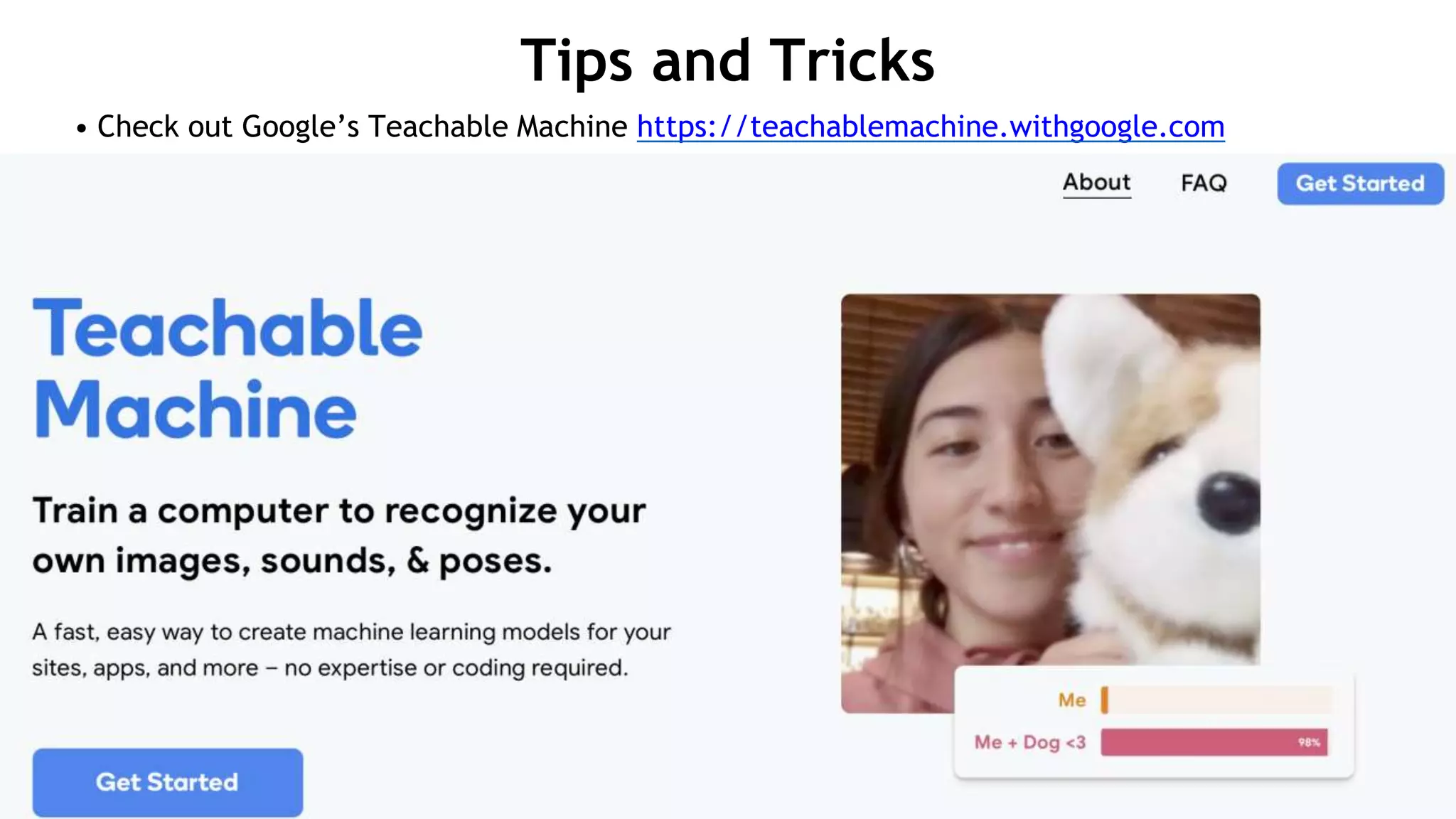
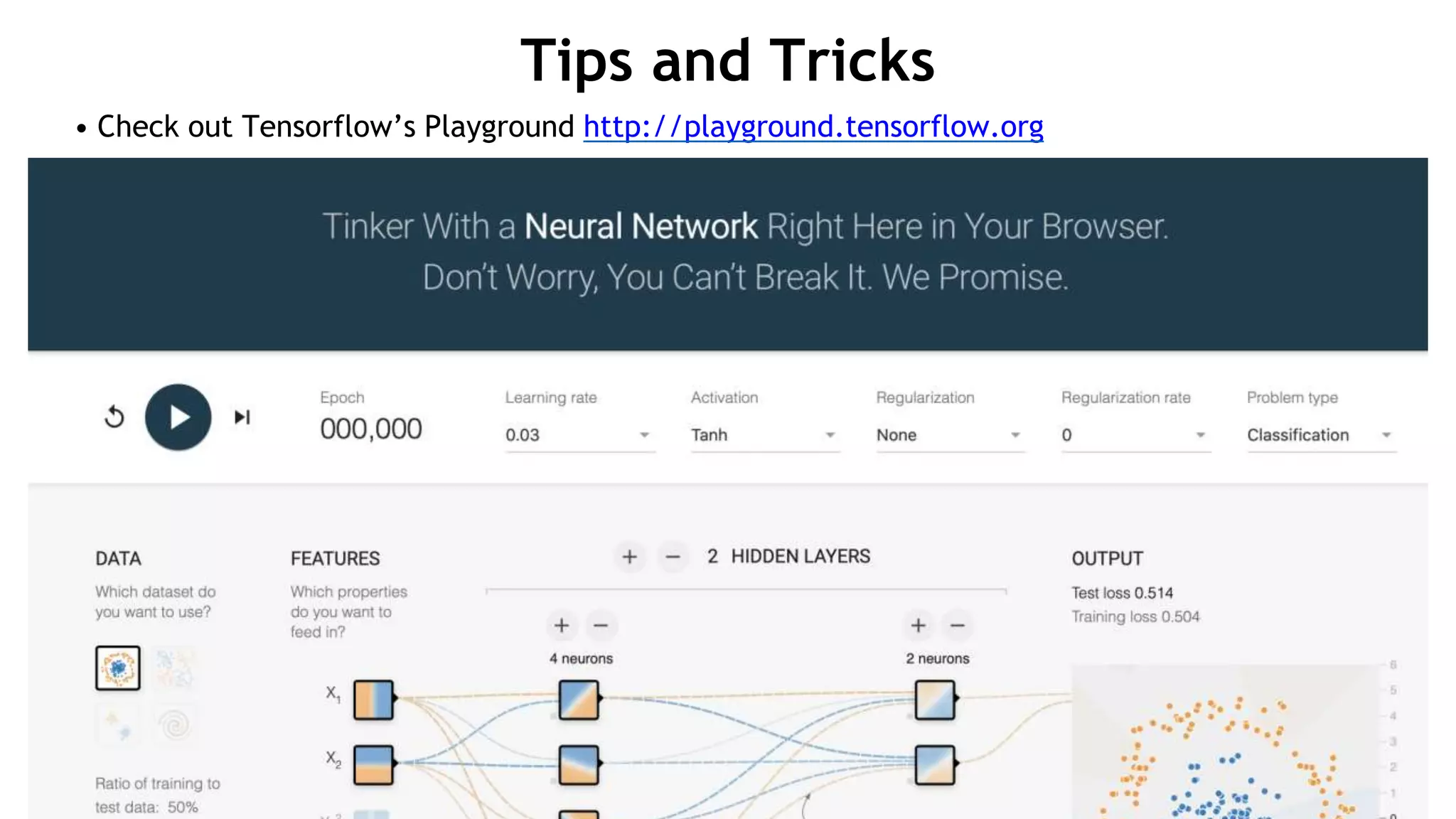
Download to read offline









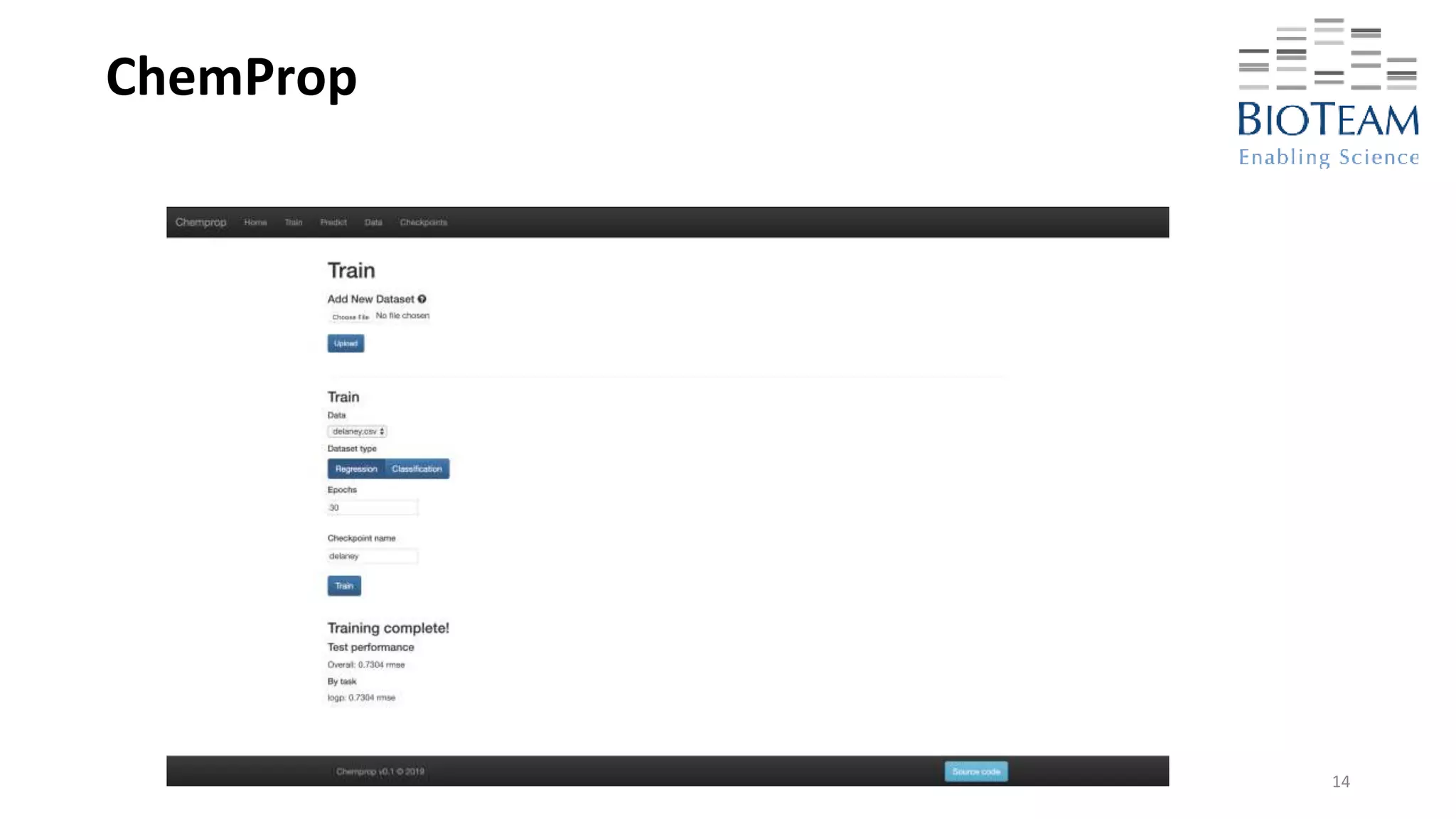
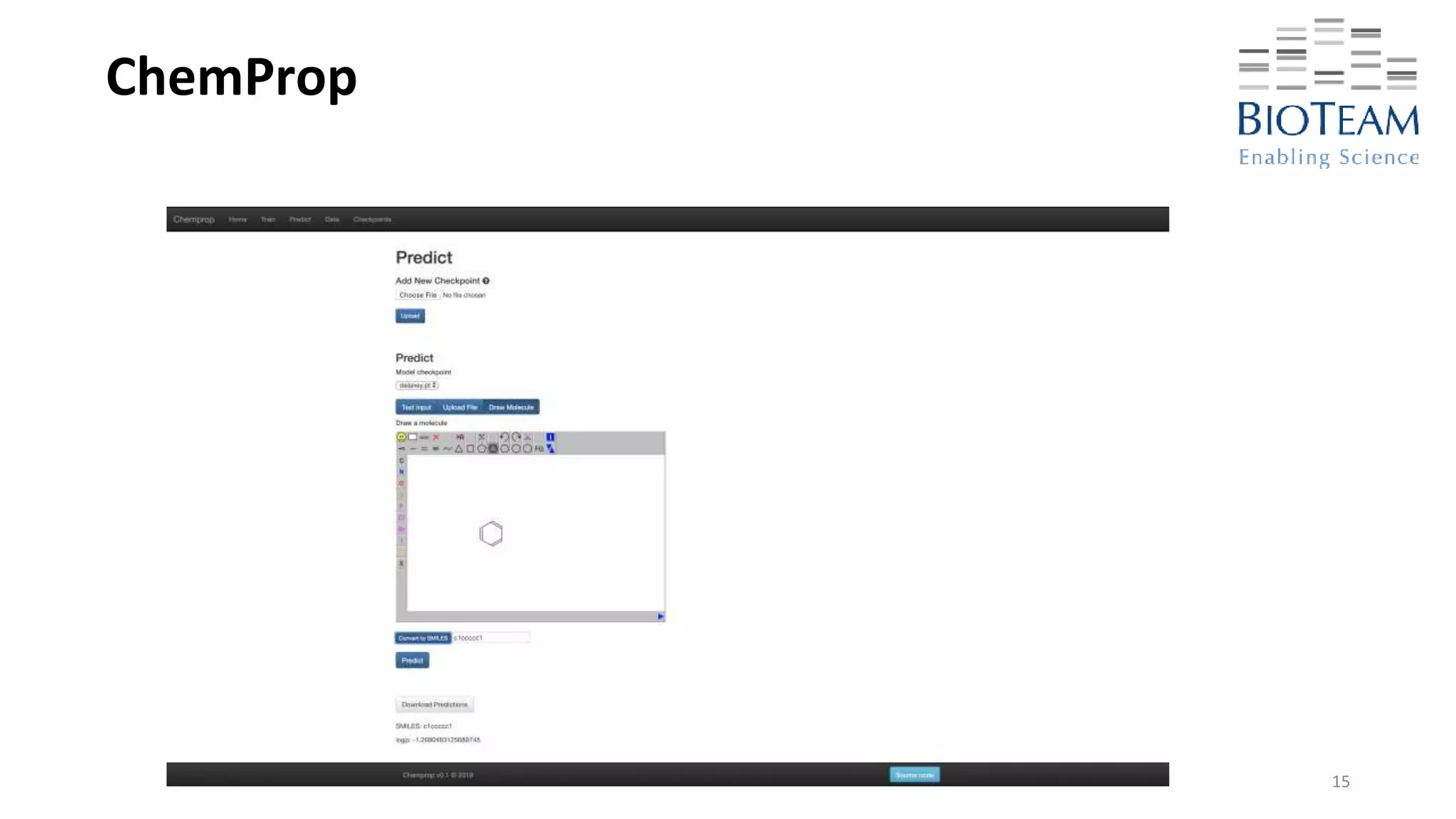
C)C(=O)NNC(=
O)C2=CC=CC=C2
0
CCN(CC)S(=O)(=O)C1=CC=C(C=C1)S(=O)(=O)N2CCCC2C(=O)O 1
CCN(CC)C1=CC(=C(C=C1)/C=N/NC(=O)C2=CC(=CC=C2)S(=O)(=O)NC3=
CC=CC=C3OC)O
1
CCCN1C=NC2=C1C=C(C(=C2N)C)C 0
CCCN1C(=O)C(SC1=O)CC(=O)NC2=CC=C(C=C2)C 1
CCC(C)NC(=O)C1CCN(CC1)S(=O)(=O)C2=CC=CC3=C2N=CC=C3 0](https://image.slidesharecdn.com/bioitwebinaronchempropppt-200506160535/75/BioIT-Webinar-on-AI-and-data-methods-for-drug-discovery-12-2048.jpg)




El documento presenta una introducción a la inteligencia artificial (IA), describiendo su definición, métodos y aplicaciones en el descubrimiento de fármacos. Se discuten herramientas como Chemprop y consejos para empezar a trabajar con IA, así como las características de los datos que se utilizan en estos procesos. También se enfatiza que los resultados obtenidos deben ser considerados preliminares y no constituyen consejos médicos.



































































