Downloaded 83 times








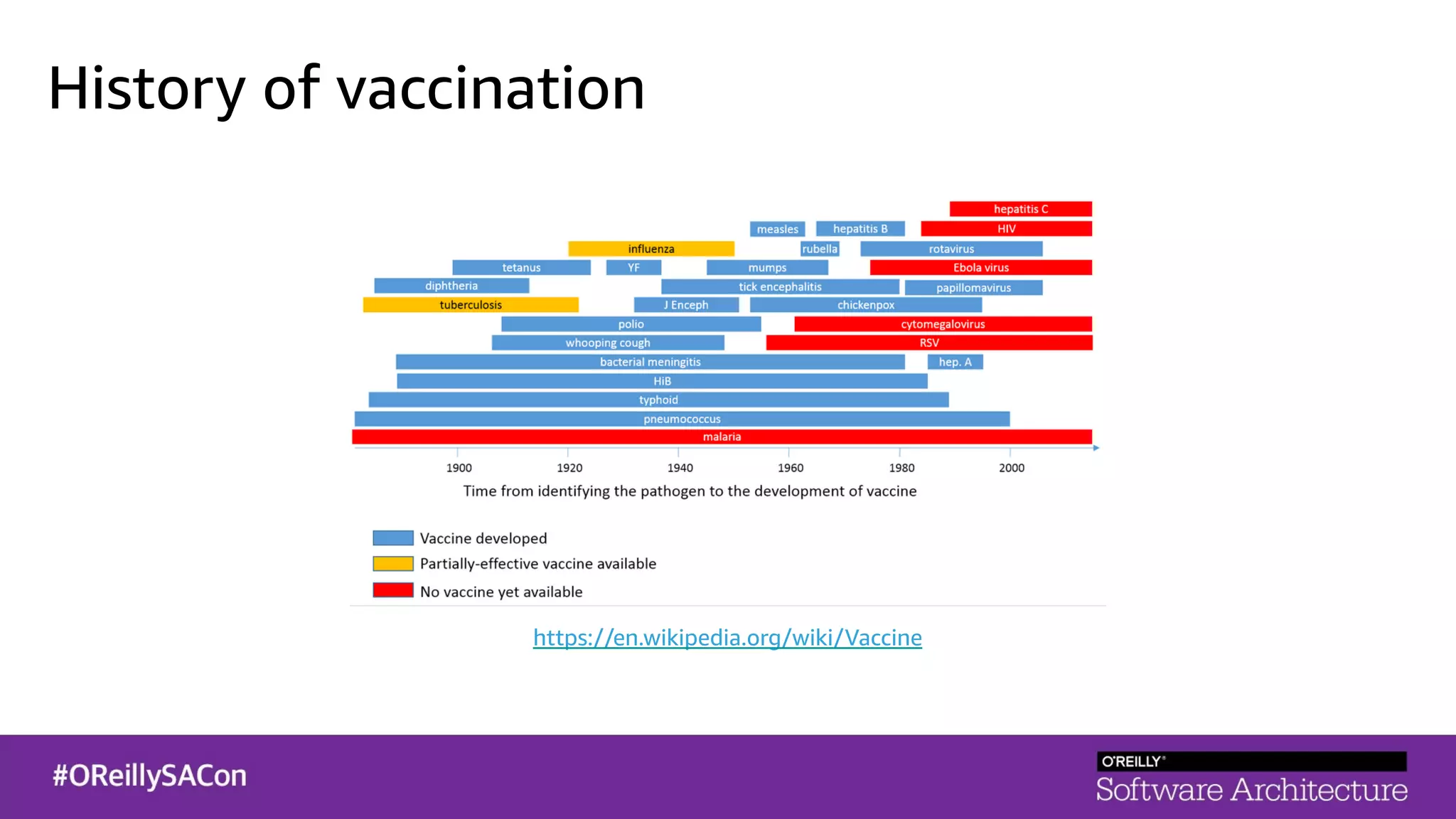




































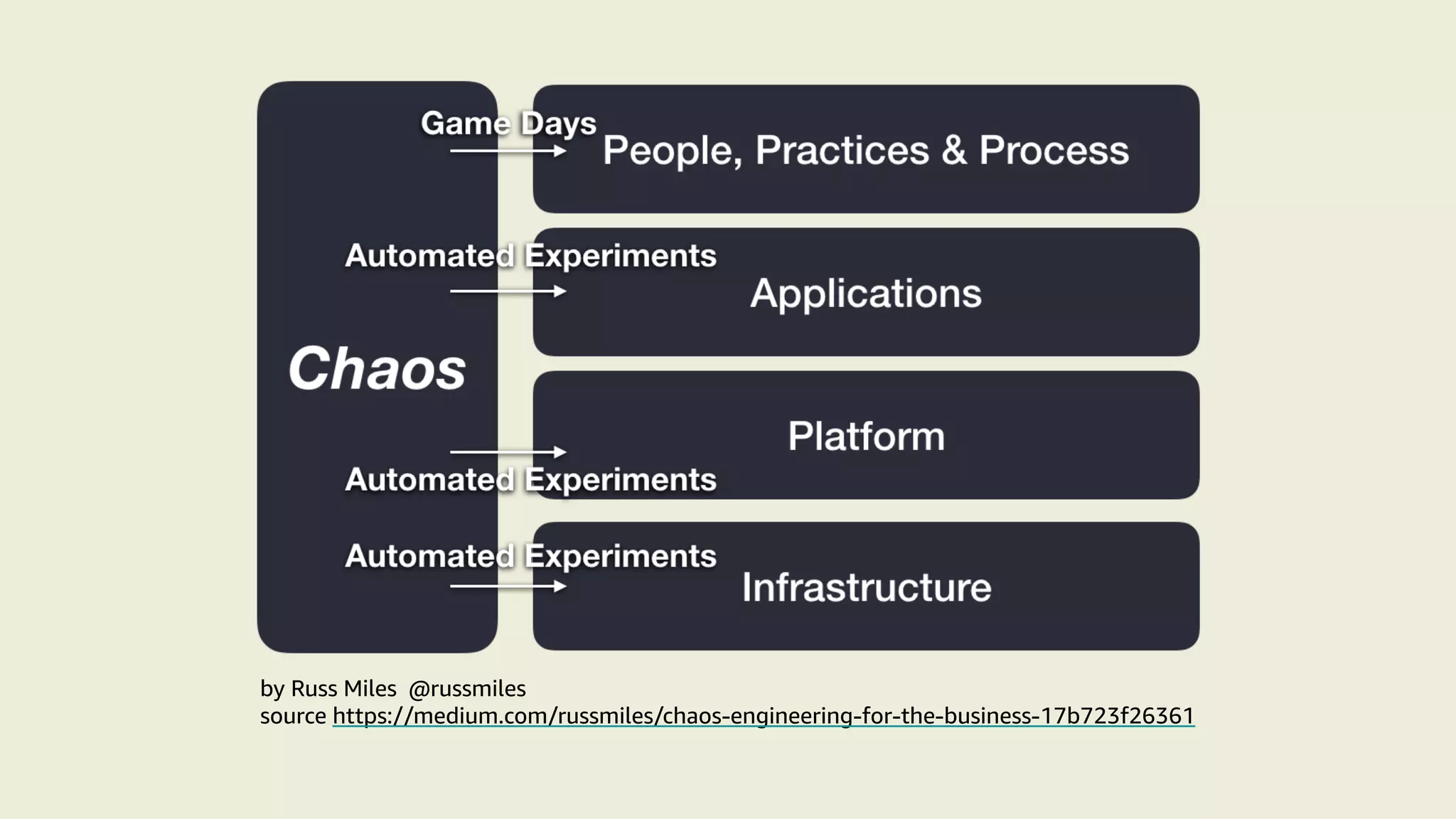




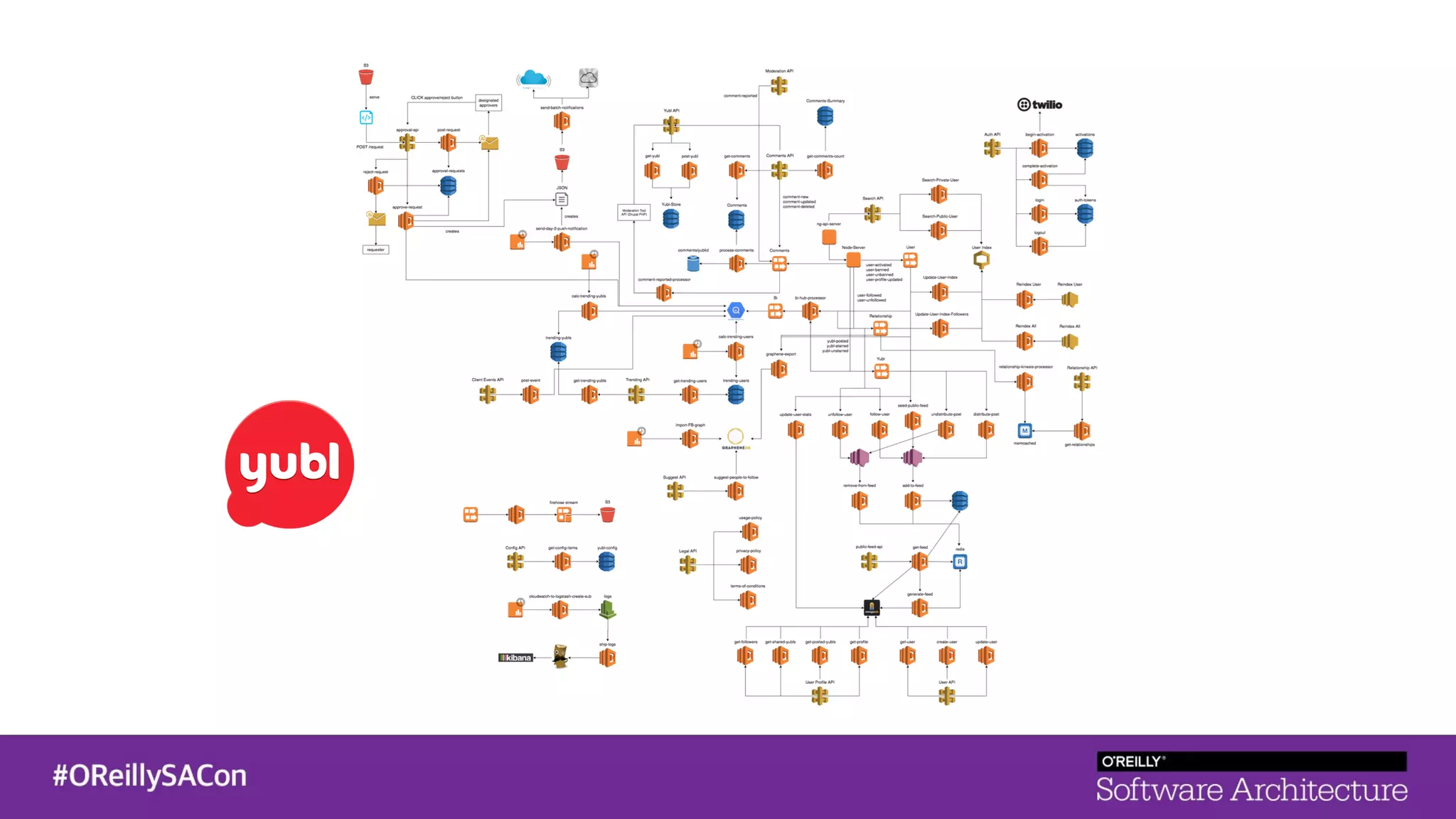


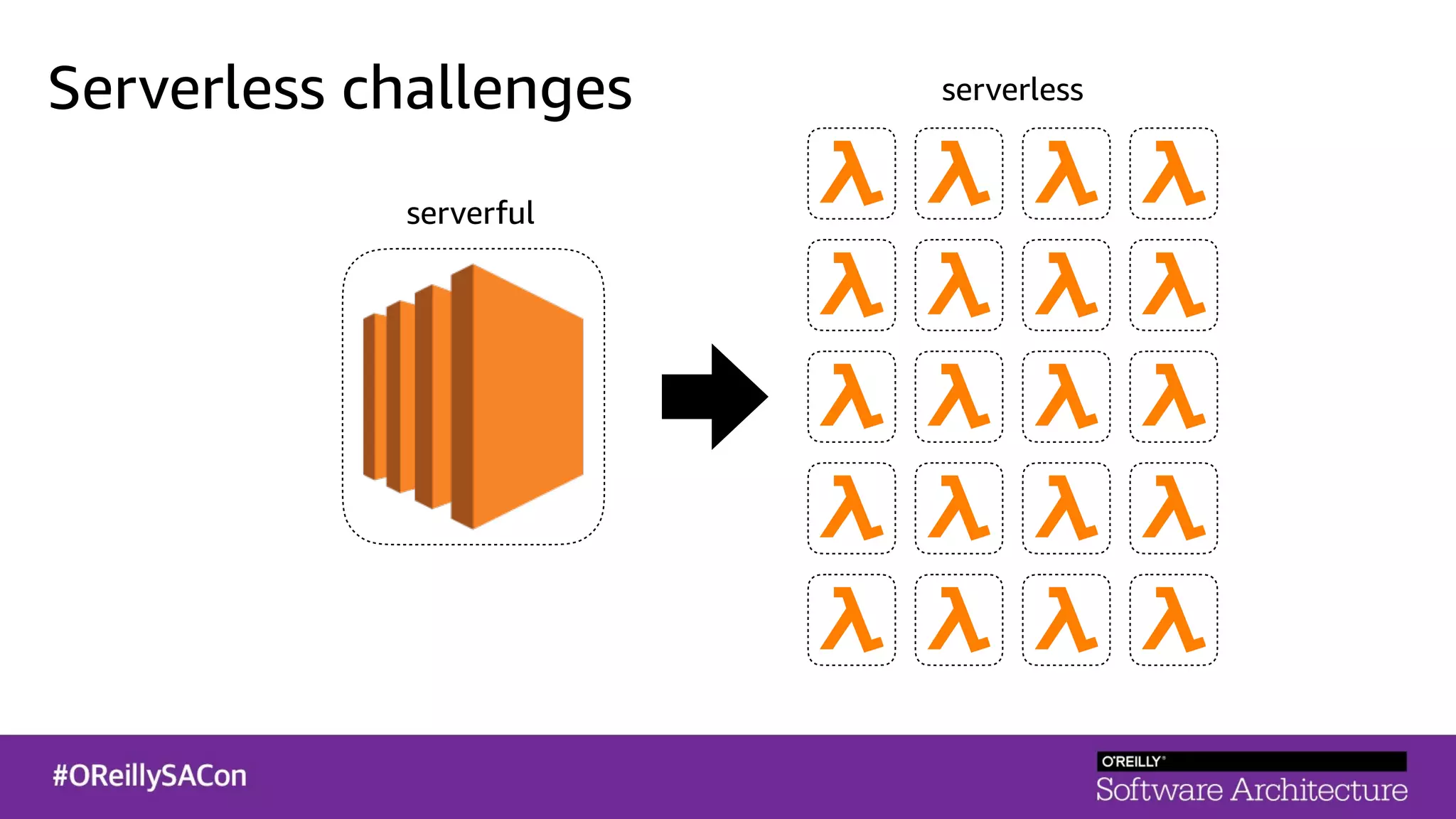

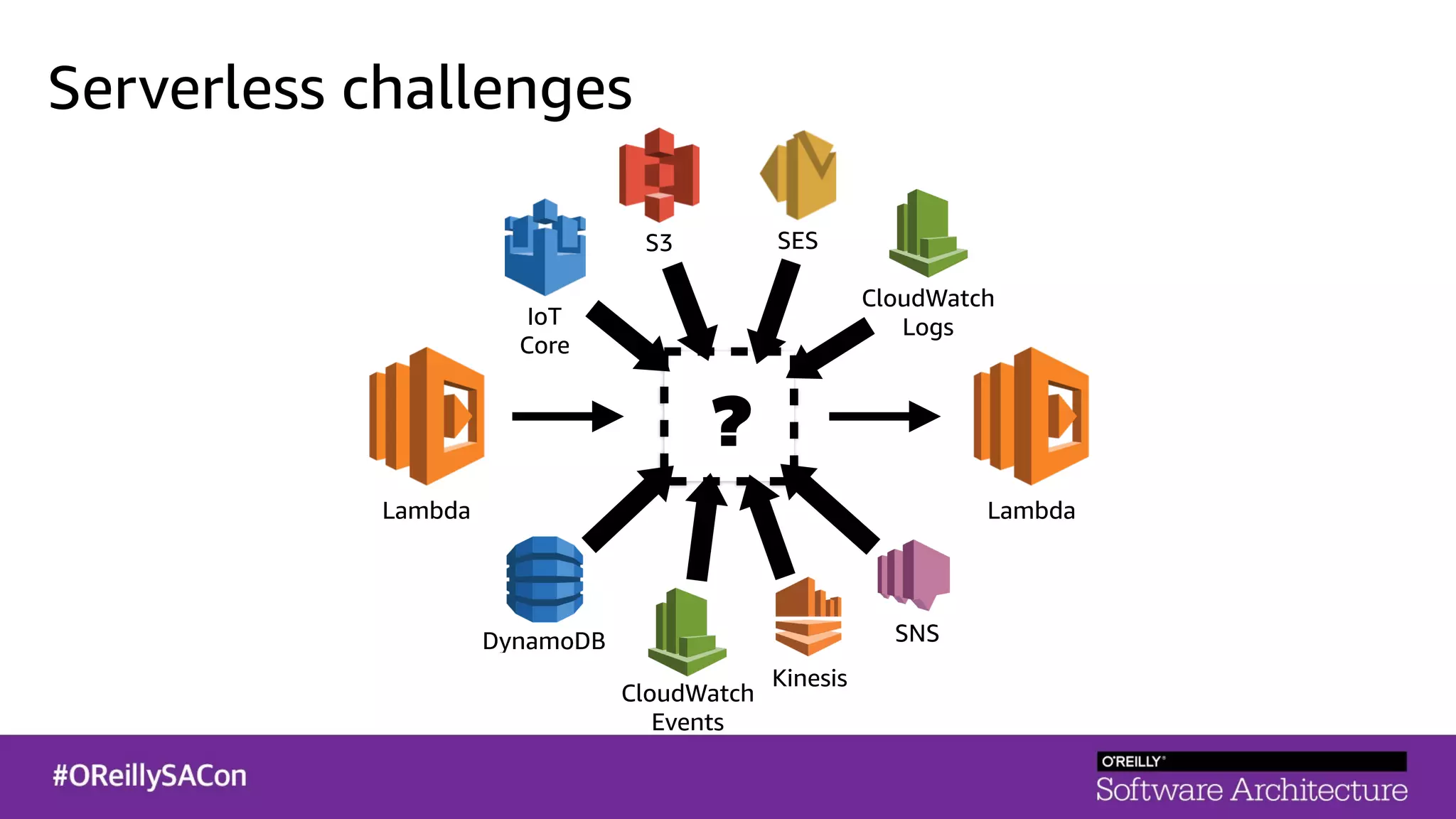




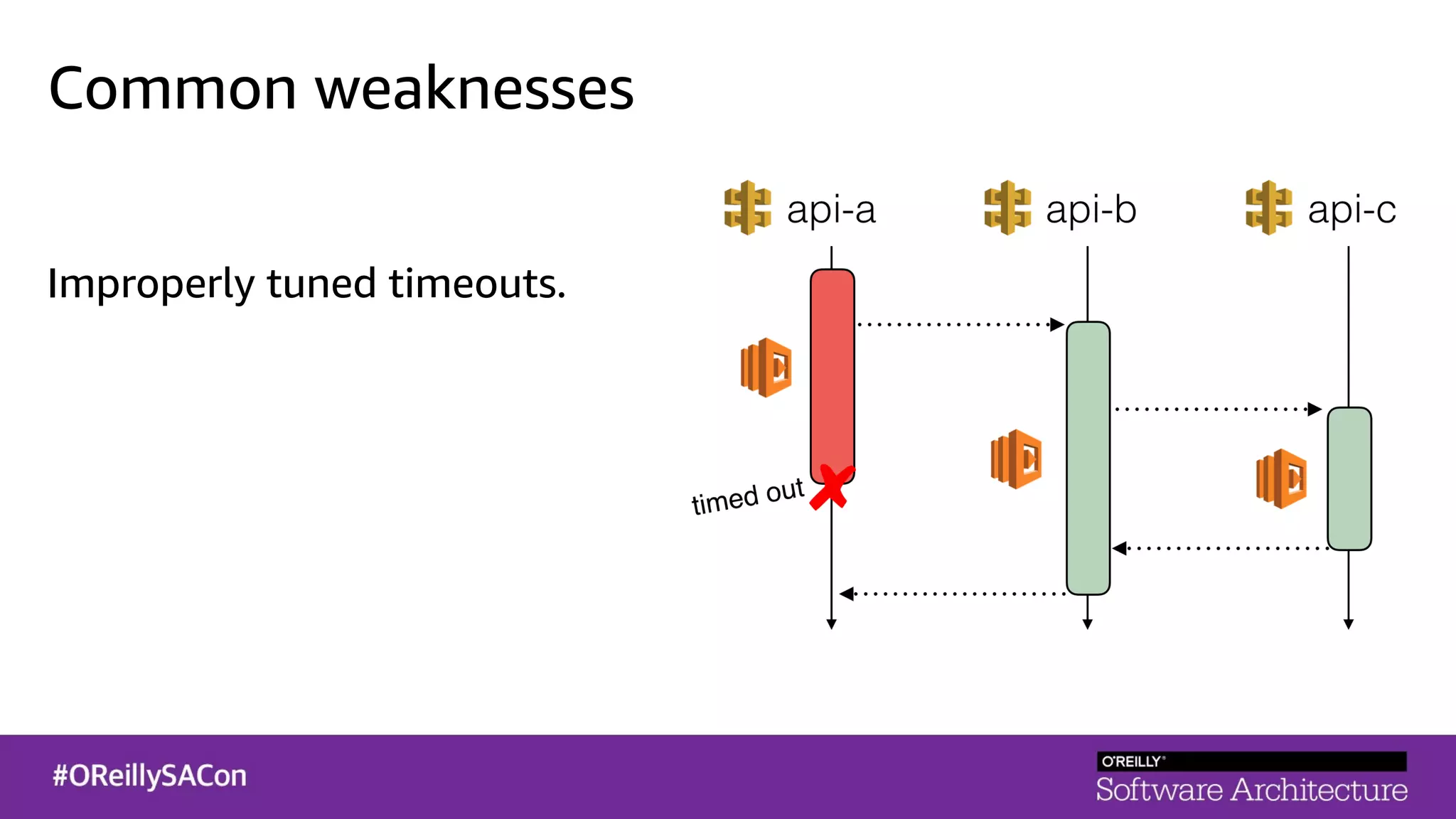
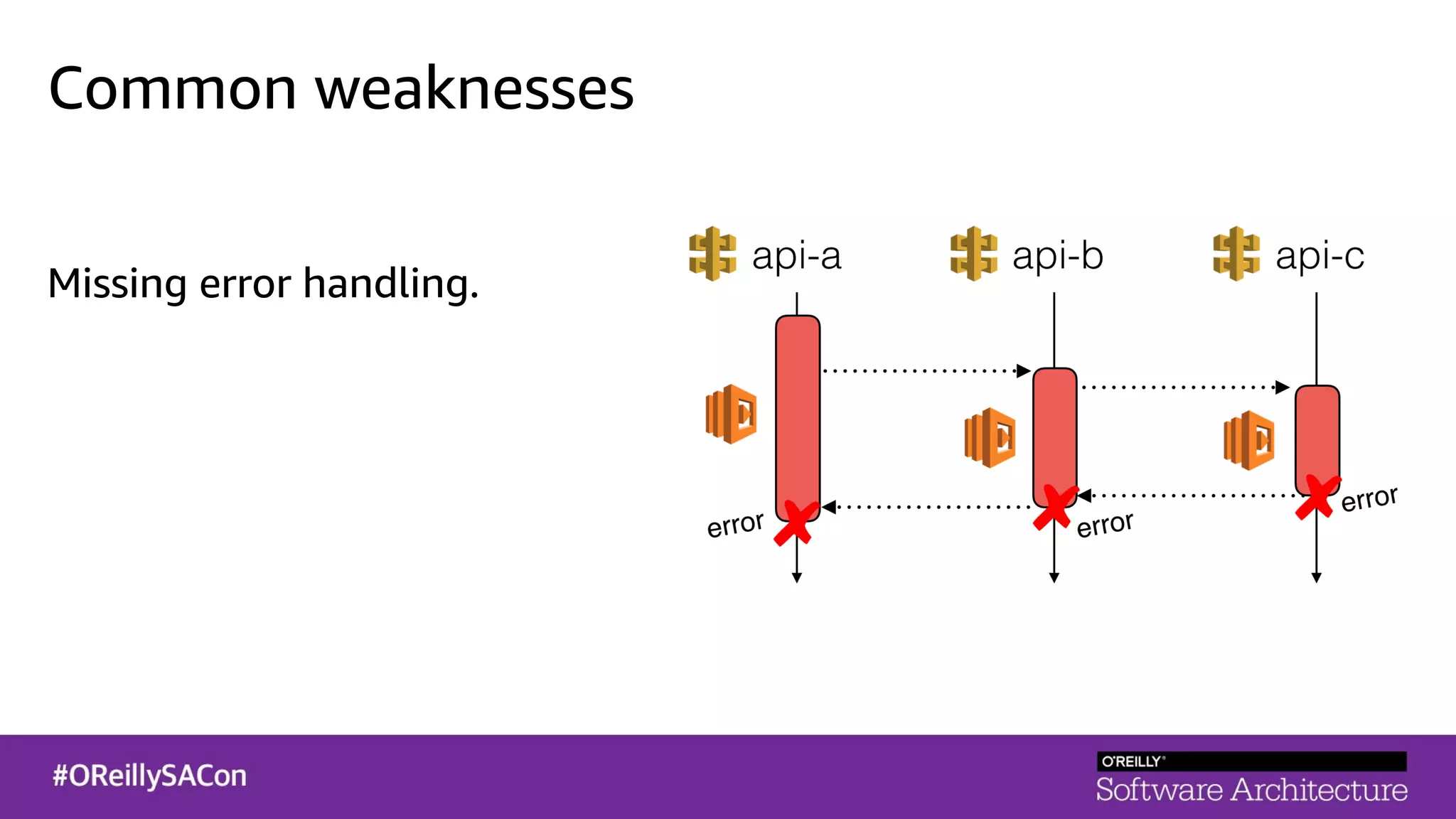




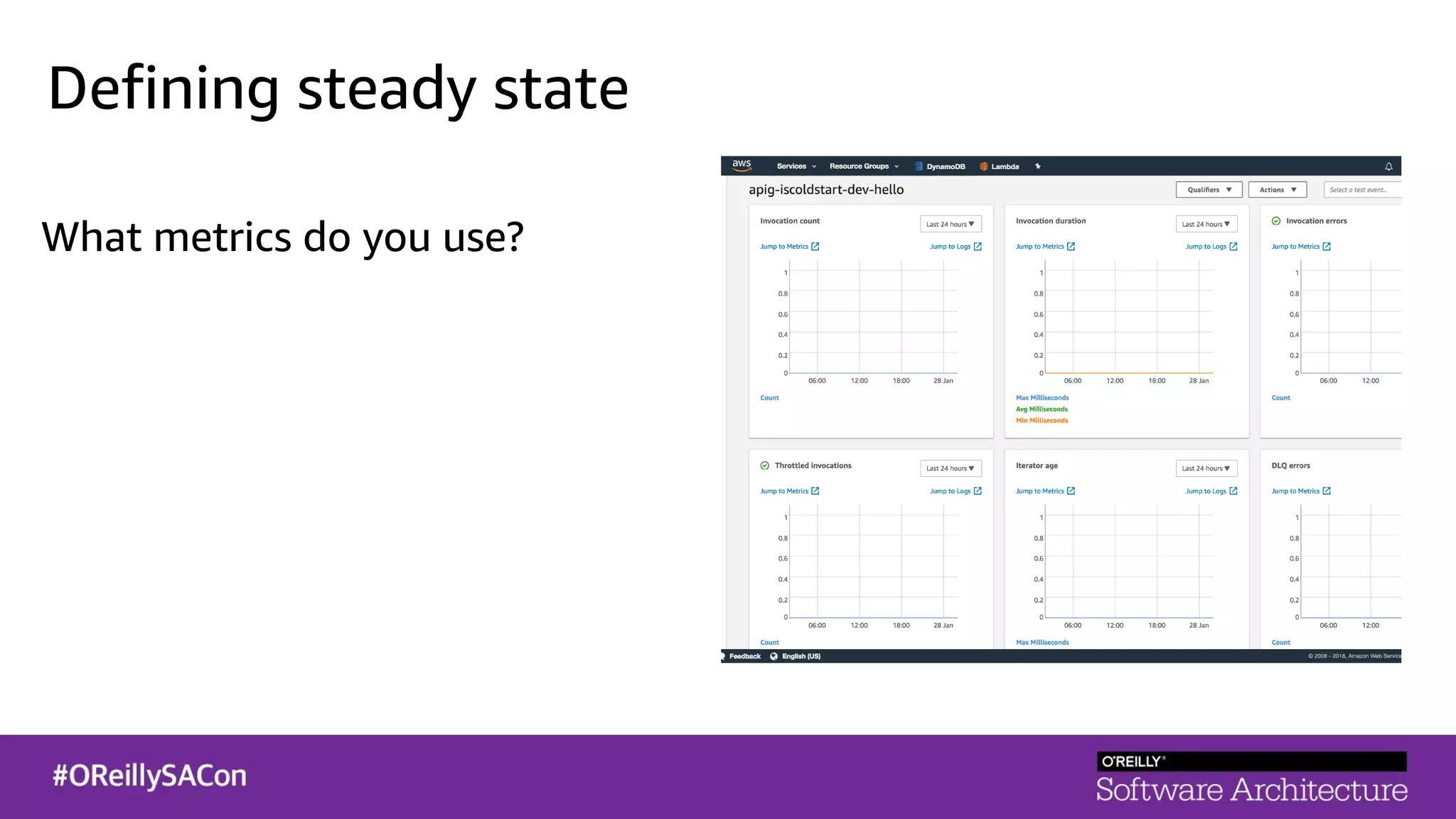











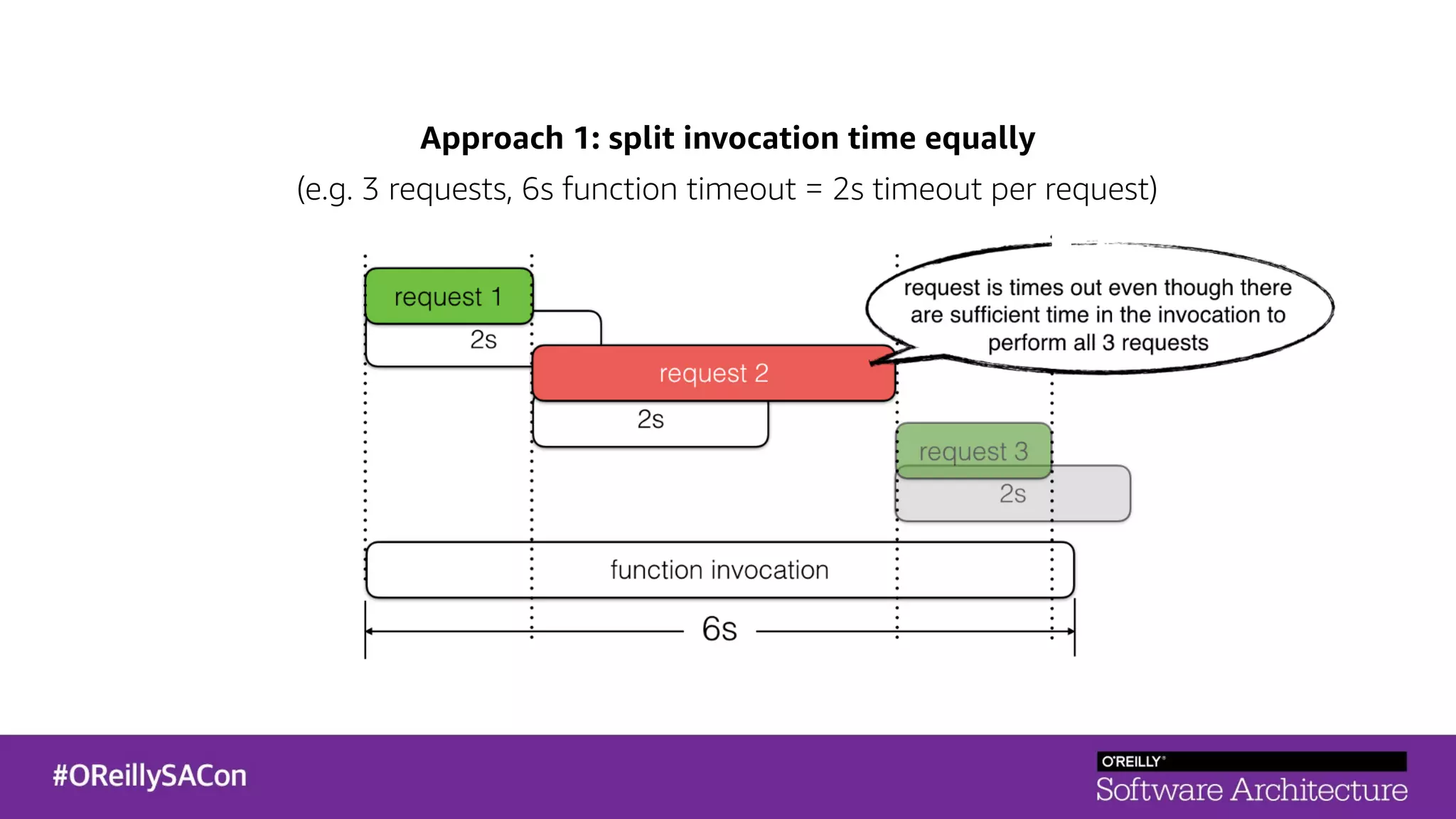
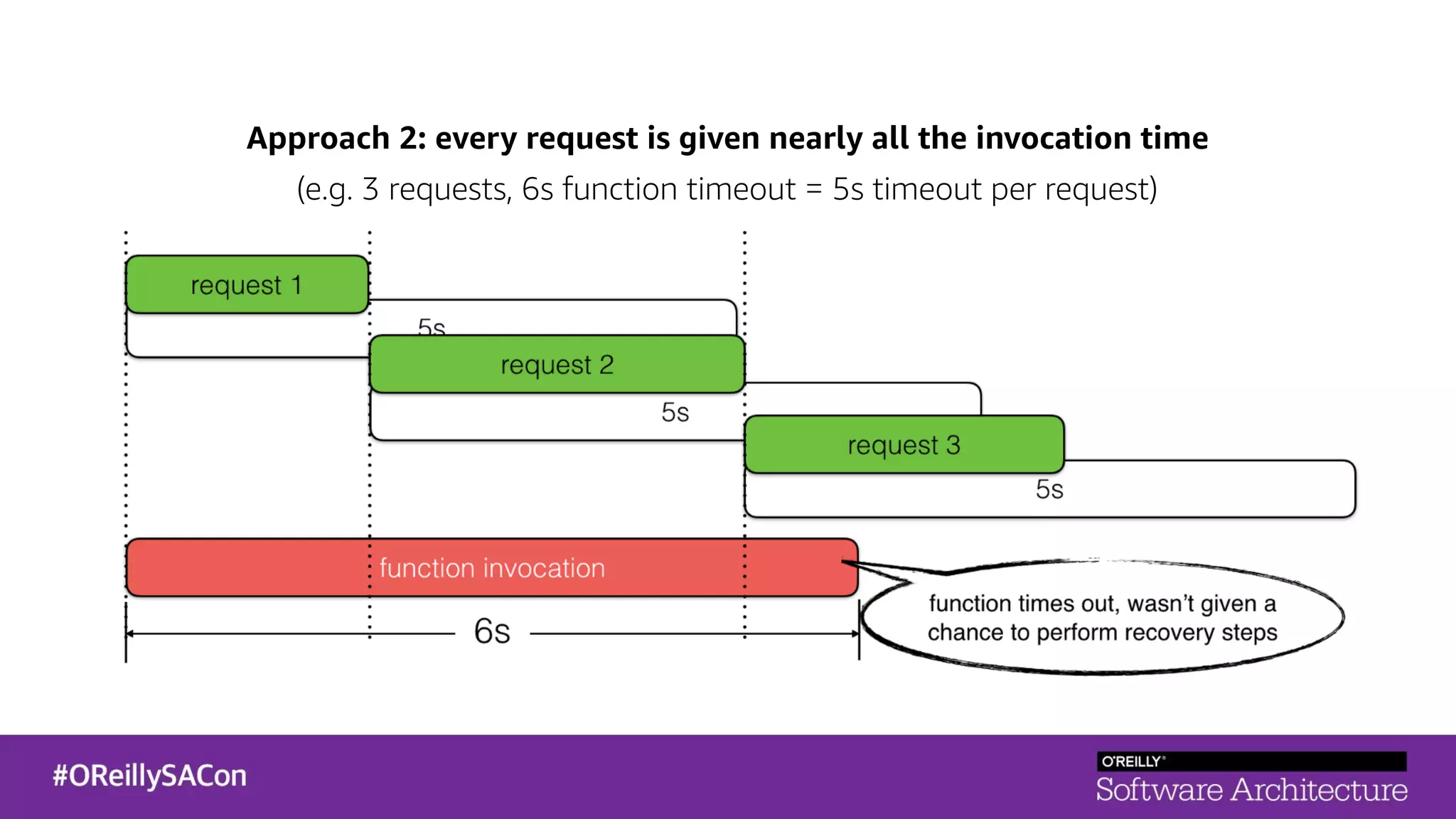


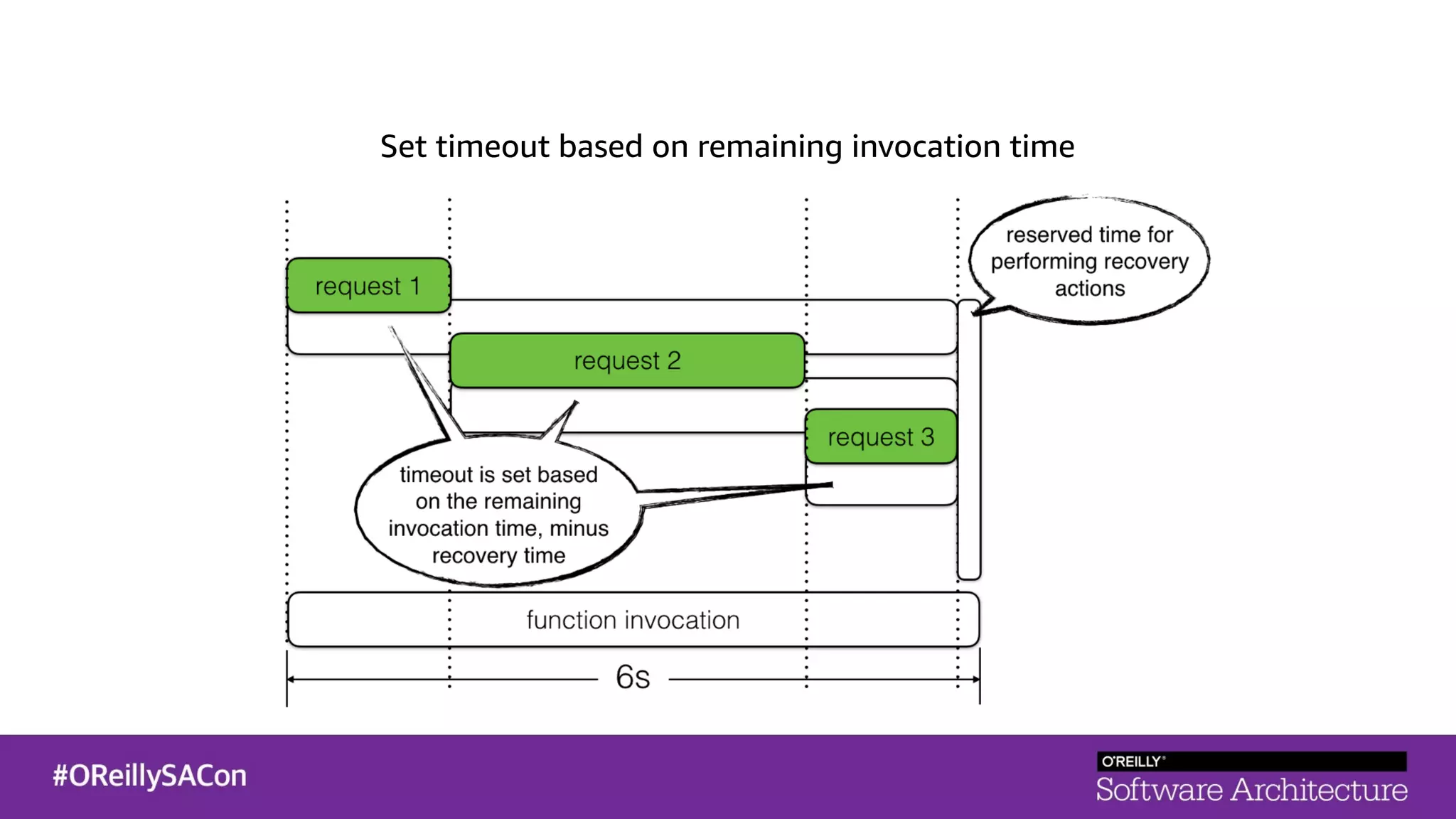
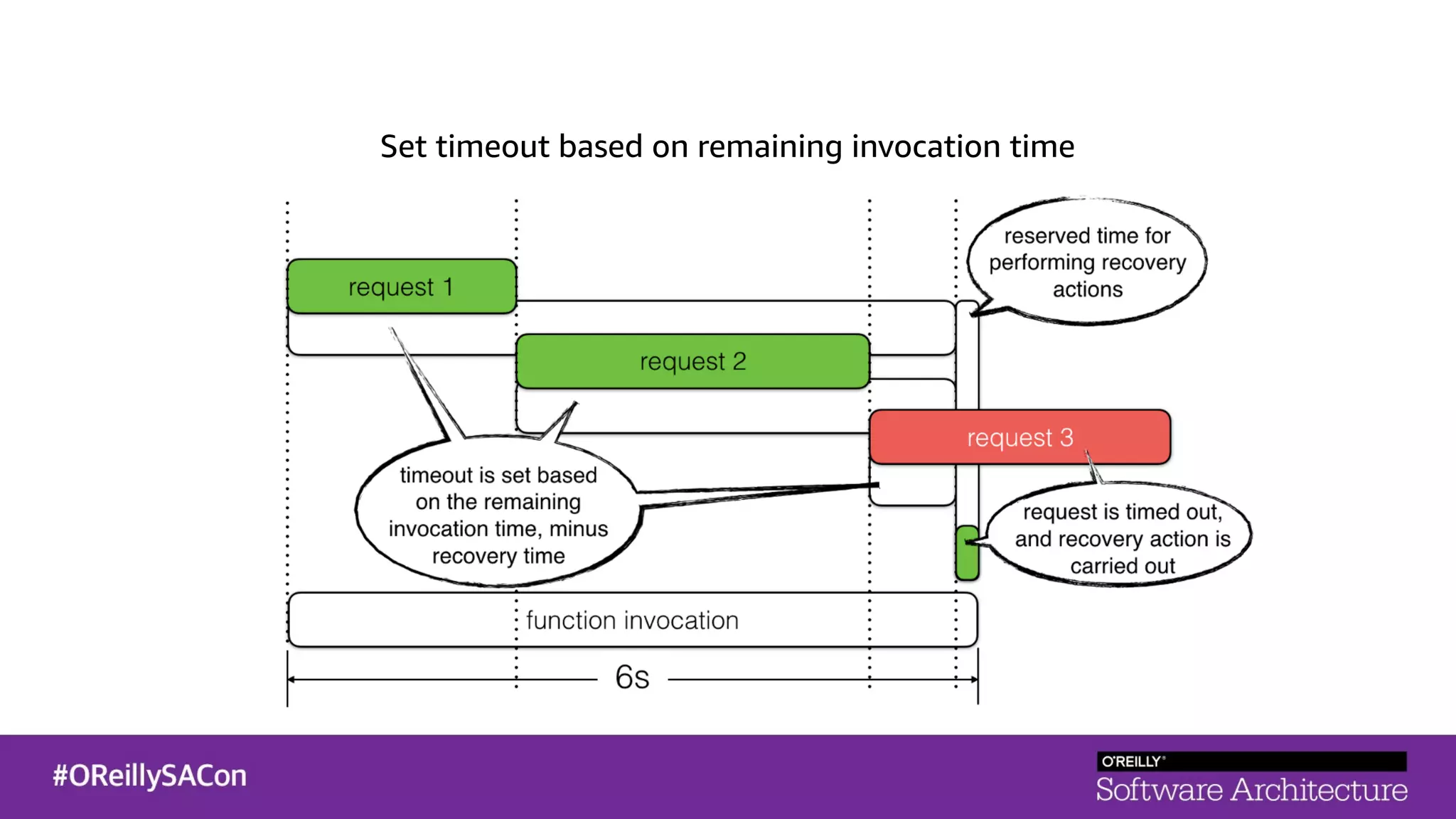



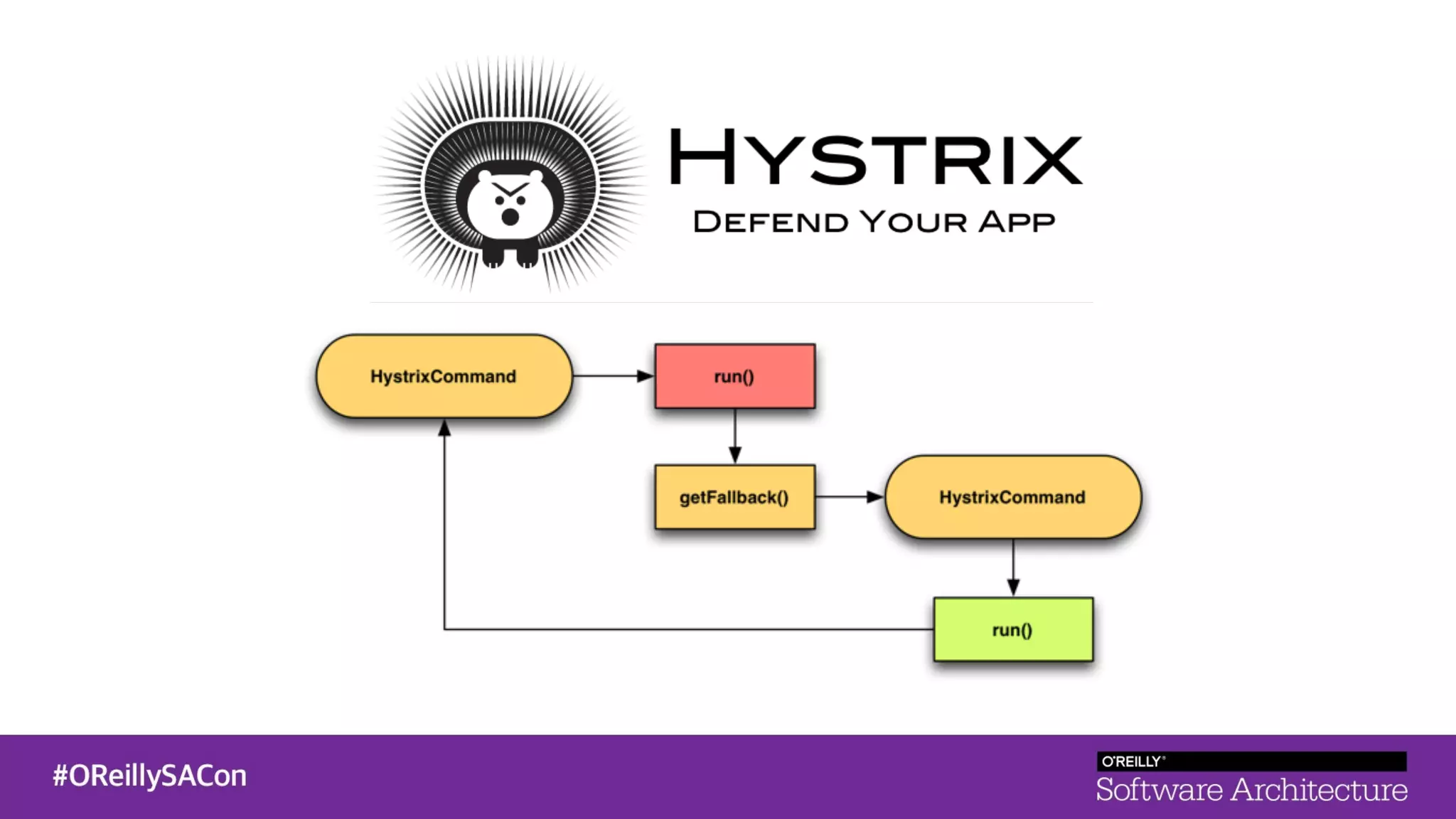



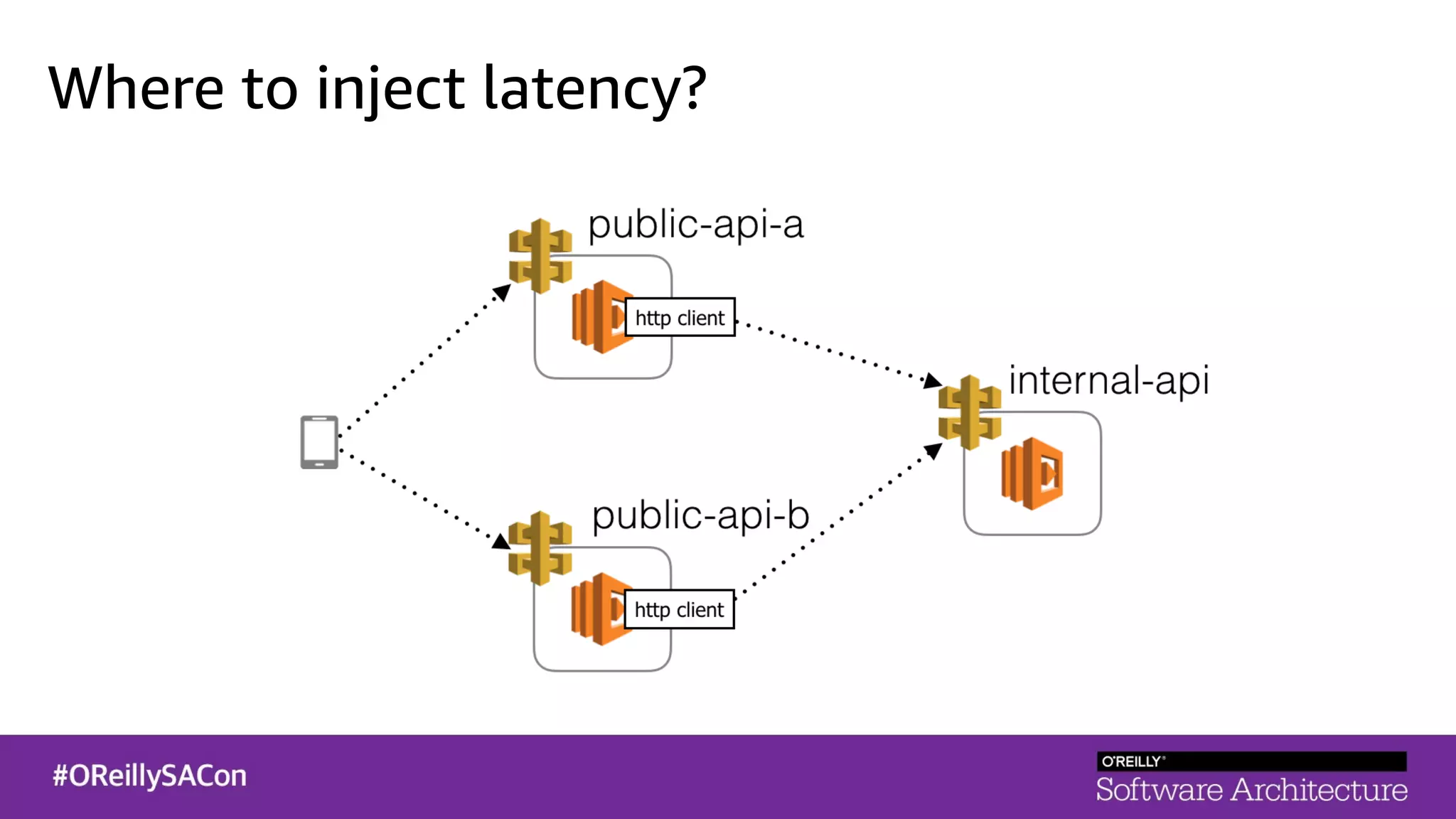

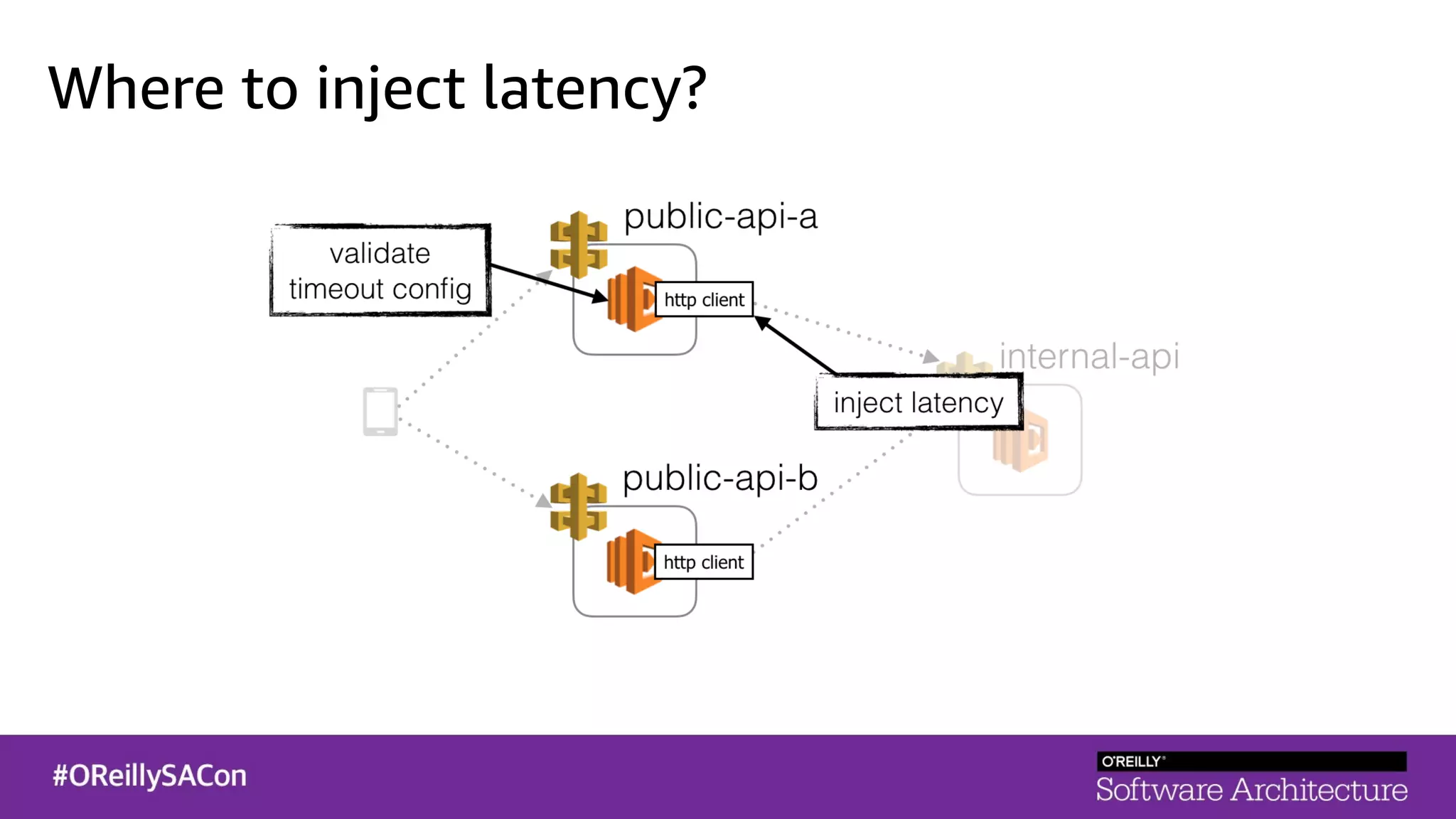

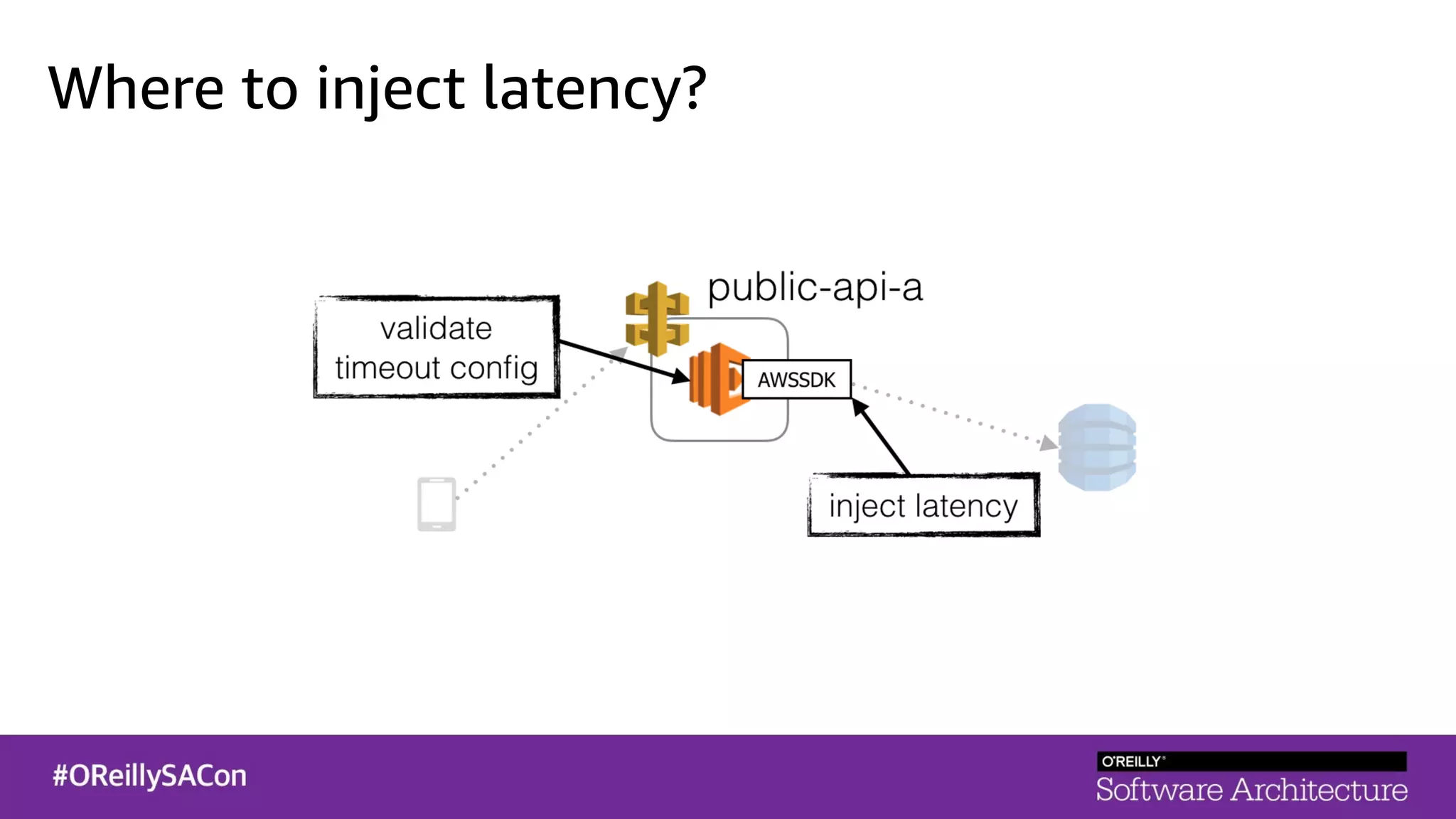

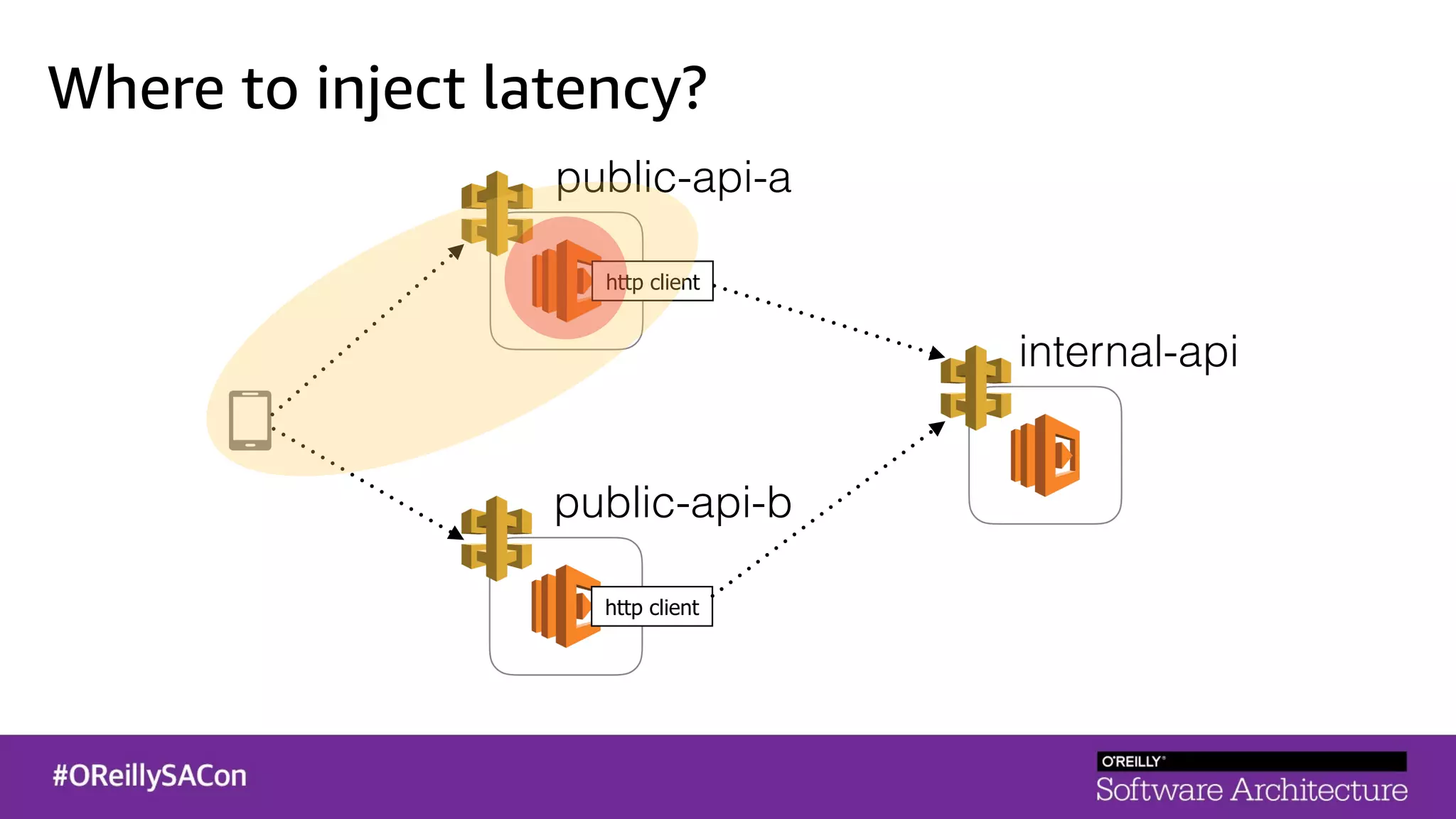

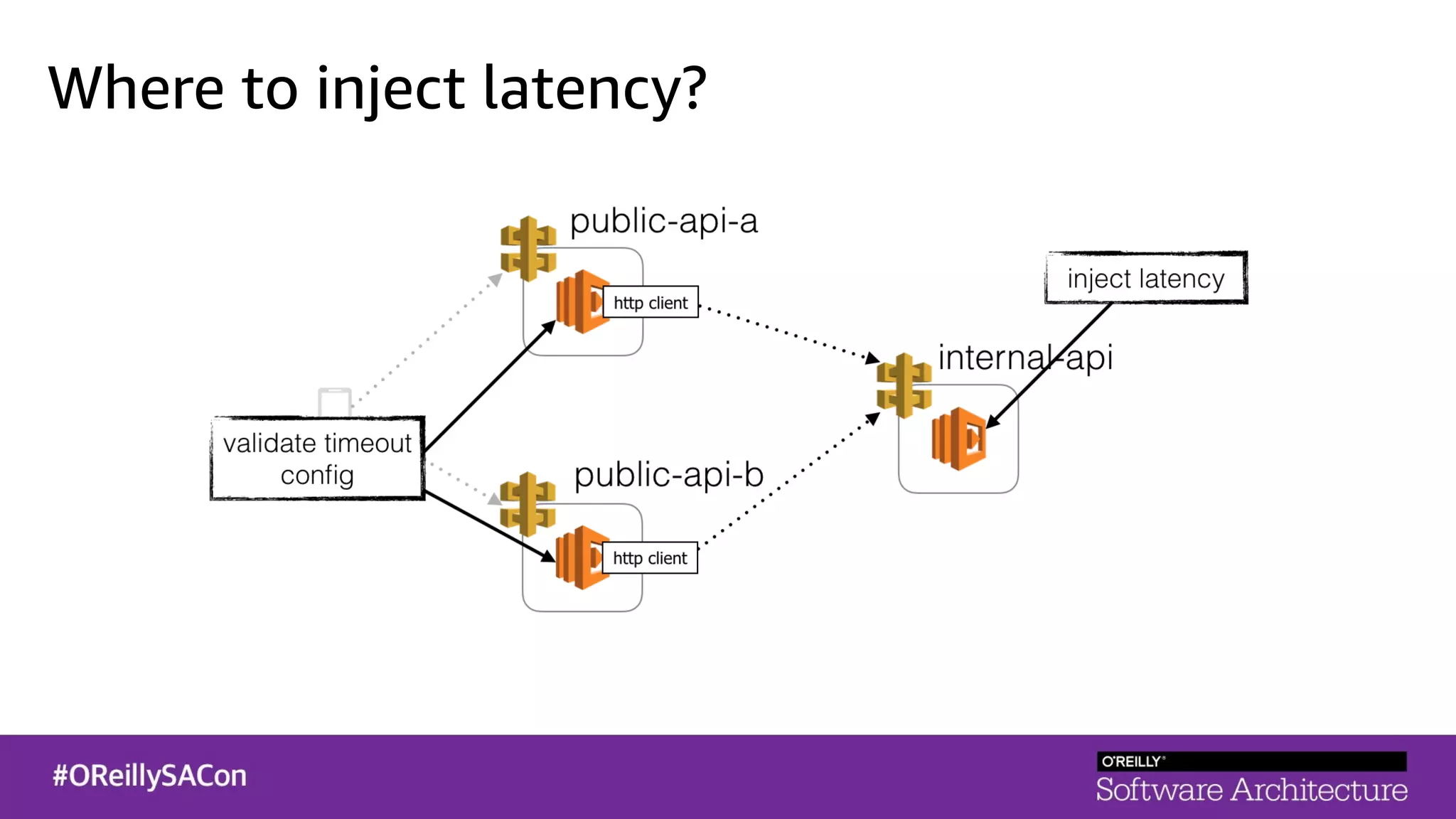
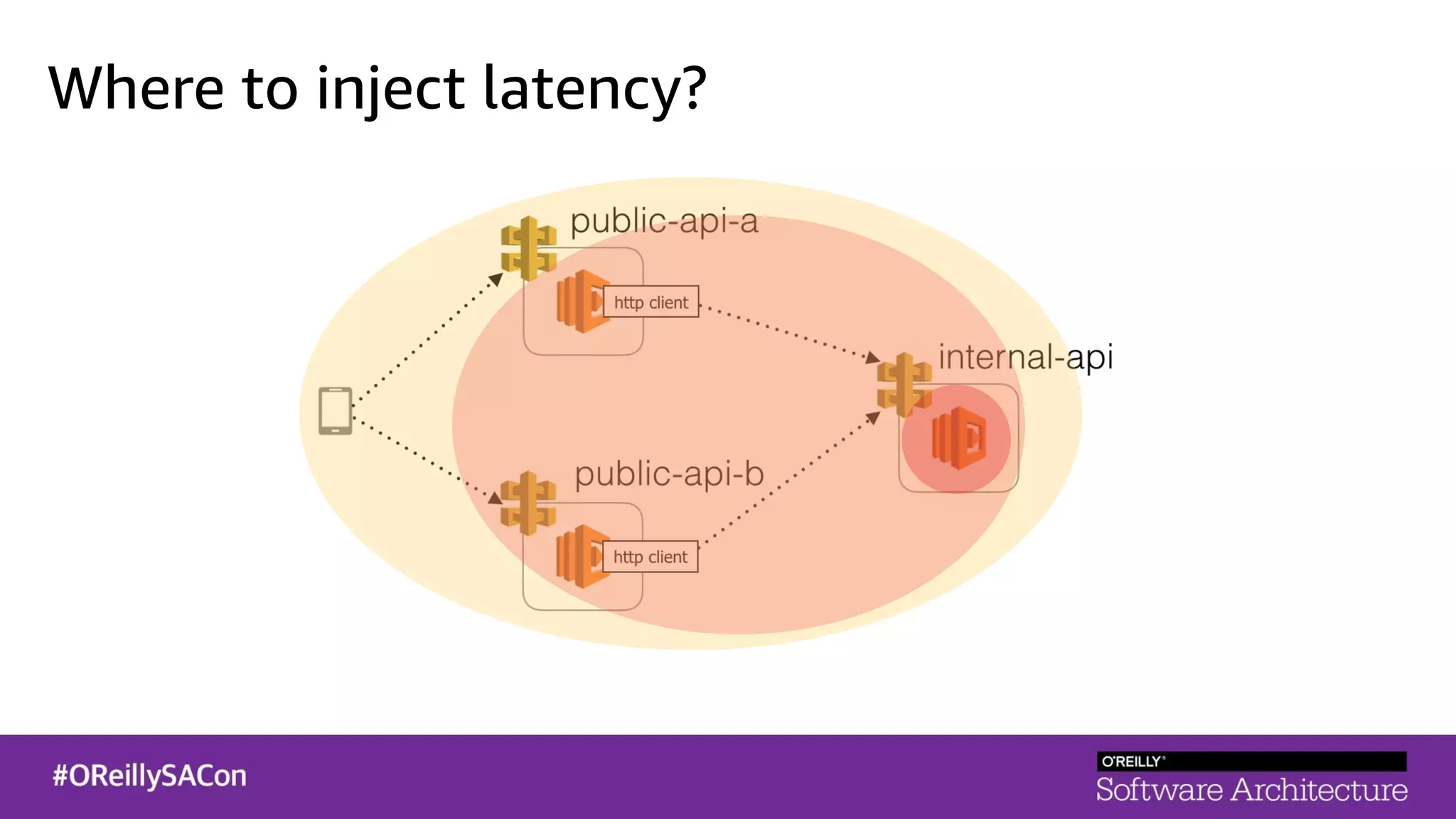






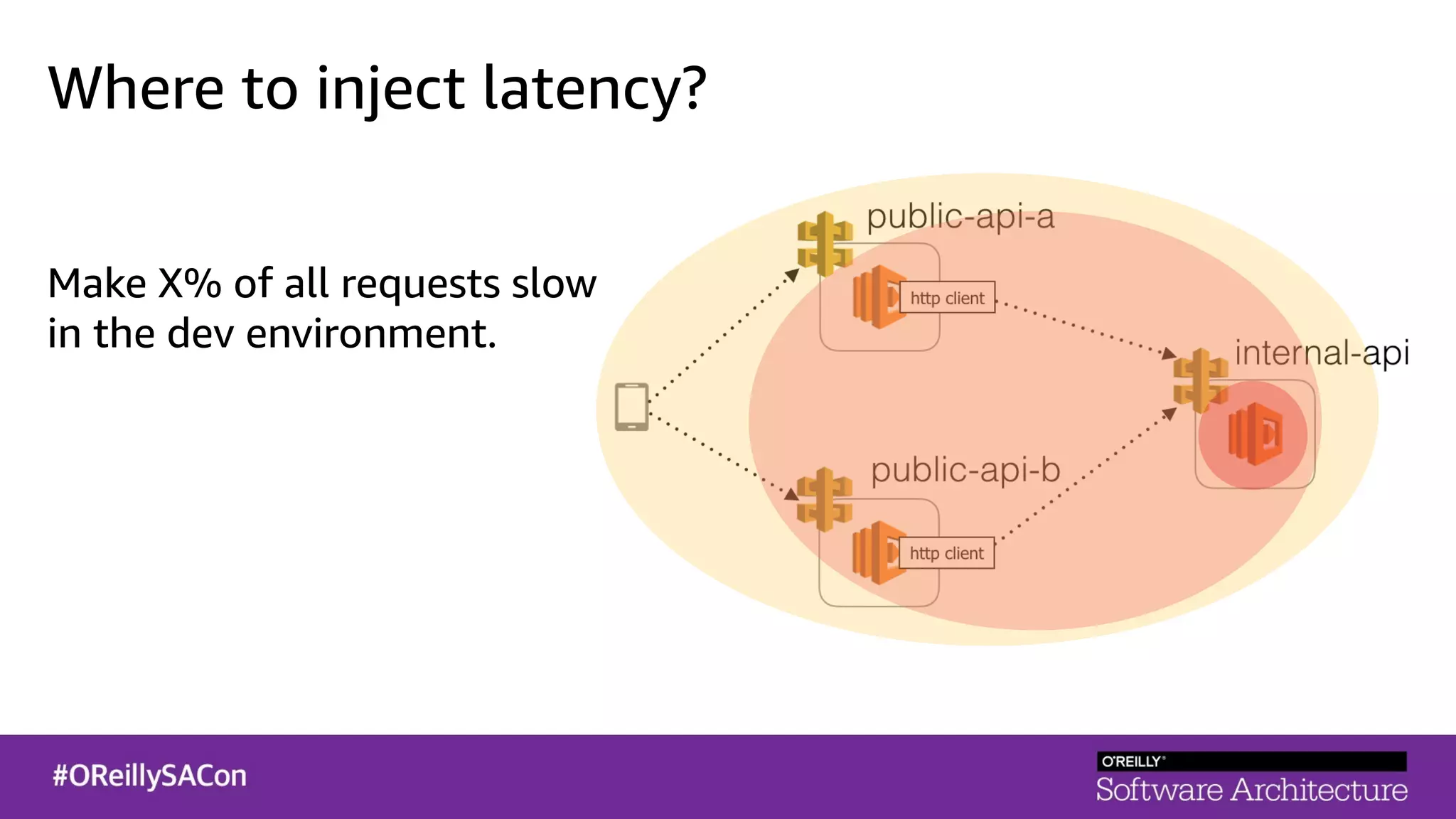

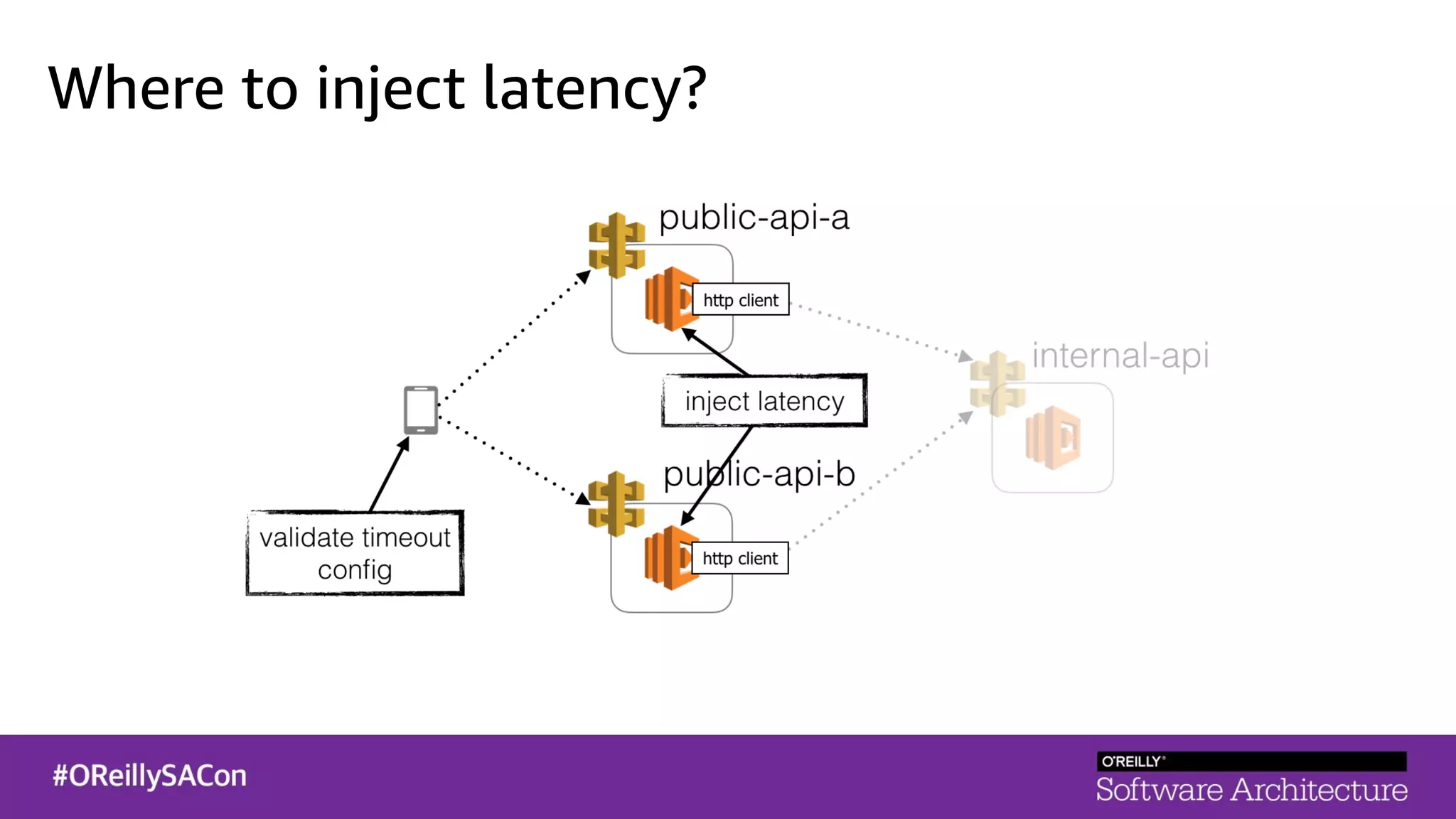
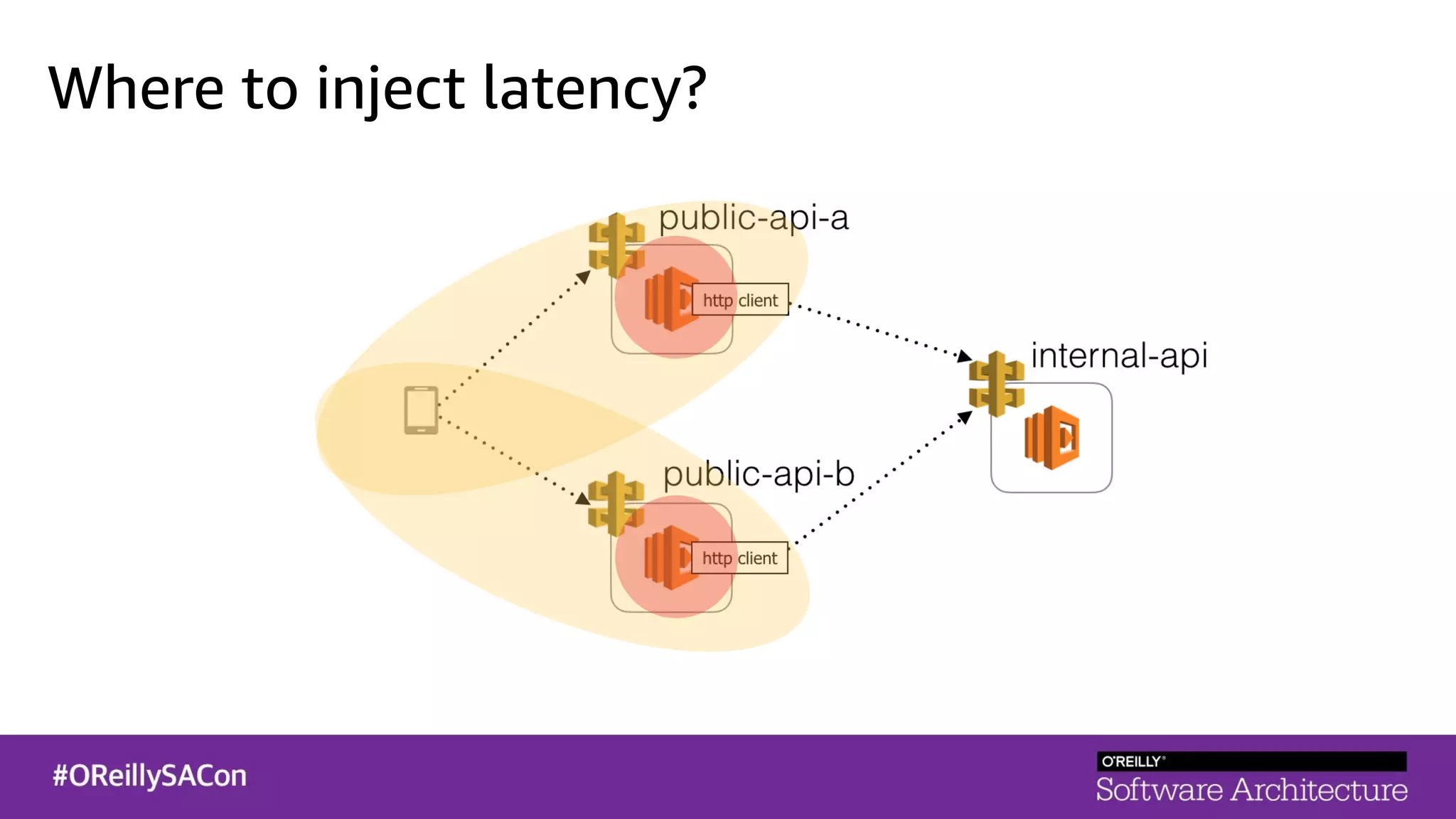
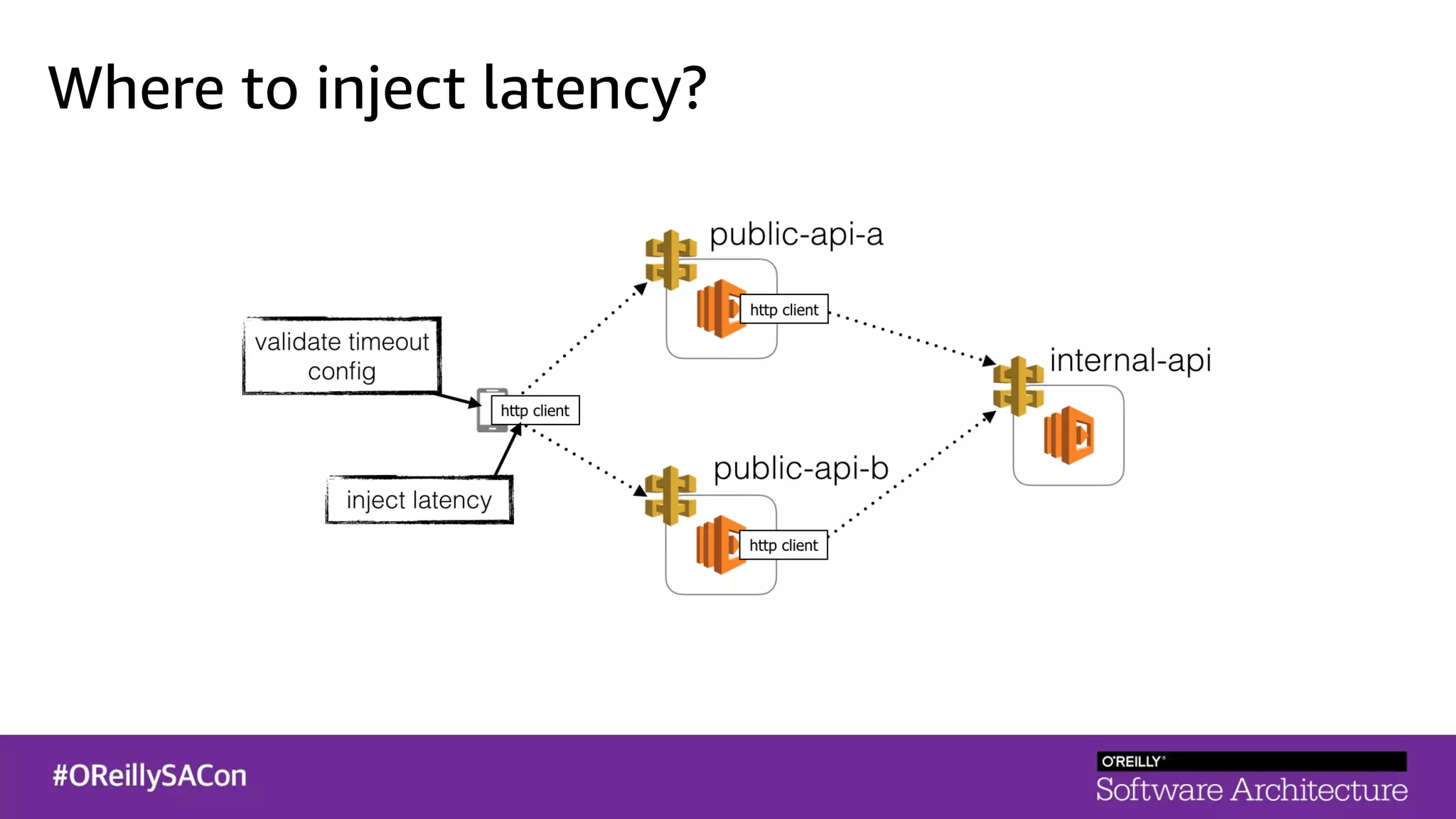



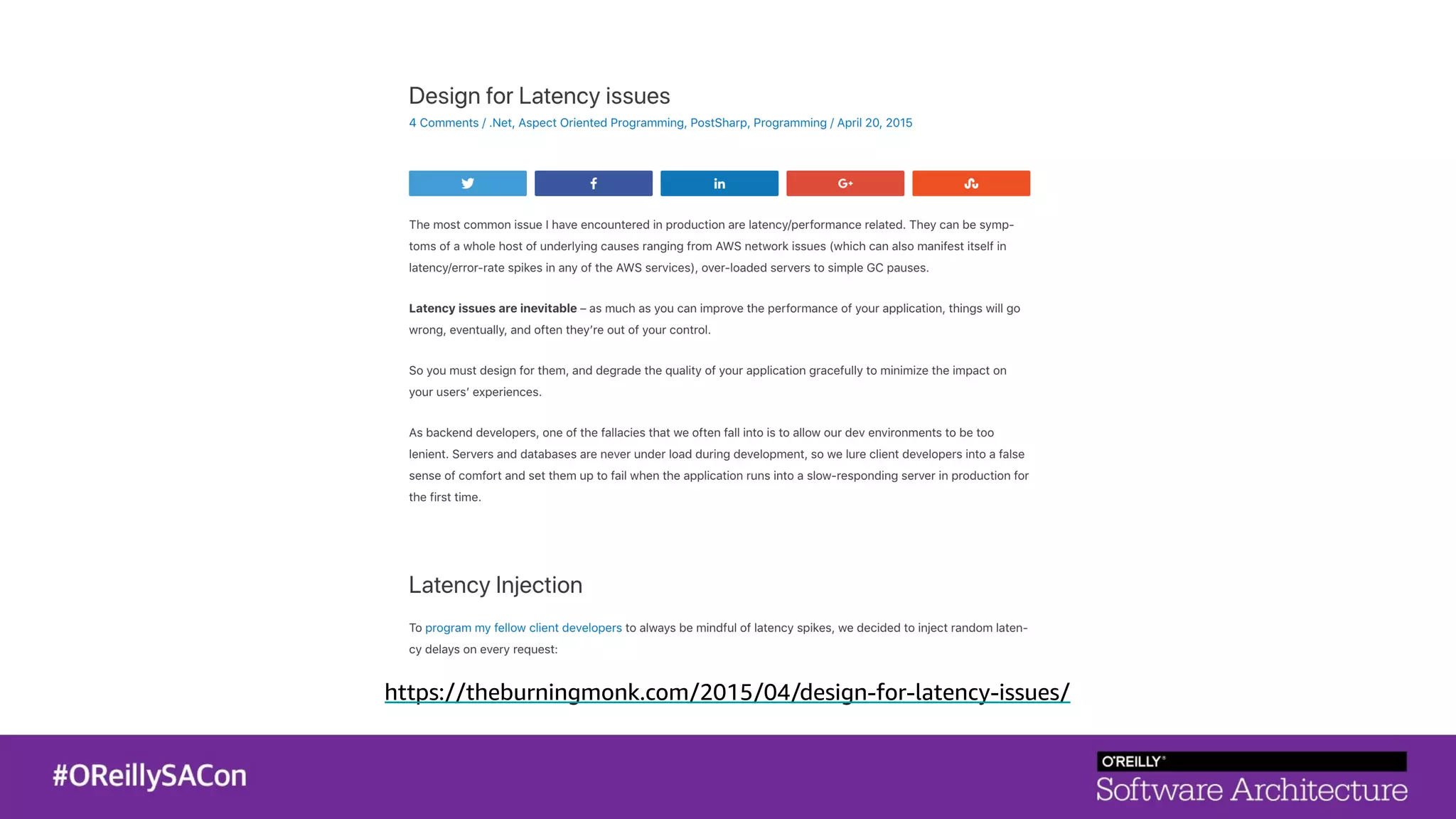


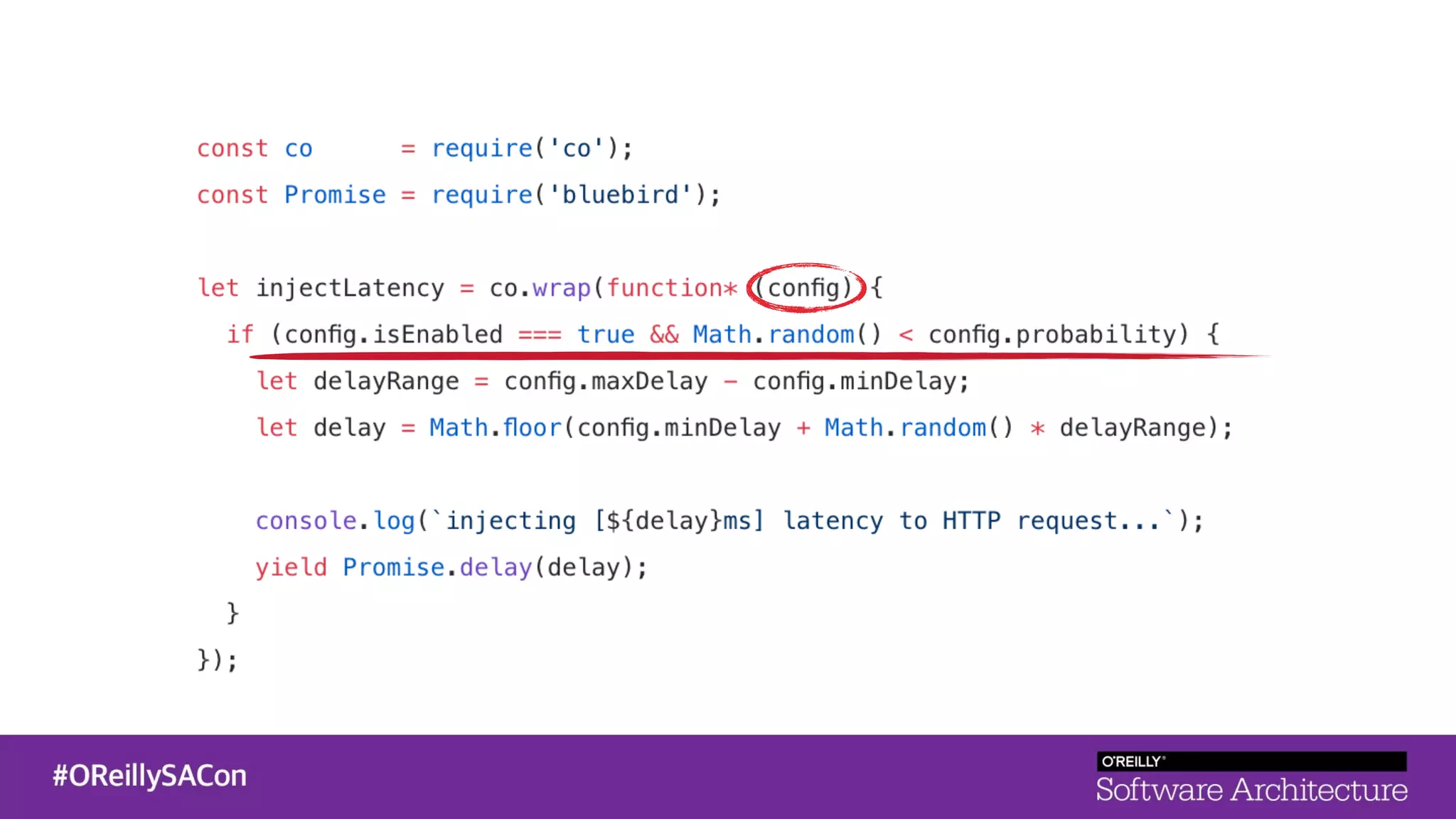

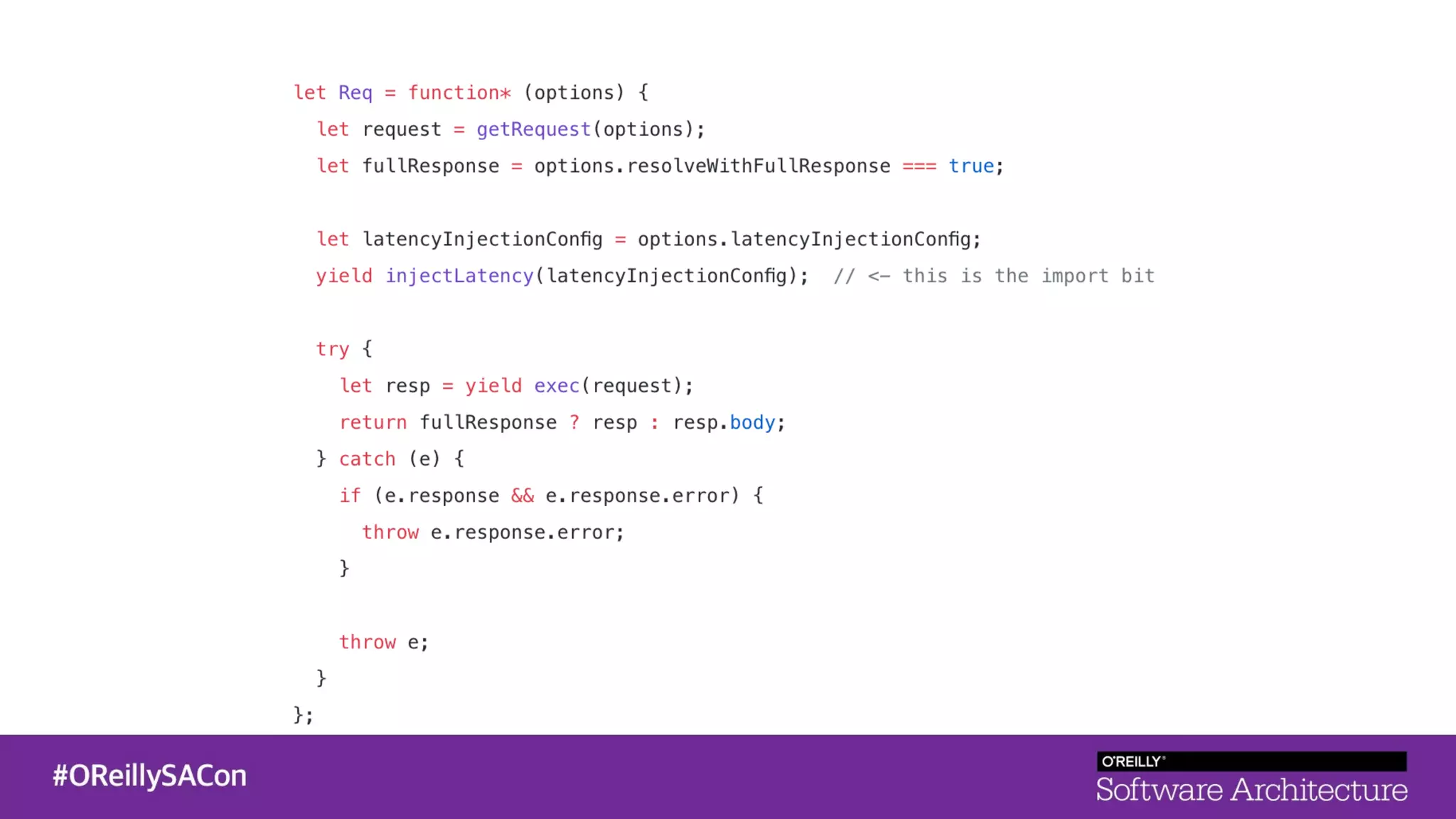
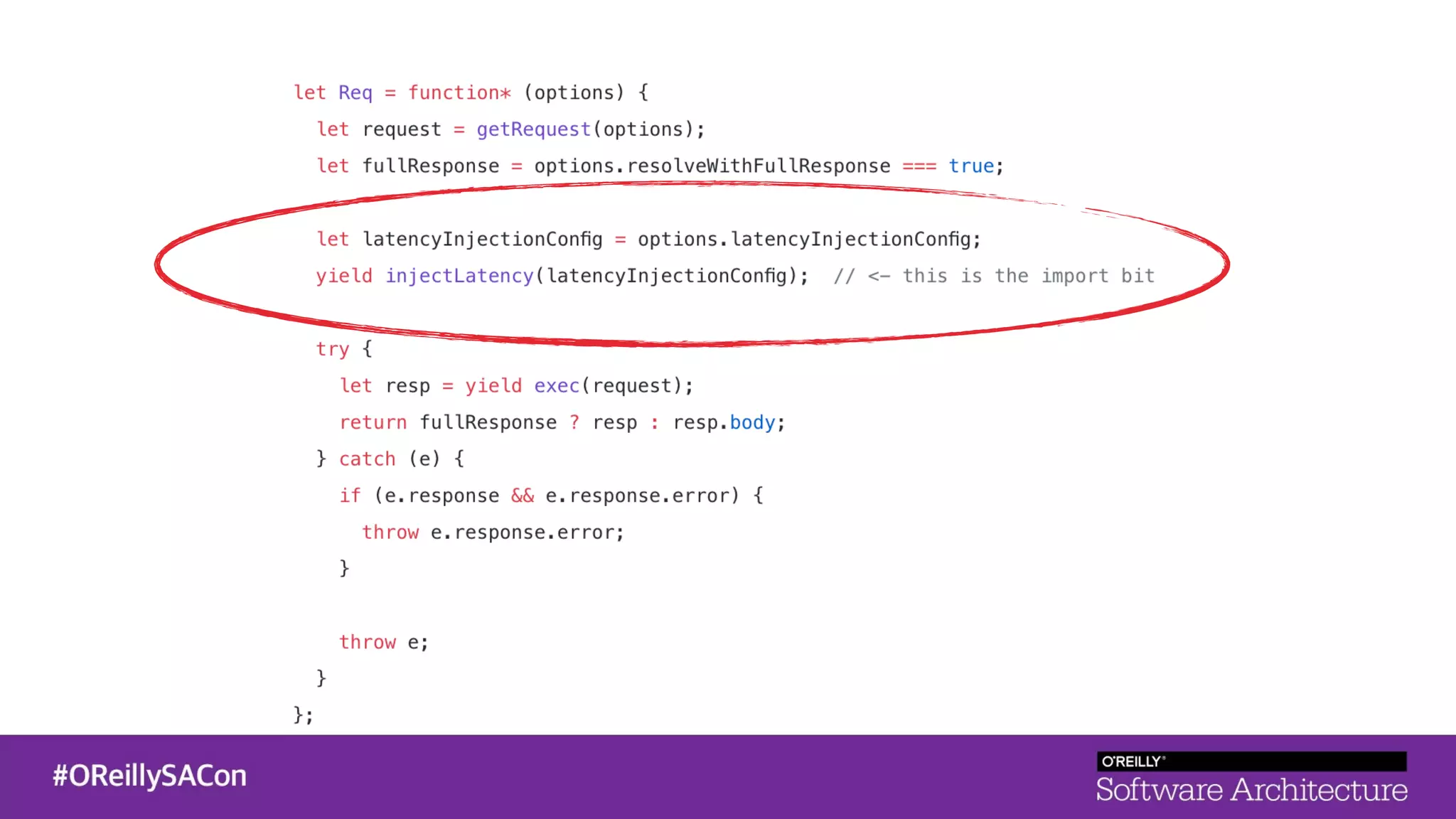
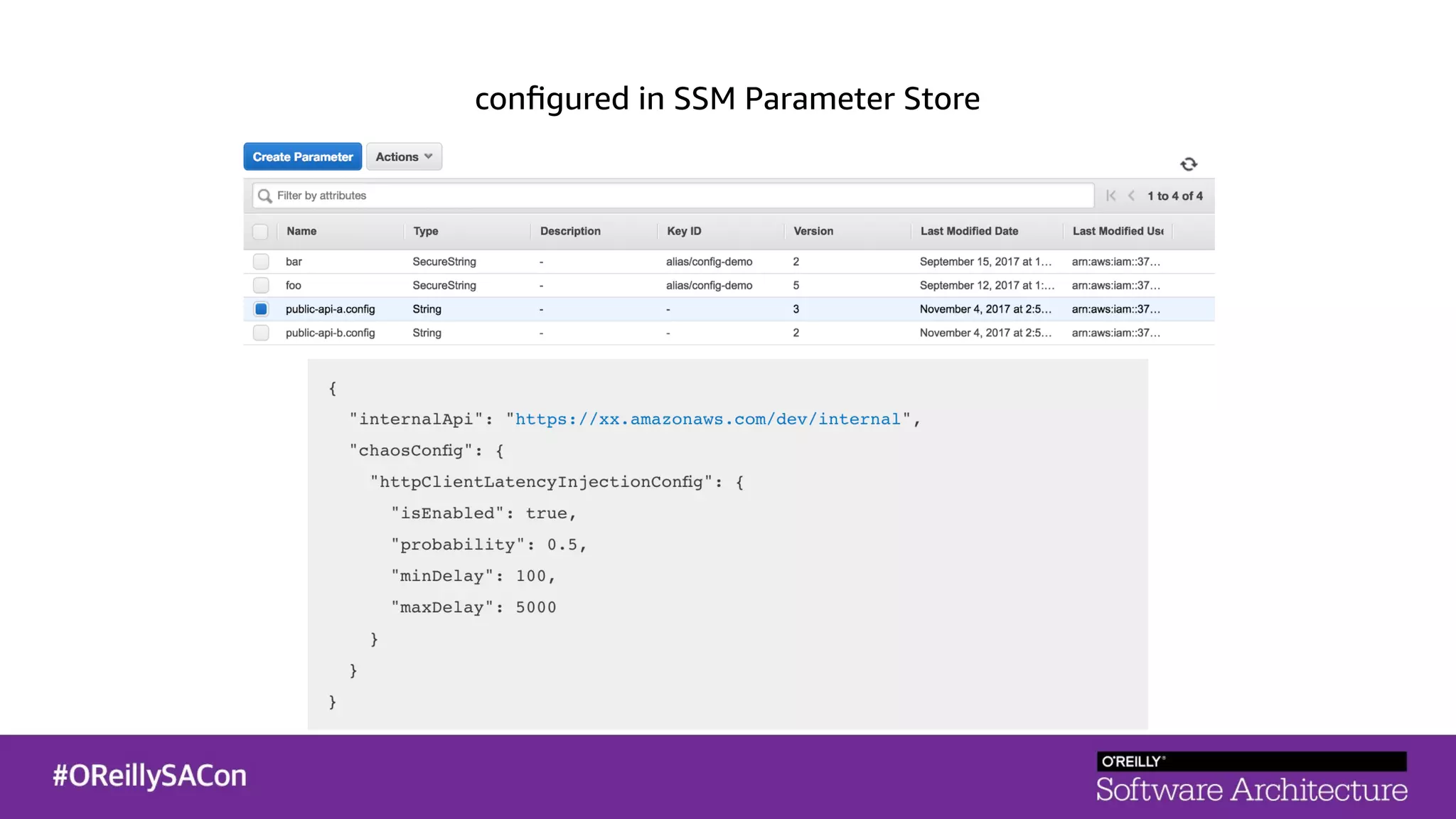
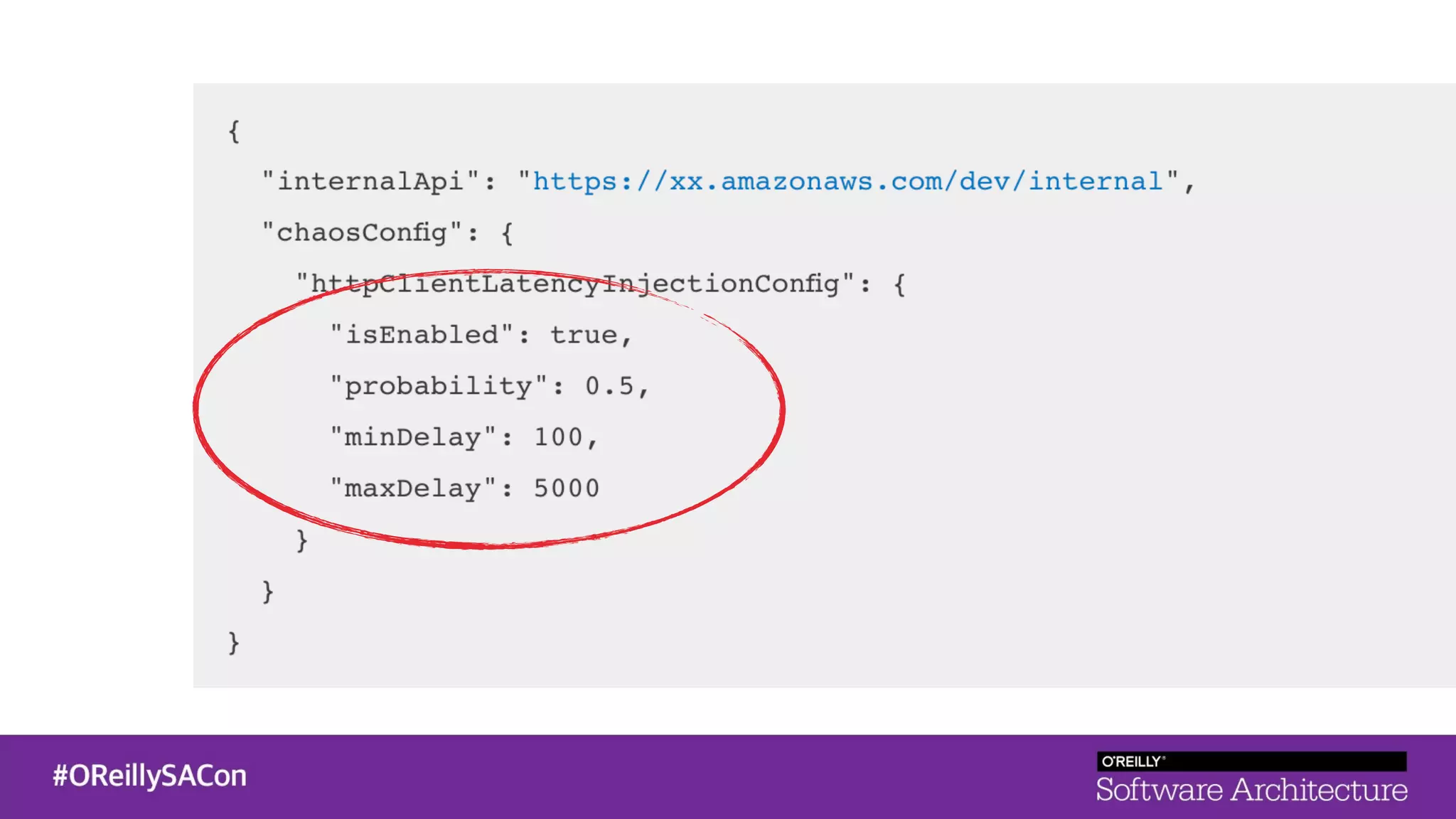
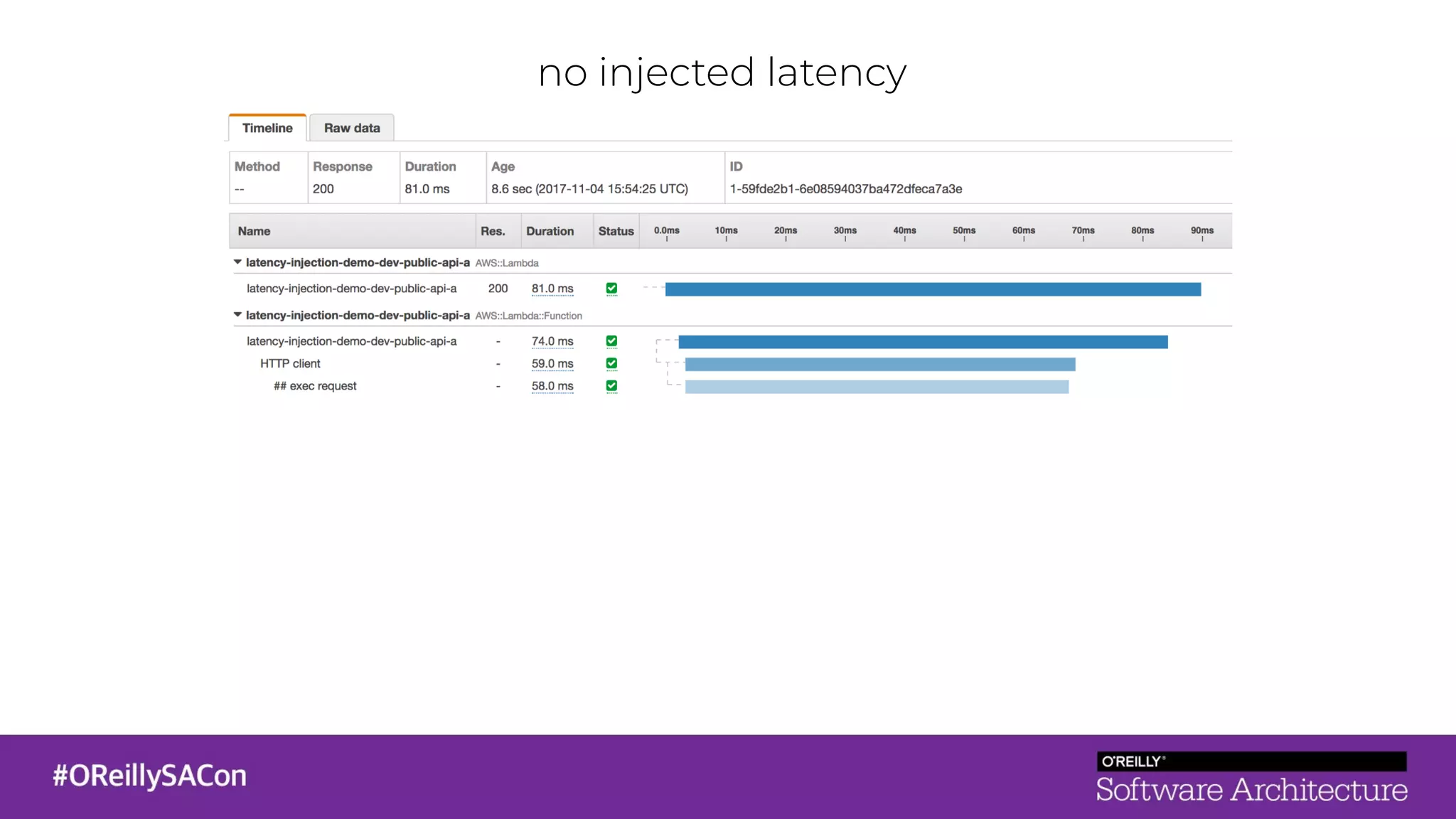
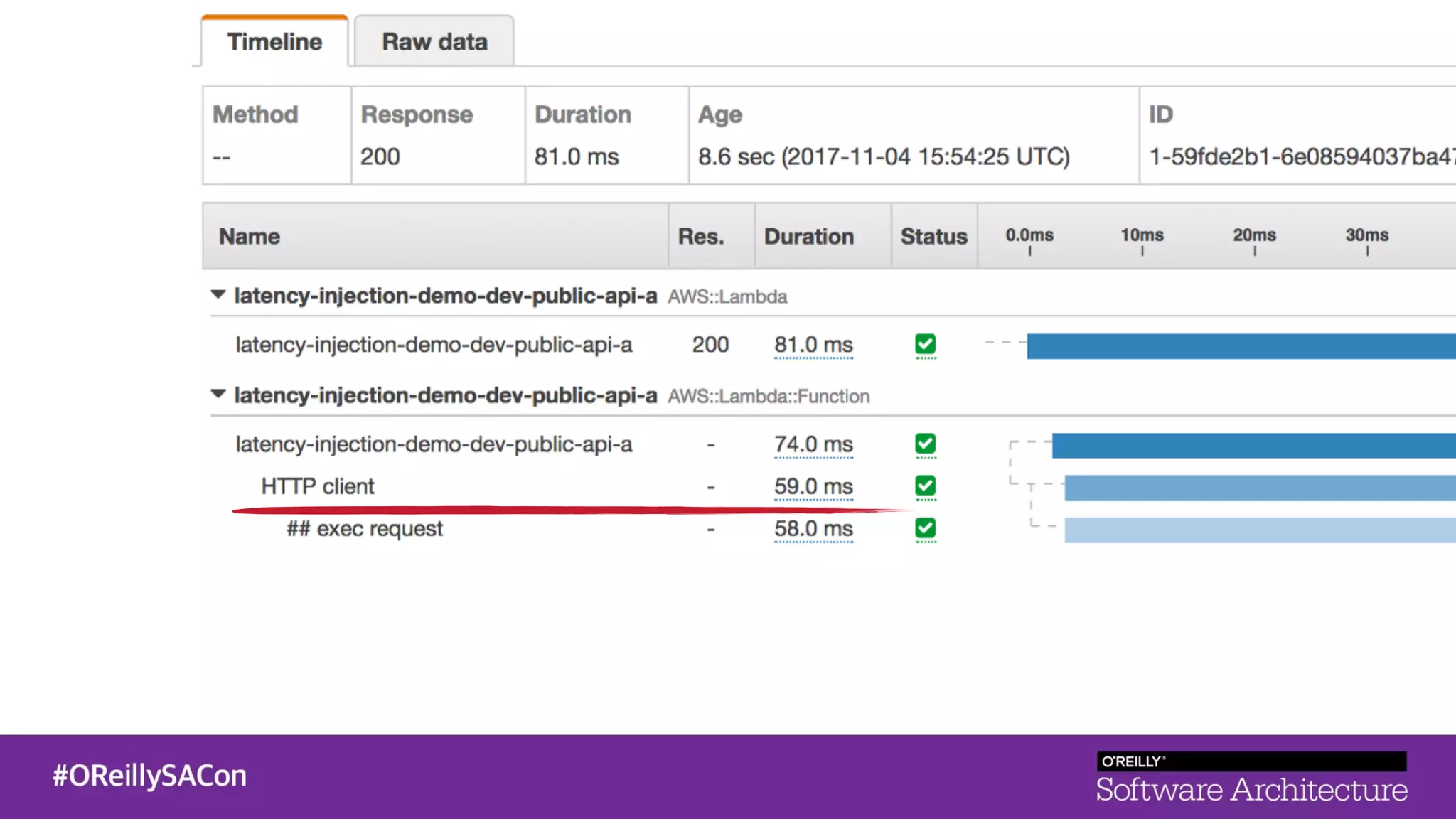
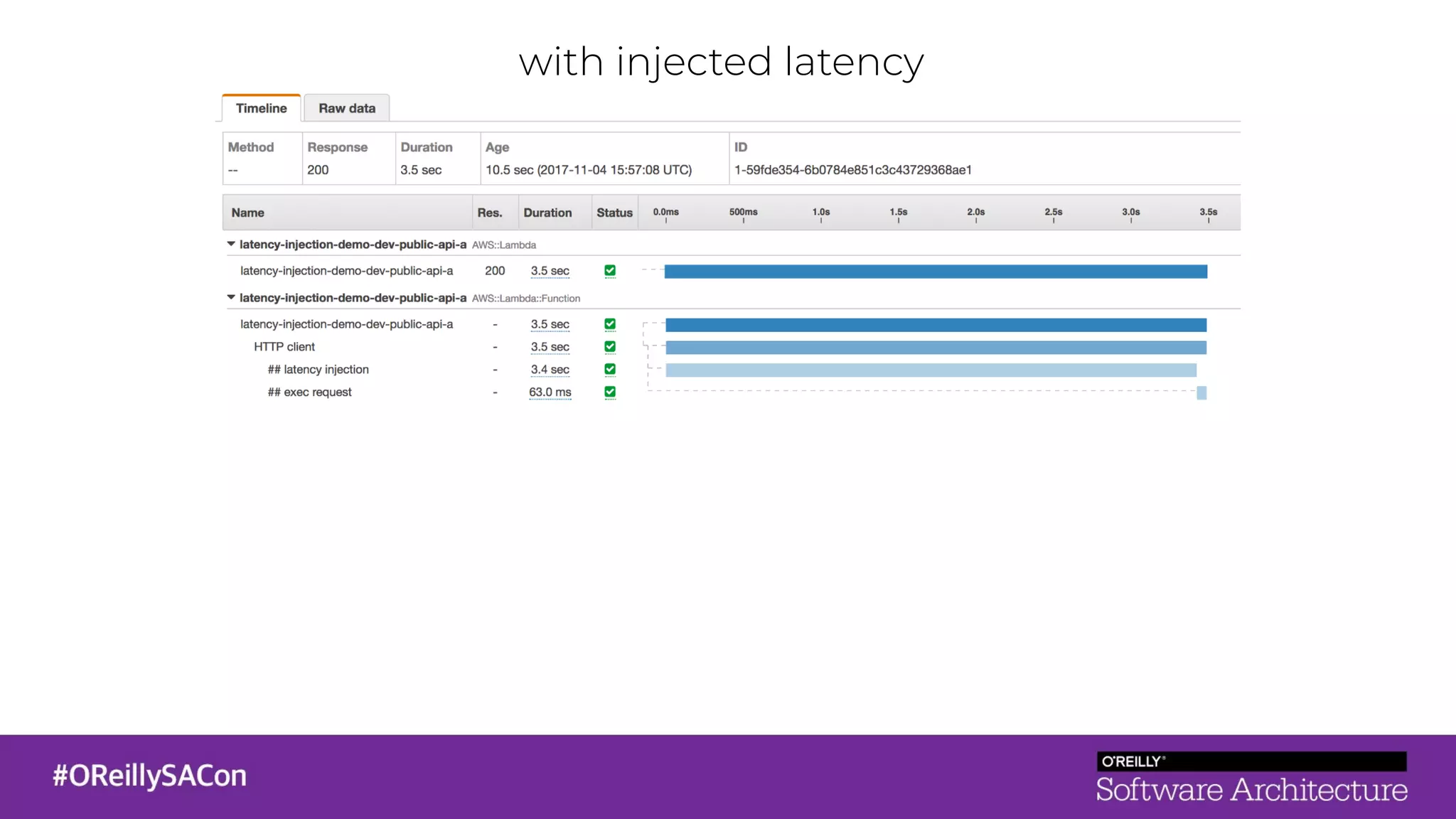
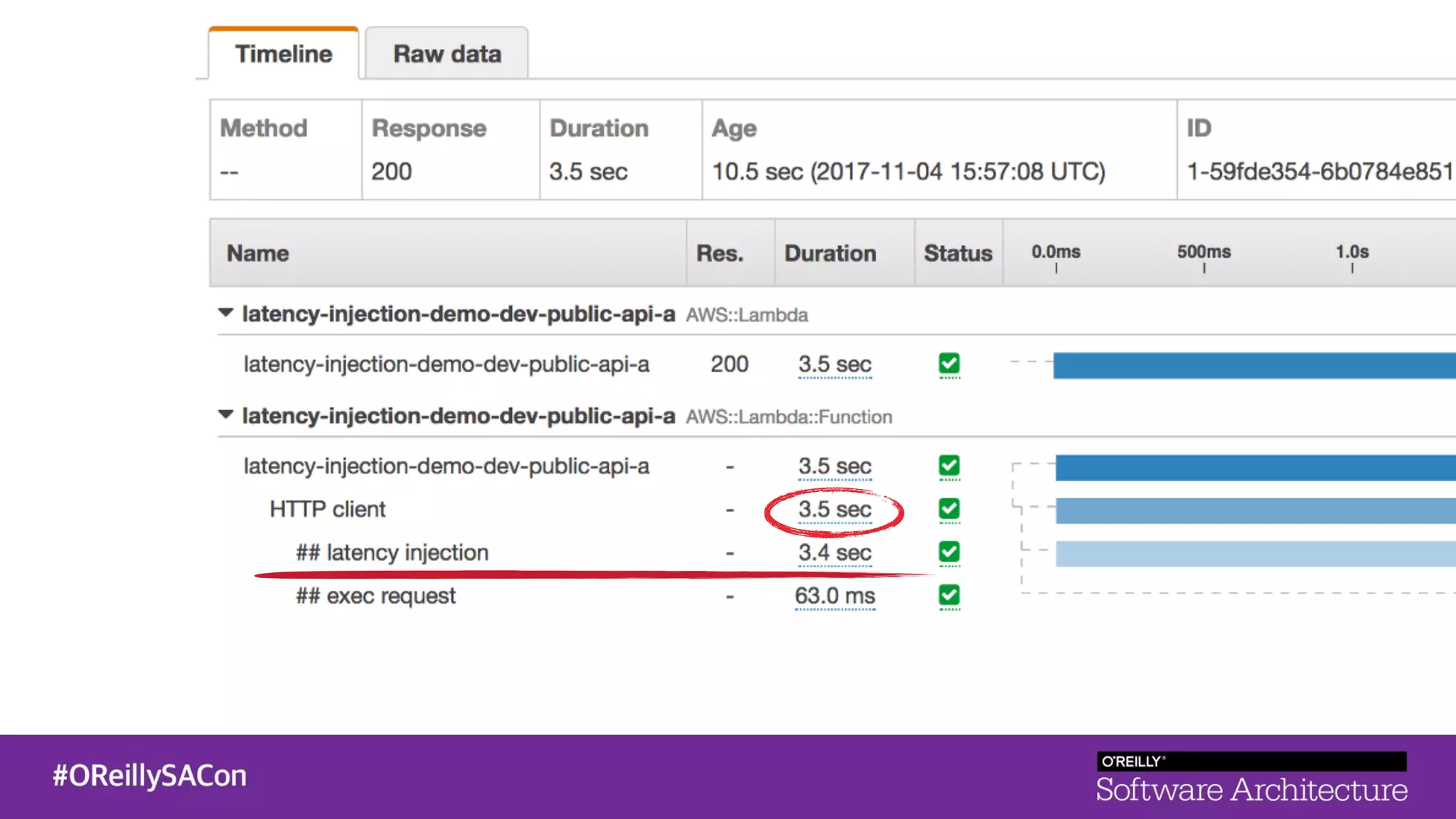



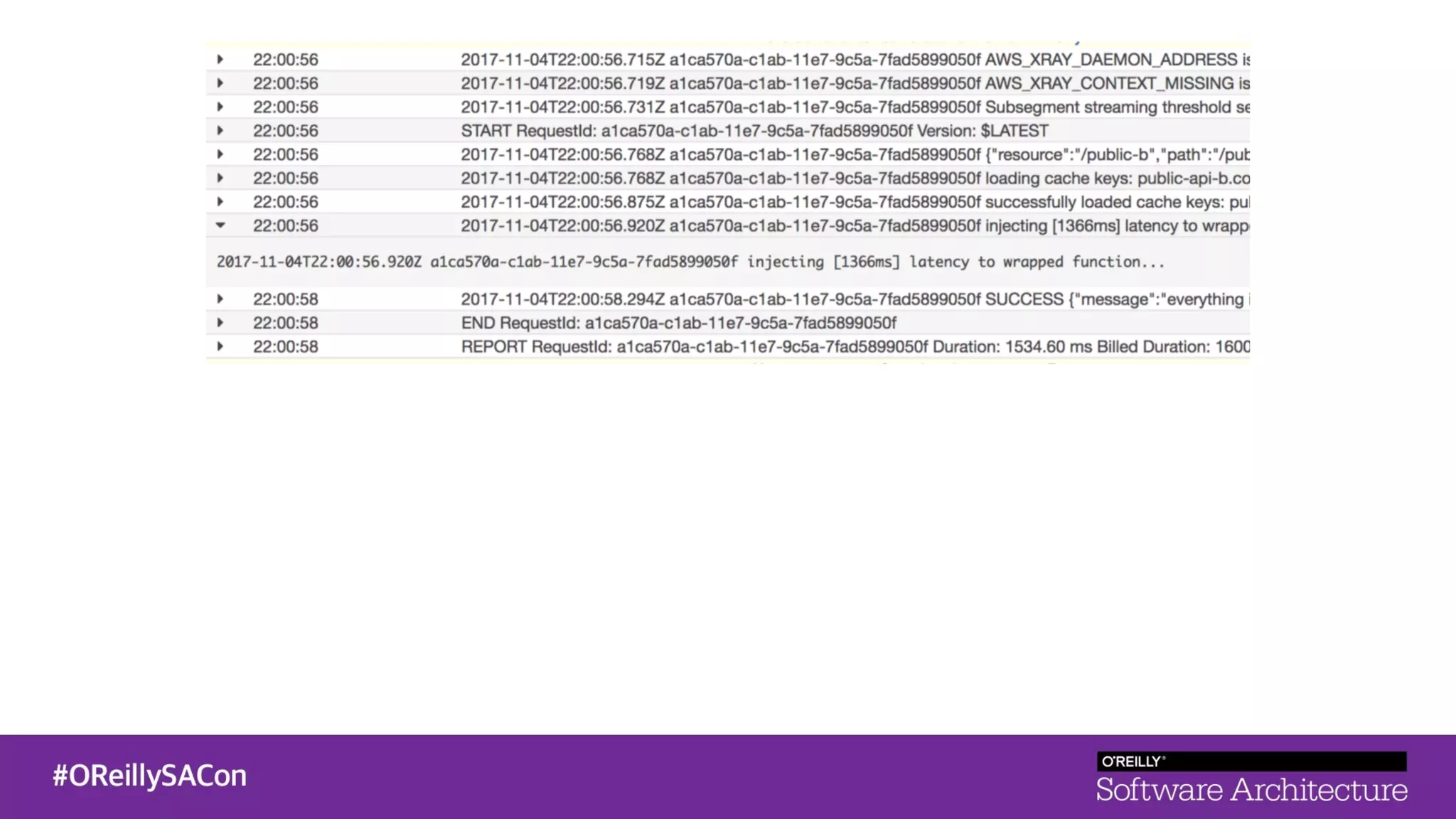
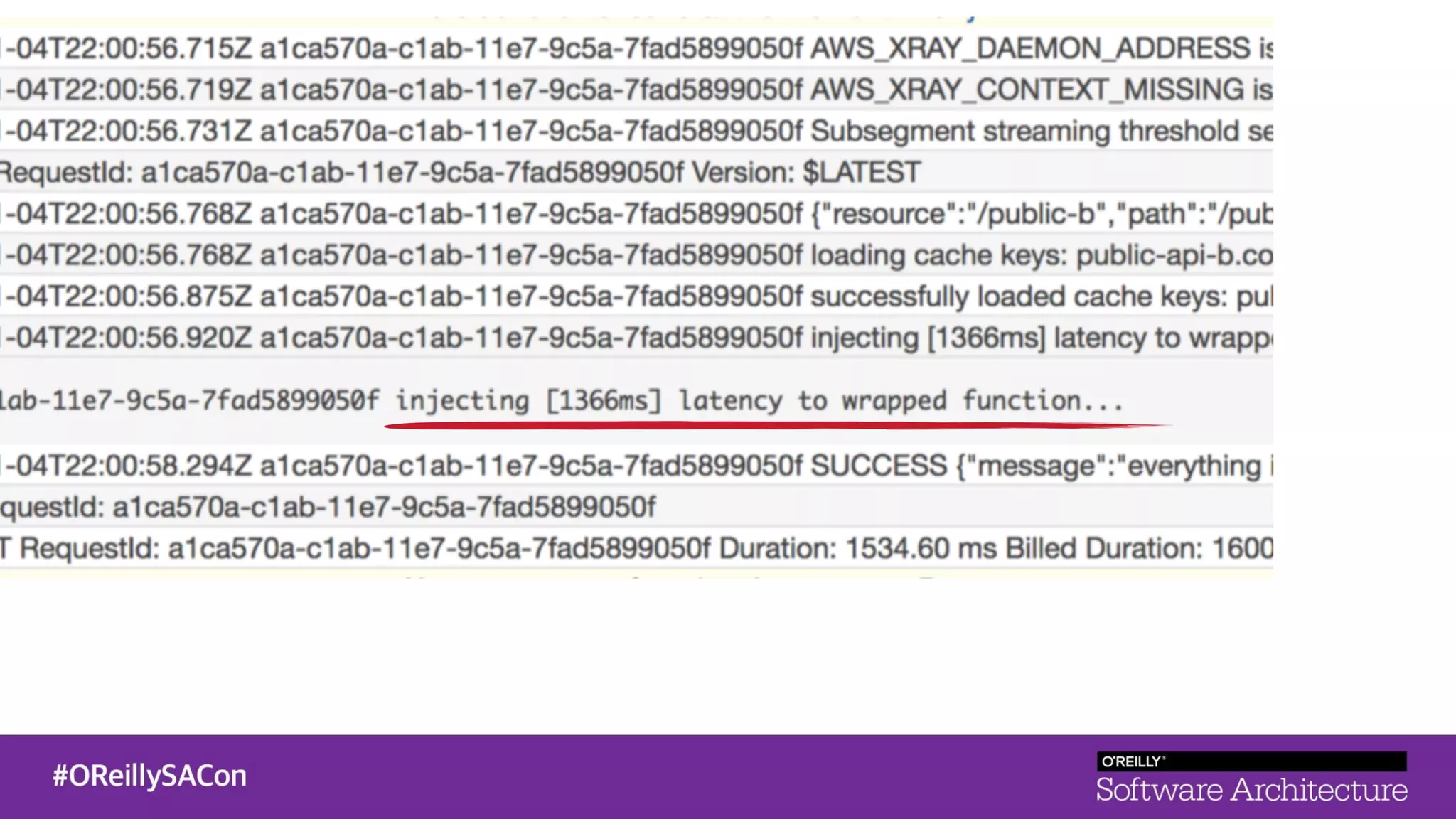



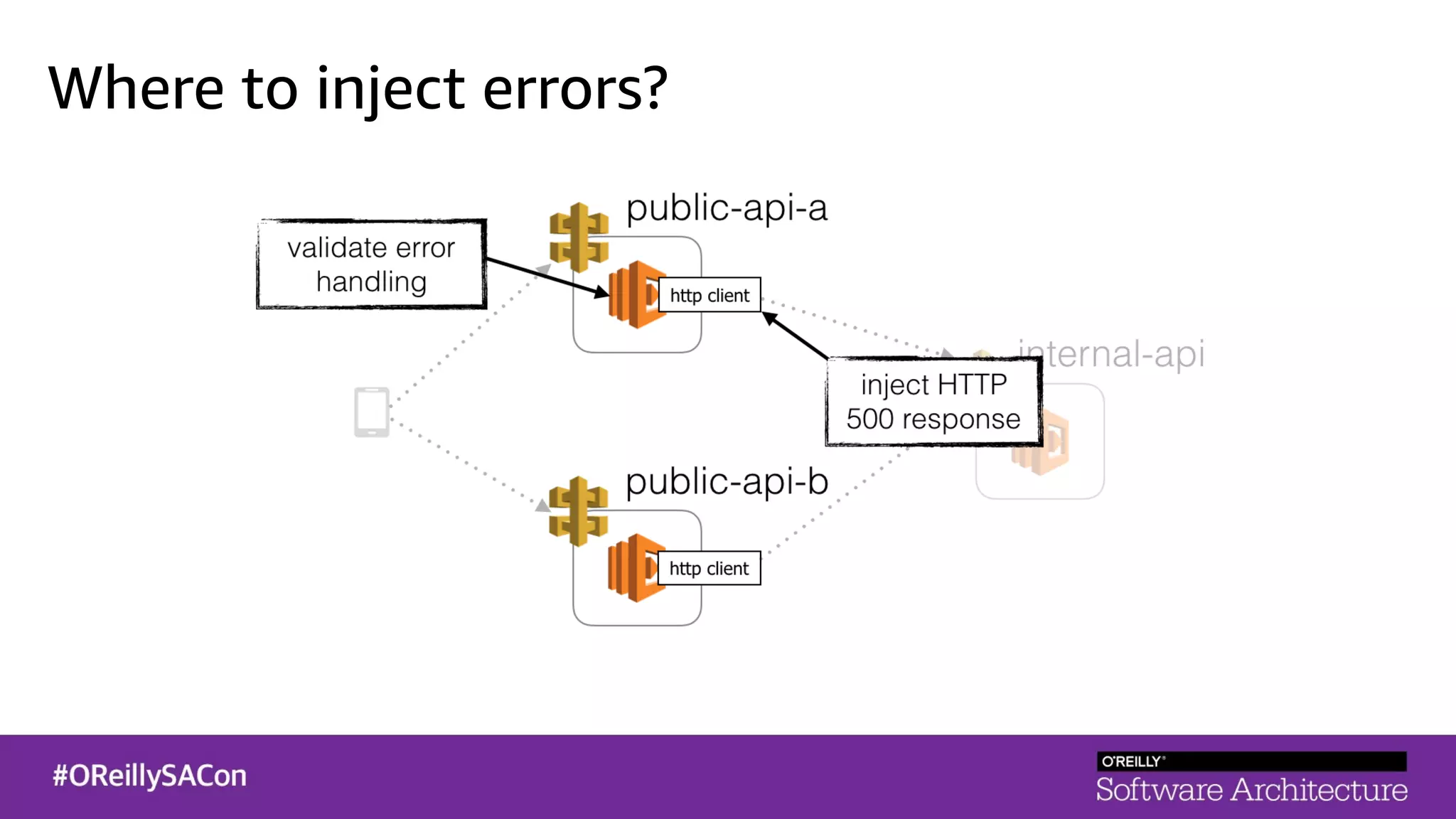

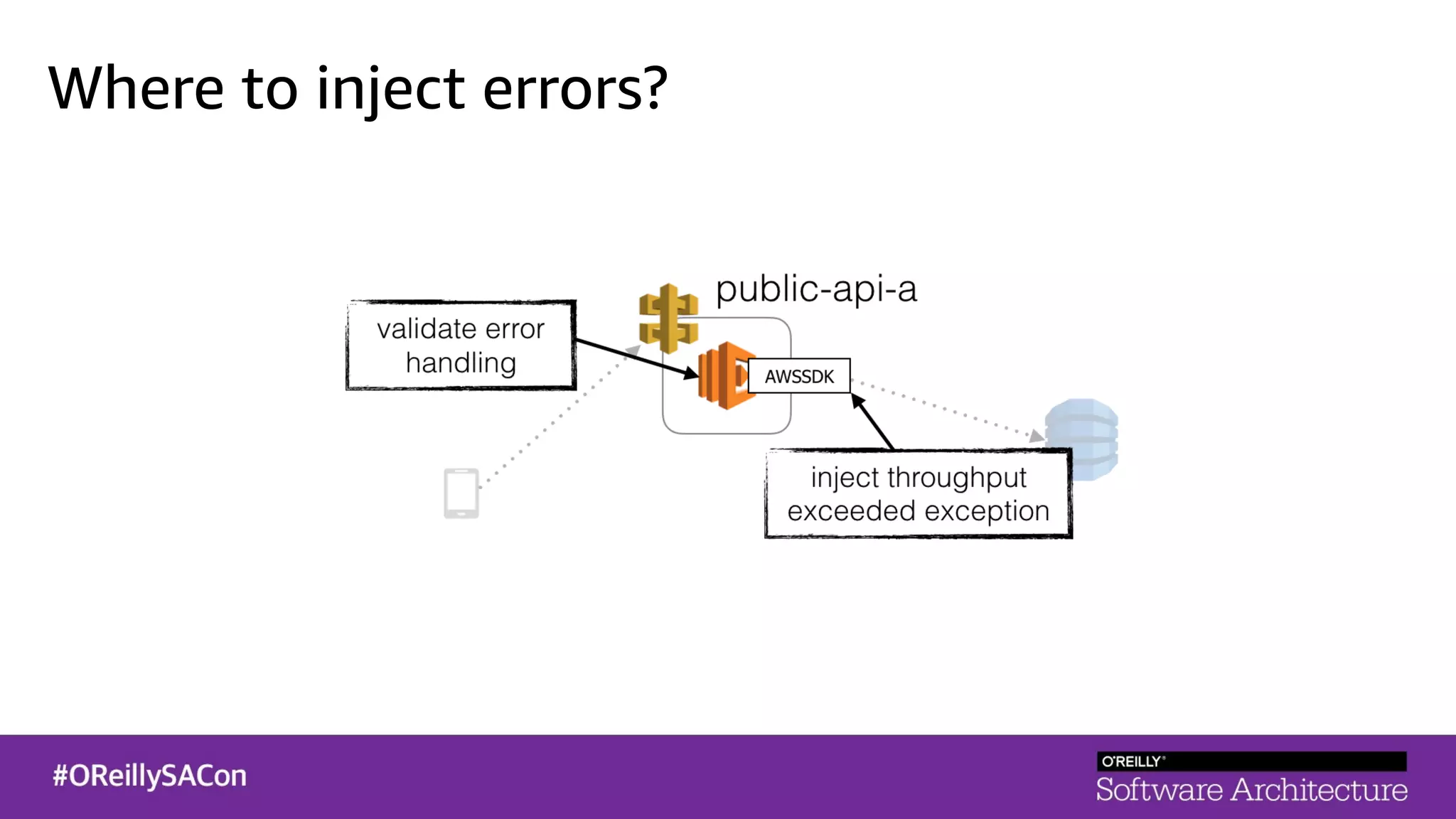
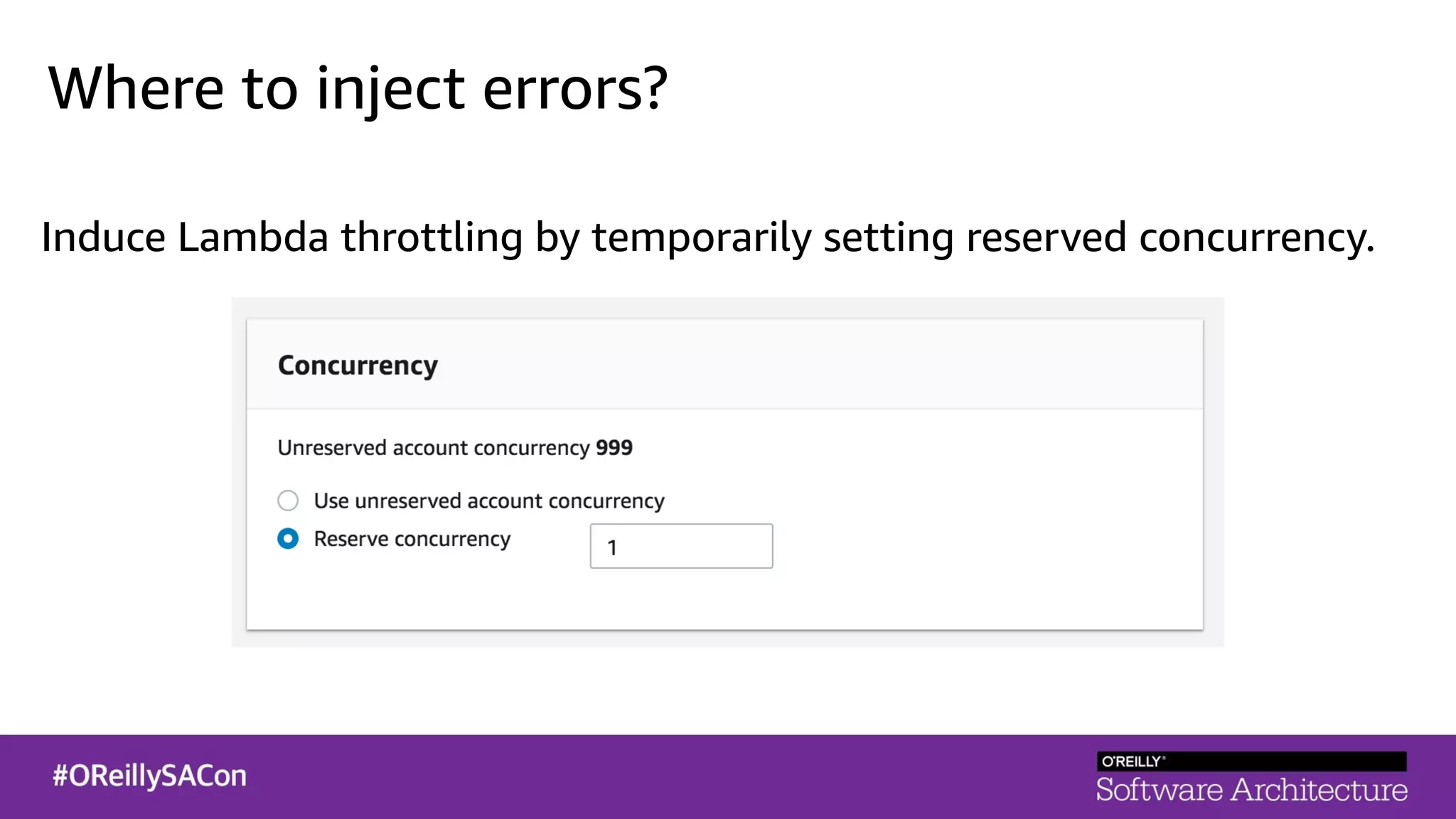













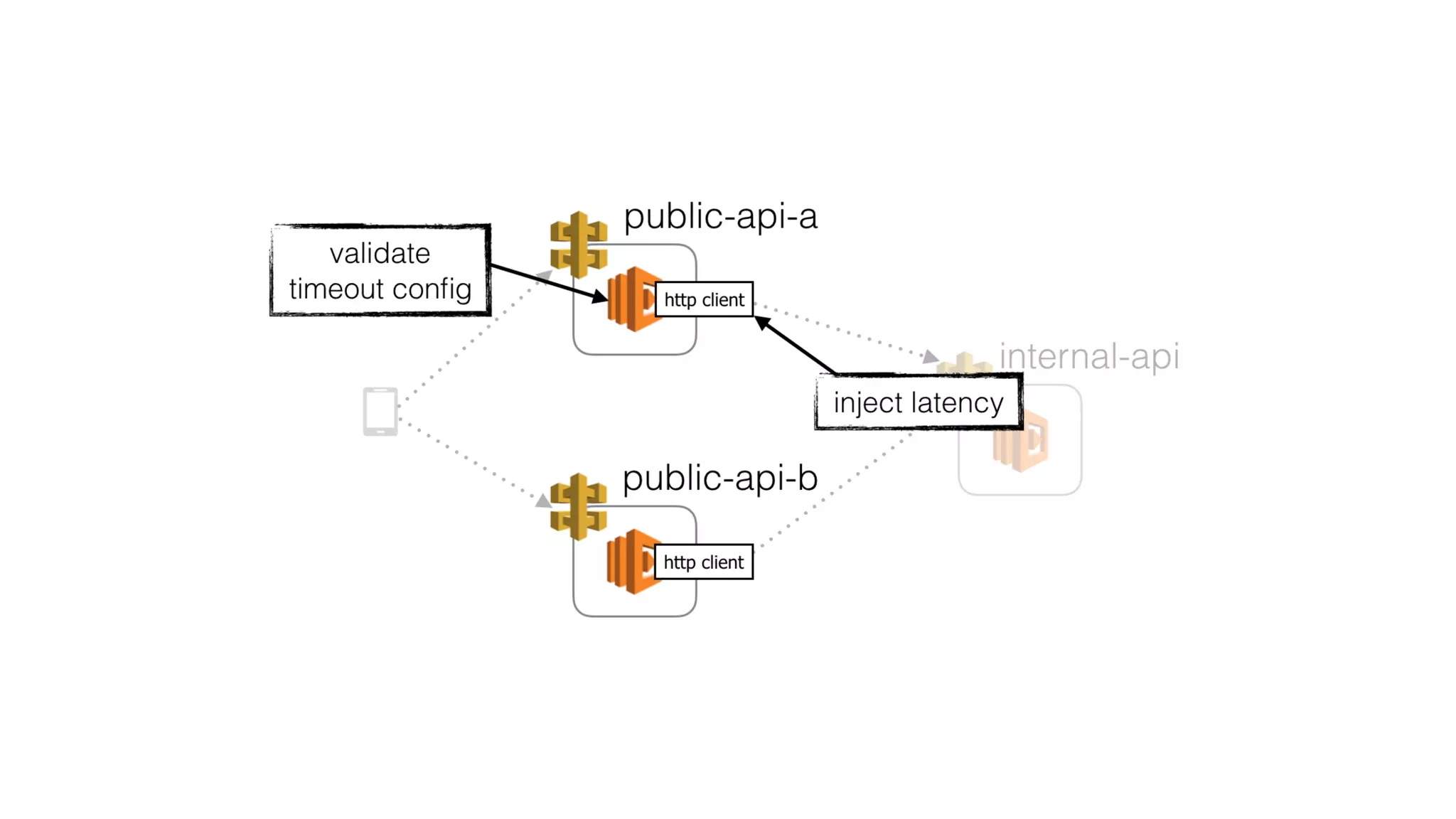
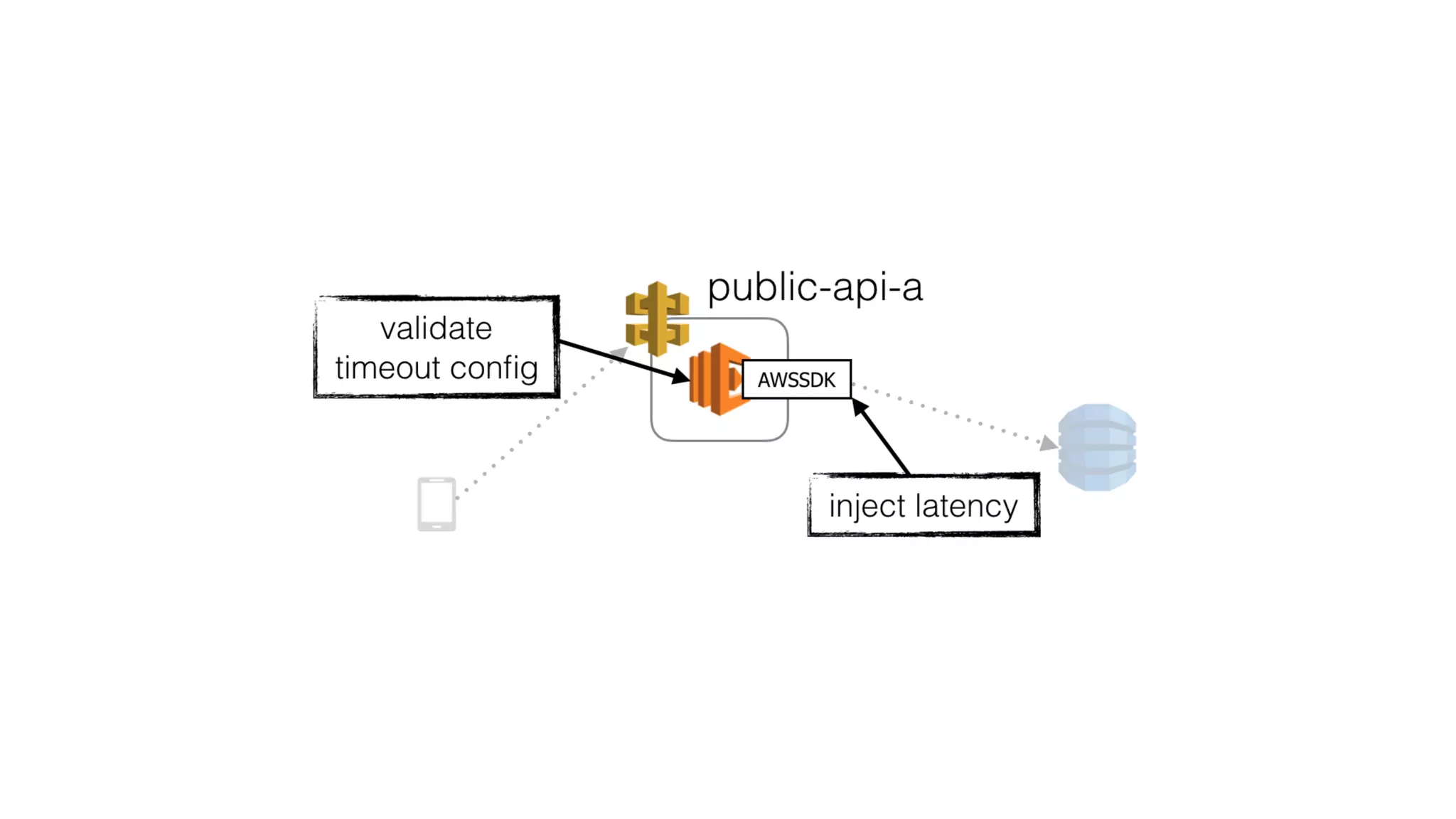
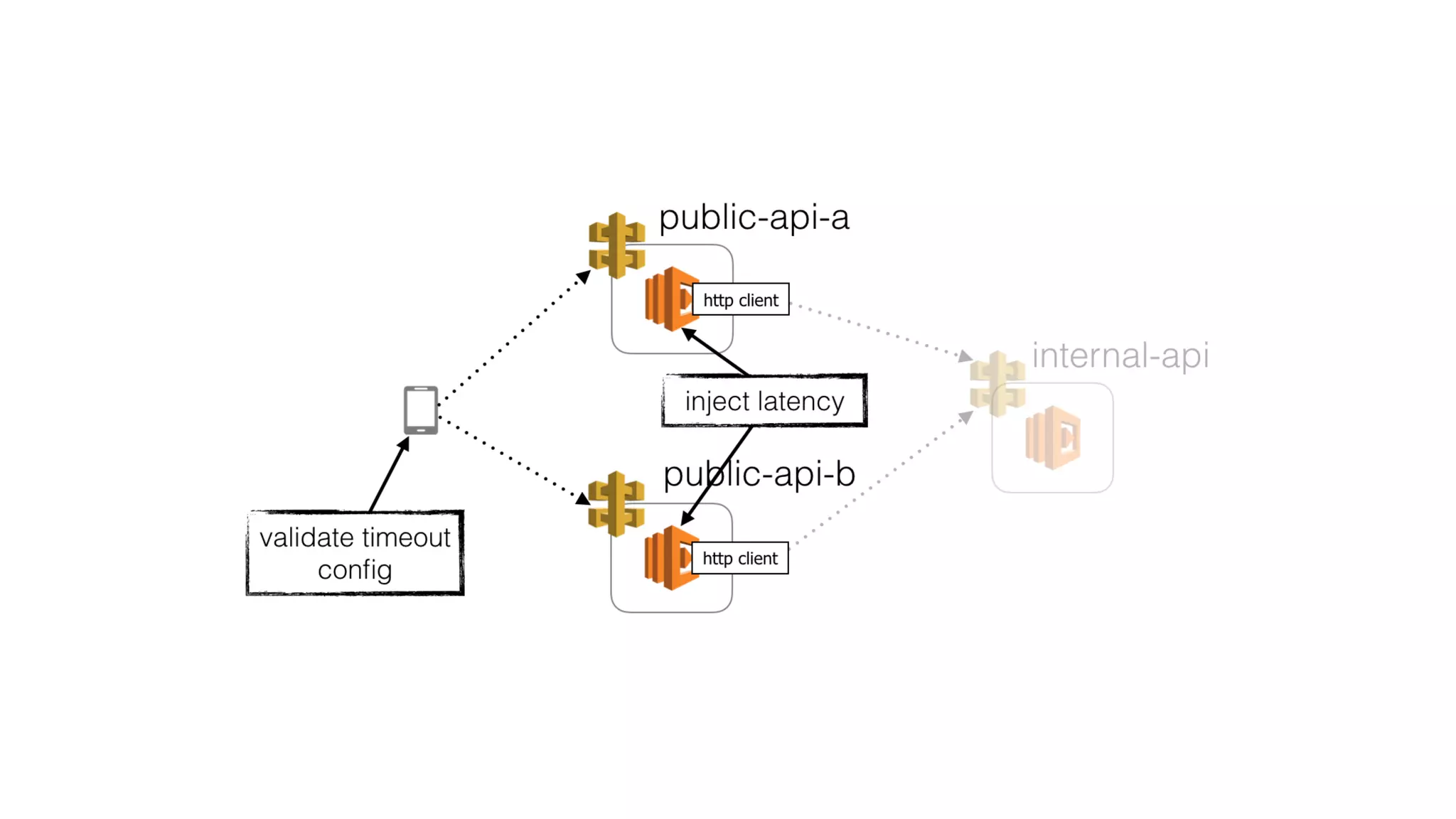
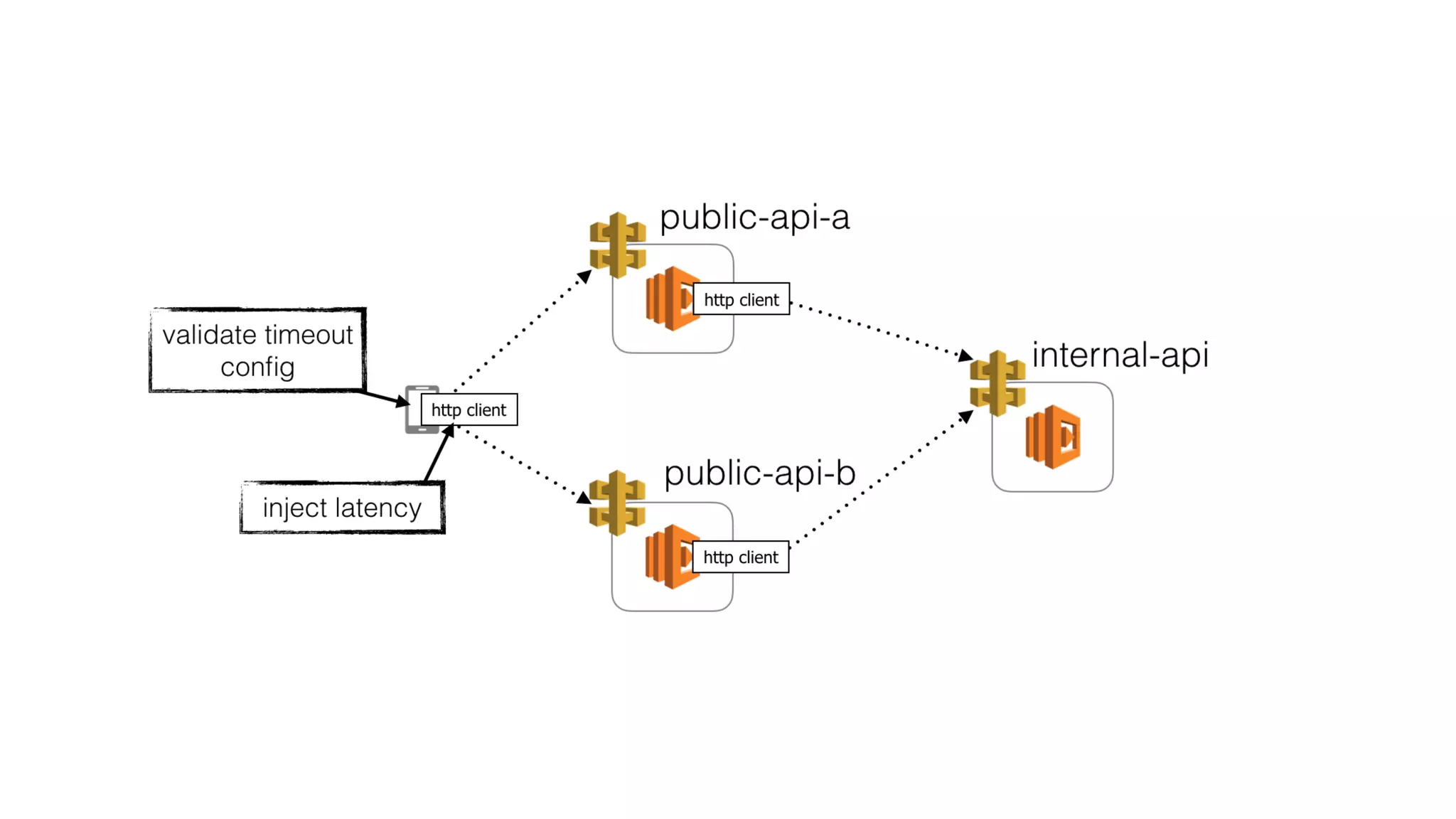



This document summarizes a talk on applying principles of chaos engineering to serverless applications. It discusses defining steady state, injecting realistic failures like latency and errors, and using controlled experiments to build confidence in a system's ability to withstand failures in production. Specifically for serverless, it addresses challenges like smaller units of deployment and many managed services, and demonstrates how to inject latency and errors at different points to test failure handling. The goal is learning from failures, not intentionally breaking systems, so containment is important.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













