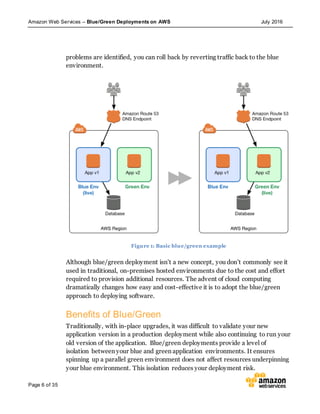
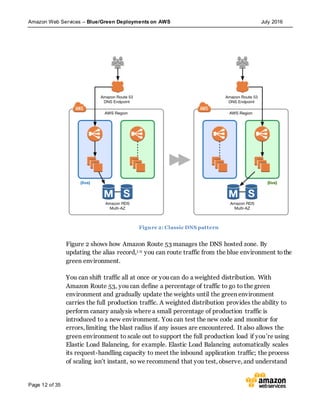
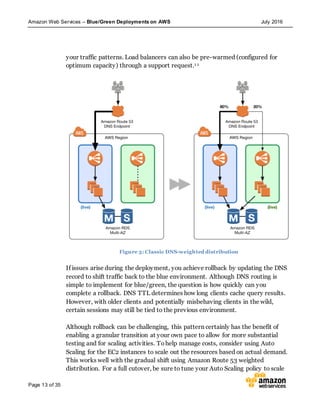
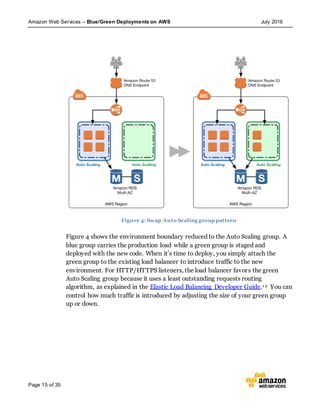
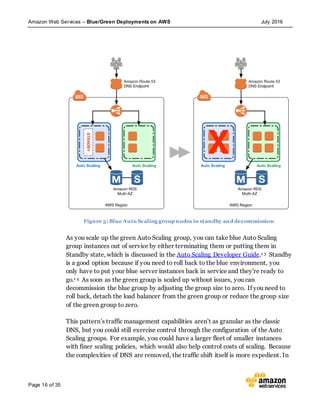
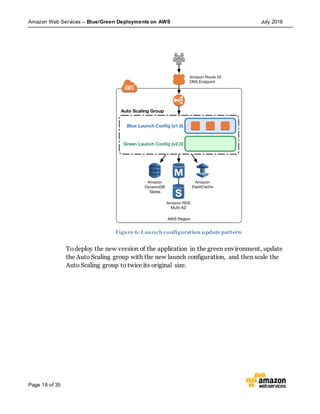
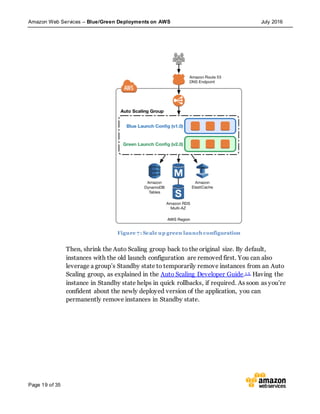
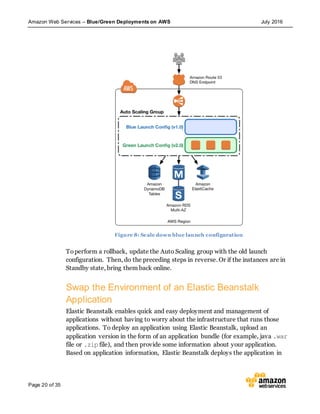
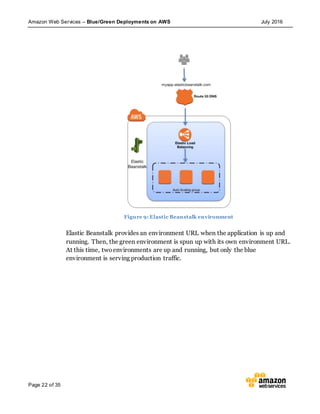
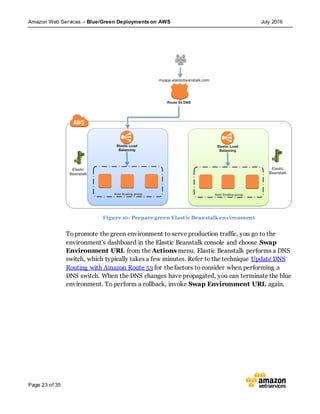
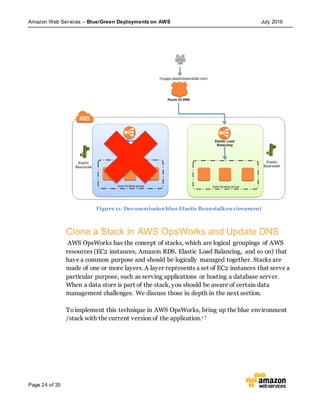
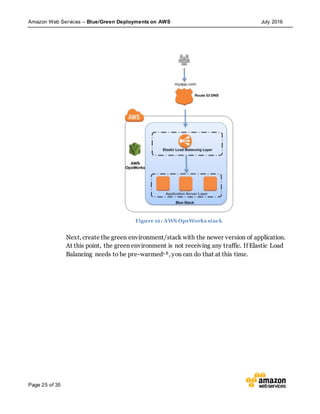
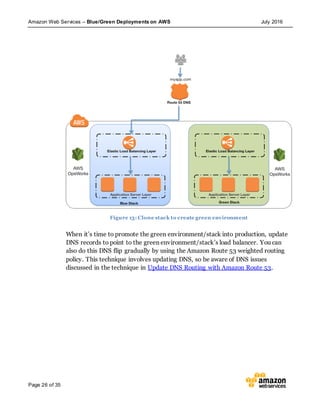
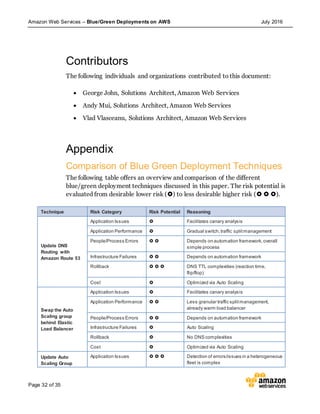
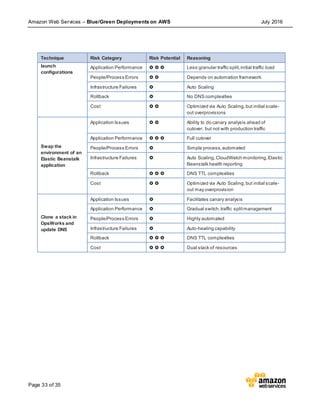
This document discusses blue/green deployments on AWS. Blue/green deployments allow near zero downtime releases and rollbacks by shifting traffic between two identical environments running different application versions (blue and green). The document describes how AWS services like Route 53, ELB, Auto Scaling, Elastic Beanstalk, OpsWorks, and CloudFormation can enable blue/green techniques. It also addresses considerations for managing data with deployments.