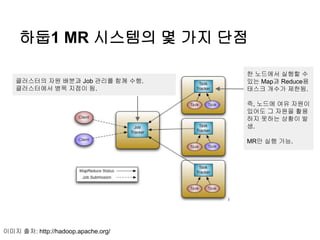
하둡1 MR 시스템의몇 가지 단점
한 노드에서 실행할 수
있는 Map과 Reduce용
태스크 개수가 제한됨.
즉, 노드에 여유 자원이
있어도 그 자원을 활용
하지 못하는 상황이 발
생.
MR만 실행 가능.
클러스터의 자원 배분과 Job 관리를 함께 수행.
클러스터에서 병목 지점이 됨.
이미지 출처: http://hadoop.apache.org/
3.
그래서 만든 YARN
●Yet Another Resource Negotiator
● 주요 특징
o MR1 시스템의 JobTracker가 하던 두 가지 역할-자원
관리, Job 상태 관리-를 ResourceManager와
ApplicationMaster로 분리
기존 JobTracker에 몰리던 병목을 제거
o 범용 컴퓨팅 클러스터
MR 외에 다양한 어플리케이션을 실행할 수 있으
며, 어플리케이션마다 자원(CPU, 메모리)을 할당
받음
4.
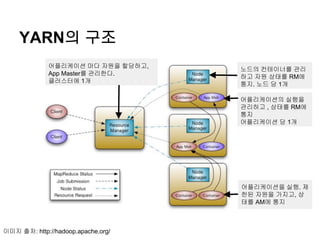
YARN의 구조
어플리케이션 마다자원을 할당하고,
App Master를 관리한다.
클러스터에 1개
노드의 컨테이너를 관리
하고 자원 상태를 RM에
통지. 노드 당 1개
어플리케이션의 실행을
관리하고 , 상태를 RM에
통지
어플리케이션 당 1개
어플리케이션을 실행. 제
한된 자원을 가지고, 상
태를 AM에 통지
이미지 출처: http://hadoop.apache.org/
5.
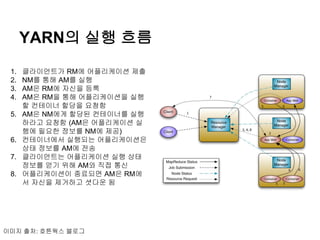
YARN의 실행 흐름
1.클라이언트가 RM에 어플리케이션 제출
2. NM를 통해 AM를 실행
3. AM은 RM에 자신을 등록
4. AM은 RM을 통해 어플리케이션을 실행
할 컨테이너 할당을 요청함
5. AM은 NM에게 할당된 컨테이너를 실행
하라고 요청함 (AM은 어플리케이션 실
행에 필요한 정보를 NM에 제공)
6. 컨테이너에서 실행되는 어플리케이션은
상태 정보를 AM에 전송
7. 클라이언트는 어플리케이션 실행 상태
정보를 얻기 위해 AM와 직접 통신
8. 어플리케이션이 종료되면 AM은 RM에
서 자신을 제거하고 셧다운 됨
이미지 출처: 호튼웍스 블로그
6.
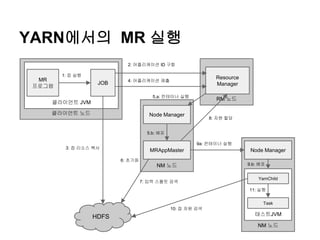
YARN에서의 MR 실행
클라이언트노드
클라이언트 JVM
MR
프로그램
JOB
1: 잡 실행
RM 노드
Resource
Manager
2: 어플리케이션 ID 구함
HDFS
3: 잡 리소스 복사
NM 노드
Node Manager
MRAppMaster
4: 어플리케이션 제출
5.a: 컨테이너 실행
5.b: 배포
6: 초기화
7: 입력 스플릿 검색
8: 자원 할당
NM 노드
Node Manager
태스트JVM
YarnChild
Task
9a: 컨테이너 실행
9.b: 배포
10: 잡 자원 검색
11: 실행
7.
실패 대상 처리방식
태스크 * 실패-태스크 실행 중 익셉션 발생(AM에 통지), JVM 갑작스런 종료
(AM에 통지), 행 걸린 태스크(핑을 통한 확인)-가 발생하면, AM은 태
스크 실행을 재시도
* 최대 시행 횟수 이상 실패하면 더 이상 태스크를 실행하지 않음
* 맵과 리듀스 태스크가 일정 비율 이상 실패하면, 잡을 실패로 간주
* AM은 한 노드에서 지정 횟수 이상 태스크가 실패하면, 해당 노드에
서 태스크를 실행하지 않음
어플리케이션 마스
터
* AM에서 RM로 주기적인 하트비트를 보내, AM의 정상 여부 판단.
* AM이 실패로 간주되면, RM은 다른 노드에 AM을 생성하고 어플리
케이션을 실행
노드 매니저 * NM는 RM로 하트비트를 보내, NM의 정상 여부 판단.
* NM가 실패로 간주되면, RM는 리소스 가용 풀에서 해당 NM를 제
거하고 해당 NM에서 실행중인 태스크와 어플리케이션은 다른 노드
에서 실행
리소스 매니저 * 주키퍼 기반 이중화 사용 (하둡 2.3.0 버전 기준)
YARN에서의 MR 실패 처리
8.
YARN 어플리케이션 예
●YARN 기반 실행
o Storm on YARN, 호튼웍스
o HOYA (Hbase on YARN), 호튼웍스
o Spark on YARN
o Apache Giraph on YARN
● YARN 어플리케이션 개발
o Spring Hadoop 2.0 (아직 RC1 버전)
Yahoo!는 YARN 기반 Storm을 이용해서 스트림 처리
- 320개 노드, 초당 13만개 이벤트 처리, 1만 2천 쓰레드 실행 증
- 공유데이터는 1900 노드에 2PB 보관
Yahoo! 전체
- 30,000 노드가 YARN에서 동작, 하루 40만개 잡 실행
- 노드 활용에서 60~150% 향상이 있다고 함
9.
정리
하둡1 MR
- MR만실행 가능
- 낮은 자원 활용
(고정된 맵/리듀스 슬롯)
- 확장 한계 (JobTracker 병목)
하둡2 YARN
- 범용 컴퓨팅/데이터 클러스터
- MR 외 다양한 어플리케이션 실행 가능
- 높은 자원 활용
- 확장성 개선 (역할 분리)



















![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)




![[빅데이터 컨퍼런스 전희원]](https://cdn.slidesharecdn.com/ss_thumbnails/random-120412212952-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)










![[225]yarn 기반의 deep learning application cluster 구축 김제민](https://cdn.slidesharecdn.com/ss_thumbnails/225yarndeeplearningapplicationcluster-161025031031-thumbnail.jpg?width=640&height=640&fit=bounds)

![[234]멀티테넌트 하둡 클러스터 운영 경험기](https://cdn.slidesharecdn.com/ss_thumbnails/234-171017024419-thumbnail.jpg?width=640&height=640&fit=bounds)

![[233]멀티테넌트하둡클러스터 남경완](https://cdn.slidesharecdn.com/ss_thumbnails/233-161025011544-thumbnail.jpg?width=640&height=640&fit=bounds)








![[2B5]nBase-ARC Redis Cluster](https://cdn.slidesharecdn.com/ss_thumbnails/2b5nbase-arcrediscluster-140930003743-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
























