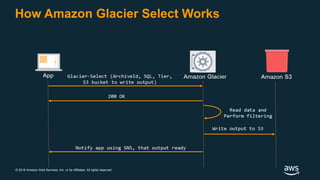
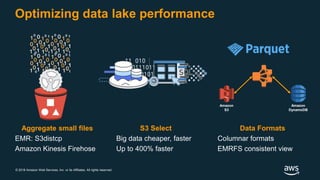
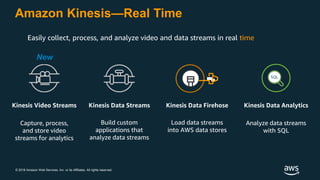
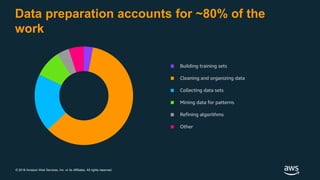
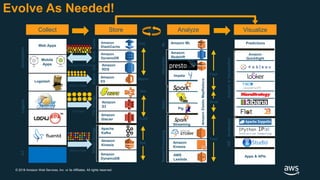
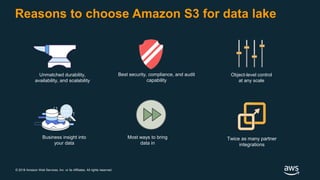
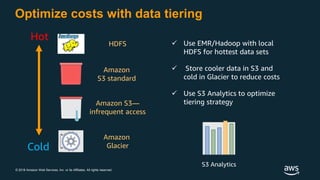
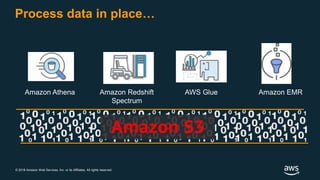
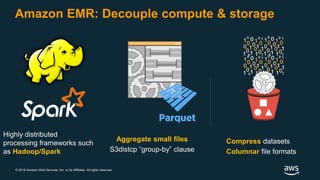
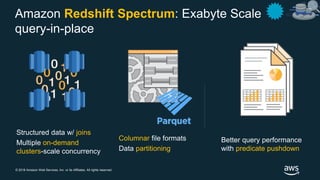
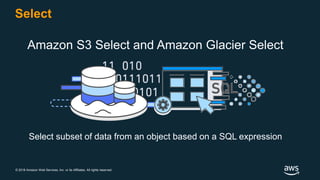
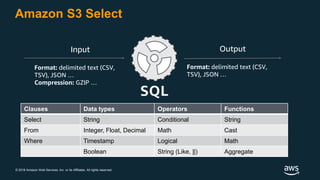
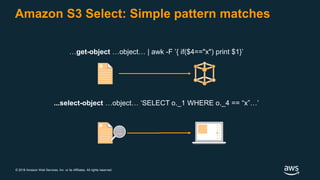
The document discusses building a data lake on AWS. It defines a data lake and its key attributes. It outlines components of the AWS data lake including storage, data movement, analytics, and machine learning services. It provides strategies for reducing costs such as data tiering and processing data in place using services like Amazon S3 Select, EMR, Redshift Spectrum, and Athena. It also discusses optimizing performance through techniques like aggregating small files and using columnar data formats. Finally, it encourages planning for the future by evolving solutions as needs change.











![© 2018 Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Before
200 seconds and 11.2 cents
# Download and process all keys
for key in src_keys:
response = s3_client.get_object(Bucket=src_bucket, Key=key)
contents = response['Body'].read()
for line in contents.split('n')[:-1]:
line_count +=1
try:
data = line.split(',')
srcIp = data[0][:8]
….
Amazon S3 Select: Serverless MapReduce
After
95 seconds and costs 2.8 cents
# Select IP Address and Keys
for key in src_keys:
response = s3_client.select_object_content
(Bucket=src_bucket, Key=key, expression =
SELECT SUBSTR(obj._1, 1, 8), obj._2 FROM s3object as obj)
contents = response['Body'].read()
for line in contents:
line_count +=1
try:
….
2X Faster at 1/5 of the cost](https://image.slidesharecdn.com/buildingyourdataprojectonaws-lukeanderson-230216121531-bc571ee3/85/Building-your-Data-Project-on-AWS-Luke-Anderson-pdf-22-320.jpg)