Downloaded 29 times





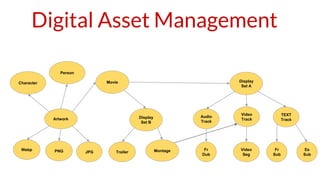




The document discusses the use of JanusGraph at Netflix, detailing its capabilities as a scalable graph database for managing vast amounts of data with high concurrency. It highlights integrations with various tools and metrics frameworks, usage statistics including over 200 million nodes, and applications in areas such as authorization and infrastructure mapping. JanusGraph efficiently handles complex queries and real-time graph traversals within Netflix's cloud environment.





































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




