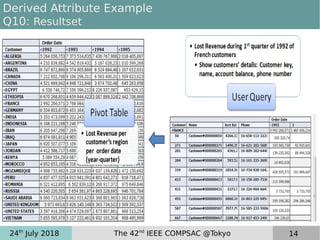
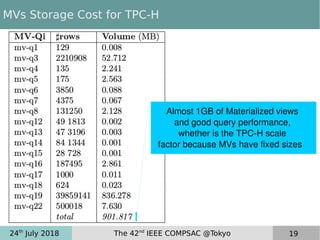
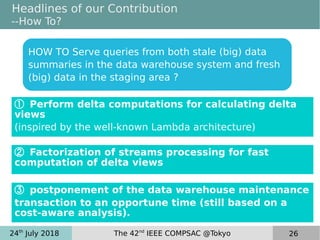
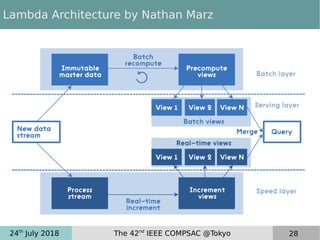
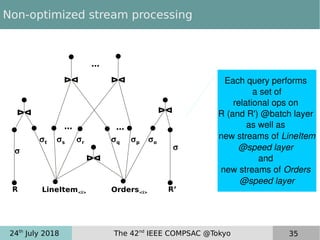
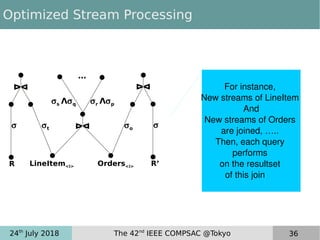
This document discusses near real-time OLAP over big data. It proposes a new framework that uses lambda processing and factorized stream processing to efficiently refresh data summaries when new data streams are received. The framework aims to improve query performance, ensure accuracy with fresh data, and keep the data warehouse operational during maintenance transactions. Key aspects of the framework include postponing maintenance transactions, computing delta views from factorized streams to refresh summaries incrementally, and applying the lambda architecture concept with batch, speed and serving layers.