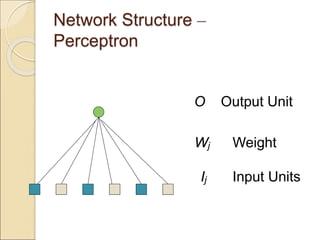
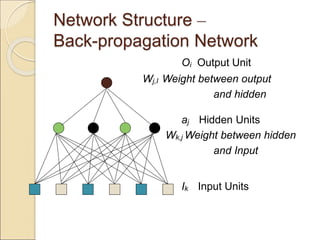
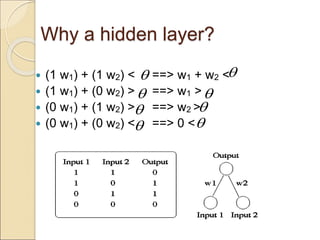
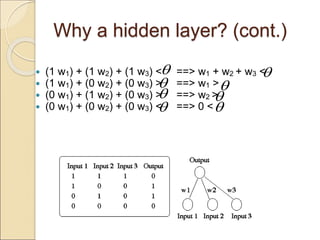
The document discusses back-propagation networks in neural networks, detailing their structure, learning rules, and weight adjustments. It highlights the significance of hidden layers for improved expressiveness, generalization, and tolerance to noise, despite challenges in computational efficiency and transparency. The learning process involves measuring and reducing error through gradient descent techniques.