Download to read offline





















]
): TraversableOnce[Feature[S]]
// …
}](https://image.slidesharecdn.com/automatedbenchmarkmanagement-171023183835/75/Automating-the-Generation-of-Benchmark-Suites-35-2048.jpg)
]
): TraversableOnce[Feature[S]]
// …
}
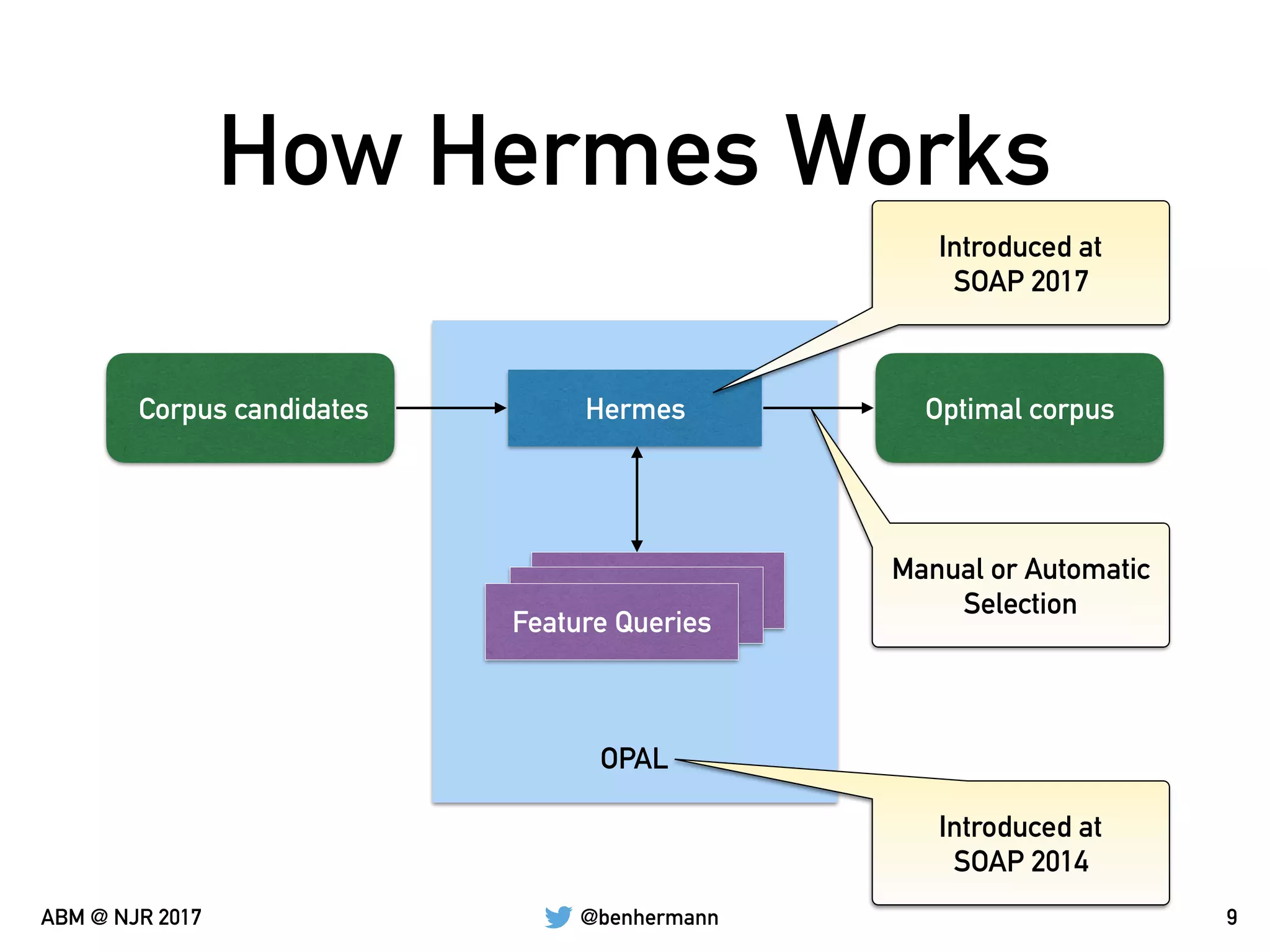
Identifier,
Project JAR Files,
Library JAR Files,
Statistics](https://image.slidesharecdn.com/automatedbenchmarkmanagement-171023183835/75/Automating-the-Generation-of-Benchmark-Suites-36-2048.jpg)
]
): TraversableOnce[Feature[S]]
// …
}
Identifier,
Project JAR Files,
Library JAR Files,
Statistics
Complete reified
project information
(classes, fields,
methods, bodys, etc.)](https://image.slidesharecdn.com/automatedbenchmarkmanagement-171023183835/75/Automating-the-Generation-of-Benchmark-Suites-37-2048.jpg)
]
): TraversableOnce[Feature[S]]
// …
}
Identifier,
Project JAR Files,
Library JAR Files,
Statistics
Complete reified
project information
(classes, fields,
methods, bodys, etc.)
Raw class file information
(e.g., for extracting
information from the
constant pool)](https://image.slidesharecdn.com/automatedbenchmarkmanagement-171023183835/75/Automating-the-Generation-of-Benchmark-Suites-38-2048.jpg)
]
): TraversableOnce[Feature[S]]
// …
}
Identifier,
Project JAR Files,
Library JAR Files,
Statistics
Complete reified
project information
(classes, fields,
methods, bodys, etc.)
Raw class file information
(e.g., for extracting
information from the
constant pool)List of detected features in
the codebase (id, frequency
of occurrence, (opt.)
locations)](https://image.slidesharecdn.com/automatedbenchmarkmanagement-171023183835/75/Automating-the-Generation-of-Benchmark-Suites-39-2048.jpg)



![@benhermannABM @ NJR 2017
Constructing a Minimal
Corpus
• Dead-Path Analysis [FSE15]
• Original evaluation conducted on the complete Qualitas
Corpus
• Minimal corpus only consists of 5 out of the 100
projects in the Qualitas Corpus
• Evaluation cut down from 16.77 minutes to 2.82
minutes (~6x faster) while coverage is only 1.06% below
the original corpus
13](https://image.slidesharecdn.com/automatedbenchmarkmanagement-171023183835/75/Automating-the-Generation-of-Benchmark-Suites-44-2048.jpg)



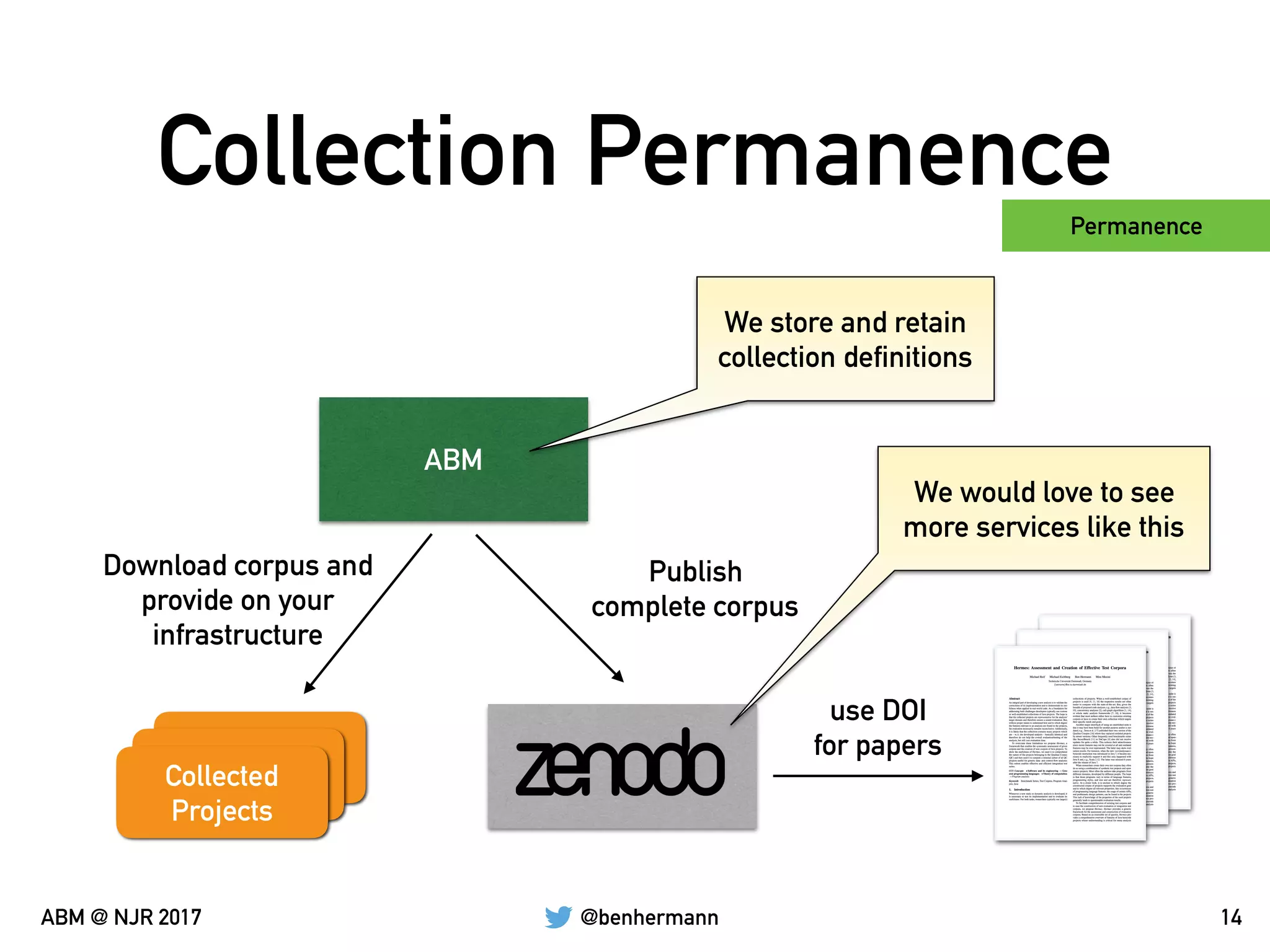



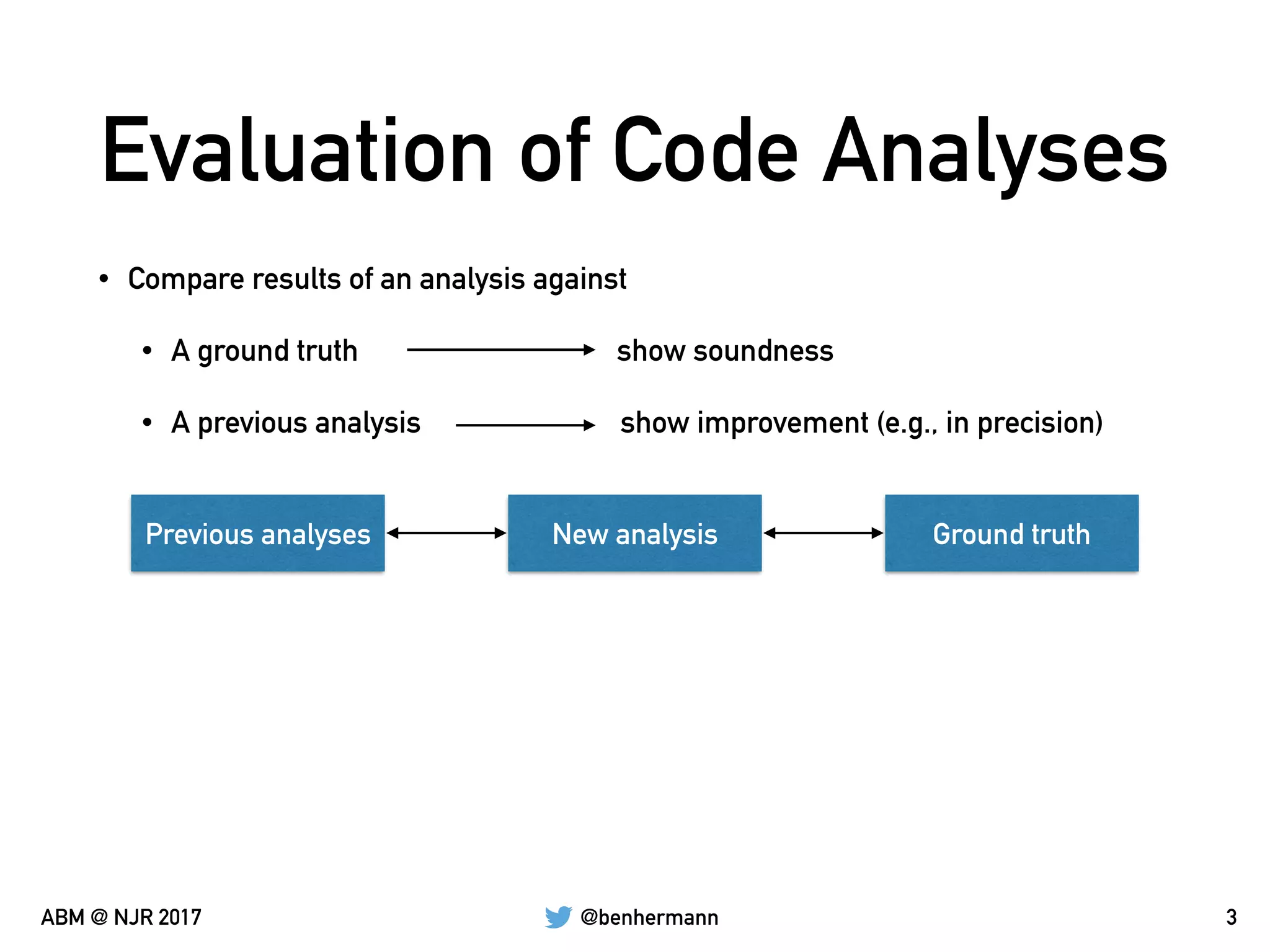
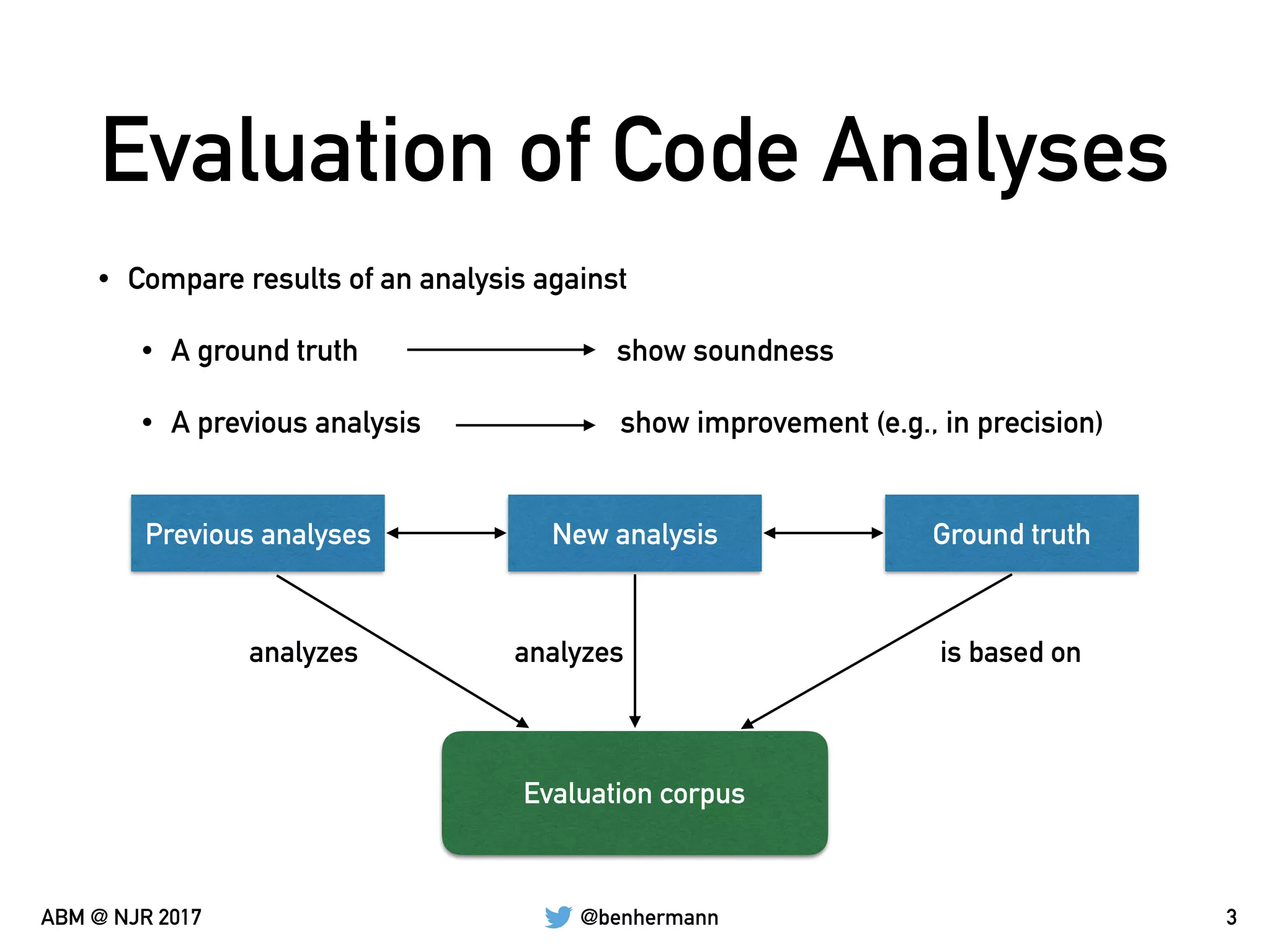
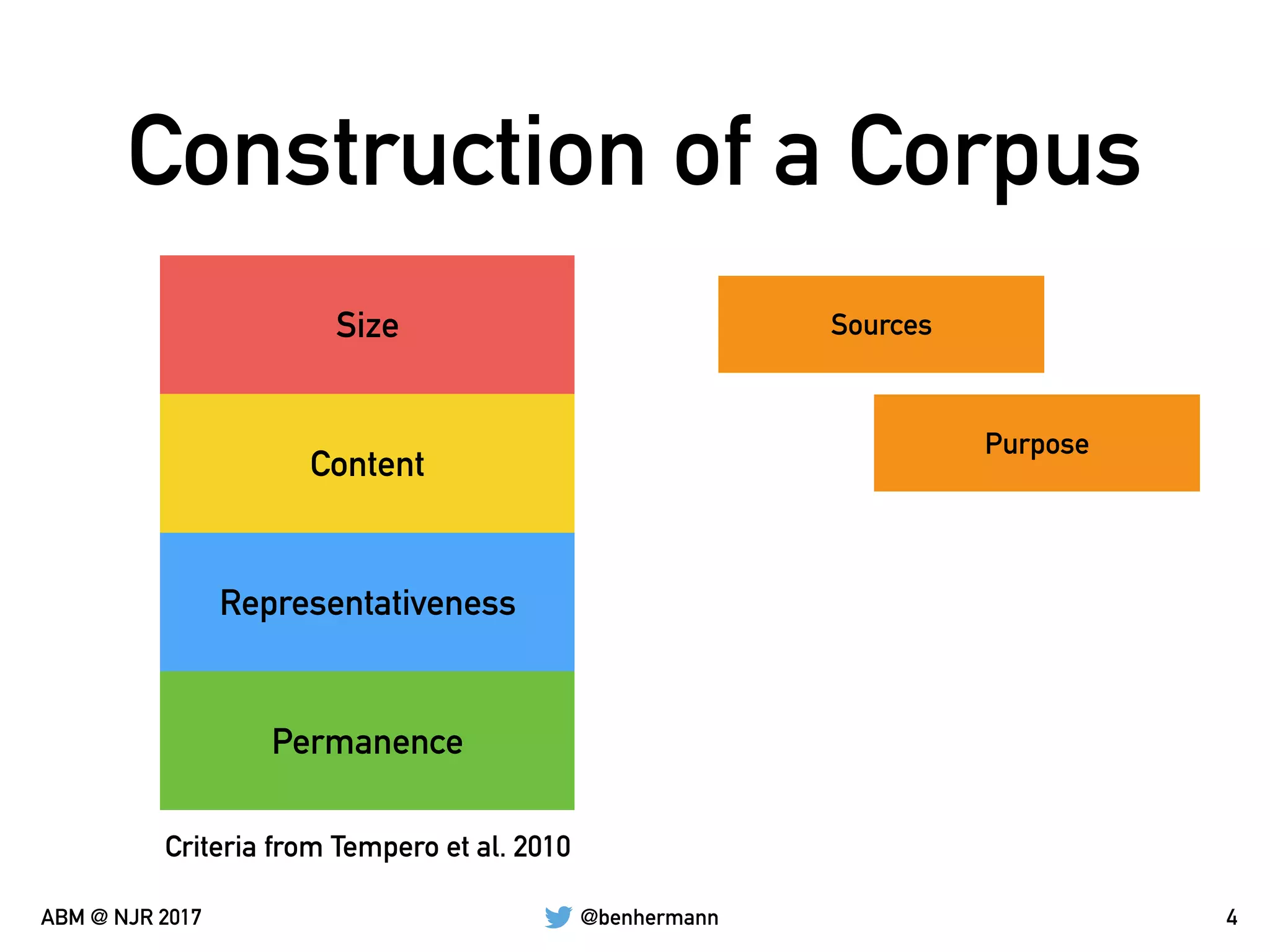
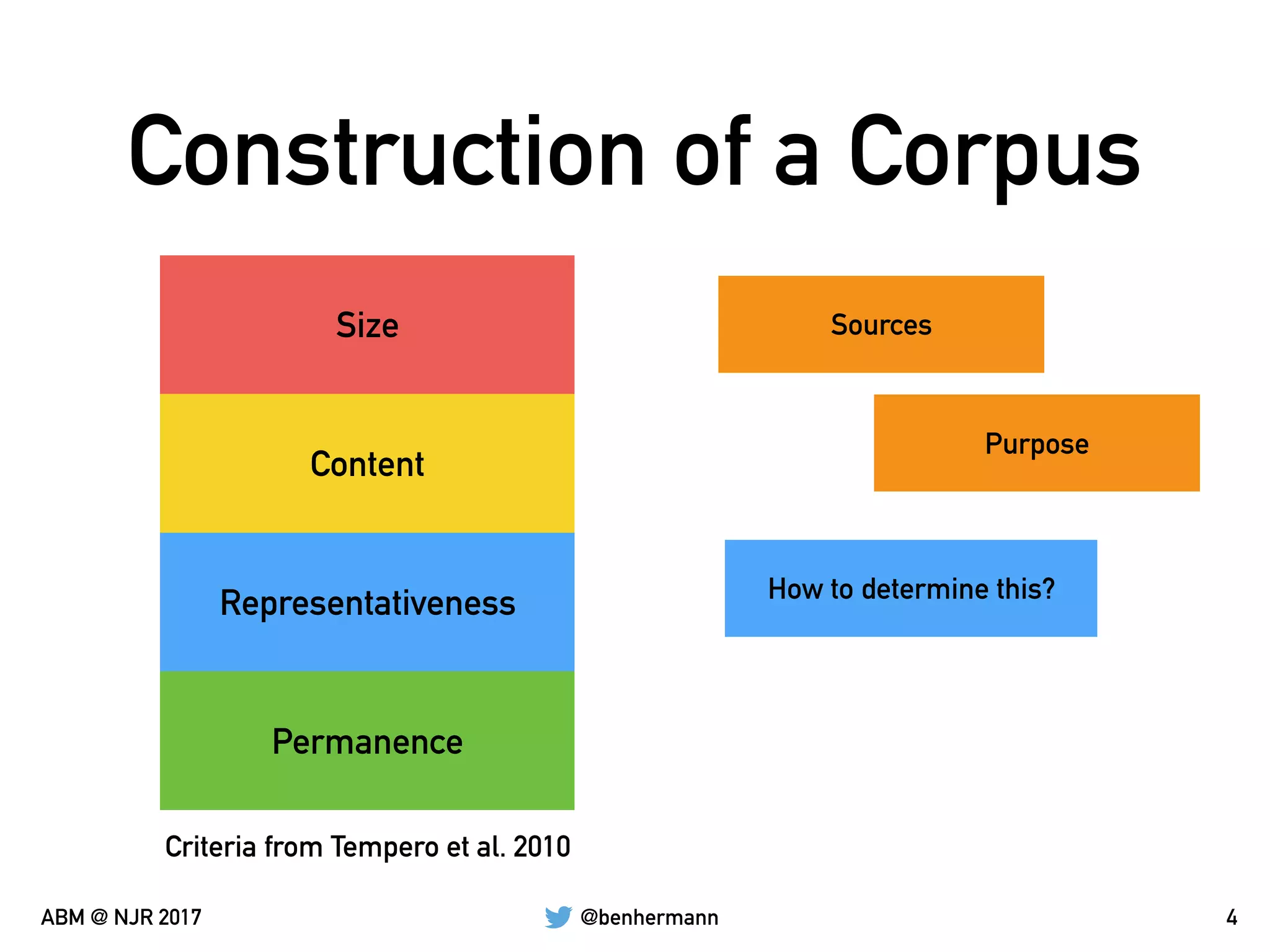
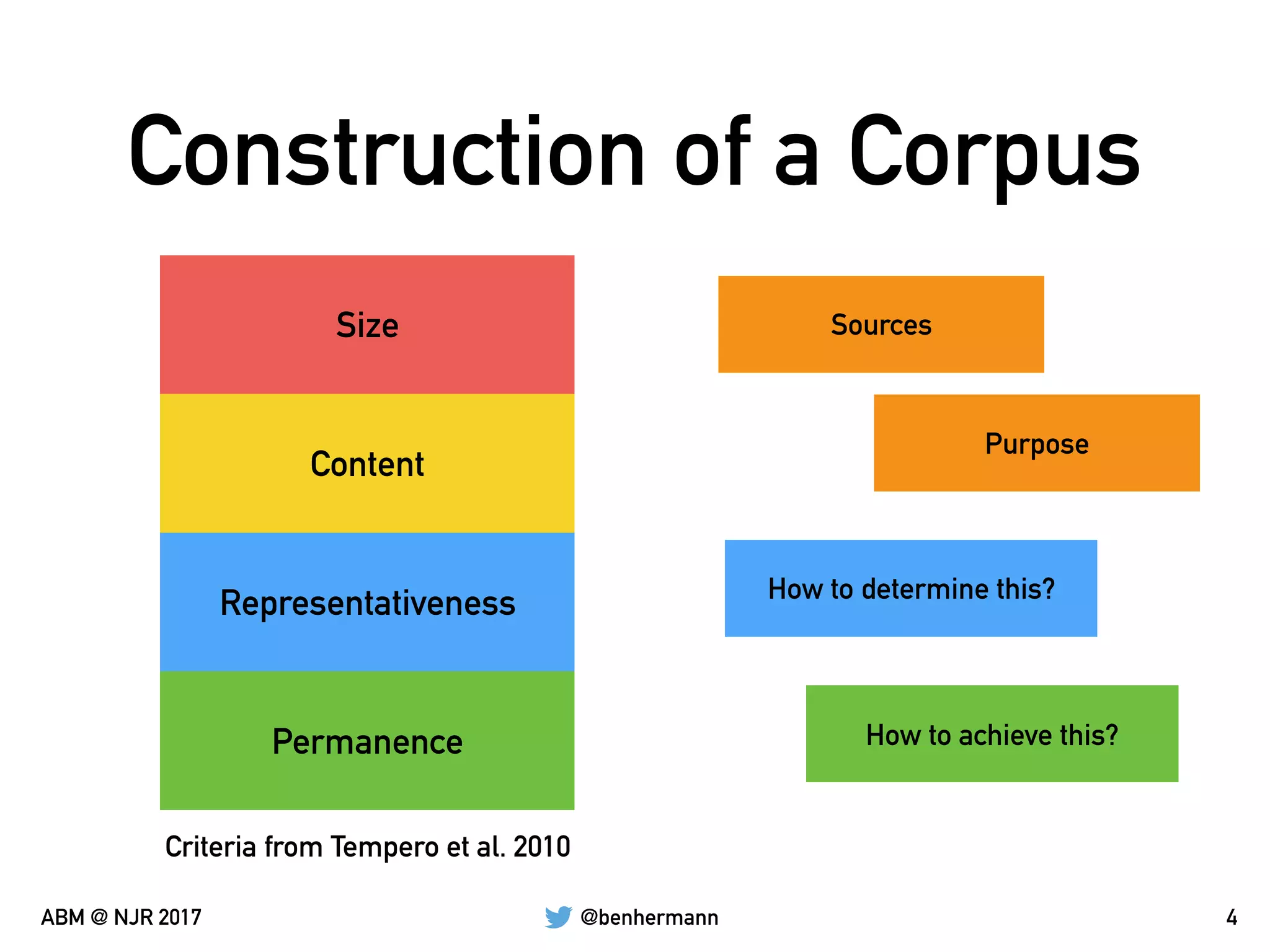
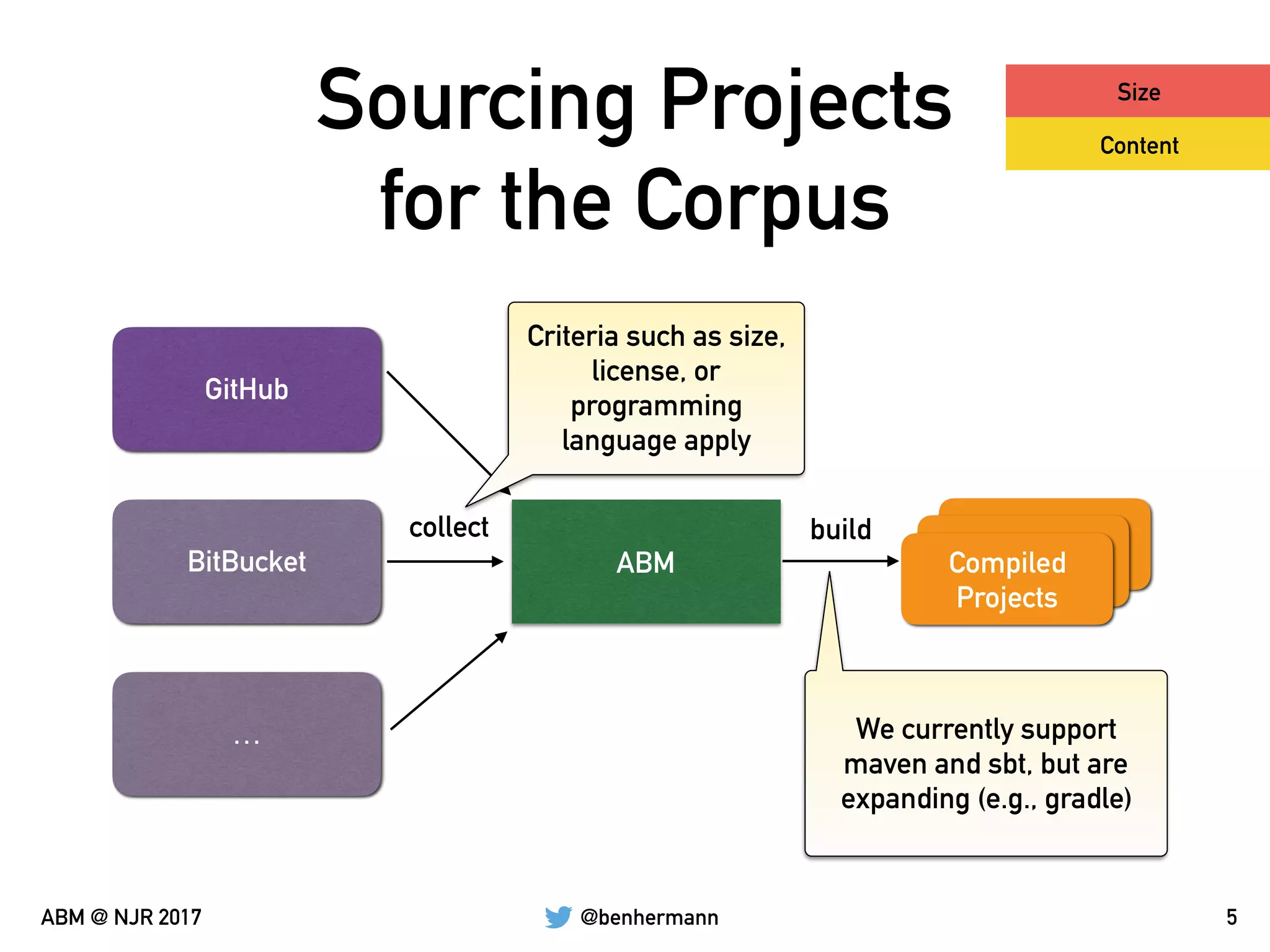
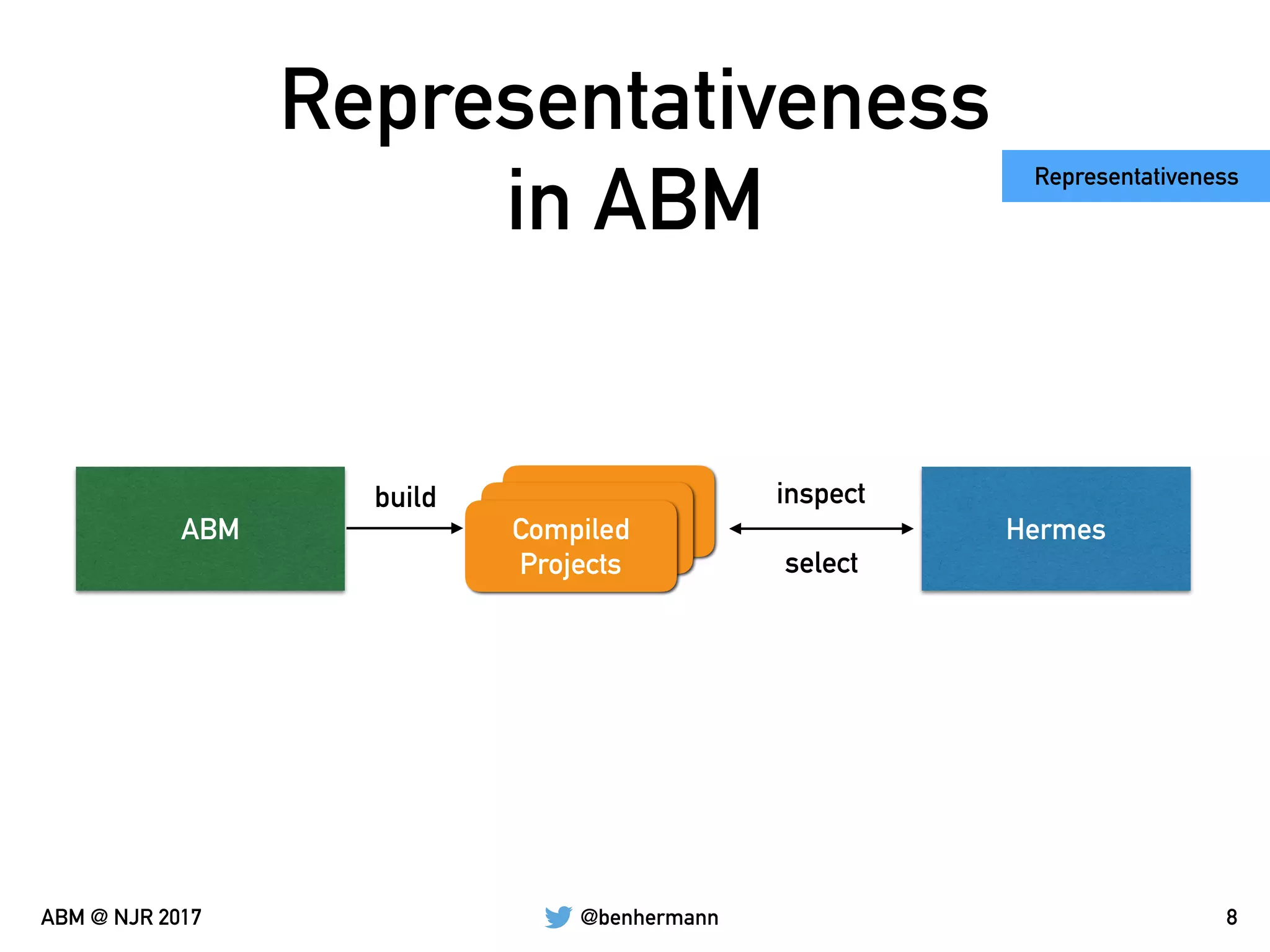
The document discusses the automation of generating benchmark suites and the construction of evaluation corpuses for code analyses. It emphasizes the importance of criteria such as size, content, representativeness, and permanence in creating effective test corpuses. Additionally, it highlights the use of algorithms to analyze a representative set of Java libraries and the strategies for sourcing and managing these corpuses.







































![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)

