More Related Content

PDF
20200422 AWS Black Belt Online Seminar Amazon Elastic Container Service (Amaz... 
PPTX
20211109 JAWS-UG SRE keynotes 
PDF
20180704(20190520 Renewed) AWS Black Belt Online Seminar Amazon Elastic File ... 
PDF
20190522 AWS Black Belt Online Seminar AWS Step Functions 
PDF
Presto ベースのマネージドサービス Amazon Athena 
PDF
20190424 AWS Black Belt Online Seminar Amazon Aurora MySQL 
PDF
20210316 AWS Black Belt Online Seminar AWS DataSync 
PDF
20190326 AWS Black Belt Online Seminar Amazon CloudWatch What's hot

PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ 
PDF
20190806 AWS Black Belt Online Seminar AWS Glue 
PDF
20180221 AWS Black Belt Online Seminar AWS Lambda@Edge ![[Cloud OnAir] Google Cloud でセキュアにアプリケーションを開発しよう 2019年3月7日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0307-190307093545-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Cloud OnAir] Google Cloud でセキュアにアプリケーションを開発しよう 2019年3月7日 放送 
PDF
20211203 AWS Black Belt Online Seminar AWS re:Invent 2021アップデート速報 
PDF
AWS Black Belt Online Seminar 2017 AWS Elastic Beanstalk 
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation 
PDF
AWS Well-Architected Security とベストプラクティス 
PDF
20201118 AWS Black Belt Online Seminar 形で考えるサーバーレス設計 サーバーレスユースケースパターン解説 
PDF
20200212 AWS Black Belt Online Seminar AWS Systems Manager 
PDF
20180425 AWS Black Belt Online Seminar Amazon Relational Database Service (Am... 
PDF

PDF
AWS Black Belt Techシリーズ AWS Direct Connect 
PDF

PDF
20210119 AWS Black Belt Online Seminar AWS CloudTrail 
PDF
202110 AWS Black Belt Online Seminar AWS Site-to-Site VPN 
PDF
浸透するサーバーレス 実際に見るユースケースと実装パターン 
PDF
AWS Black Belt Online Seminar AWS Amplify 
PDF
AWS Black Belt Online Seminar 2017 AWS WAF 
PDF
Best Practices for Running PostgreSQL on AWS Similar to Amazon Elastic MapReduce with Hive/Presto ハンズオン(講義)

PDF
AWS Black Belt Tech シリーズ 2015 - Amazon Elastic MapReduce 
PDF
AWS Black Belt Techシリーズ Amazon EMR ![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR) 
PDF
20120303 _JAWS-UG_SUMMIT2012_エキスパートセッションEMR編 
PDF
AWS Black Belt Techシリーズ AWS Data Pipeline 
PDF
AWS Black Belt Online Seminar 2016 Amazon EMR 
PDF
Amazon S3を中心とするデータ分析のベストプラクティス 
PDF

PDF
ソリューションセッション#3 ビッグデータの3つのVと4つのプロセスを支えるAWS活用法 
PDF
AWS初心者向けWebinar AWSでBig Data活用 
PPTX

PDF
20111130 10 aws-meister-emr_long-public 
PDF
ビッグデータサービス群のおさらい & AWS Data Pipeline 
PDF
【IVS CTO Night & Day】AWSにおけるビッグデータ活用 
PDF
Awsデータレイク事例祭り dmm.com YUKI SASITO.pdf 
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall 
PDF
TokyoWebminig カジュアルなHadoop 
PDF
AWS Black Belt Tech シリーズ 2015 - AWS Data Pipeline 
PDF
Modernizing Big Data Workload Using Amazon EMR & AWS Glue 
PPT
More from Amazon Web Services Japan

PDF
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM) 
PDF
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS 
PDF
202204 AWS Black Belt Online Seminar AWS IoT Device Defender 
PDF
Infrastructure as Code (IaC) 談義 2022 
PDF
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現 
PDF
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap... 
PDF
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート 
PPTX
20220409 AWS BLEA 開発にあたって検討したこと 
PDF
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用 
PDF
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf 
PDF
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介 
PDF
Amazon QuickSight の組み込み方法をちょっぴりDD 
PDF
マルチテナント化で知っておきたいデータベースのこと 
PDF
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介 
PDF
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles 
PDF
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために 
PDF
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨ ![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介 
PDF
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介 
PDF
202201 AWS Black Belt Online Seminar Apache Spark Performnace Tuning for AWS ... Amazon Elastic MapReduce with Hive/Presto ハンズオン(講義)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
12
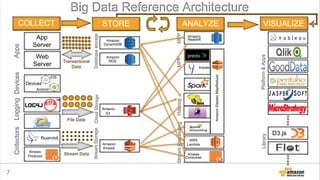
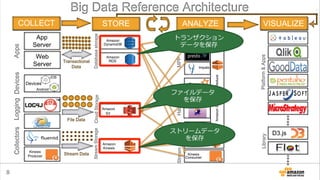
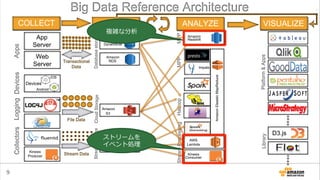
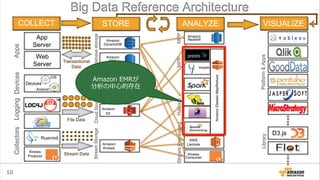
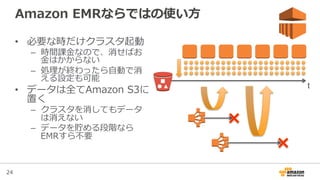
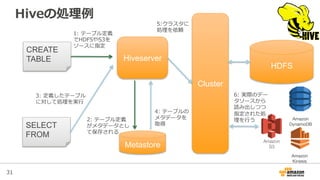
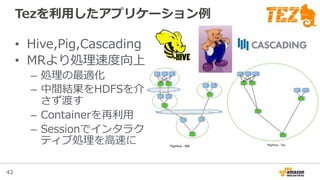
Amazon Elastic MapReduceとは?
• 1クリックでHadoopクラスタが⼿手に⼊入る
– 使い終わったらまとめて捨てるのも簡単
– スポットインスタンスを使ったコストカットも
• 設定済のアプリケーションがすぐ使える
– Application: Hive, Hue, Impalaなど
– Bootstrap Action: Presto, Sparkなど
• ⾏行行うべき処理理を簡単に設定できる
– ジョブが終わったらクラスタを消すところまで⾃自動化
- 13.
13
Task Node
Task InstanceGroup
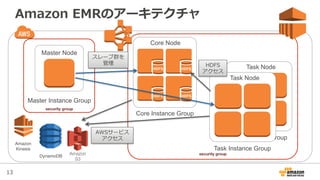
Amazon EMRのアーキテクチャ
security group
security group
Master Node
Master Instance Group
Amazon
S3
DynamoDB
Amazon
Kinesis
Core Node
Core Instance Group
HDFS HDFS
HDFS HDFS
Task Node
Task Instance Group
スレーブ群を
管理理 HDFS
アクセス
AWSサービス
アクセス
- 14.
14
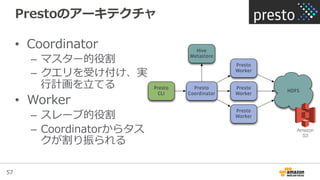
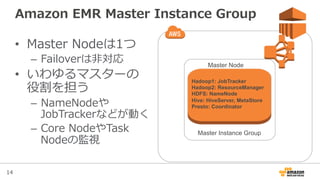
Amazon EMR Master Instance Group
• Master Nodeは1つ
– Failoverは⾮非対応
• いわゆるマスターの
役割を担う
– NameNodeや
JobTrackerなどが動く
– Core NodeやTask
Nodeの監視
Master Node
Master Instance Group
Hadoop1: JobTracker
Hadoop2: ResourceManager
HDFS: NameNode
Hive: HiveServer, MetaStore
Presto: Coordinator
- 15.
15
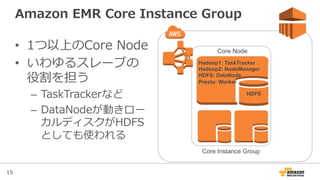
Amazon EMR Core Instance Group
• 1つ以上のCore Node
• いわゆるスレーブの
役割を担う
– TaskTrackerなど
– DataNodeが動きロー
カルディスクがHDFS
としても使われる
HDFS
Core Node
Core Instance Group
Hadoop1: TaskTracker
Hadoop2: NodeManager
HDFS: DataNode
Presto: Worker
- 16.
16
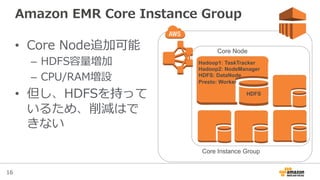
Amazon EMR Core Instance Group
• Core Node追加可能
– HDFS容量量増加
– CPU/RAM増設
• 但し、HDFSを持って
いるため、削減はで
きない
HDFS
Core Node
Core Instance Group
Hadoop1: TaskTracker
Hadoop2: NodeManager
HDFS: DataNode
Presto: Worker
- 17.
17
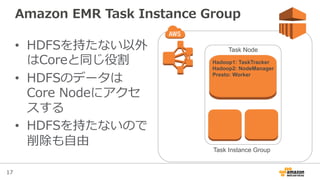
Amazon EMR Task Instance Group
• HDFSを持たない以外
はCoreと同じ役割
• HDFSのデータは
Core Nodeにアクセ
スする
• HDFSを持たないので
削除も⾃自由
Task Node
Task Instance Group
Hadoop1: TaskTracker
Hadoop2: NodeManager
Presto: Worker
- 18.
18
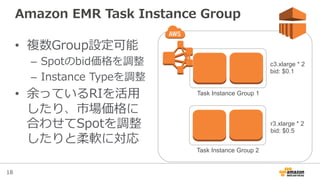
Amazon EMR Task Instance Group
• 複数Group設定可能
– Spotのbid価格を調整
– Instance Typeを調整
• 余っているRIを活⽤用
したり、市場価格に
合わせてSpotを調整
したりと柔軟に対応
Task Instance Group 2
Task Instance Group 1
c3.xlarge * 2
bid: $0.1
r3.xlarge * 2
bid: $0.5
- 19.
19
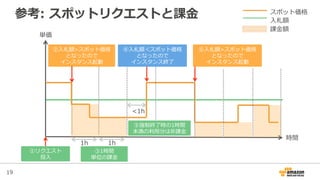
参考: スポットリクエストと課⾦金金
単価
時間
1h 1h
<1h
スポット価格
⼊入札額
課⾦金金額
②⼊入札額>スポット価格
となったので
インスタンス起動
④⼊入札額<スポット価格
となったので
インスタンス終了了
⑥⼊入札額>スポット価格
となったので
インスタンス起動
①リクエスト
投⼊入
⑤強制終了了時の1時間
未満の利利⽤用分は⾮非課⾦金金
③1時間
単位の課⾦金金
- 20.
20
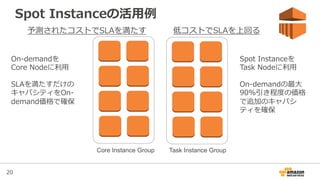
Spot Instanceの活⽤用例例
Task InstanceGroupCore Instance Group
予測されたコストでSLAを満たす 低コストでSLAを上回る
On-‐‑‒demandを
Core Nodeに利利⽤用
SLAを満たすだけの
キャパシティをOn-‐‑‒
demand価格で確保
Spot Instanceを
Task Nodeに利利⽤用
On-‐‑‒demandの最⼤大
90%引き程度度の価格
で追加のキャパシ
ティを確保
- 21.
- 22.
- 23.
23
EMRFSのConsistent View
• Amazon S3は結果整合性
– 書き込み直後の読み取りは不不整
合の可能性
• EMRFSではConsistent View
を提供
– Amazon DynamoDBにメタデー
タを格納し整合性担保
• 結果としてオブジェクトのリ
スト取得も⾼高速に
Amazon S3
Amazon DynamoDB
EMRFSの
メタデータを格納
- 24.
- 25.
25
Amazon EMRの機能: Bootstrap Action
• 全てのNodeの起動時に実⾏行行されるスクリプト
– 実⾏行行可能ファイルであれば何でもOK
• Bash, Ruby, Python, etc.
– Amazon S3にファイルを置いて指定する
– コマンドライン引数も⾃自由に指定できる
• 任意のソフトウェアをインストールしたり、設
定したりできる
– AWS提供のものもいくつか存在する
- 26.
26
Amazon EMRの機能: Step
• クラスタが準備できたら始まる処理理
– クラスタ起動時に設定することもできるし、起動しているクラスタ
に後から追加することもできる
– 例例: ⽇日次のETL処理理を⾏行行うHiveQL実⾏行行
• Amazon S3のjarファイルを指定すると実⾏行行される
– Streaming, Hive, PigはEMRがサポート
• 必要なスクリプトをS3で指定するだけ
– script-‐‑‒runner.jarでbashスクリプトを実⾏行行させることも可能
• 最後のStepが終わったら⾃自動でクラスタを終了了させ
ることもできる(Auto-‐‑‒terminate)
- 27.
27
Amazon EMRの機能: Application
• いくつかのApplicationをサポート
– Hive, Pig, Hue, HBase, etc.
– 実体はBootstrap ActionとStepの組み合わせ
• 難しいことを覚えずに、分散処理理をすぐ使える
– 最近はMapReduceを直接書くより、⽤用途に合わせたアプリケー
ションを利利⽤用することでレイテンシ最適化を⾏行行うことが多い
– Bootstrap Action, Step, Applicationを組み合わせて、分散処
理理を簡単に扱える環境を提供するのが、Amazon EMR
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
33
Hive on Amazon EMR
• Applicationサポート
– クラスタ起動時に指定
– すぐに利利⽤用可能
• Metastore
– デフォルトではMaster上
のMySQLに保存
– hive-‐‑‒site.xmlを設定して任
意のMySQLも利利⽤用可能
$ aws emr create-cluster …
--applications Name=Hive
…
- 34.
- 35.
35
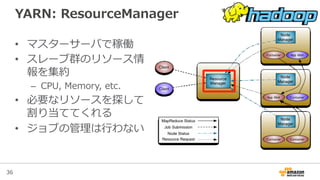
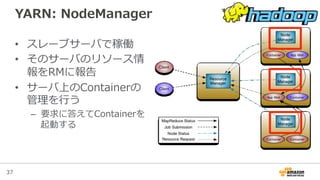
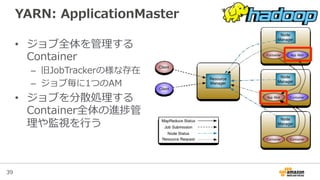
YARNとは?
• YARN = Yet-‐‑‒Another-‐‑‒Resource-‐‑‒Negotiator
• Hadoop2から導⼊入されたリソース管理理の仕組み
– 以前は全てJobTrackerが⾏行行っていた
• YARN対応アプリケーションであればマルチテ
ナントに動かすことが容易易
– MapReduceだけでなく、分散リソースを必要とする処理理をクラ
スタが許す限りいくらでも並列列に実⾏行行できる
- 36.
- 37.
- 38.
- 39.
- 40.
40
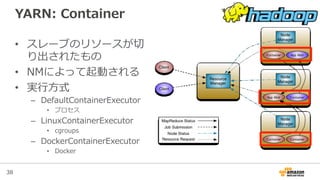
YARNがもたらしたもの
• クラスタのリソース管理理の抽象化
– 同様のものに、Mesos, Amazon EC2 Container Service等がある
• 分散処理理実⾏行行フレームワーク
– 実際の分散処理理の開発に注⼒力力できる
– YARN対応すれば全てをマルチテナント実⾏行行できる
• YARN上のフレームワークも
– Tez: DAG処理理を⾼高速にYARN上で実⾏行行する(詳細は後で)
– Twill: YARNアプリを簡単に書ける
– Slider: コード変えずに⻑⾧長期起動アプリをYARN上で動かせる
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
46
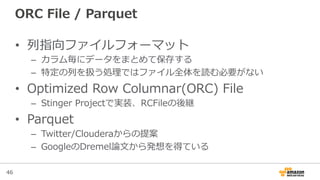
ORC File / Parquet
• 列列指向ファイルフォーマット
– カラム毎にデータをまとめて保存する
– 特定の列列を扱う処理理ではファイル全体を読む必要がない
• Optimized Row Columnar(ORC) File
– Stinger Projectで実装、RCFileの後継
• Parquet
– Twitter/Clouderaからの提案
– GoogleのDremel論論⽂文から発想を得ている
- 47.
47
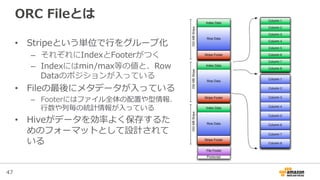
ORC Fileとは
• Stripeという単位で⾏行行をグループ化
– それぞれにIndexとFooterがつく
– Indexにはmin/max等の値と、Row
Dataのポジションが⼊入っている
• Fileの最後にメタデータが⼊入っている
– Footerにはファイル全体の配置や型情報、
⾏行行数や列列毎の統計情報が⼊入っている
• Hiveがデータを効率率率よく保存するた
めのフォーマットとして設計されて
いる
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
53
Massively Parallel Processing (MPP) SQL
• ⼤大規模分散SQLを実⾏行行環
境はHiveだけではない
• HiveライクなMPP
– Presto, Impala, Spark
SQL, Drill
• DWH
– Amazon Redshift
• データ⾃自体もMPPに特化さ
せてAmazon Redshift内に
保持する
Amazon Redshift
- 54.
- 55.
- 56.
56
Prestoとは?
• MPP SQLエンジンの1つ
• ANSI SQL準拠のクエリ⾔言語
• 独⾃自のクラスタでSQLの⾼高速分散実⾏行行に特化
– メモリ上でデータをやり取り
– 今のところYARN等の対応は無い
• MySQLやPostgreSQL等にもクエリが可能
– 異異なるデータソースをJOINすることも可能
- 57.
- 58.
58
Presto on Amazon EMR
• 2015年年4⽉月現在、Applicationサポートは無し
• Bootstrap Actionでのインストールが可能
– AWSから提供されるスクリプトが存在
– https://github.com/awslabs/emr-‐‑‒bootstrap-‐‑‒actions/tree/master/presto/latest
• PrestoはYARNと別でクラスタを組むのでリ
ソース競合に注意
– お互いがサーバのリソースを使いきる可能性
– Presto専⽤用のAmazon EMRクラスタとして使うのがベター
- 59.
- 60.


























![50
HiveでのORC File/Parquetの使い⽅方
• テーブル定義で指定
するだけ
• あとは何も意識識しな
くて良良い
CREATE TABLE t (
col1 STRING,
…
) STORED AS [ORC/PARQUET];
INSERT INTO t (…);
SELECT col1 FROM t;](https://image.slidesharecdn.com/20150513emr-handson-public-150515050024-lva1-app6892/85/Amazon-Elastic-MapReduce-with-Hive-Presto-50-320.jpg)