More Related Content

PDF

PDF
D&DEPARTMENT PROJECT 창립자 나가오카 겐메이 특강 
PPTX

PDF
내가 뽀로로를 아이들에게 추천하는 이유 (Pororo is good for your children.) 
PPTX
웹보 소셜커머스의 부상과 향후전망(수정) 박민주 전하정 
PPTX

PDF

PPTX
Similar to Tm기반검색v2

PDF

PDF
인터넷 서비스 동향(검색/SNS 서비스 중심) 
PPSX
130308 디지털컨버젼스i 2교시 
PDF

PDF

PDF

PDF

PDF

PDF
전문가토크릴레이1탄 크로스모바일플랫폼 전략 (이경일 대표) 
PDF
전문가토크 릴레이1탄 크로스모바일플랫폼 전략 (이경일 대표) 
PDF
클라우드 기반의 시맨틱 웹 검색 서비스 사례 (플랫폼데이 2010) 
PDF
모바일 AR 개요 및 Scan Search 사례 3부 
PPT

PDF
네비게이션 검색 통합 - 민병국(2009) 
PDF
semantic search and mining 
PDF
6.최광선 semantic search and mining 
PDF

PDF
Daum 내부 빅데이터 및 클라우드 기술 활용 사례- 윤석찬 (2012) 
PDF
UCC특강-문화 미디어(Culture Technology)의 매커니즘과 웹 2.0 기술의 변화 3회 
PDF
More from H K Yoon

PDF

PDF

PDF

PDF
Nlp and transformer (v3s) 
PDF

PDF
Open source Embedded systems 
PDF

PPT
Tm기반검색v2
- 1.
- 2.
순서
• 배경
– 환경변화
– 개발배경
• 솔루션 개요
– 기본개념
– 시스템특징
• 솔루션 세부사항
– 주요 기능
– 제품구성
– 활용
– 아키텍처
• 결론
– 전망과 중기계획
• 회사소개
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 2
- 3.
배경
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 3
- 4.
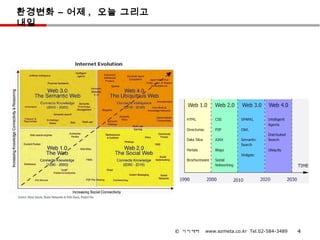
환경변화 – 어제, 오늘 그리고
내일
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 4
- 5.
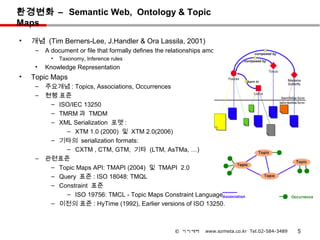
환경변화 – SemanticWeb, Ontology & Topic
Maps
• 개념 (Tim Berners-Lee, J.Handler & Ora Lassila, 2001)
– A document or file that formally defines the relationships among terms.
• Taxonomy, Inference rules
• Knowledge Representation
• Topic Maps
– 주요개념 : Topics, Associations, Occurrences
– 현행 표준
– ISO/IEC 13250
– TMRM 과 TMDM
– XML Serialization 포맷 :
– XTM 1.0 (2000) 및 XTM 2.0(2006)
– 기타의 serialization formats:
– CXTM , CTM, GTM, 기타 (LTM, AsTMa, …)
– 관련표준
– Topic Maps API: TMAPI (2004) 및 TMAPI 2.0
– Query 표준 : ISO 18048: TMQL
– Constraint 표준
– ISO 19756: TMCL - Topic Maps Constraint Language
– 이전의 표준 : HyTime (1992), Earlier versions of ISO 13250.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 5
- 6.
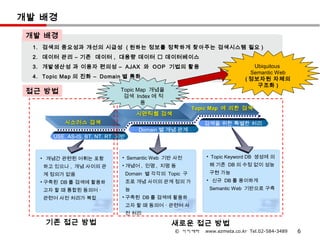
개발 배경
개발배경
1. 검색의 중요성과 개선의 시급성 ( 원하는 정보를 정학하게 찾아주는 검색시스템 필요 )
2. 데이터 관리 – 기존 데이터 , 대용량 데이터 데이터베이스
3. 개발생산성 과 이용자 편의성 – AJAX 와 OOP 기법의 활용 Ubiquitous
Semantic Web
4. Topic Map 의 진화 – Domain 별 특화 ( 정보자원 자체의
구조화 )
접근 방법 Topic Map 개념을
검색 Index 에 적
용
Topic Map 에 의한 검색
시맨틱웹 검색
시소러스 검색 검색을 위한 특별한 처리
Domain 별 개념 관계
USE, AS-IS, BT, NT, RT 기반
• 개념간 관련된 어휘는 포함 • Semantic Web 기반 사전 • Topic Keyword DB 생성에 의
하고 있으나 , 개념 사이의 관 • 개념어 , 인명 , 지명 등 해 기존 DB 의 수정 없이 성능
계 정의가 없음 Domain 별 각각의 Topic 구 구현 가능
• 구축된 DB 를 검색에 활용하 조로 개념 사이의 관계 정의 가 • 신규 DB 를 용이하게
고자 할 때 통합된 동의어ㆍ 능 Semantic Web 기반으로 구축
관련어 사전 처리가 복잡 • 구축된 DB 를 검색에 활용하
고자 할 때 동의어ㆍ관련어 사
전 처리
기존 접근 방법 새로운 접근 방법
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 6
- 7.
솔루션 개요
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 7
- 8.
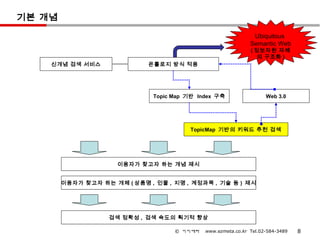
기본 개념
Ubiquitous
Semantic Web
( 정보자원 자체
의 구조화 )
신개념 검색 서비스 온톨로지 방식 적용
Topic Map 기반 Index 구축 Web 3.0
TopicMap 기반의 키워드 추천 검색
이용자가 찾고자 하는 개념 제시
이용자가 찾고자 하는 개체 ( 상품명 , 인물 , 지명 , 계정과목 , 기술 등 ) 제시
검색 정확성 , 검색 속도의 획기적 향상
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 8
- 9.
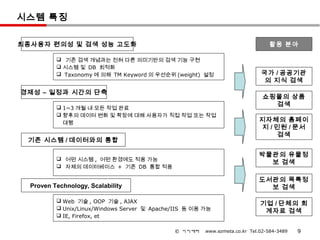
시스템 특징
최종사용자 편의성및 검색 성능 고도화 활용 분야
기존 검색 개념과는 전혀 다른 의미기반의 검색 기능 구현
시스템 및 DB 최적화
Taxonomy 에 의해 TM Keyword 의 우선순위 (weight) 설정 국가 / 공공기관
의 지식 검색
경제성 – 일정과 시간의 단축
쇼핑몰의 상품
1~3 개월 내 모든 작업 완료
검색
향후의 데이터 변화 및 확장에 대해 사용자가 직접 작업 또는 작업
대행
지자체의 홈페이
지 / 민원 / 문서
검색
기존 시스템 / 데이터와의 통합
박물관의 유물정
어떤 시스템 , 어떤 환경에도 적용 가능
보 검색
자체의 데이터베이스 + 기존 DB 통합 적용
도서관의 목록정
Proven Technology, Scalability 보 검색
Web 기술 , OOP 기술 , AJAX
기업 / 단체의 회
Unix/Linux/Windows Server 및 Apache/IIS 등 이용 가능
계자료 검색
IE, Firefox, et
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 9
- 10.
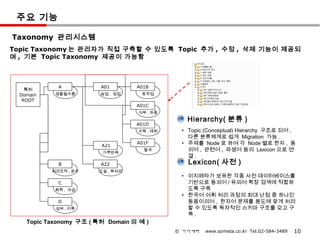
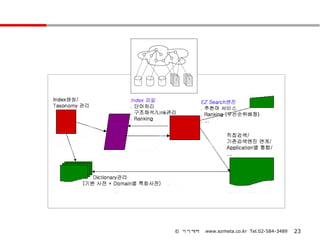
주요 기능
Taxonomy 관리시스템
TopicTaxonomy 는 관리자가 직접 구축할 수 있도록 Topic 추가 , 수정 , 삭제 기능이 제공되
며 , 기본 Topic Taxonomy 제공이 가능함
A A01 A01B
특허
Domain 생활필수품 농업 , 임업 토작업
ROOT
A01C
식부 , 파종
Hierarchy( 분류 )
A01D
수확 , 예취 • Topic (Conceptual) Hierarchy 구조로 되어 ,
다른 분류체계로 쉽게 Migration 가능 .
A21
A01F • 주제를 Node 로 하여 각 Node 별로 한자 , 동
가루반죽
탈곡 의어 , 관련어 , 파생어 등의 Lexicon 으로 연
결.
B A22 Lexicon( 사전 )
처리조작 , 운수 도살 , 육처리
• 이지메타가 보유한 각종 사전 데이터베이스를
C 기반으로 동의어 / 유의어 확장 검색에 적합하
화학 , 야금 도록 구축
• 한국어 어휘 처리 과정의 최대 난점 중 하나인
D 동음이의어 , 한자어 문제를 용도에 맞게 처리
섬유 , 지류 할 수 있도록 독자적인 스키마 구조를 갖고 구
축.
Topic Taxonomy 구조 ( 특허 Domain 의 예 )
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 10
- 11.
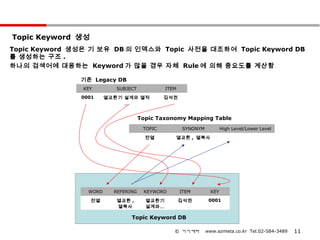
Topic Keyword 생성
TopicKeyword 생성은 기 보유 DB 의 인덱스와 Topic 사전을 대조하여 Topic Keyword DB
를 생성하는 구조 .
하나의 검색어에 대응하는 Keyword 가 많을 경우 자체 Rule 에 의해 중요도를 계산함
기존 Legacy DB
KEY SUBJECT ITEM
0001 열교환기 설계와 열적 김석권
…
Topic Taxonomy Mapping Table
TOPIC SYNONYM High Level/Lower Level
전열 열교환 , 열복사
WORD REFERING KEYWORD ITEM KEY
전열 열교환 , 열교환기 김석권 0001
열복사 설계와…
Topic Keyword DB
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 11
- 12.
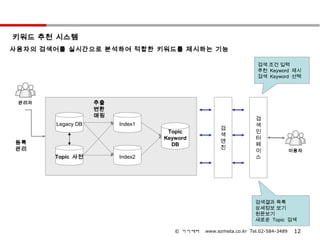
키워드 추천 시스템
사용자의검색어를 실시간으로 분석하여 적합한 키워드를 제시하는 기능
검색 조건 입력
추천 Keyword 제시
검색 Keyword 선택
관리자 추출
변환
매핑
검
Legacy DB Index1 색
검
Topic 인
색
Keyword 터
등록 엔
DB 페
관리 진
이 이용자
Topic 사전 Index2 스
검색결과 목록
상세정보 보기
원문보기
새로운 Topic 검색
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 12
- 13.
제품 구성
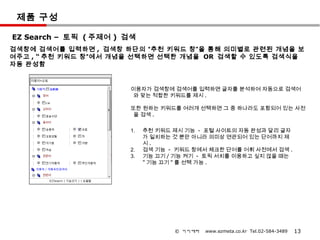
EZ Search– 토픽 ( 주제어 ) 검색
검색창에 검색어를 입력하면 , 검색창 하단의 “추천 키워드 창”을 통해 의미별로 관련된 개념을 보
여주고 , “ 추천 키워드 창”에서 개념을 선택하면 선택한 개념을 OR 검색할 수 있도록 검색식을
자동 완성함
이용자가 검색창에 검색어를 입력하면 글자를 분석하여 자동으로 검색어
와 맞는 적합한 키워드를 제시 .
또한 원하는 키워드를 여러개 선택하면 그 중 하나라도 포함되어 있는 사전
을 검색 .
1. 추천 키워드 제시 기능 - 포털 사이트의 자동 완성과 달리 글자
가 일치하는 것 뿐만 아니라 의미상 연관되어 있는 단어까지 제
시.
2. 검색 기능 - 키워드 창에서 체크한 단어를 어휘 사전에서 검색 .
3. 기능 끄기 / 기능 켜기 - 토픽 서치를 이용하고 싶지 않을 때는
" 기능 끄기 " 를 선택 가능 .
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 13
- 14.
EZ Book Search( 도서검색 )
검색창에 검색어를 입력하면 , 검색창 하단의 “추천 키워드 창”을 통해 검색어와 관련된 도서명을
보여주고 , “ 추천 키워드 창”에서 도서를 선택하면 선택한 도서로 검색식을 구성하고 , 그 도서들
의 상세 정보로 이동함
이용자가 검색창에 검색어를 입력하면 검색어가 포함되어 있는 도서명을
자동으로 검색합니다 . 검색어가 포함된 도서명이 없을 경우에는 이지메
타의 시소러스 사전을 적용하여 관련된 도서명을 검색 .
1. 추천 도서 제시 기능 - 포털 사이트의 검색어 자동 완성과 달리
도서명과 저자명을 키워드로 제시 .
2. 추천 도서 검색 기능 - 키워드창에 제시된 도서명 중에서 원하는
도서를 선택하여 검색 .
3. 여러 개 선택 - 2 개 이상의 도서명을 선택하여 그에 대한 서지정
보를 한꺼번에 볼 수 있는 기능 .
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 14
- 15.
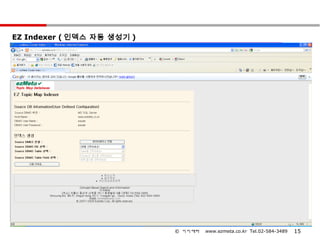
EZ Indexer (인덱스 자동 생성기 )
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 15
- 16.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 17.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 17
- 18.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 18
- 19.
활용
사이트 검색 (SiteSearch)
검색창에 검색어를 입력하면 , 검색창 하단의 “추천 키워드 창”을 통해 실시간으로 웹사이트의 관
련 메뉴 , 첨부파일 , 웹페이지 정보를 보여주고 , 원하는 페이지로 이동
검색어를 입력하자마자 실시간으로 검색어와 관련된 정보를
보여줌 .
건
물
1. 관련 메뉴를 먼저 표시
2. 관련 민원서식을 두번째로 제시
3. 관련 웹문서를 세번째로 제시
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 19
- 20.
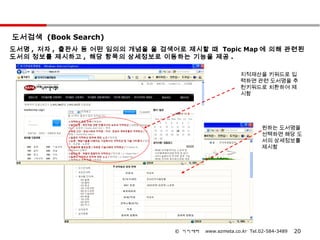
도서검색 (Book Search)
도서명, 저자 , 출판사 등 어떤 임의의 개념을 을 검색어로 제시할 때 Topic Map 에 의해 관련된
도서의 정보를 제시하고 , 해당 항목의 상세정보로 이동하는 기능을 제공 .
지적재산을 키워드로 입
력하면 관련 도서명을 추
천키워드로 치환하여 제
시함
원하는 도서명을
선택하면 해당 도
서의 상세정보를
제시함
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 20
- 21.
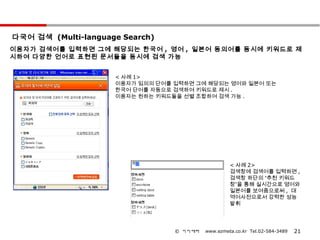
다국어 검색 (Multi-languageSearch)
이용자가 검색어를 입력하면 그에 해당되는 한국어 , 영어 , 일본어 동의어를 동시에 키워드로 제
시하여 다양한 언어로 표현된 문서 들을 동시에 검색 가능
< 사례 1>
이용자가 임의의 단어를 입력하면 그에 해당되는 영어와 일본어 또는
한국어 단어를 자동으로 검색하여 키워드로 제시 .
이용자는 원하는 키워드들을 선별 조합하여 검색 가능 .
< 사례 2>
검색창에 검색어를 입력하면 ,
검색창 하단의 “추천 키워드
창”을 통해 실시간으로 영어와
일본어를 보여줌으로써 , 대
역어사전으로서 강력한 성능
발휘
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 21
- 22.
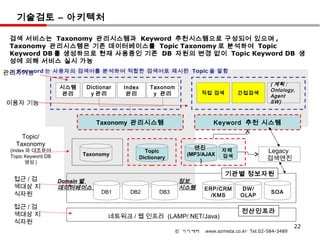
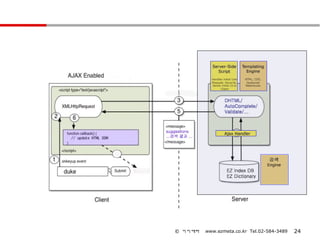
기술검토 – 아키텍처
검색 서비스는 Taxonomy 관리시스템과 Keyword 추천시스템으로 구성되어 있으며 ,
Taxonomy 관리시스템은 기존 데이터베이스를 Topic Taxonomy 로 분석하여 Topic
Keyword DB 를 생성하므로 현재 사용중인 기존 DB 자원의 변경 없이 Topic Keyword DB 생
성에 의해 서비스 실시 가능
※ Keyword 는 사용자의 검색어를 분석하여 적합한 검색어로 제시된 Topic 을 말함
관리자기능
( 계획 :
시스템 Dictionar Index Taxonom
Ontology,
관리 y 관리 관리 y 관리 직접 검색 간접검색
Agent
이용자 기능 SW)
Taxonomy 관리시스템 Keyword 추천 시스템
Topic/
Taxonomy
엔진
(Index 와 대조하여
Taxonomy
Topic
(MP3/AJAX
자체 Legacy
Topic Keyword DB 검색
Dictionary
) 검색엔진
생성 )
기관별 정보자원
접근 / 검 Domain 별 정보
색대상 지 데이터베이스 시스템 ERP/CRM DW/
식자원 DB1 DB2 DB3 SOA
/KMS OLAP
접근 / 검
전산인프라
색대상 지 네트워크 / 웹 인프라 (LAMP/.NET/Java)
식자원
22
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 23.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 23
- 24.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 24
- 25.
RDB vs. XML(RDF/Native Ontology)
RDB 활용 Topic Maps XML(RDF/…) 기반 Topic Maps
• 주요 특징 • 주요특징
– DB 기술 : Normalization, Join, … – Semantic precision
– Highly concentrated – Fully-declared documents
– Performance – Knowledge representation & reasoning
– Integrity checking system
– Partitioning, Cluster/Replication, 분산 – Ontology
DB , Federated DB – Model relations as only binary
• 단점
– Structured Data 중심 • 단점
– Additional entities 필요
• 구현 : – Verbose (for human readability)
– 성숙한 기술 • 구현 :
– Oracle, SQL Server, MySQL – XML DB
• 의견 – RDB 활용 ( 구현방법은 각기 다름 )
– Relation 기술 – RDB 활용 • 의견
– RDF – RDB – RDF to XML DB
– RDF – Flat file – DB Gateway 활용
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 26.
DB 차원 프로그래밍 언어 (framework)
• MySQL, SQL Server, Oracle 에서의 • RDF library for C++
XML API – C#/.Net
– 각기 다른 접근법 !! • RDF library for Java
– Jena Semantic Web Framework
• XML DB (RDF DB) • RDF API for Python, PHP
– 다양한 open source project
예 : RDF in MySQL
• Tags RDF/OWL 등의 tag 데이터를 일반 DB schema 로 자동 validate 하지 않는다 .
– MySQL 은 XML 을 string 데이터로 처리
– 따라서 XML functions (EXTRACTVALUE or UPDATEXML) 등을 이용
• RDFLib
– = a Python library for working with RDF, a simple yet powerful language for representing
information.
– http://www.rdflib.net/
• tell MySQL to create the Rdf database
– http://www.w3.org/1999/02/26-modules/User/RdfSQL-HOWTO.html#CreateDB
• DMOZ RDF Parser
– http://sourceforge.net/projects/suckdmoz/
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 27.
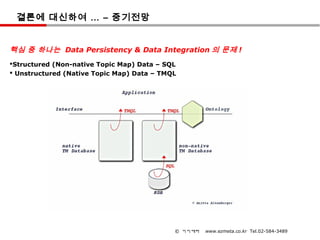
결론에 대신하여 …– 중기전망
핵심 중 하나는 Data Persistency & Data Integration 의 문제 !
Structured (Non-native Topic Map) Data – SQL
Unstructured (Native Topic Map) Data – TMQL
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 28.
- 29.
회사소개
• 개요
– 회사명 : 이지메타
– 주소 : 서울시 용산구 신계동 30-1 원영빌딩 4 층 Tel:02-584-3489
– 홈페이지 : http://www.ezmeta.co.kr
– 설립 : 2007 년 5 월 11 일
• 주요 사업분야 :
– 시소러스 , 온톨로지 DB 개발 / 디지털 콘텐츠 제작 / 사전 제작
• 주요 연혁 :
– 2009 한국전자출판협회 Book Search 공급
– 2009 지재권 판례정보 통합검색시스템 한영일 교차검색 개발
– 2008 특허 검색용 시소러스 DB 공급 [ 한국 IP 보호기술연구소 ]
– 2007 역사교육정보통합시스템 연구용역 [ 국사편찬위원회 ]
– 2007 ㈜지식공학의 시소러스 사업부문으로부터 독립
– 2004 특허등록 " 유의어 전자사전과 그 전자사전을 이용한 검색방법 "
– 2003 지식자원정보화사업 수행 ( 역사통합정보 , 한의학지식정보 )
– 2002 특허등록 " 유의어 전자사전과 그 전자사전을 이용한 검색방법 "
– 2002 한국기술거래소 " 기술거래용어“ [Autonomy 용 Taxonomy Data 제작 ]
– 2002 특허청 " 특허 , 과학기술 시소러스사전 " [ 검색엔진용 동의어 , 이형어 사전 ]
– 2001 한솔 CSN " 쇼핑몰 검색용 동의어사전 " 제작 [ 외래어 이형어 사전 포함 ]
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 29
- 30.
감사합니다 .
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 30
- 31.
Topic Maps 표준– SC34/WG3
• ISO/IEC JTC1/SC34/WG3 • Standards for which WG3 is responsible include:
• 3 working groups – HyTime (ISO/IEC/10744)
– – Topic Maps (ISO/IEC 13250)
WG1 deals with markup languages,
– – ISMID (ISO/IEC 13240)
WG2 with information presentation,
– – HTML (ISO/IEC 15545)
WG3 with information association.
• ISO 8879 (SGML) 및 관련 표준 기 • ISO 13250-1: Topic Maps — Overview
반의 정보관리 및 교환 표준 아키 • ISO 13250-2: Topic Maps — Data Model (TMDM)
텍처 : • ISO 13250-3: Topic Maps — XML Syntax (XTM
– 1. Information linking and addressing 2.0)
– 2. Time-based information management
• ISO 13250-4: CXTM (Canonicalization)
– 3. Representation of knowledge
structures, indexes, etc. • ISO 13250-5: Topic Maps — Reference Model
– 4. Management of behavioral (TMRM)
components in interactive documents
• ISO 13250-6: CTM (Compact Notation)
• ISO 13250-7: GTM (Graphical Notation)
• ISO 18048: TMQL
• ISO 19756: TMCL
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 32.
주요 tools
• TM4J
– a topic map processing tool-kit written in Java.
– http://www.tm4j.org/.
• The GooseWorks Topic Map Toolkit
– a topic map processing "engine" and API in C, with a wrapper API also available in Python.
– http://www.goose-works.org/
• TMTab
– a plug-in for Protégé-2000, an ontology creation tool, which enables an ontology created with
Protégé to be exported using XTM syntax.
– http://www.techquila.com/tmtab.html
• Nexist
– http://nexist.sourceforge.net/.
• SemanText
– developed in Python.
– http://www.semantext.com/.
• 회사
– www.ontopia.net
– www.empolis.net
– www.infoloom.com
– www.mondeca.com
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 33.
Topic Map 과B2B
• Ontology 를 이용한 B2B 데이터 상호운용성에 대해 Topic Map
은 해결책을 제시해 줄 수 있다 . == Business Maps
• 예:
– xCBL
– FinXML
– FpML
– OASIS Universal Business Language (UBL) TC
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 34.
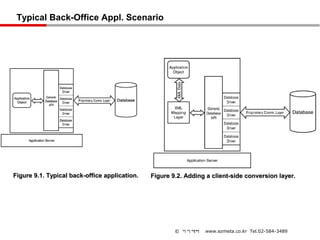
Typical Back-Office Appl.Scenario
Figure 9.1. Typical back-office application. Figure 9.2. Adding a client-side conversion layer.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 35.
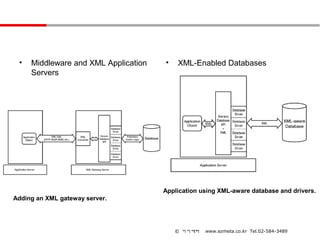
• Middleware and XML Application • XML-Enabled Databases
Servers
Application using XML-aware database and drivers.
Adding an XML gateway server.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 36.
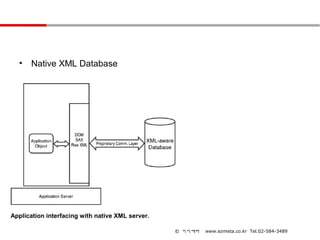
• Native XML Database
Application interfacing with native XML server.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 37.
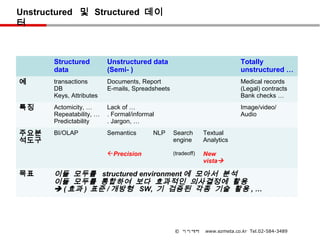
Unstructured 및 Structured데이
터
Structured Unstructured data Totally
data (Semi- ) unstructured …
예 transactions Documents, Report Medical records
DB E-mails, Spreadsheets (Legal) contracts
Keys, Attributes Bank checks …
특징 Actomicity, … Lack of … Image/video/
Repeatability, … . Formal/informal Audio
Predictability . Jargon, …
주요분 BI/OLAP Semantics NLP Search Textual
석도구 engine Analytics
Precision (tradeoff) New
vista
목표 이들 모두를 structured environment 에 모아서 분석
이들 모두를 통합하여 보다 효과적인 의사결정에 활용
( 효과 ) 표준 / 개방형 SW, 기 검증된 각종 기술 활용 , …
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
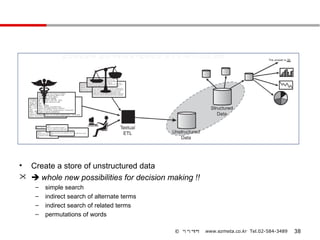
- 38.
• Create astore of unstructured data
whole new possibilities for decision making !!
– simple search
– indirect search of alternate terms
– indirect search of related terms
– permutations of words
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 38
- 39.
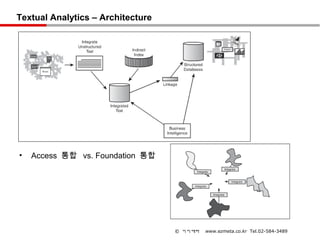
Textual Analytics –Architecture
• Access 통합 vs. Foundation 통합
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 40.
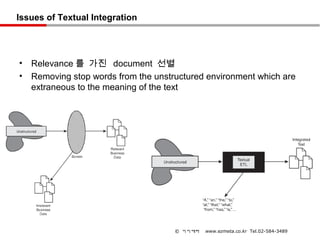
Issues of TextualIntegration
• Relevance 를 가진 document 선별
• Removing stop words from the unstructured environment which are
extraneous to the meaning of the text
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 41.
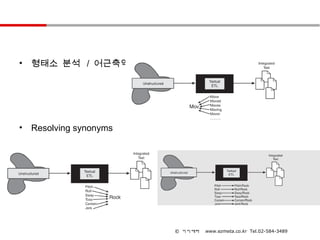
• 형태소 분석 / 어근축약
• Resolving synonyms
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 42.
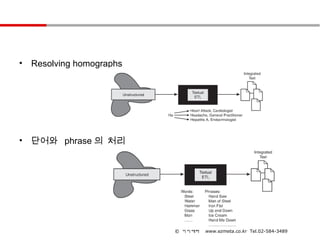
• Resolving homographs
• 단어와 phrase 의 처리
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 43.
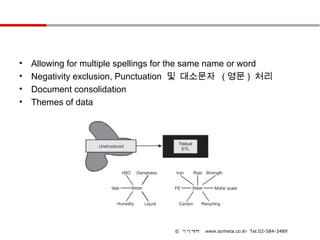
• Allowing for multiple spellings for the same name or word
• Negativity exclusion, Punctuation 및 대소문자 ( 영문 ) 처리
• Document consolidation
• Themes of data
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 44.
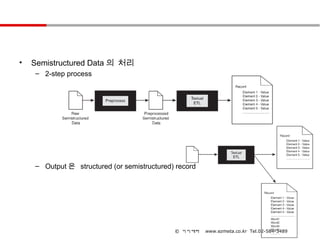
• Semistructured Data 의 처리
– 2-step process
– Output 은 structured (or semistructured) record
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 45.
• Approaching Metadata Through the Data Model
– A good way of approaching metadata – both internal and external – and
unstructured data environment is through the data model.
– A data model is merely another form of meta data
– The analyst selects the few things that are relevant to the unstructured
data that is at hand. The data model is created for whatever the analyst
has chosen. Then the data model is used to produce external
categories of data.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 46.
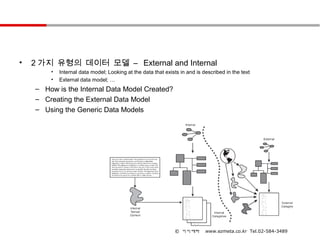
• 2 가지 유형의 데이터 모델 – External and Internal
• Internal data model; Looking at the data that exists in and is described in the text
• External data model; …
– How is the Internal Data Model Created?
– Creating the External Data Model
– Using the Generic Data Models
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 47.
Semantic Web 에서의Data
Model
Table A table of restaurants
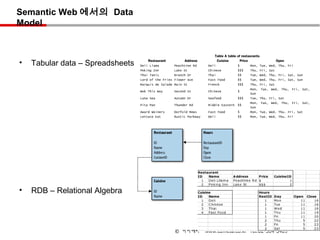
• Tabular data – Spreadsheets Restaurant
Deli Llama
Address
Peachtree Rd Deli
Cuisine
$
Price Open
Mon, Tue, Wed, Thu, Fri
Peking Inn Lake St Chinese $$$ Thu, Fri, Sat
Thai Tanic Branch Dr Thai $$ Tue, Wed, Thu, Fri, Sat, Sun
Lord of the Fries Flower Ave Fast Food $$ Tue, Wed, Thu, Fri, Sat, Sun
Marquis de Salade Main St French $$$ Thu, Fri, Sat
Mon, Tue, Wed, Thu, Fri, Sat,
Wok This Way Second St Chinese $
Sun
Luna Sea Autumn Dr Seafood $$$ Tue, Thu, Fri, Sat
Mon, Tue, Wed, Thu, Fri, Sat,
Pita Pan Thunder Rd Middle Eastern $$
Sun
Award Weiners Dorfold Mews Fast Food $ Mon, Tue, Wed, Thu, Fri, Sat
Lettuce Eat Rustic Parkway Deli $$ Mon, Tue, Wed, Thu, Fri
• RDB – Relational Algebra
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 48.
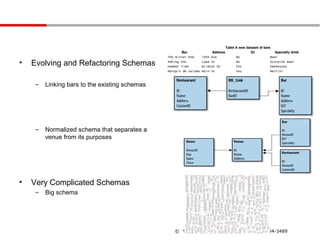
Table A newdataset of bars
Bar Address DJ Specialty drink
The Bitter End 14th Ave No Beer
• Evolving and Refactoring Schemas Peking Inn
Hammer Time
Lake St
Wildcat Dr
No
Yes
Scorpion Bowl
Hennessey
Marquis de Salade Main St Yes Martini
– Linking bars to the existing schemas
– Normalized schema that separates a
venue from its purposes
• Very Complicated Schemas
– Big schema
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 49.
• Getting it right the first time
– Venue schema with completely custom properties
– Venue data in more flexible form
– Adding a concert venue
without changing the schema
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 50.
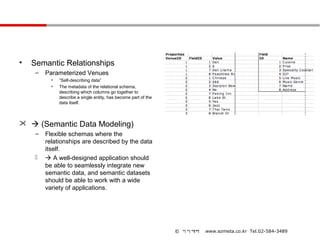
• Semantic Relationships
– Parameterized Venues
• “Self-describing data”
• The metadata of the relational schema,
describing which columns go together to
describe a single entity, has become part of the
data itself.
(Semantic Data Modeling)
– Flexible schemas where the
relationships are described by the data
itself.
A well-designed application should
be able to seamlessly integrate new
semantic data, and semantic datasets
should be able to work with a wide
variety of applications.
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 51.
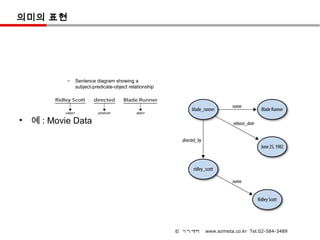
의미의 표현
– Sentence diagram showing a
subject-predicate-object relationship
• 예 : Movie Data
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489
- 52.
• Building a Simple Triplestore
– Indexes
class SimpleGraph:
def __init__(self):
self._spo = {}
self._pos = {}
self._osp = {}
– The add and remove Methods
def add(self, (sub, pred, obj)): def _addToIndex(self, index, a, b, c):
self._addToIndex(self._spo, sub, pred, obj) if a not in index: index[a] = {b:set([c])}
self._addToIndex(self._pos, pred, obj, sub) else:
self._addToIndex(self._osp, obj, sub, pred) if b not in index[a]: index[a][b] = set([c])
else: index[a][b].add(c)
def remove(self, (sub, pred, obj)):
triples = list(self.triples((sub, pred, obj)))
for (delSub, delPred, delObj) in triples:
self._removeFromIndex(self._spo, delSub, delPred,
delObj)
self._removeFromIndex(self._pos, delPred, delObj,
delSub)
self._removeFromIndex(self._osp, delObj, delSub,
delPred)
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489










![회사소개
• 개요
– 회사명 : 이지메타
– 주소 : 서울시 용산구 신계동 30-1 원영빌딩 4 층 Tel:02-584-3489
– 홈페이지 : http://www.ezmeta.co.kr
– 설립 : 2007 년 5 월 11 일
• 주요 사업분야 :
– 시소러스 , 온톨로지 DB 개발 / 디지털 콘텐츠 제작 / 사전 제작
• 주요 연혁 :
– 2009 한국전자출판협회 Book Search 공급
– 2009 지재권 판례정보 통합검색시스템 한영일 교차검색 개발
– 2008 특허 검색용 시소러스 DB 공급 [ 한국 IP 보호기술연구소 ]
– 2007 역사교육정보통합시스템 연구용역 [ 국사편찬위원회 ]
– 2007 ㈜지식공학의 시소러스 사업부문으로부터 독립
– 2004 특허등록 " 유의어 전자사전과 그 전자사전을 이용한 검색방법 "
– 2003 지식자원정보화사업 수행 ( 역사통합정보 , 한의학지식정보 )
– 2002 특허등록 " 유의어 전자사전과 그 전자사전을 이용한 검색방법 "
– 2002 한국기술거래소 " 기술거래용어“ [Autonomy 용 Taxonomy Data 제작 ]
– 2002 특허청 " 특허 , 과학기술 시소러스사전 " [ 검색엔진용 동의어 , 이형어 사전 ]
– 2001 한솔 CSN " 쇼핑몰 검색용 동의어사전 " 제작 [ 외래어 이형어 사전 포함 ]
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489 29](https://image.slidesharecdn.com/tmv2-121109171502-phpapp01/85/Tm-v2-29-320.jpg)






![• Building a Simple Triplestore
– Indexes
class SimpleGraph:
def __init__(self):
self._spo = {}
self._pos = {}
self._osp = {}
– The add and remove Methods
def add(self, (sub, pred, obj)): def _addToIndex(self, index, a, b, c):
self._addToIndex(self._spo, sub, pred, obj) if a not in index: index[a] = {b:set([c])}
self._addToIndex(self._pos, pred, obj, sub) else:
self._addToIndex(self._osp, obj, sub, pred) if b not in index[a]: index[a][b] = set([c])
else: index[a][b].add(c)
def remove(self, (sub, pred, obj)):
triples = list(self.triples((sub, pred, obj)))
for (delSub, delPred, delObj) in triples:
self._removeFromIndex(self._spo, delSub, delPred,
delObj)
self._removeFromIndex(self._pos, delPred, delObj,
delSub)
self._removeFromIndex(self._osp, delObj, delSub,
delPred)
© 이지메타 www.ezmeta.co.kr Tel.02-584-3489](https://image.slidesharecdn.com/tmv2-121109171502-phpapp01/85/Tm-v2-52-320.jpg)