Data Lake 나온배경
• 아파트 단지 별 일/주/월 조회 수 데이터 뽑을 수 있나요?
• 원룸 매물 별 조회수 일/주/월 데이터 뽑을 수 있나요?
• 지역별 서비스 별 조회수 구할 수 있나요?
• 현재 사용자가 조회한 아파트 단지 조회 수 실시간으로 볼 수 있나요?
요구사항
7.
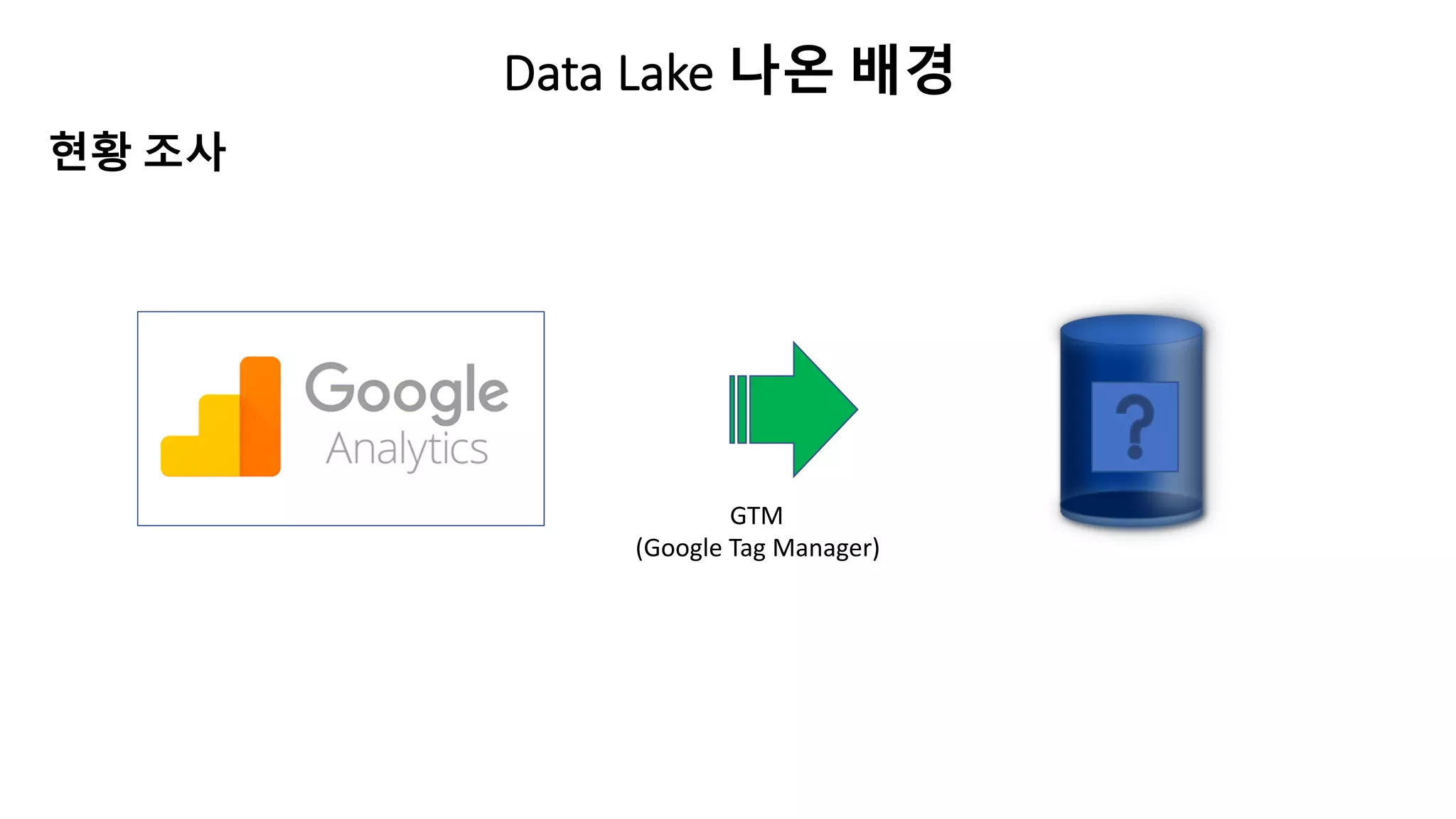
Data Lake 나온배경
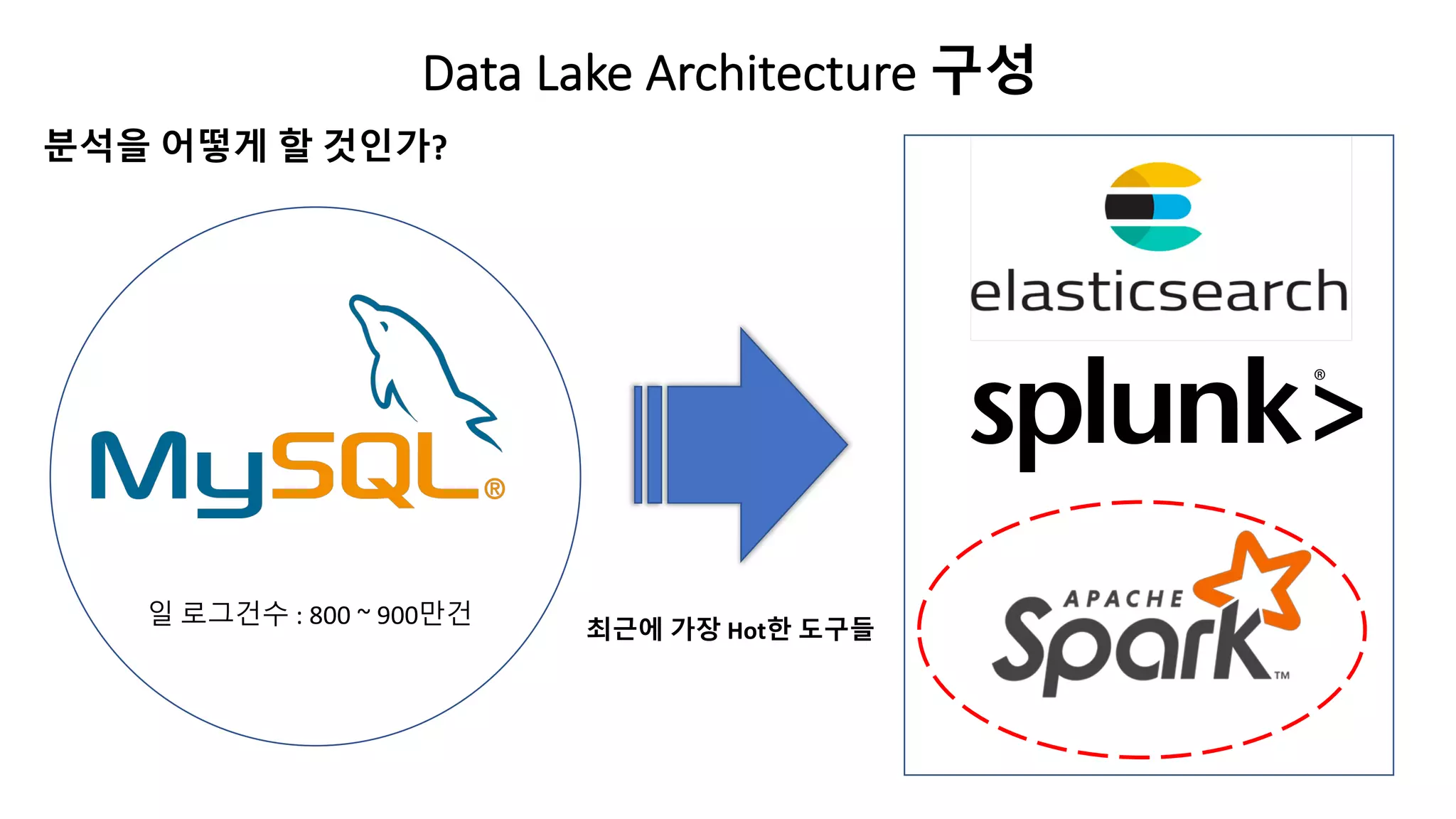
• GA(Google Analytics) 에서만 데이터 쌓고 있음.
• 현재 해당 데이터 내부 시스템에 쌓고 있지 않음.
• GA는 현재 하루에 쌓아야 할 수 있는 데이터 Event수를 넘어서 유료 전환해야 함.
• GA는 현재 무료사용자이기때문에 데이터가 정확하지 않음.
현황 조사
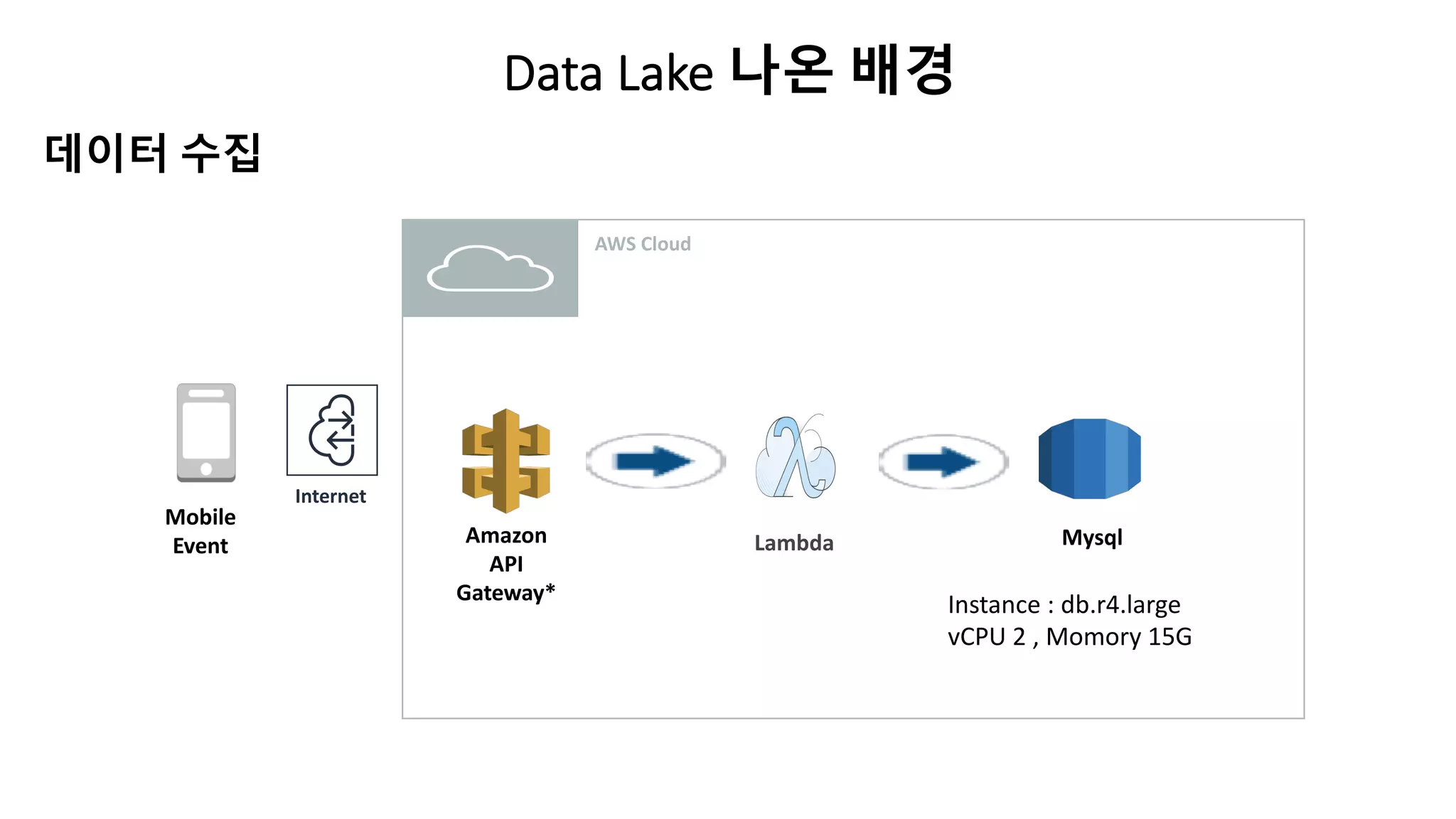
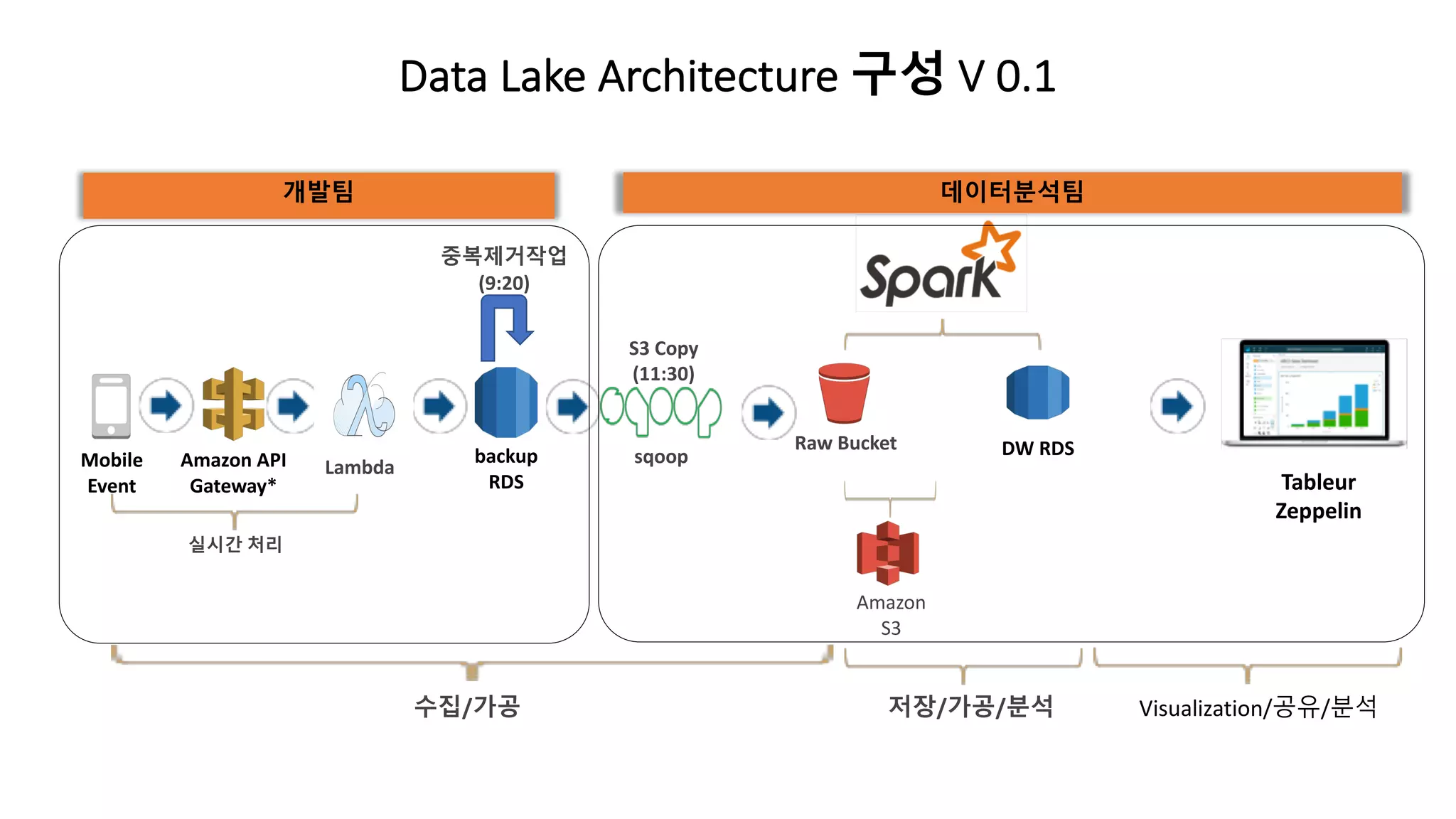
Data Lake Architecture구성 V 0.1
Raw Bucket
Amazon
S3
LambdaAmazon API
Gateway*
Mobile
Event Tableur
Zeppelin
backup
RDS
sqoop
중복제거작업
(9:20)
S3 Copy
(11:30)
수집/가공 저장/가공/분석 Visualization/공유/분석
실시간 처리
DW RDS
개발팀 데이터분석팀
20.
개선된 점
1. 내부데이터로 Dau, Wau, Mau 생성이 가능해졌다
2. 사용자에 대한 분석이 가능해졌다.
3. 아파트 별 일자 별 조회수가 가능해졌다.
4. 서비스별 일자별 조회수가 가능해졌다.
5. 서비스별 Dau 조회가 가능해졌다.
6. 현제 Raw Data만 있다면 1일 내로 요청Use case에 대해서 데이터를 처리가 가능해졌다
7. 빅데이터 분석의 희망이 보임
20
Data Lake Architecture 구성 V 0.1
21.
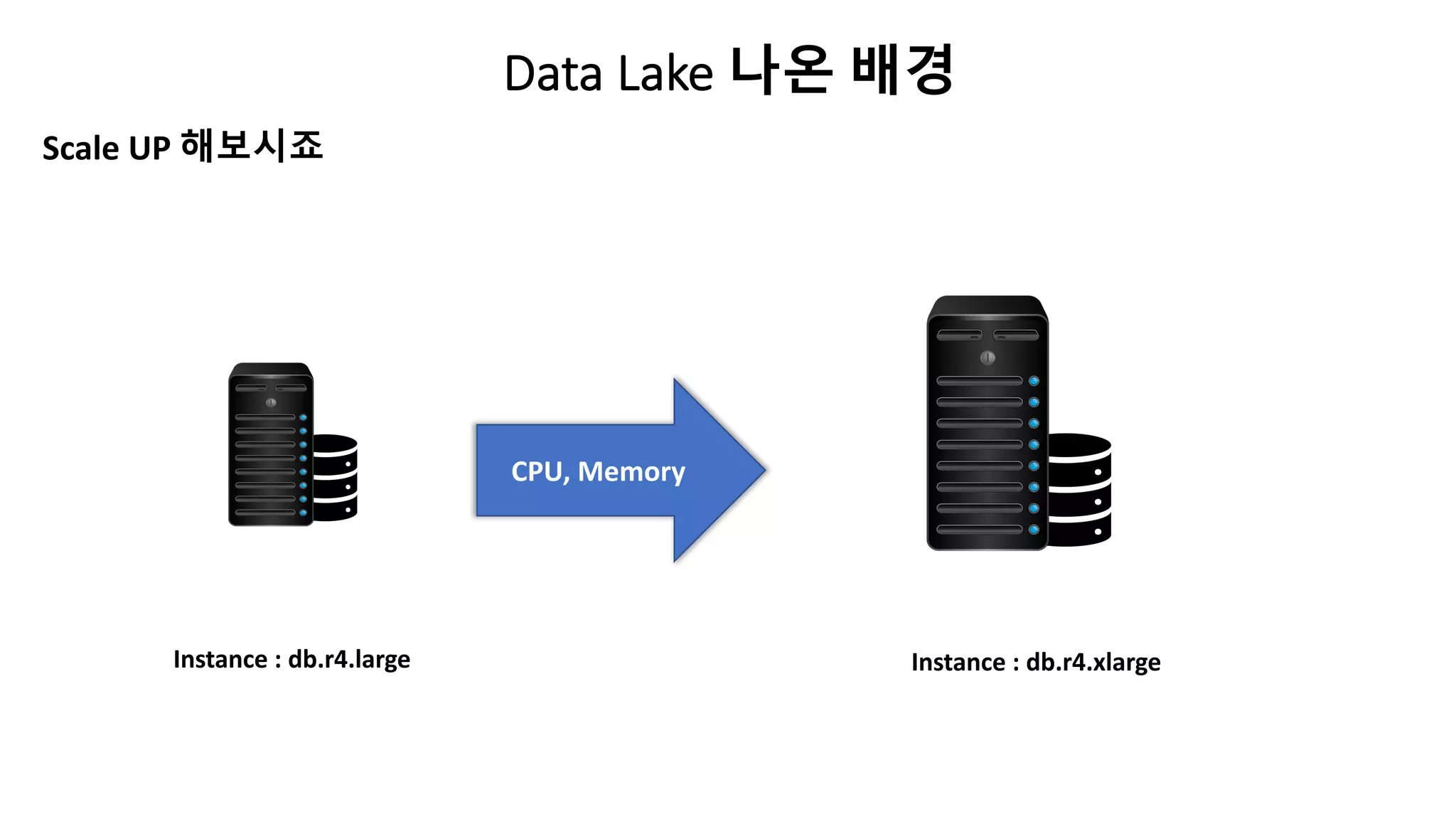
남은 문제점
1. 수집
-Push 같은 Event발생시에 RDS가 평소대비 CPU 사용량이 5배 올라감.
- Mysql 서비스에 과도한 Server 비용
- Mysql 관리가 항상 필요하다.
2. 분석
- Data Warehouse(DW) 용의 RDS 비용
- Data Warehouse(DW) 용량의 지속적 Scale UP이 필요
3. 공유
- DW 기반으로 제공Data 느리다
- 너무 늦은 시간에 데이터 공유
21
Data Lake Architecture 구성 V 0.1
22.
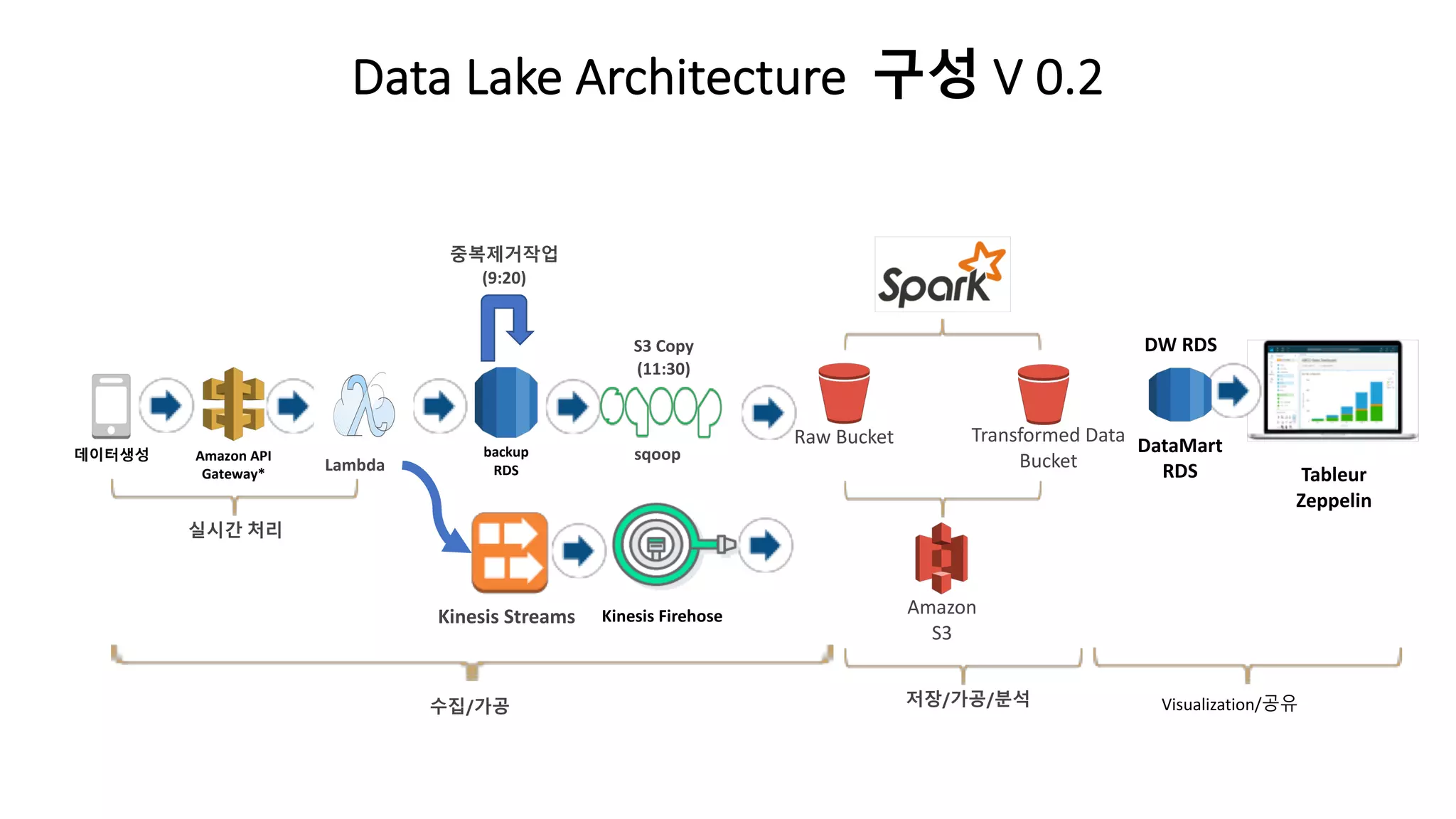
Data Lake Architecture구성 V 0.2
Transformed Data
Bucket
Raw Bucket
Amazon
S3
Lambda
Amazon API
Gateway*
데이터생성
Tableur
Zeppelin
backup
RDS
sqoop
중복제거작업
(9:20)
S3 Copy
(11:30)
수집/가공 저장/가공/분석 Visualization/공유
실시간 처리
Kinesis FirehoseKinesis Streams
DataMart
RDS
DW RDS
23.
1. 개선된 사항
ü이벤트에 의한 과도한 몰림 현상을 극복
ü 아침시간에 데이터 공유가 가능해졌다.
ü 오전에 데이터를 통한 회의가 가능해짐
2. 남은 문제
ü Cloud Tableau 서비스라 느림
ü DW 기반으로 제공 Data 느리다
ü Meta 관리가 되지 않는다.
23
Data Lake Architecture 구성 V 0.2
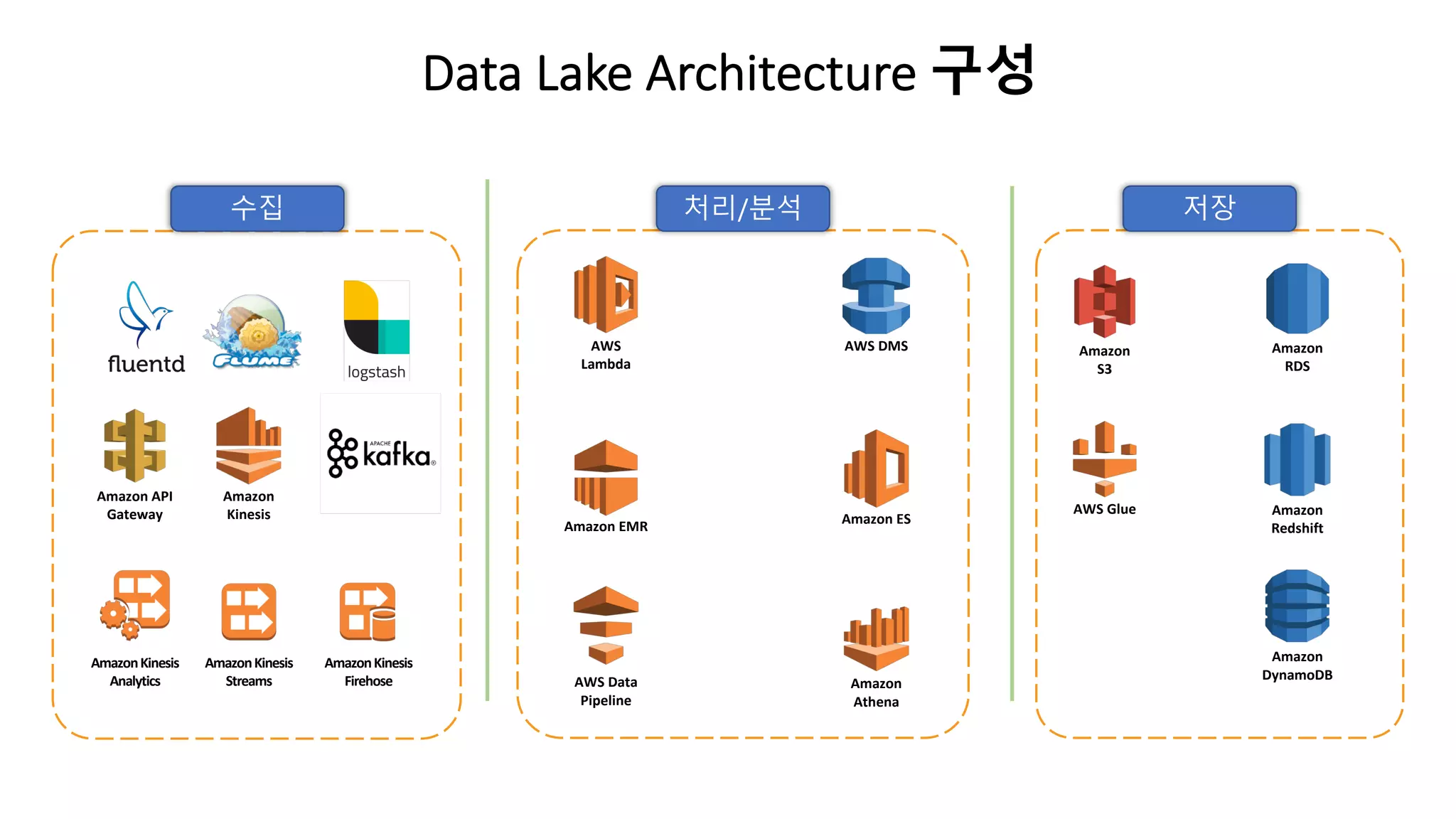
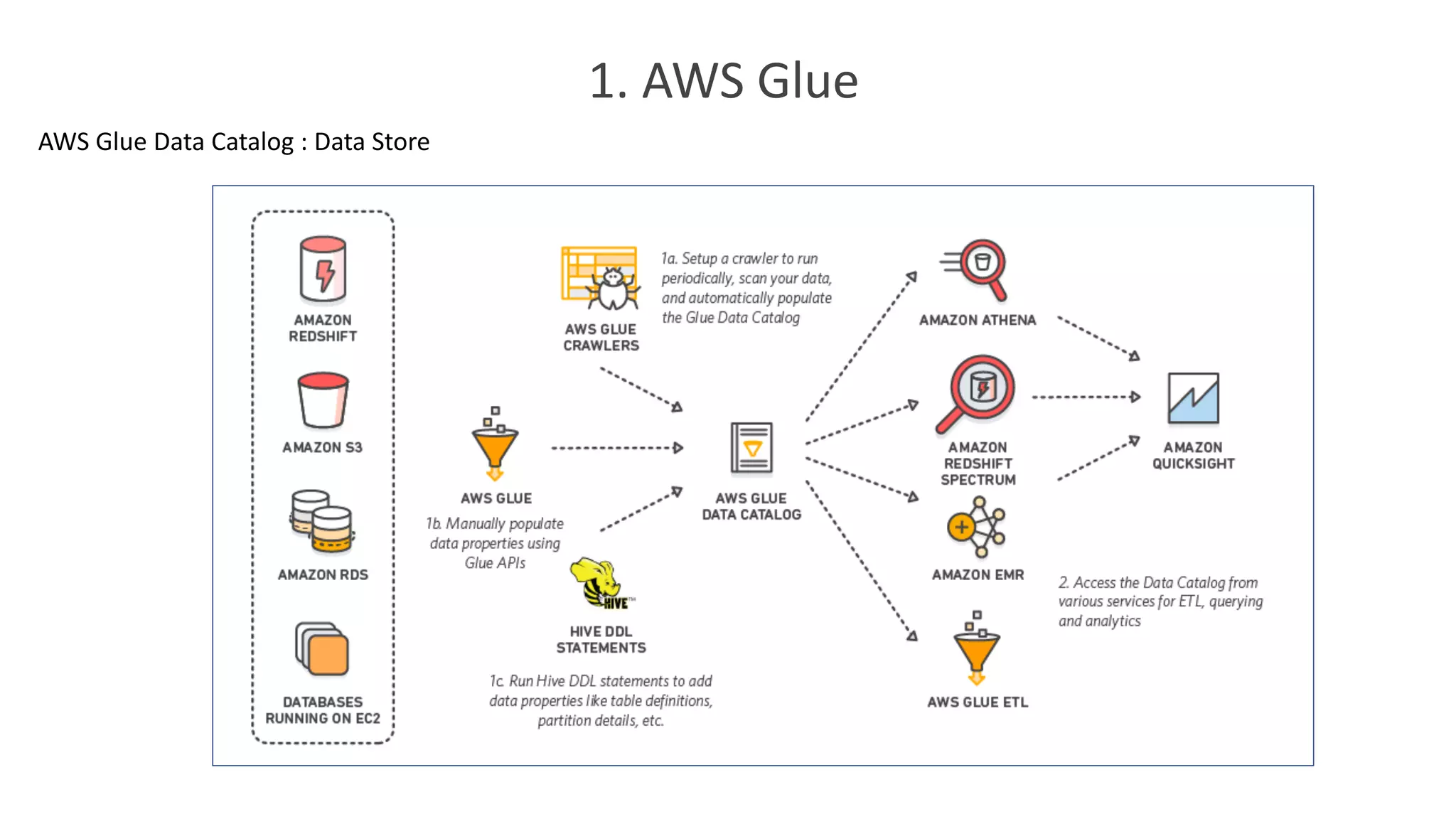
1. AWS Glue
정의:ETL(Extract Transform Load) 워크플로우를 정의하고 관리할 수 있습니다
1. Data Catalog: Meta Data Store 입니다.
2. AWS Glue Crawlers
ü 리포지토리에서 데이터를 스캔하고 분류, 스키마 정보를 추출 및 AWS Glue Data Catalog에서
자동적으로 Metadata를 저장하는 Crawlers 를 설정할 수 있습니다
3. AWS Glue ETL WorkFlow
ü AWS Glue Jobs System
ü Trigger 기능
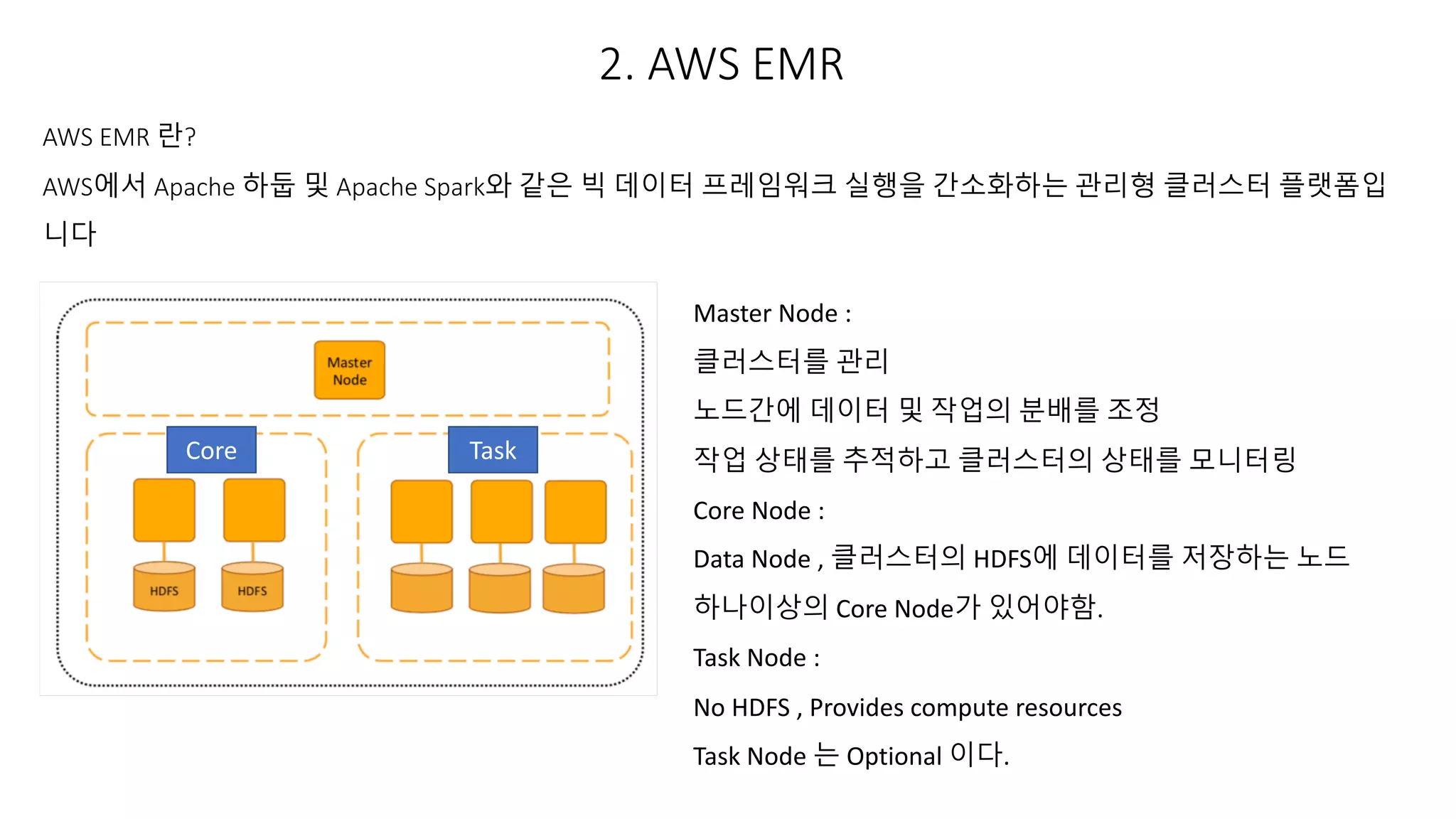
2. AWS EMR
AWSEMR 란?
AWS에서 Apache 하둡 및 Apache Spark와 같은 빅 데이터 프레임워크 실행을 간소화하는 관리형 클러스터 플랫폼입
니다
Master Node :
클러스터를 관리
노드간에 데이터 및 작업의 분배를 조정
작업 상태를 추적하고 클러스터의 상태를 모니터링
Core Node :
Data Node , 클러스터의 HDFS에 데이터를 저장하는 노드
하나이상의 Core Node가 있어야함.
Task Node :
No HDFS , Provides compute resources
Task Node 는 Optional 이다.
Core Task
29.
29
ü EMR Cluster를종료 후에 다시 신규 EMR Cluster를 구성해도 기존데이터를 읽을 수 있다.
ü HDFS의 용량 확장에 대해서 신경을 쓰지 않아도 된다.
ü Both in IOPs and data storage
ü Amazon guarantees ... 11 x 9's" durability
ü Build elastic clusters
• Add nodes to read from Amazon S3
• Remove nodes with data safe on Amazon S3
HDFS로 S3를 사용했을 때의 장점
2. AWS EMR
Batch-Processing
Engine
Real-Time
Processing Engine
데이터생성 Visualization
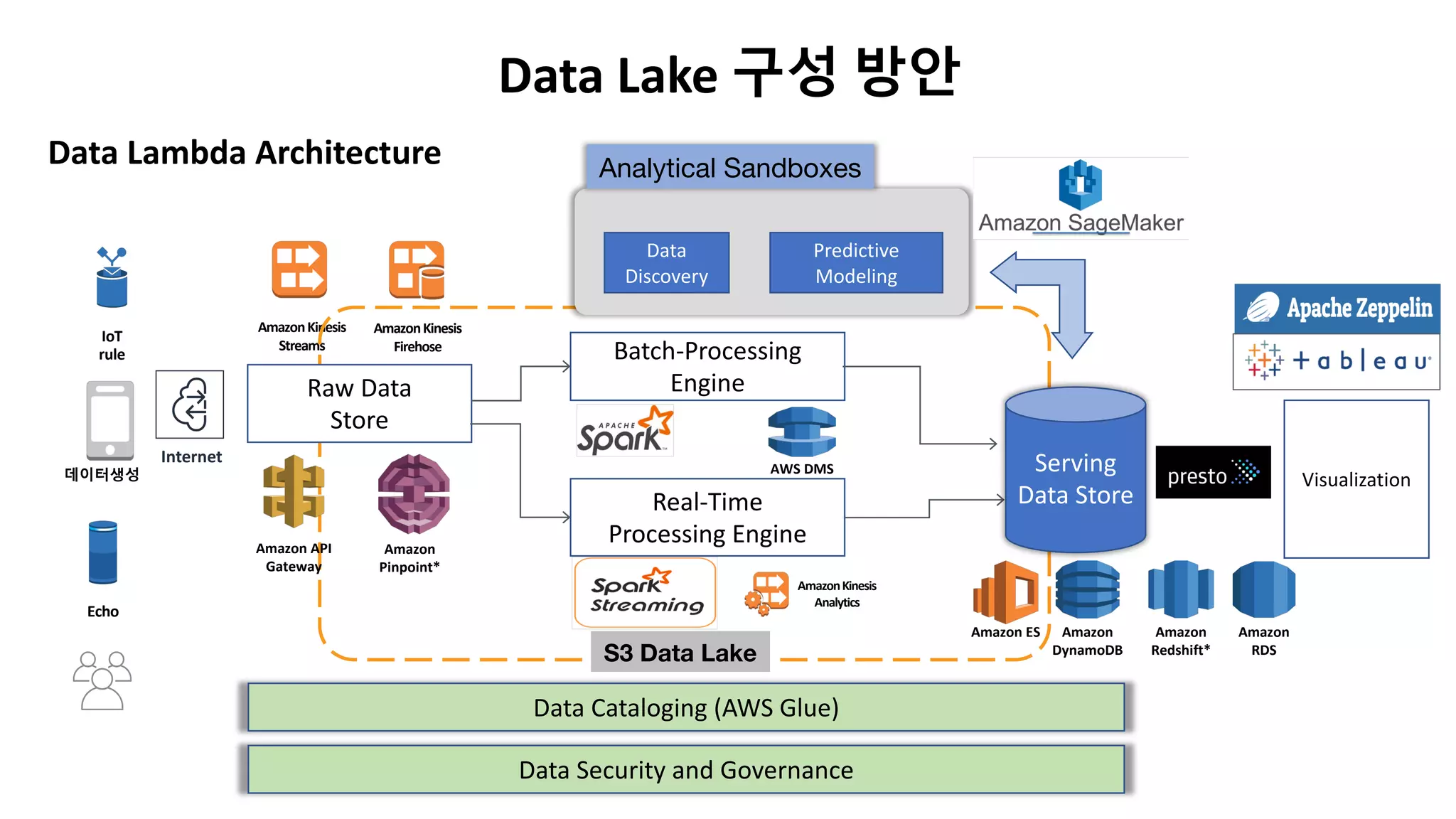
DataCataloging (AWS Glue)
Data Security and Governance
Echo
IoT
rule
Data Lake 구성 방안
Amazon ES Amazon
Redshift*
AmazonKinesis
Firehose
AmazonKinesis
Streams
AmazonKinesis
Analytics
AWS DMS
Amazon
DynamoDB
Amazon
RDSS3 Data Lake
Raw Data
Store
Amazon
Pinpoint*
Analytical Sandboxes
Data
Discovery
Predictive
Modeling
Internet
Amazon API
Gateway
Data Lambda Architecture
Serving
Data Store
32.
1. Bigdata 분석환경
ü Cloud를 사용하라
ü Cloud 장점인 Infra를 Coding 하라.
2. 저장
ü S3에 저장하라
ü 모든 데이터(sns, 사진, 비디오 등)를 저장하라
ü 압축하라(Parquet 형식으로 저장)
ü Partitioning 하라
3. 분석
ü Serverless를 추구
ü EMR 활용시 Spot Instance 를 최대한 활용하라
4. Governance
ü Metadata 관리 ( AWS Glue )
Data Lake 구성 방안
32
































![[2019] PAYCO 쇼핑 마이크로서비스 아키텍처(MSA) 전환기](https://cdn.slidesharecdn.com/ss_thumbnails/nhnforward201926-200122093003-thumbnail.jpg?width=640&height=640&fit=bounds)







![[AWSマイスターシリーズ] Amazon ElastiCache](https://cdn.slidesharecdn.com/ss_thumbnails/20131030aws-meister-regenerate-elasticache-131101003447-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AWS Builders] AWS상의 보안 위협 탐지 및 대응](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuilders300security-190611112644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)




![[Retail & CPG Day 2019] AWS기반의 Data 분석 플랫폼 구축, 고객사례 (GS SHOP) -김형일, AWS 솔루션즈 ...](https://cdn.slidesharecdn.com/ss_thumbnails/gsshop-191024042351-thumbnail.jpg?width=640&height=640&fit=bounds)







![[E-commerce & Retail Day] Data Freedom을 위한 Database 최적화 전략](https://cdn.slidesharecdn.com/ss_thumbnails/datafreedomdatabase-171027021754-thumbnail.jpg?width=640&height=640&fit=bounds)






