Download to read offline




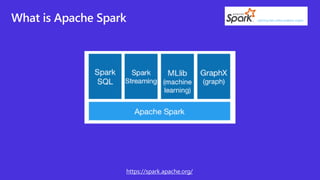
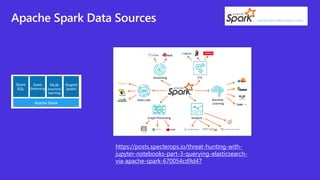
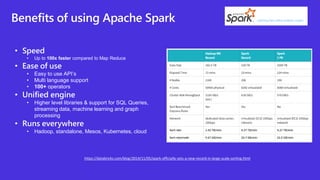











The document discusses Apache Spark, a unified analytics engine for large-scale data processing. It introduces .Net for Apache Spark, which provides .Net language bindings for Spark. It also mentions using the MovieLens dataset with Spark on Azure Synapse Analytics. Key components of Spark include RDDs, DataFrames, SparkSession, and transformations/actions. The document provides an overview of Spark and demonstrates it through a movie recommendation example on Azure Synapse Analytics.























































































