Downloaded 29 times






















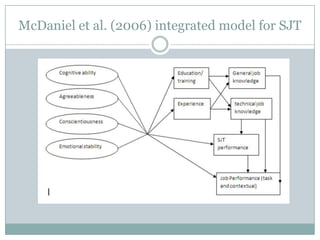








Situational judgment tests (SJTs) present respondents with hypothetical scenarios and ask for appropriate responses. Research shows SJTs have incremental validity over cognitive ability and personality in predicting job performance. However, SJTs measure multiple constructs heterogeneously and their reliability is unclear due to their multidimensional nature. While SJTs show promise, more research is needed to better understand their construct validity, address issues like susceptibility to faking, and enhance theoretical development and experimental design. Future directions include developing SJTs targeted to specific constructs and exploring their use in teams and training contexts.








































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)















