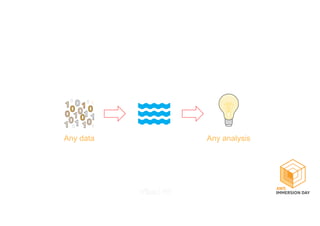
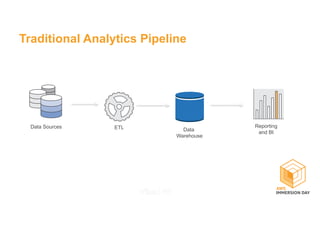
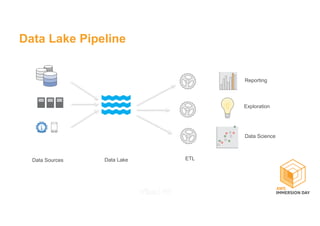
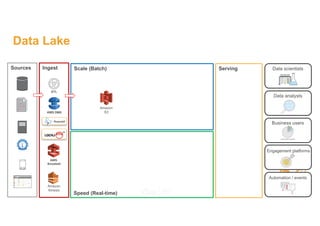
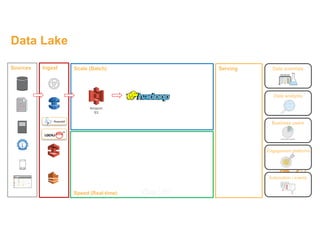
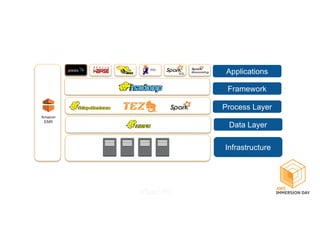
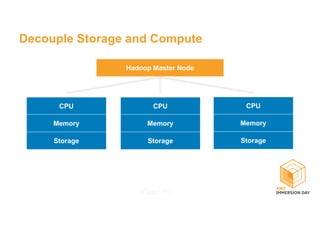
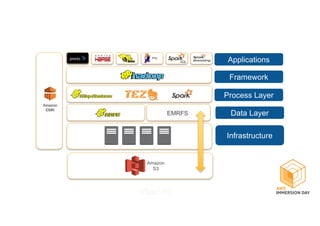
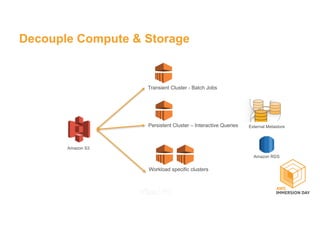
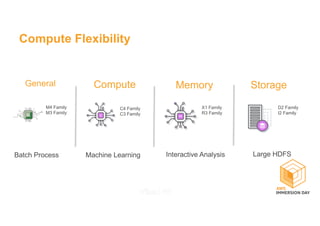
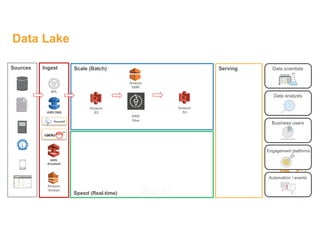
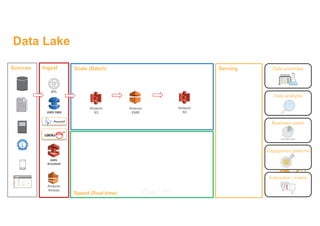
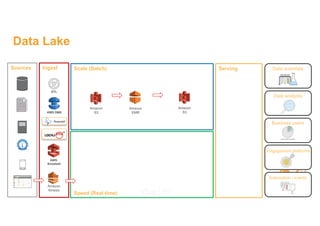
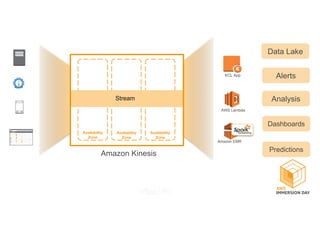
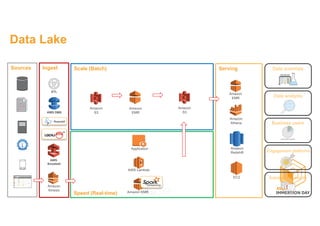
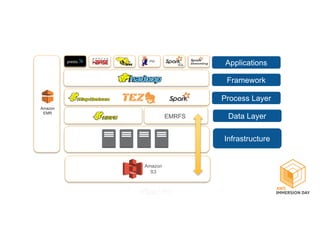
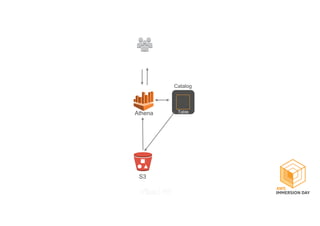
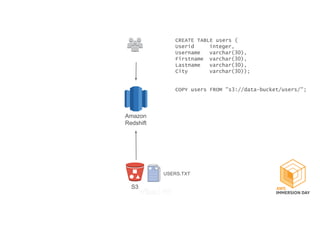
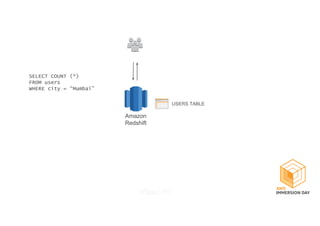
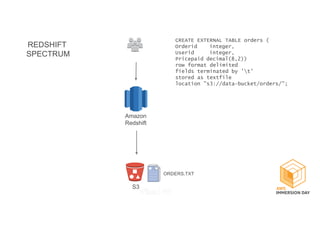
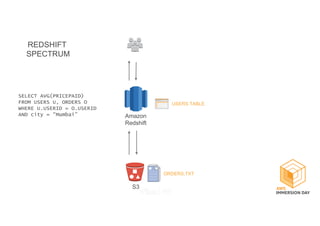
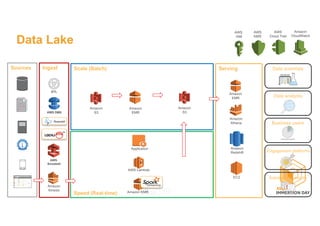
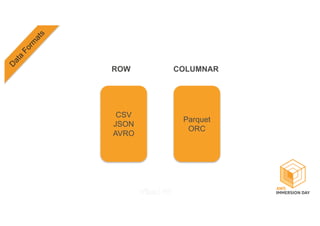
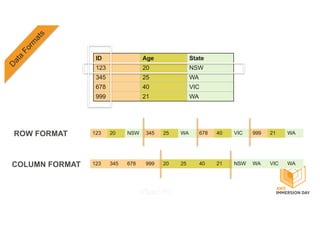
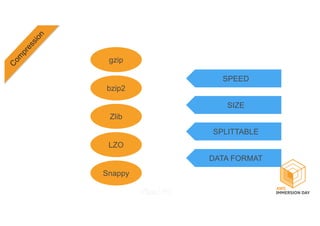
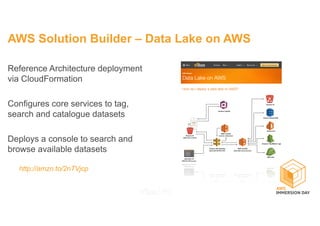
This document discusses building a data lake on AWS. It describes how AWS services like S3, EMR, Glue, Kinesis, Athena and Redshift can be used together to build a scalable data lake for ingesting, storing, processing, analyzing and serving data at any scale. It provides architectures for batch and real-time data ingestion and processing, and interactive analysis on the data lake. Best practices around data formats, compression and partitioning are also covered.