Downloaded 14 times




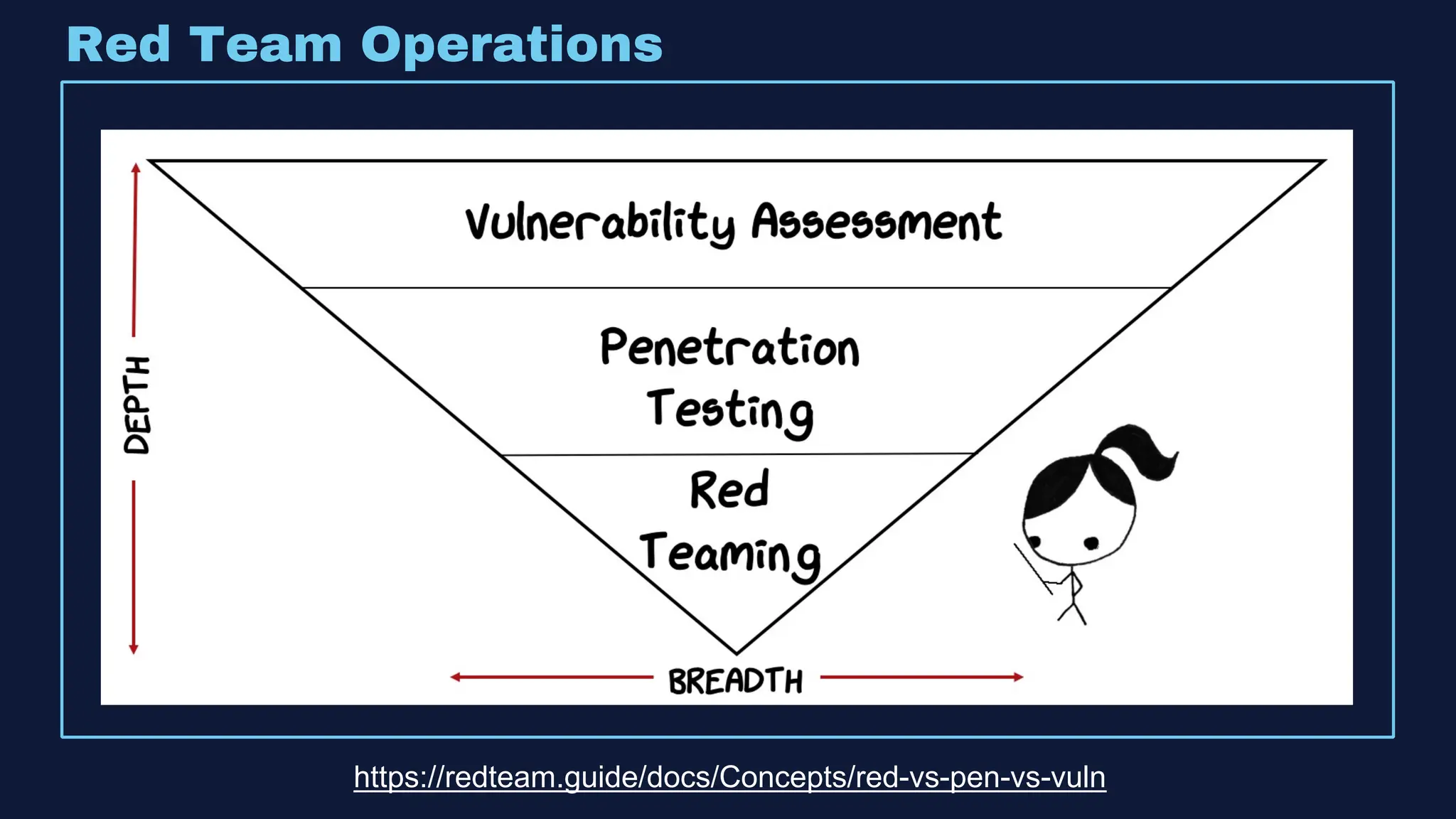

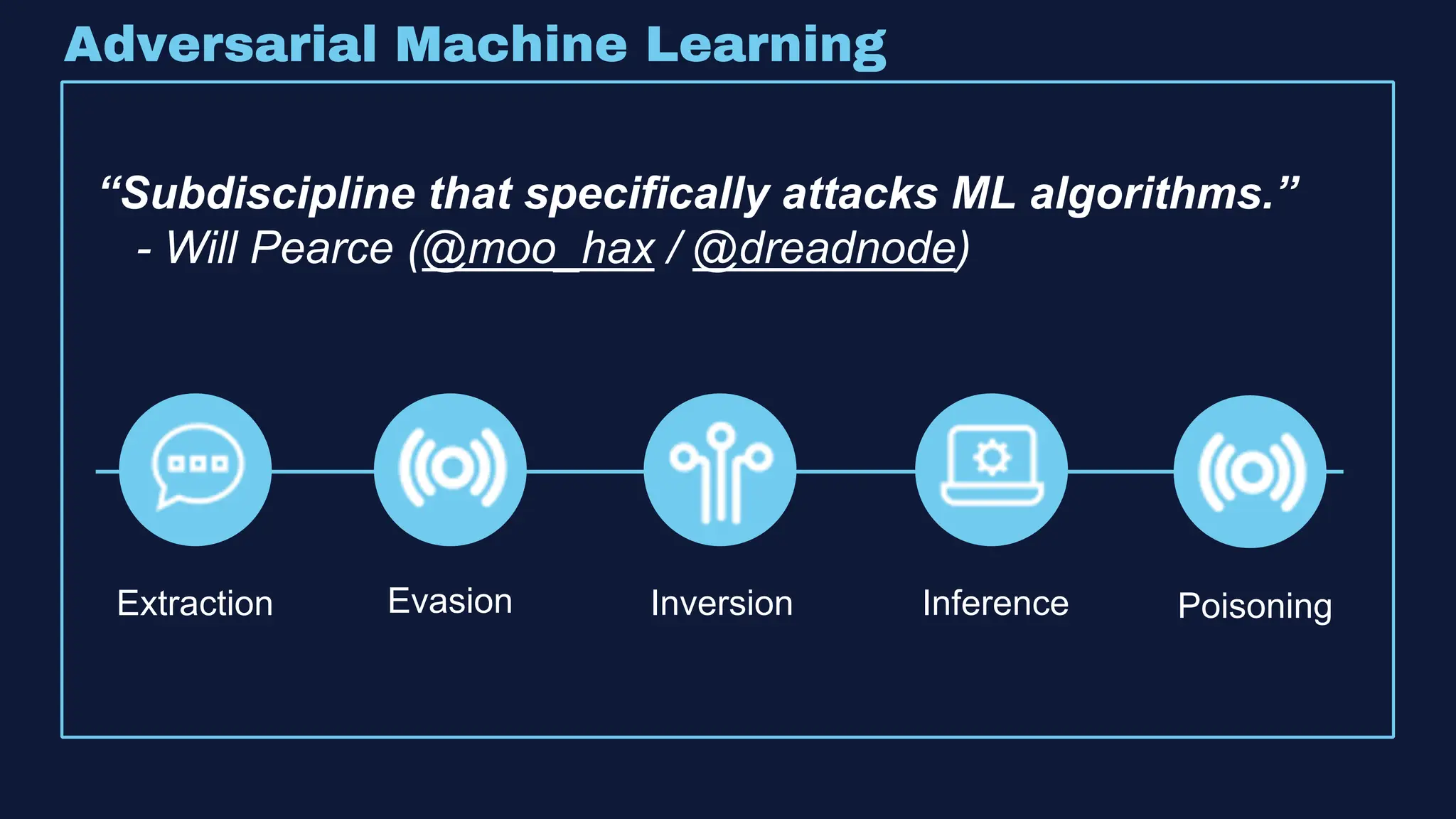

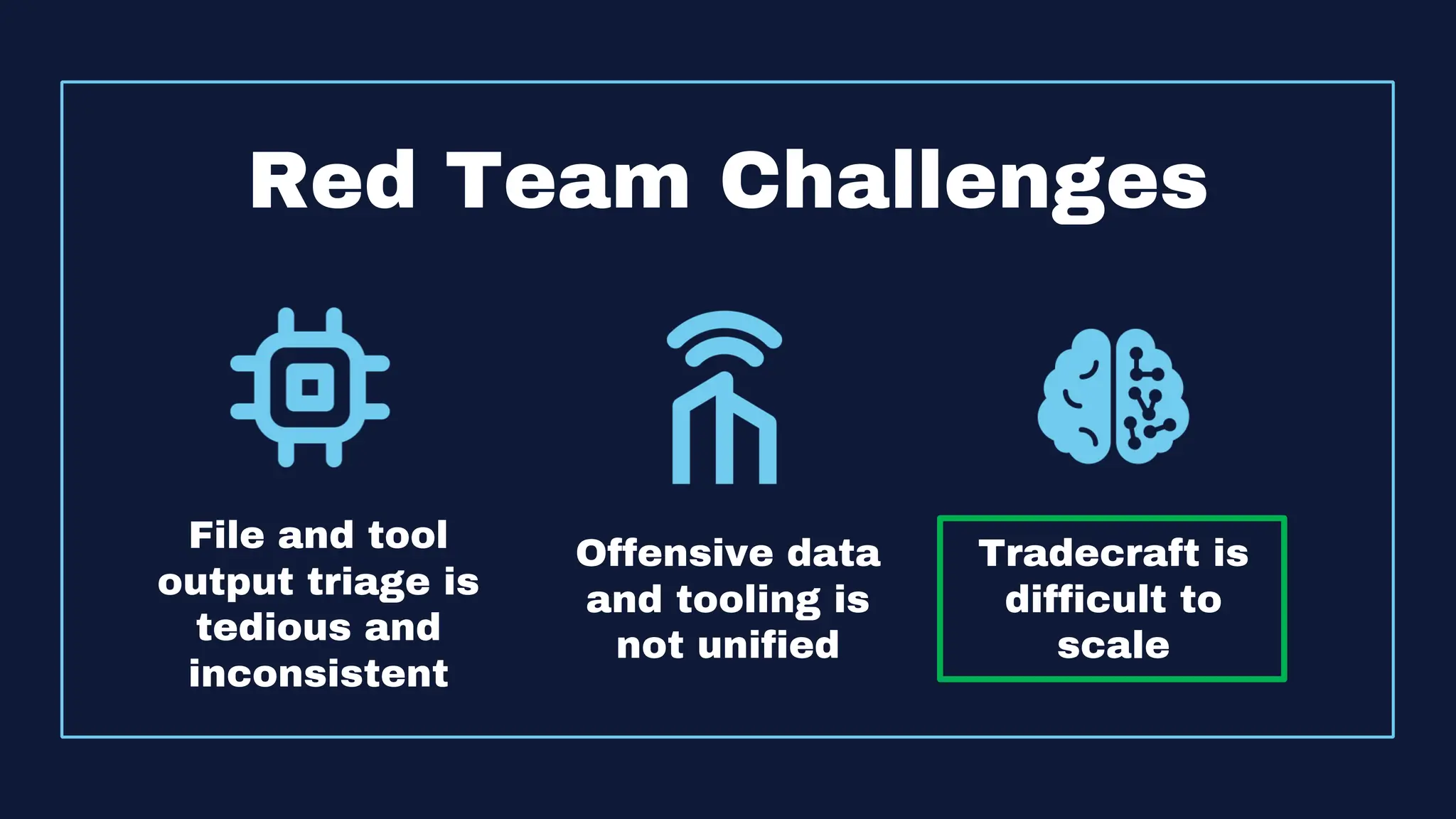


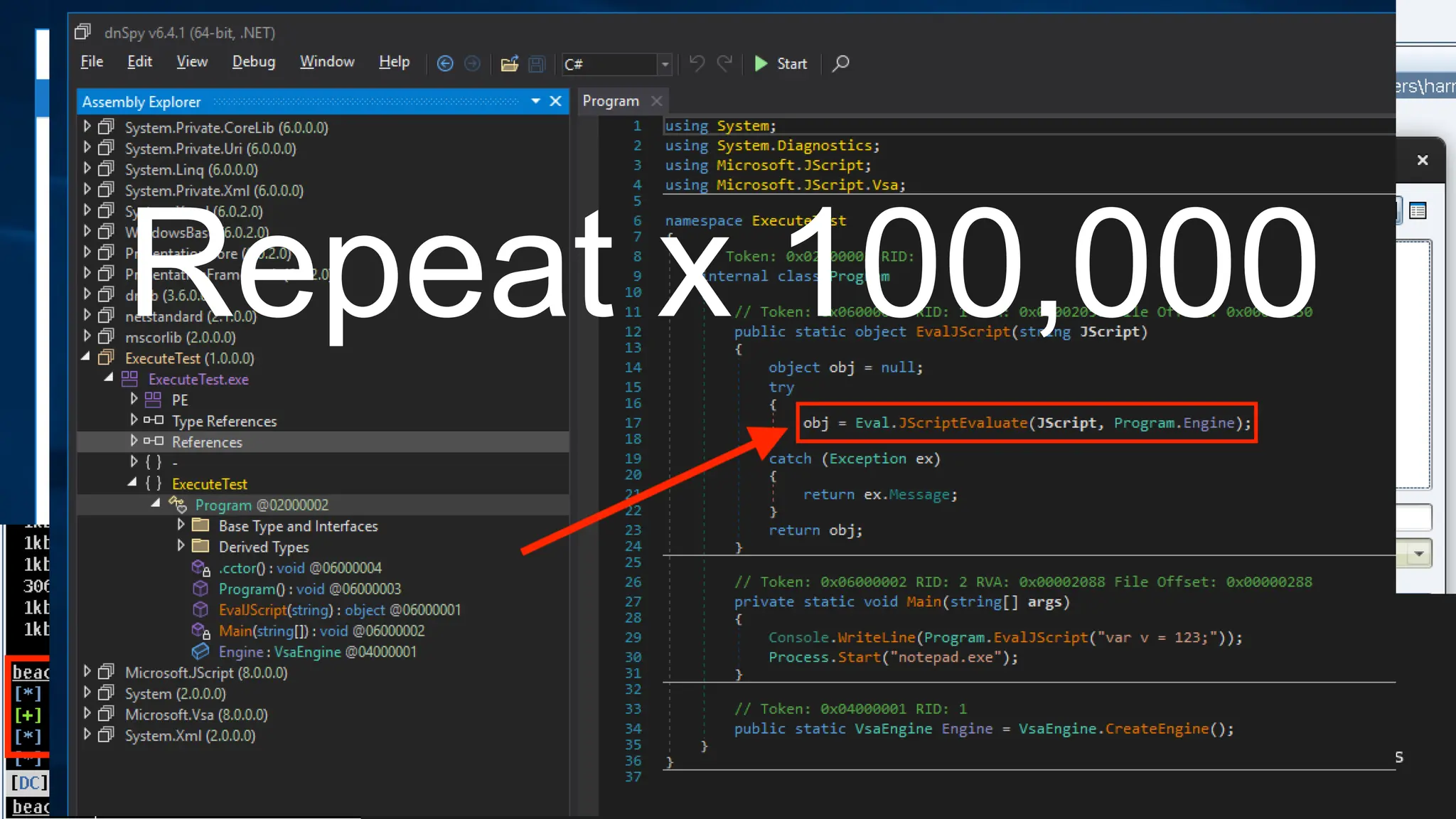


















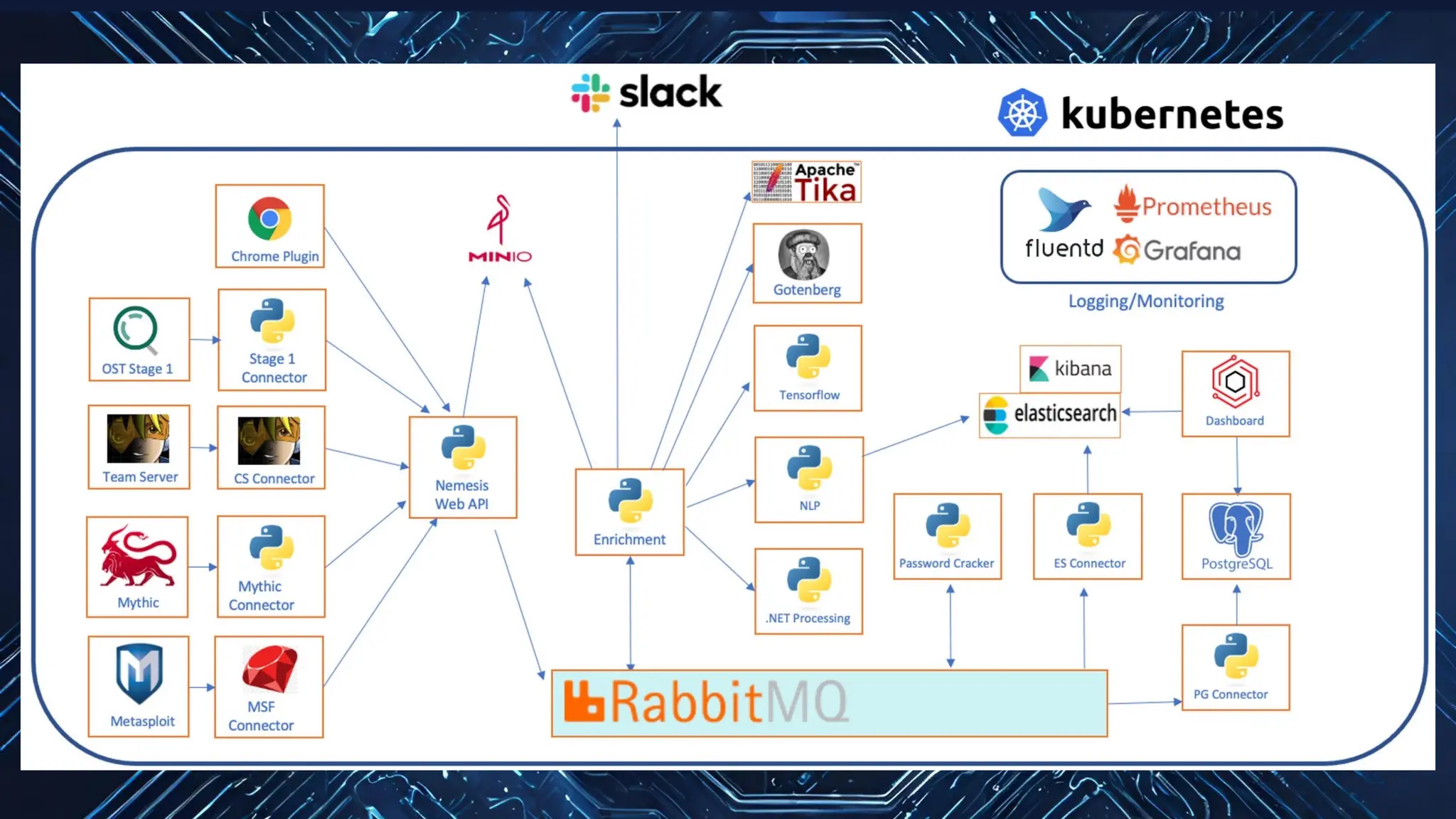
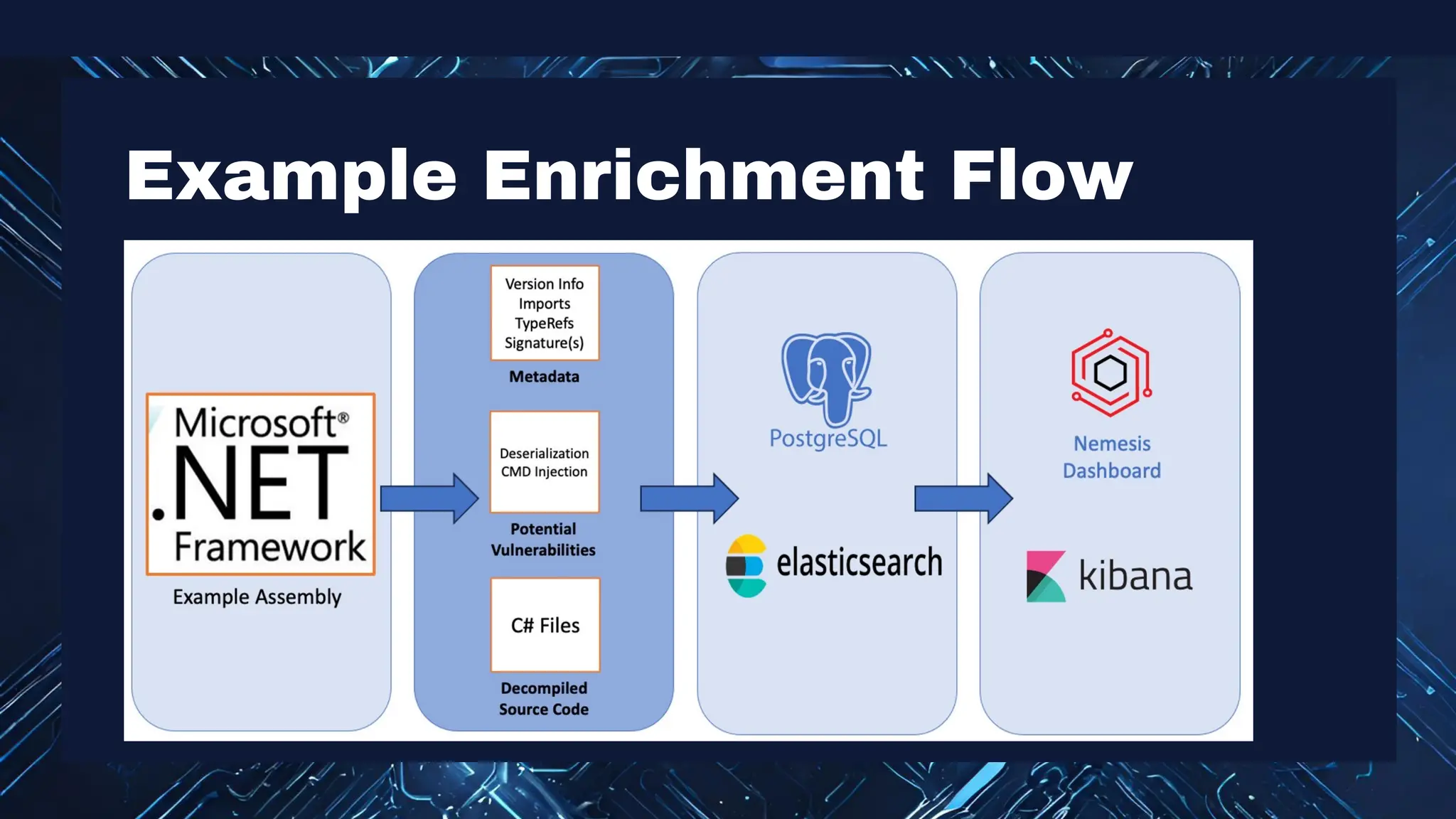









The document discusses the integration of machine learning in offensive security operations, highlighting the challenges faced by red teams in data management and tooling. It emphasizes the asymmetrical nature of offensive and defensive data landscapes, the limitations in available data sets, and the need for a unified offensive data model. The vision for a centralized data processing platform aims to automate analysis and improve data utilization in offensive operations, potentially transforming how red teams operate.






















































































