

![CURSE OF DIMENSIONALITY
In 𝑅2
the Vornoi diagram is of size O(n) and the Query takes
O(log(n)) time.
In 𝑅𝑑
the Vornoi diagram time complexity is O(𝑛[𝑑/2]
)
We can also perform a linear scan: O(dn) space, O(dn) time
Volume-distance ratio explodes](https://image.slidesharecdn.com/27anninhigherdimensions-211113101952/75/Approximate-Nearest-Neighbour-in-Higher-Dimensions-4-2048.jpg)





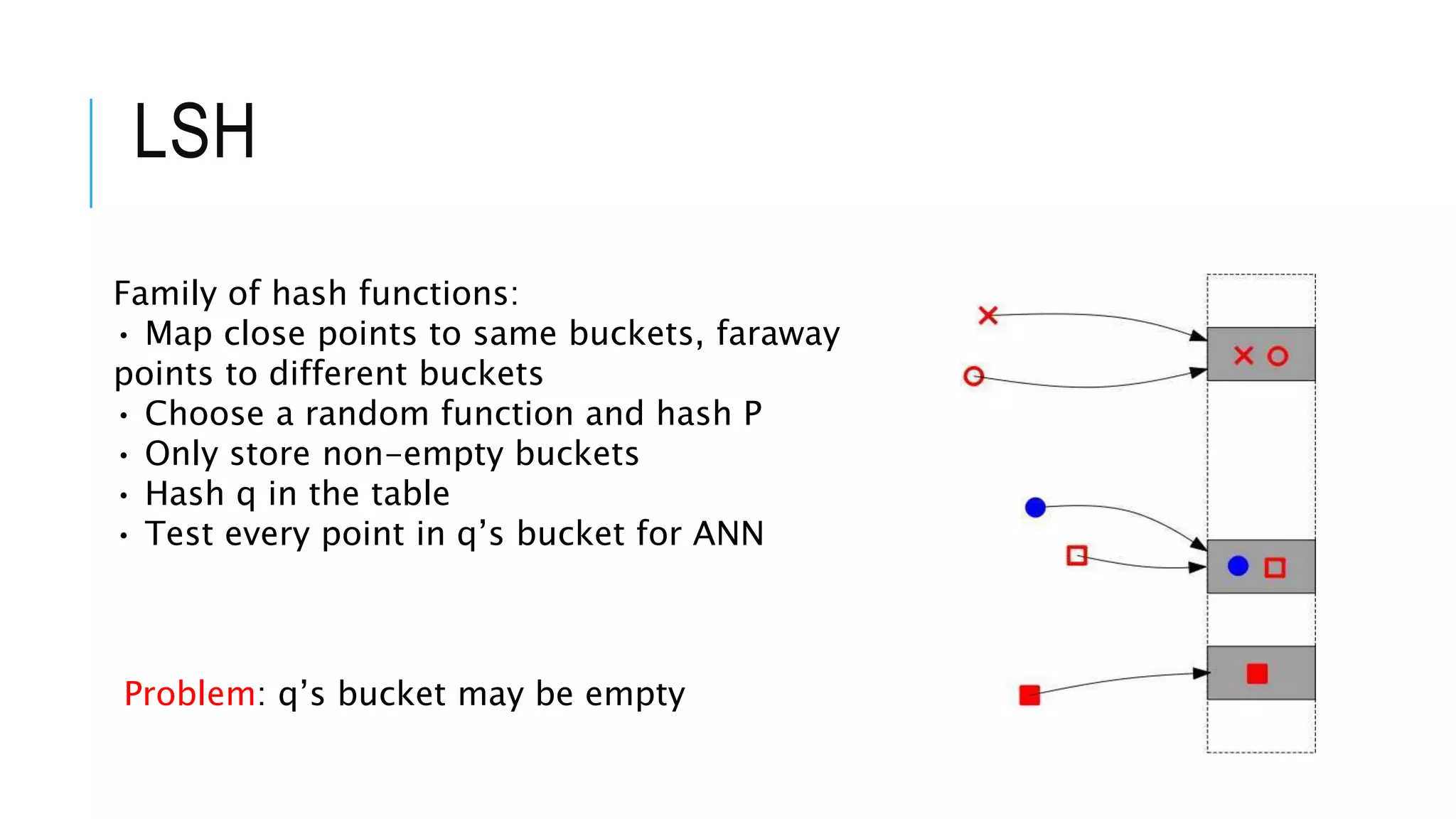
![CONSTRUCTING NNBR≈ FOR THE
HAMMING CUBE
We are interested in building an NNbr≈ for balls of radius r in the
Hamming distance.
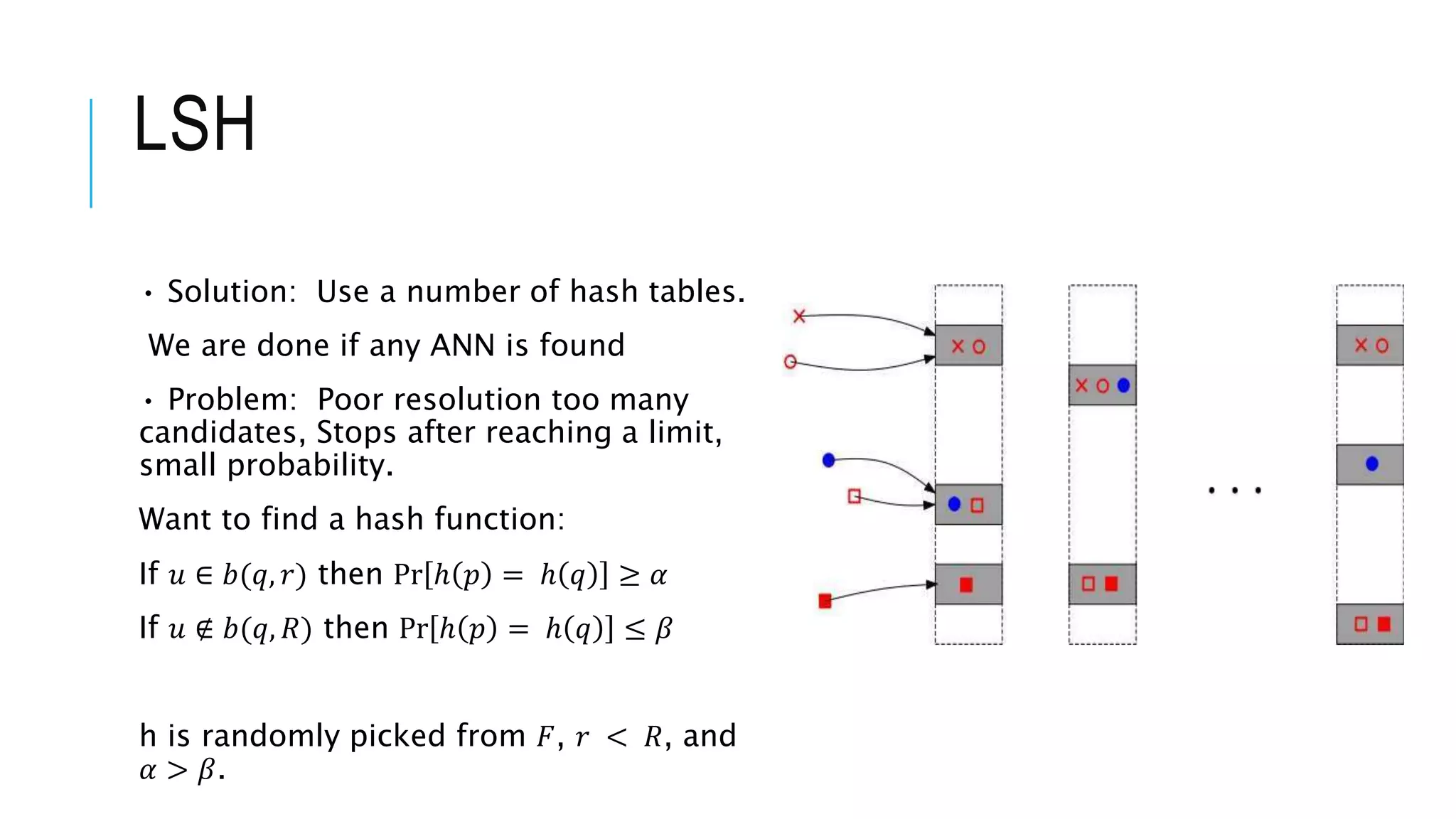
F = {ℎ ∶ 𝑆 → [0; 𝑈]} of functions, is an (r, R, 𝛼, 𝛽)-sensitive if for any p, 𝑞
∈ 𝑆, we have:
If 𝑢 ∈ 𝑏(𝑞, 𝑟) then Pr ℎ 𝑝 = ℎ 𝑞 ≥ 𝛼
If 𝑢 ∉ 𝑏(𝑞, 𝑅) then Pr ℎ 𝑝 = ℎ 𝑞 ≤ 𝛽
h is randomly picked from 𝐹, 𝑟 < 𝑅, and 𝛼 > 𝛽.](https://image.slidesharecdn.com/27anninhigherdimensions-211113101952/75/Approximate-Nearest-Neighbour-in-Higher-Dimensions-12-2048.jpg)

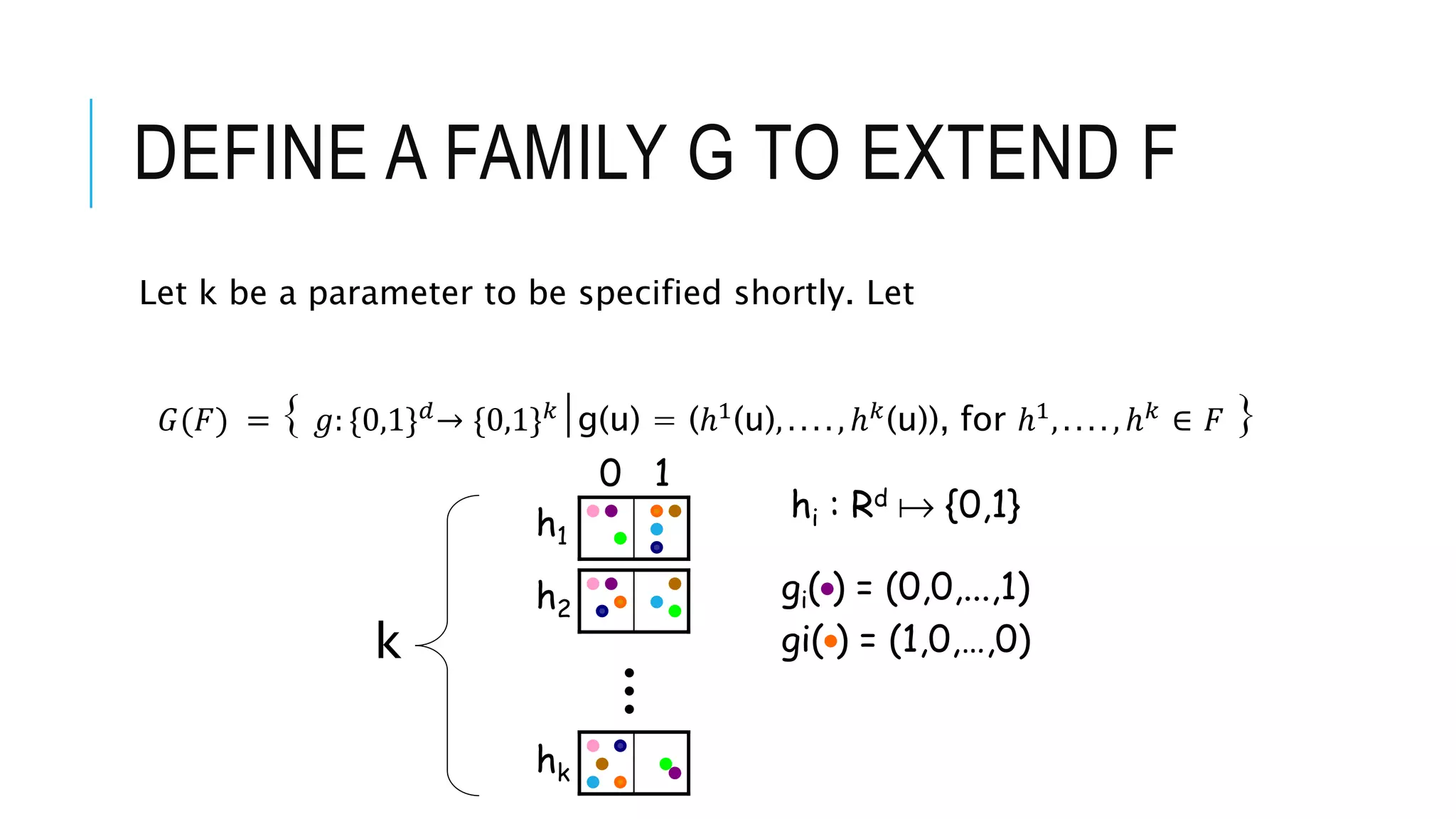
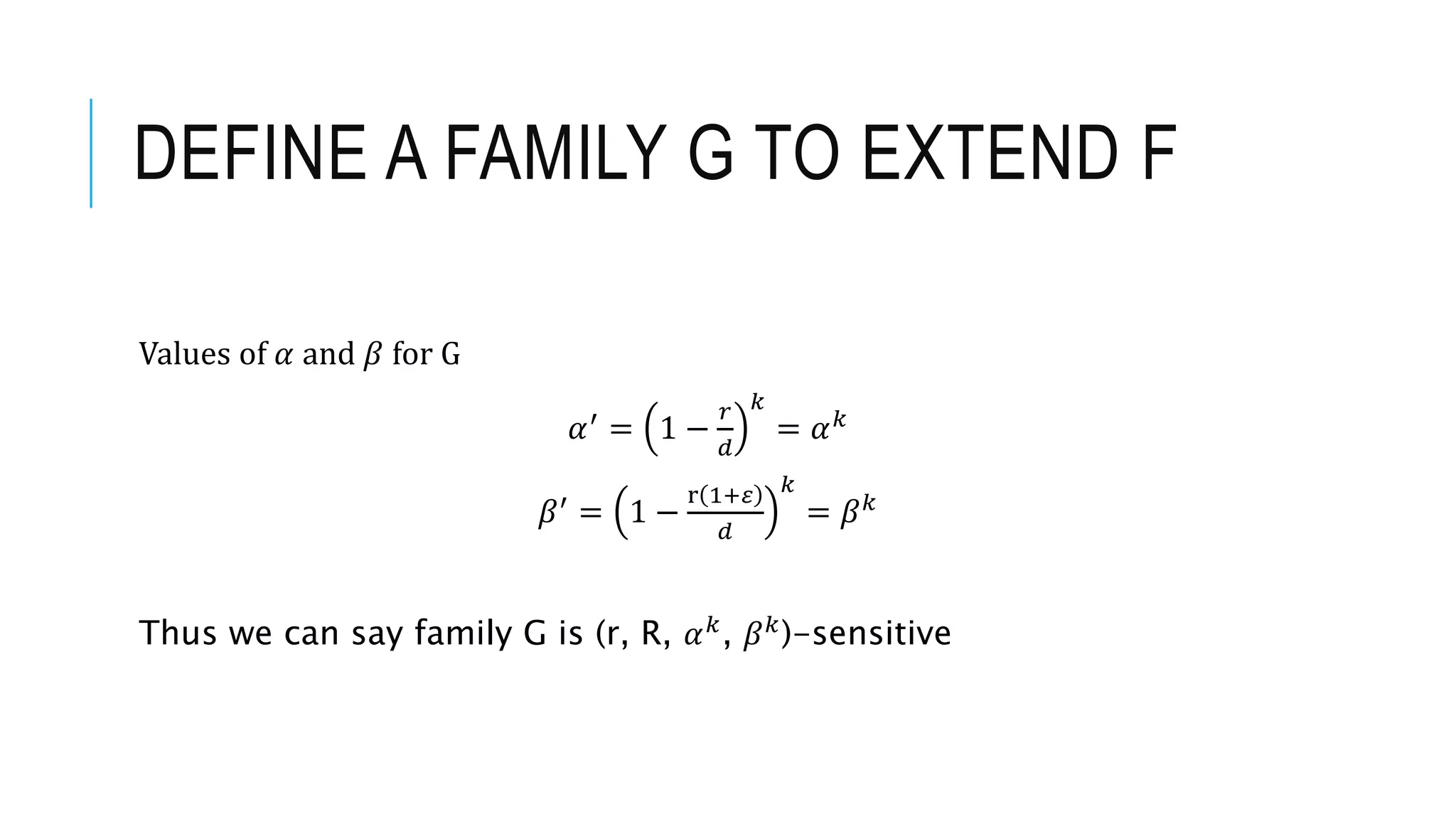
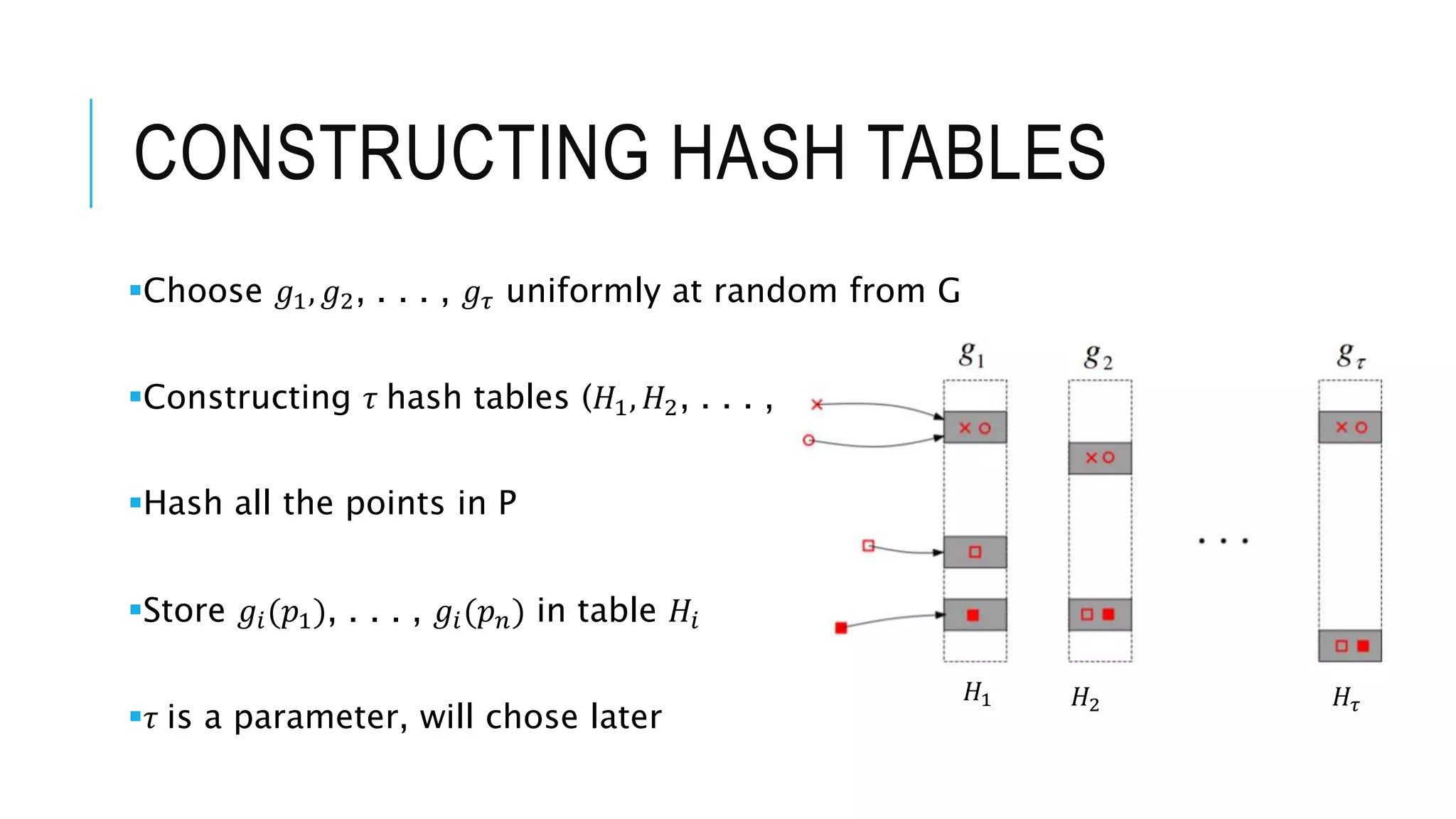
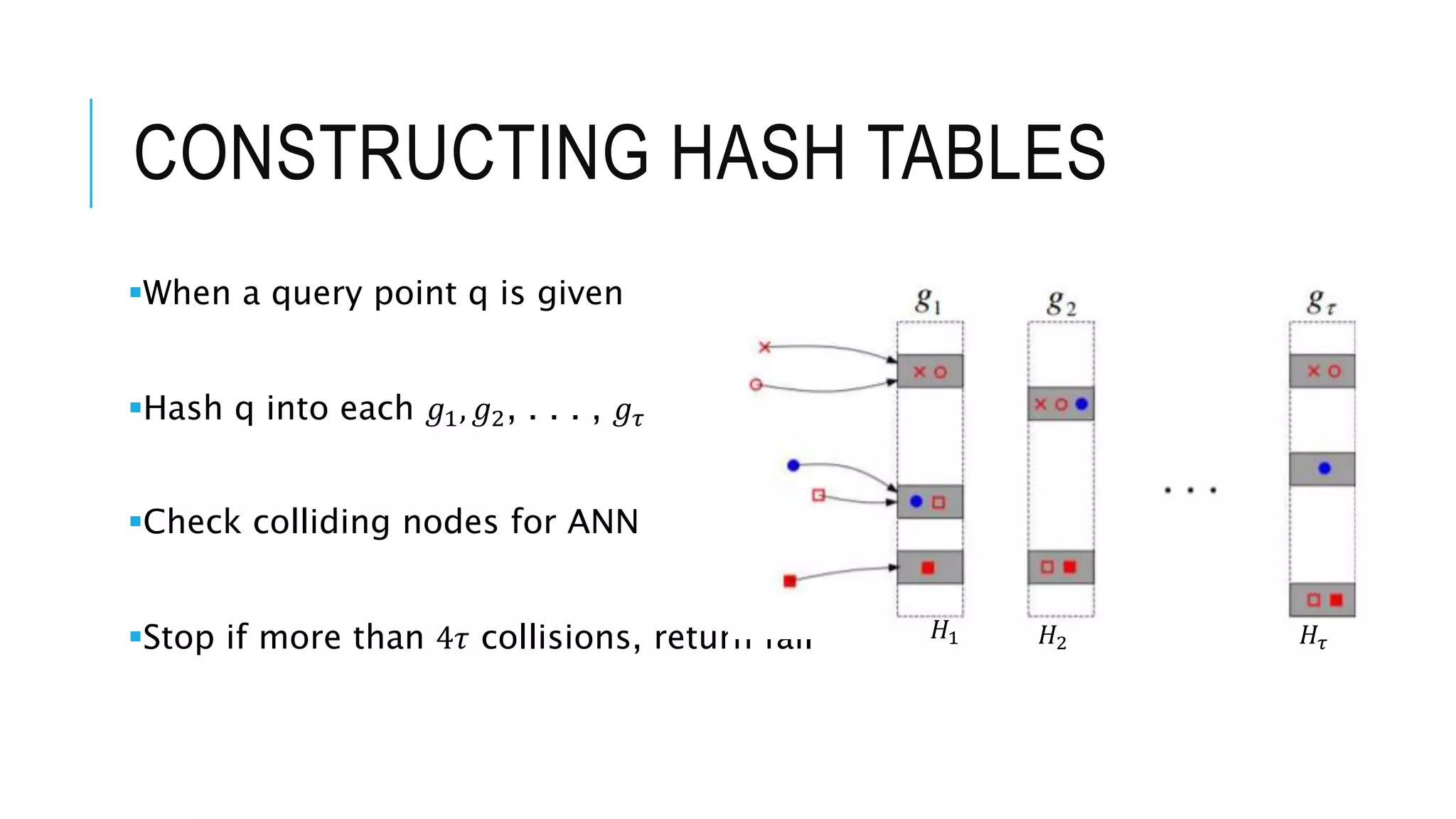


![DEFINING VALUES OF
PARAMETERS
Pr[E(collisions with q in 1
table)] ≤ 1
Pr[E(collisions with q in 𝜏
tables)] ≤ 𝜏
Pr[E(≥ 4𝜏 collisions)] ≤
𝜏
4𝜏
=
1
4
Pr[E(< 4𝜏 collisions)] ≥
3
4](https://image.slidesharecdn.com/27anninhigherdimensions-211113101952/75/Approximate-Nearest-Neighbour-in-Higher-Dimensions-21-2048.jpg)
![Case 2: Probability of finding an ANN if there is a NN
Pr 𝑔𝑖 𝑝 = 𝑔𝑖 𝑞 ≥ 𝛼𝑘
= 𝛼
ln 𝑛
ln 1/𝛽
= 𝑛
−
ln 1/𝛼
ln 1/𝛽
= 𝑛−𝜌
Pr[E(𝑔𝑖 hashes p and q to different locations)] ≤ 1 − 𝑛−𝜌
Pr[E(p and q collide atleast once in 𝜏 tables)] ≥ 1 − (1− 𝑛−𝜌)𝜏
By setting 𝜏 = 2𝑛𝜌 we get the probability > 4/5
DEFINING VALUES OF
PARAMETERS](https://image.slidesharecdn.com/27anninhigherdimensions-211113101952/75/Approximate-Nearest-Neighbour-in-Higher-Dimensions-22-2048.jpg)





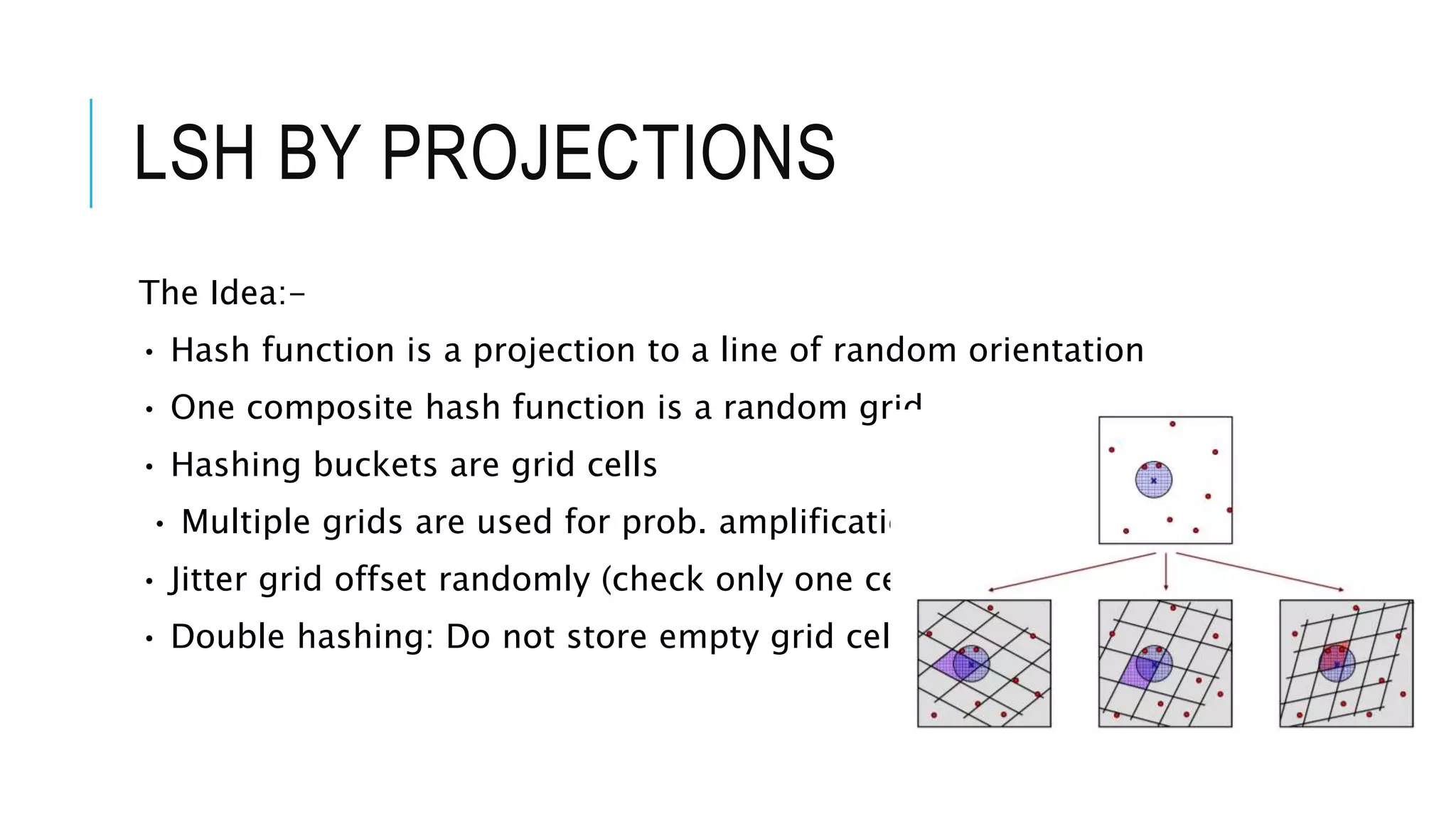
![PROJECTION
• The idea: If two points are close
together then after projection, these
points will remain close together.
• Let p, q be two points in 𝑅𝑑
. We want
to decide if q − r ≤ 1 or q − r ≥ η, η
= 1 + ε. We randomly choose a vector
𝑣 from the d-dimensional normal
distribution 𝑁𝑑
(0, 1) (which is 2-
stable).
• r is a parameter which signifies size of
the bucket, and t is a random number
from the interval [0,r]. p ∈ 𝑅𝑑
• consider the random hash function:
h(p) =
𝑝.𝑣+𝑡
𝑟](https://image.slidesharecdn.com/27anninhigherdimensions-211113101952/75/Approximate-Nearest-Neighbour-in-Higher-Dimensions-31-2048.jpg)
![If p and q are in distance η from each other, and distance between their
projection on 𝑣 is t, then the probability that they get the same hash
value is 1 − t/r. The probability of collusion is:
α(η) = Pr[ h(p) = h(q)] = 𝑡=0
𝑟
Pr[ 𝑝. 𝑣 − 𝑞. 𝑣 =t] (1−
𝑡
𝑟
)ⅆt
Since 𝑣 is a 2-stable distribution, we have that 𝑝. 𝑣 − 𝑞. 𝑣 = (𝑝 − 𝑞). 𝑣 ∼
N(0, 𝑝𝑞 2
). For absolute value, we multiply this by 2:
α(η,r) = 𝑡=0
𝑟 2
η 2𝜋
exp(
−𝑡2
2η2 (1−
𝑡
𝑟
)ⅆt)
We would like to maximize the difference α(1 + ε,r) − α(1,r), as much as
possible, by choosing the right value of r. Through numerical
computation we obtain that we can chose an r such that:
ρ(1 + ε) ≤
1
1+ε
LSH](https://image.slidesharecdn.com/27anninhigherdimensions-211113101952/75/Approximate-Nearest-Neighbour-in-Higher-Dimensions-32-2048.jpg)





This document discusses approximate nearest neighbor (ANN) search in high dimensional spaces. It begins by introducing the ANN problem and noting the "curse of dimensionality" that makes exact searches inefficient in high dimensions. It then discusses constructing a (1+ε)-approximate NN data structure for the Hamming cube using locality sensitive hashing (LSH). The data structure uses O(dn + n1+ρ) space and O(nρ) hash probes per query, where ρ depends on sensitivity properties of the hash family. The document also discusses using LSH for ANN search in Euclidean spaces by projecting points to random lines, using multiple projections to amplify probabilities of nearby points hashing to the same value.
Introduction to ANN by Shelly Chouhan and Shrey Verma; Overview of topics including hypercube, Hamming distance, and LSH.
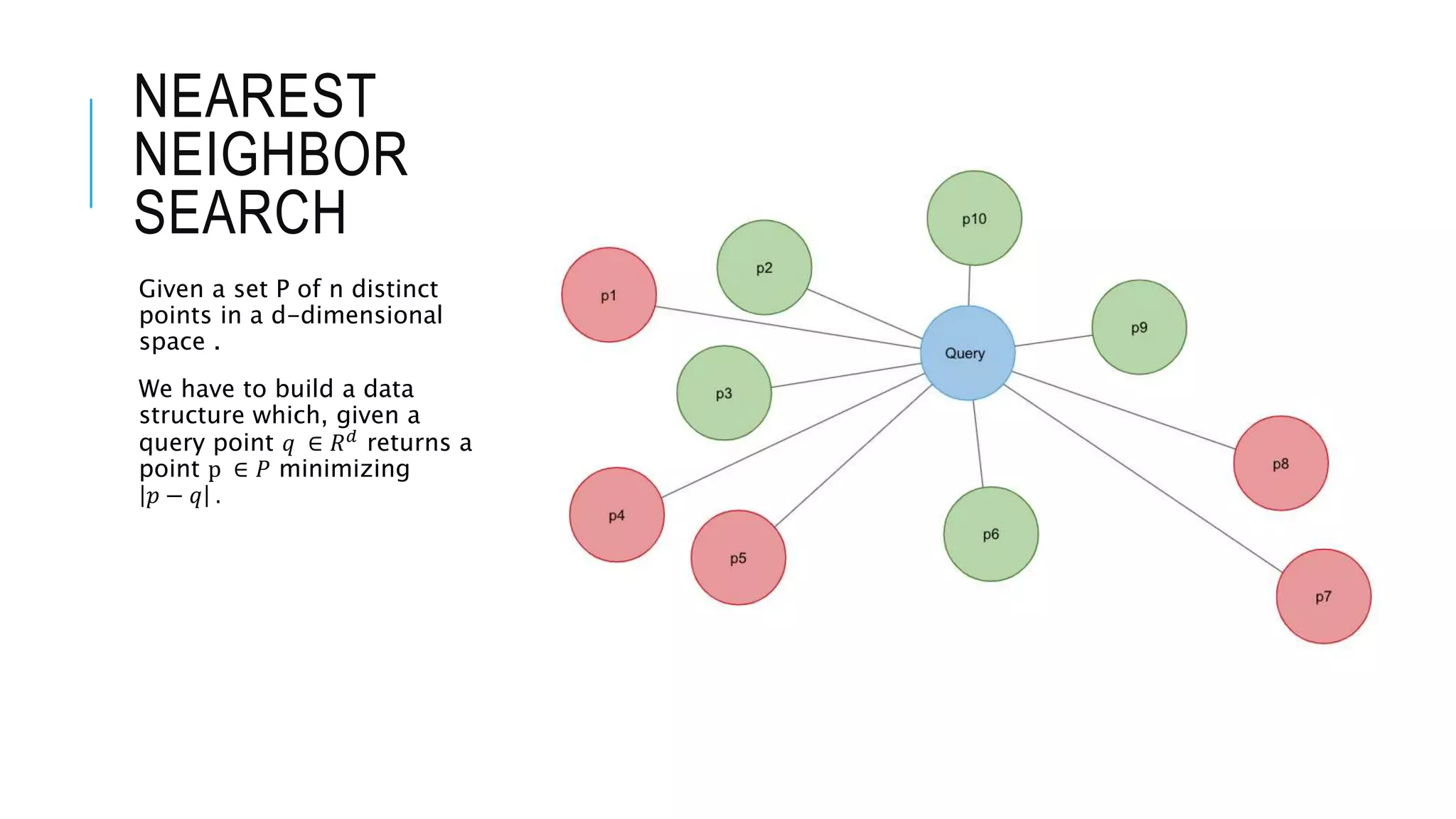
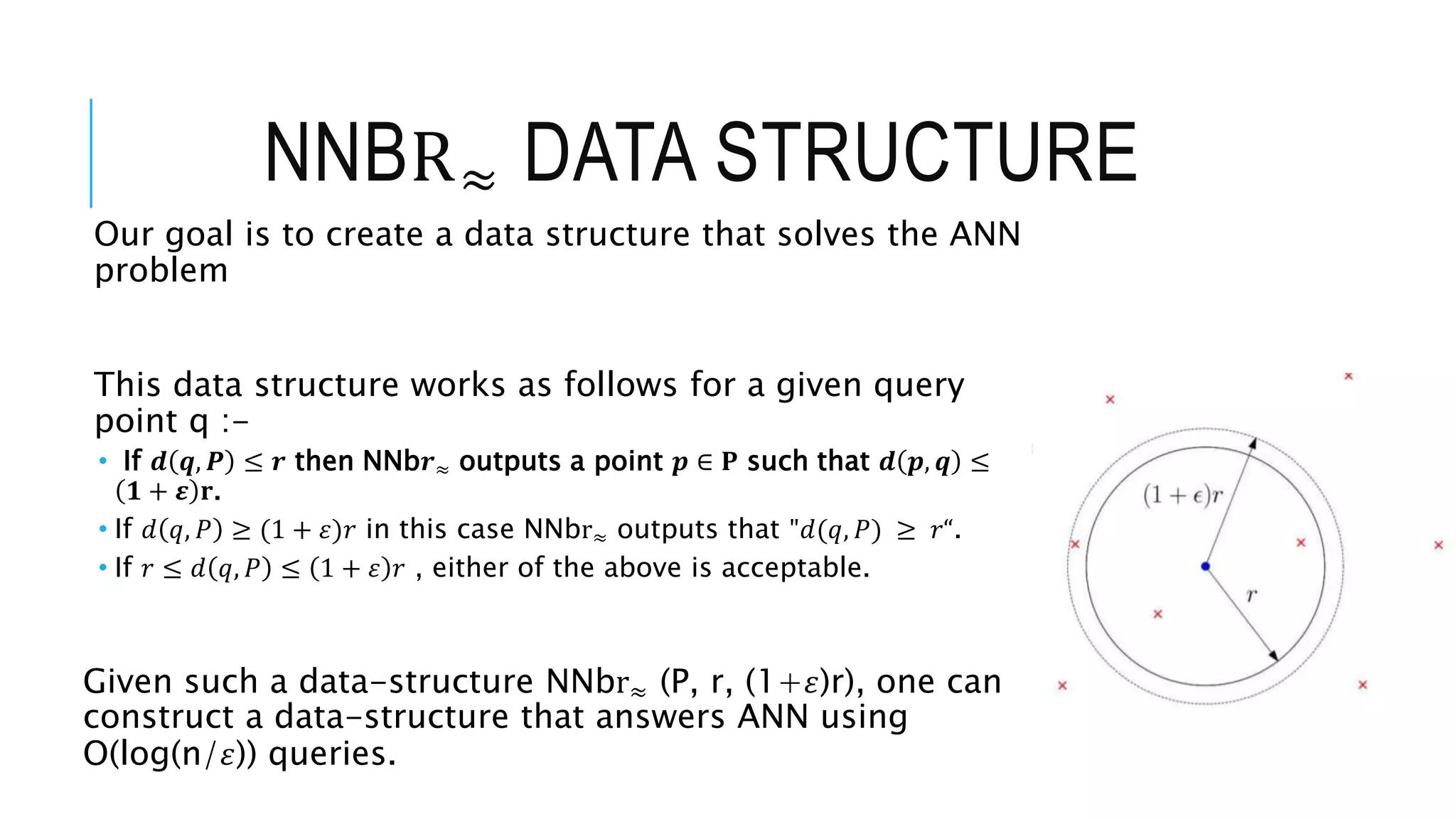
Introduction to nearest neighbor search, emphasizing the need for efficient data structures. Discussing approximate nearest neighbor search and its computational aspects.
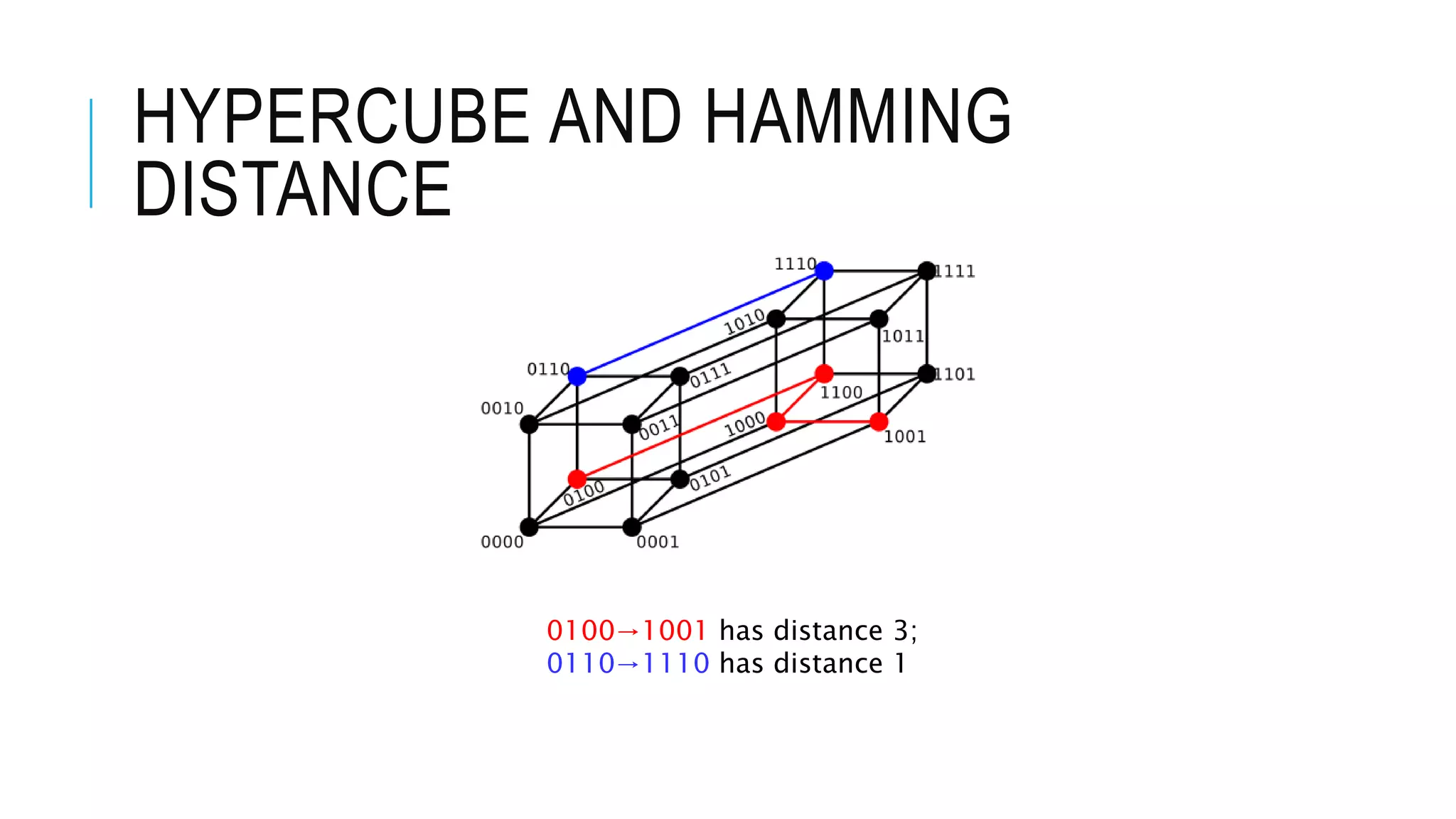
Explains the concept of the hypercube and Hamming distance, including distance calculations and data structure development for ANN.
Details on creating a data structure for ANN specifically for the Hamming cube, focusing on sensitivity properties of functions.
Expand on function families for hypercube, defining parameters for sensitivity, and proving the use of such families in ANN structures.
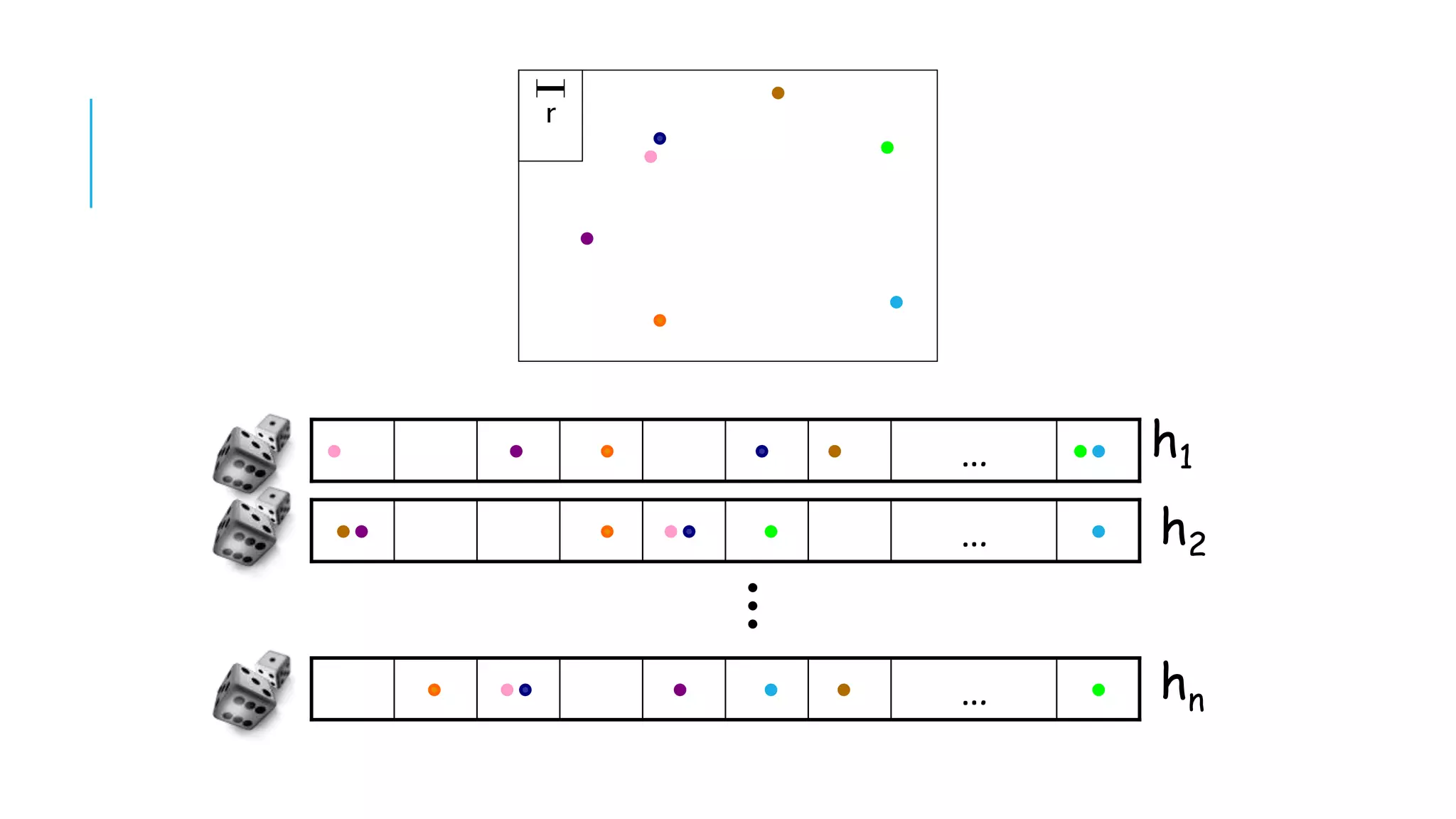
Introduction to LSH concepts, explaining its utility in ANN queries, and detailing space complexity and performance guarantees.
Final results on ANN data structures, presenting construction times, efficiency in finding approximate neighbors in high-dimensional spaces.















































