Download as PDF, PPTX








![DEEP NEURAL NETWORK
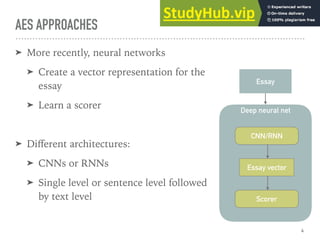
➤ Some variations yielded worse results
➤ Max pooling instead of mean
➤ CNNs instead of LSTMs
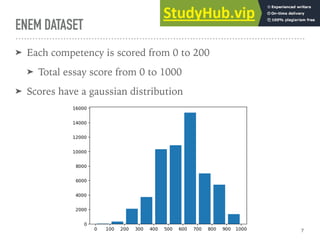
➤ The network outputs 5 scores
➤ Sigmoid activation; normalize scores to range [0, 1]
➤ Extra hidden layers did not help
➤ Optimize the Mean Squared Errors:
12
5
∑
i
(yi − ̂
yi)2](https://image.slidesharecdn.com/automaticallygradingbrazilianstudentessays-230807180202-041b2b31/85/Automatically-Grading-Brazilian-Student-Essays-pdf-12-320.jpg)




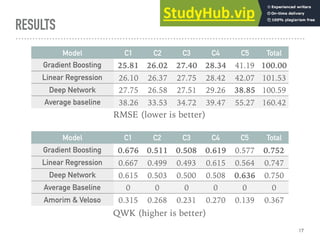




This document discusses automatically grading Brazilian student essays. It compares using feature-based models versus deep neural networks for automatic essay scoring (AES). The researchers tested both approaches on a dataset of over 56,000 graded Brazilian student essays. Their results found that feature-based models performed better on competencies related to writing mechanics, while neural networks performed better on a more subjective competency. Overall, the models achieved comparable performance to the limited prior work on AES in Portuguese and provide promising approaches, though the field is still developing.
























![[DSC Europe 23] Dmitry Ustalov - Design and Evaluation of Large Language Models](https://cdn.slidesharecdn.com/ss_thumbnails/dmitryustalov-designandevaluationofllms-231128235048-b0b24f5d-thumbnail.jpg?width=640&height=640&fit=bounds)










































