Download as PDF, PPTX










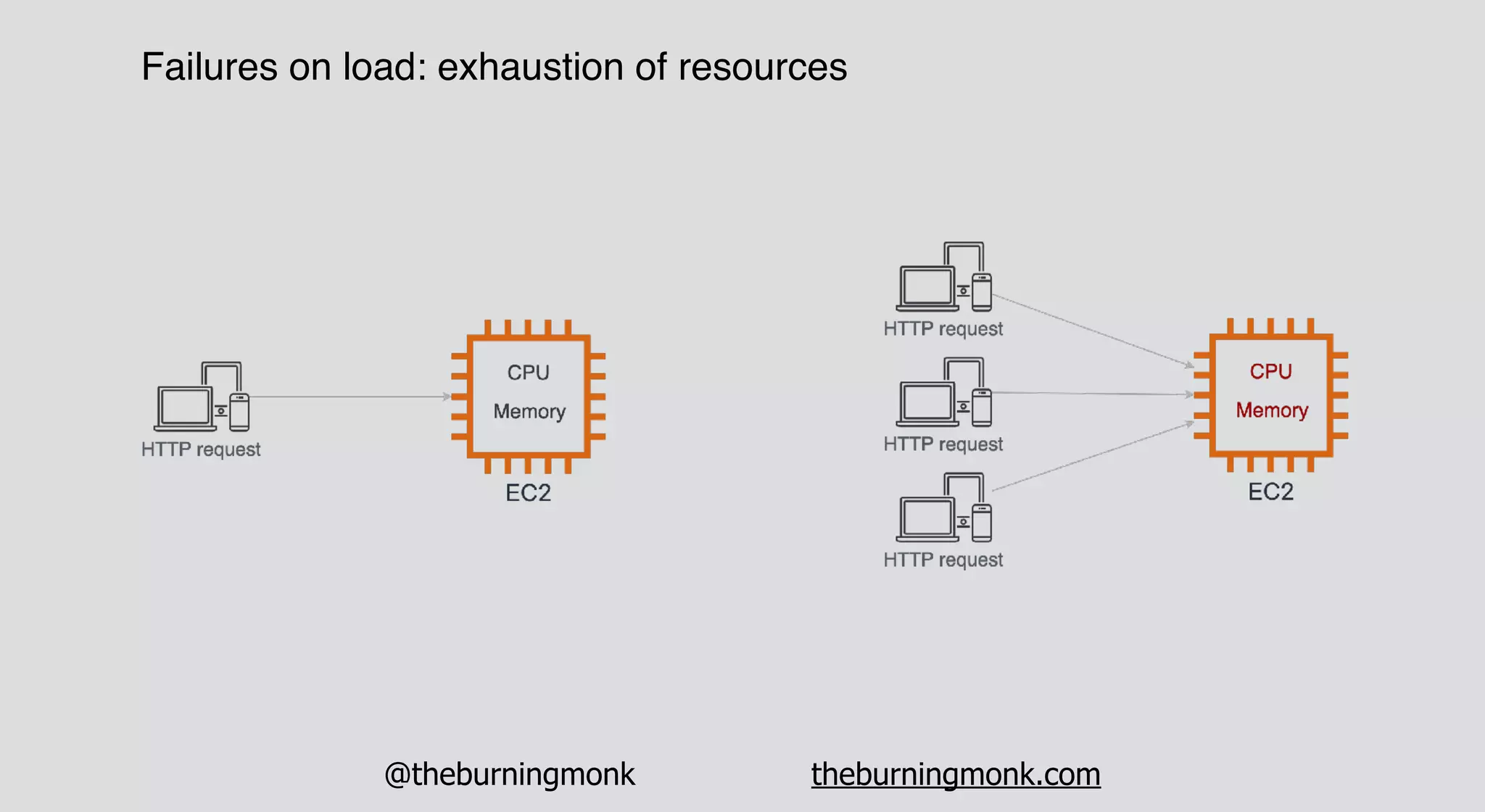
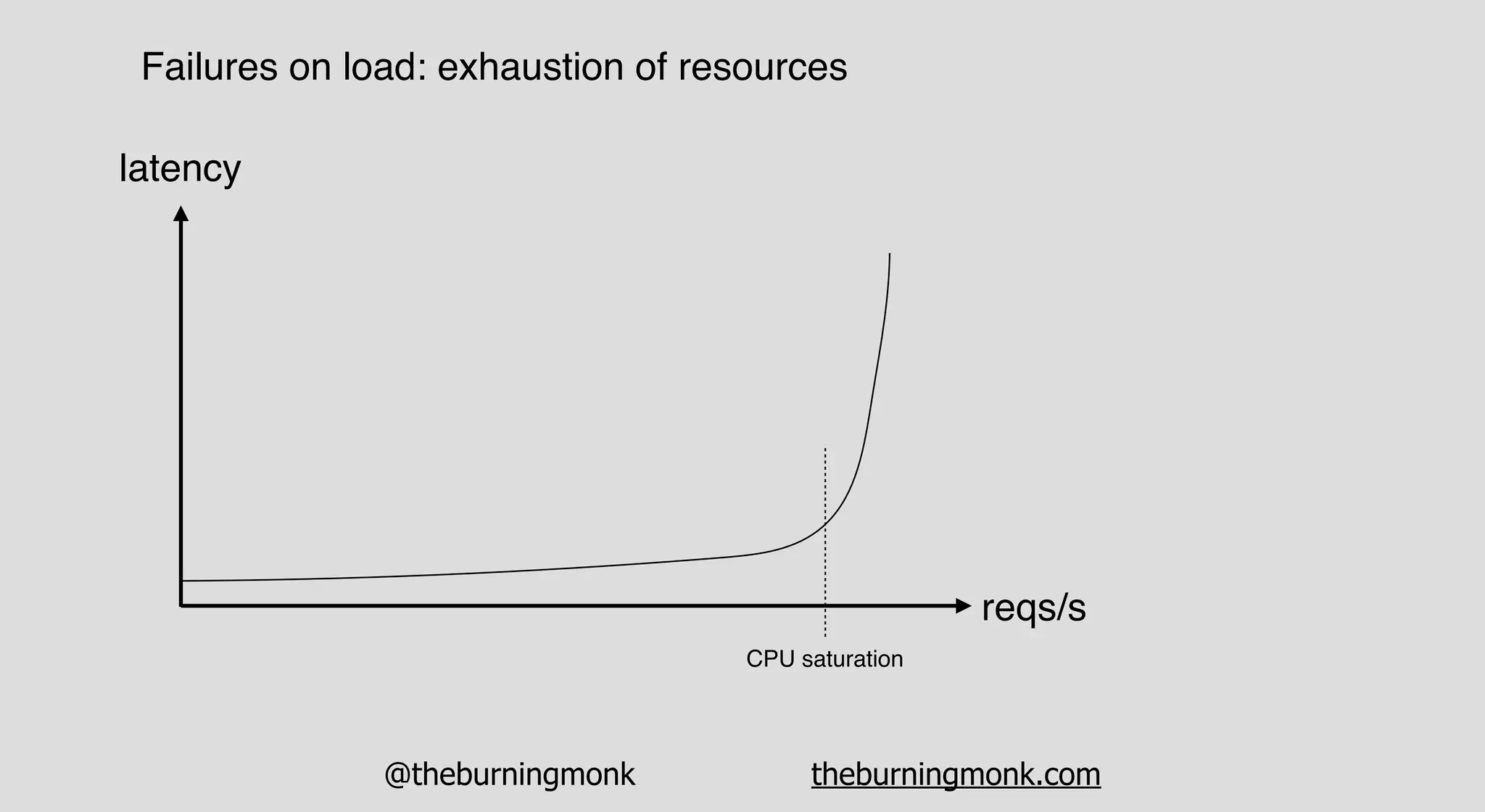
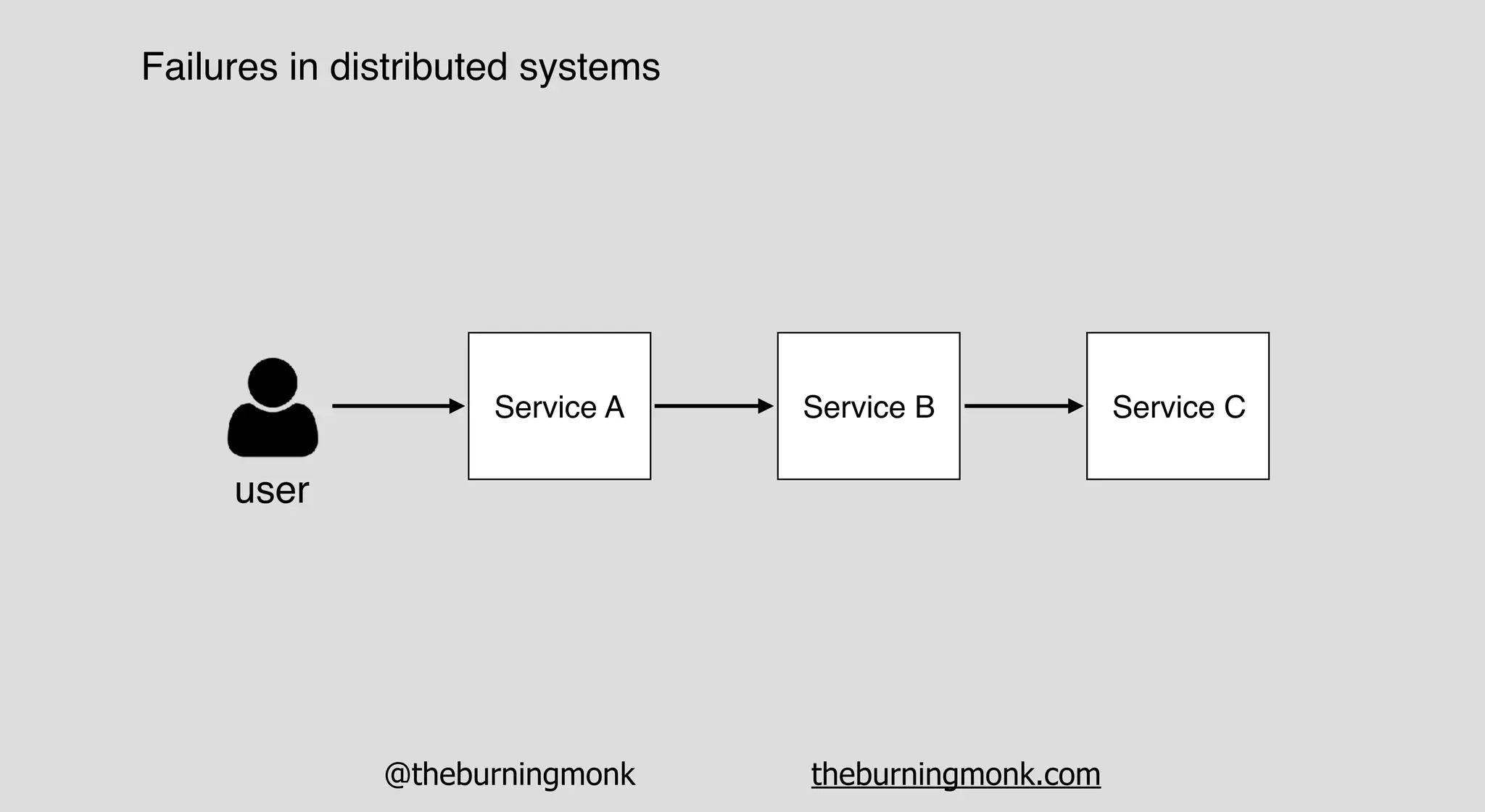
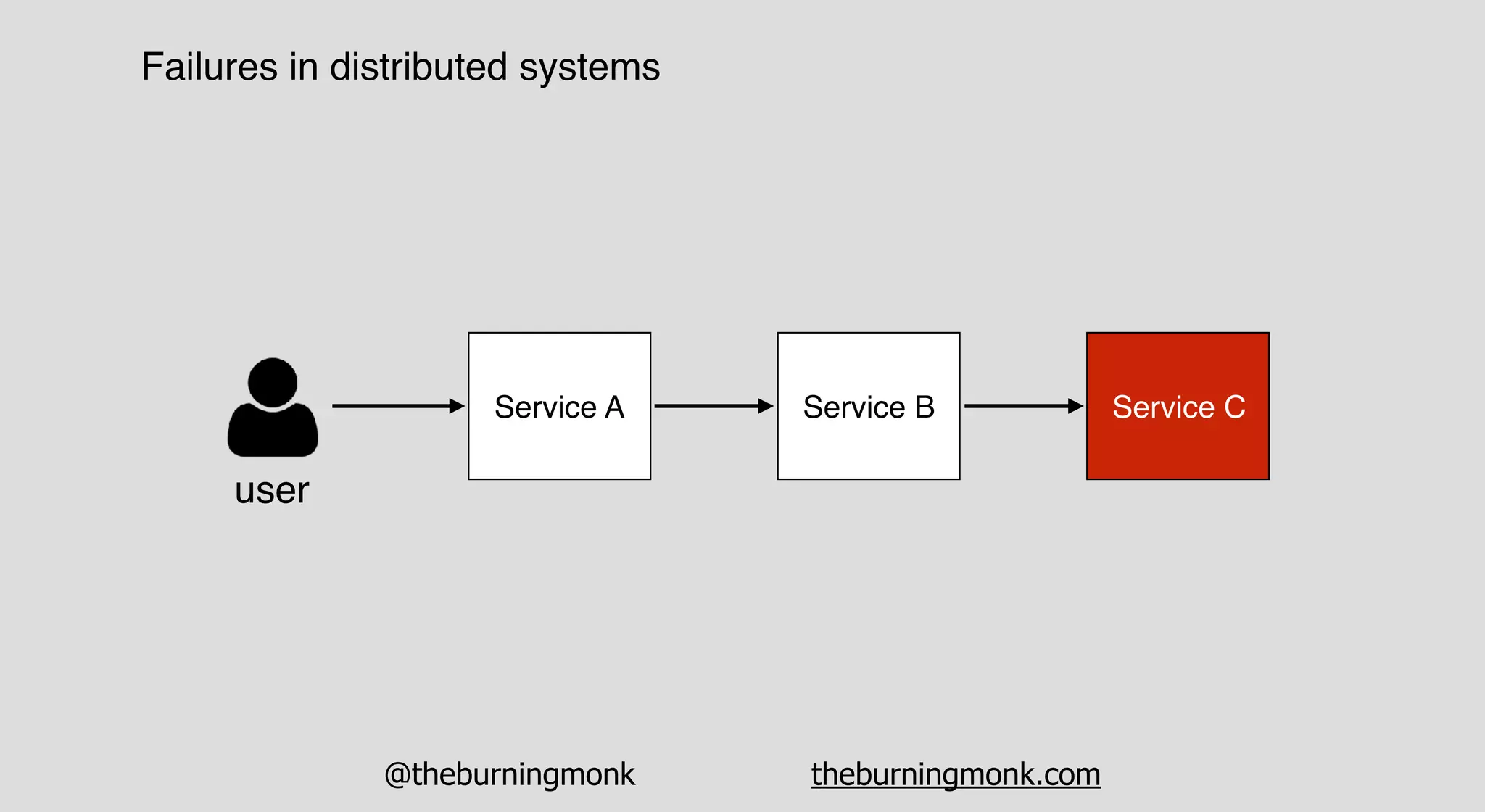
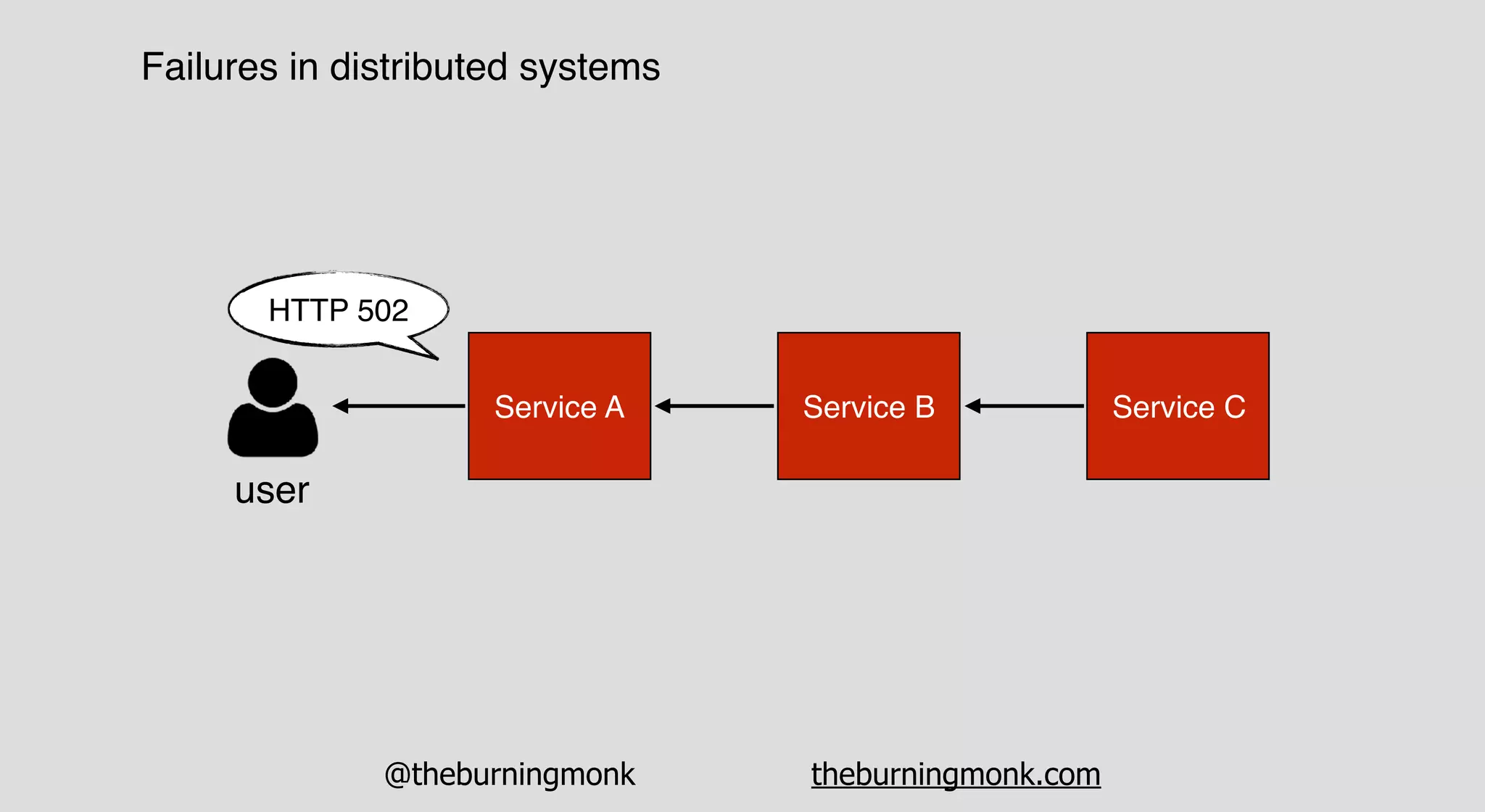
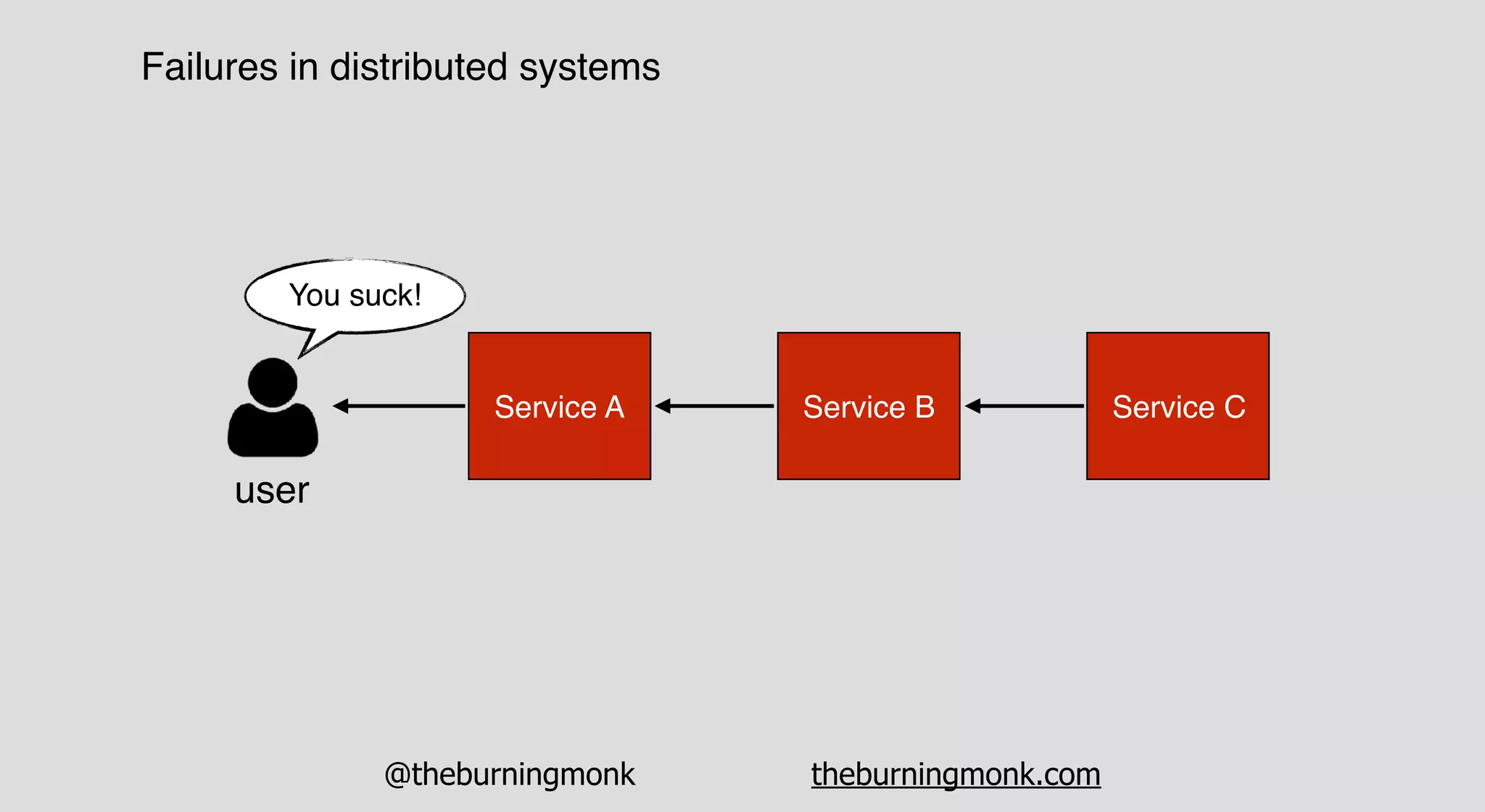
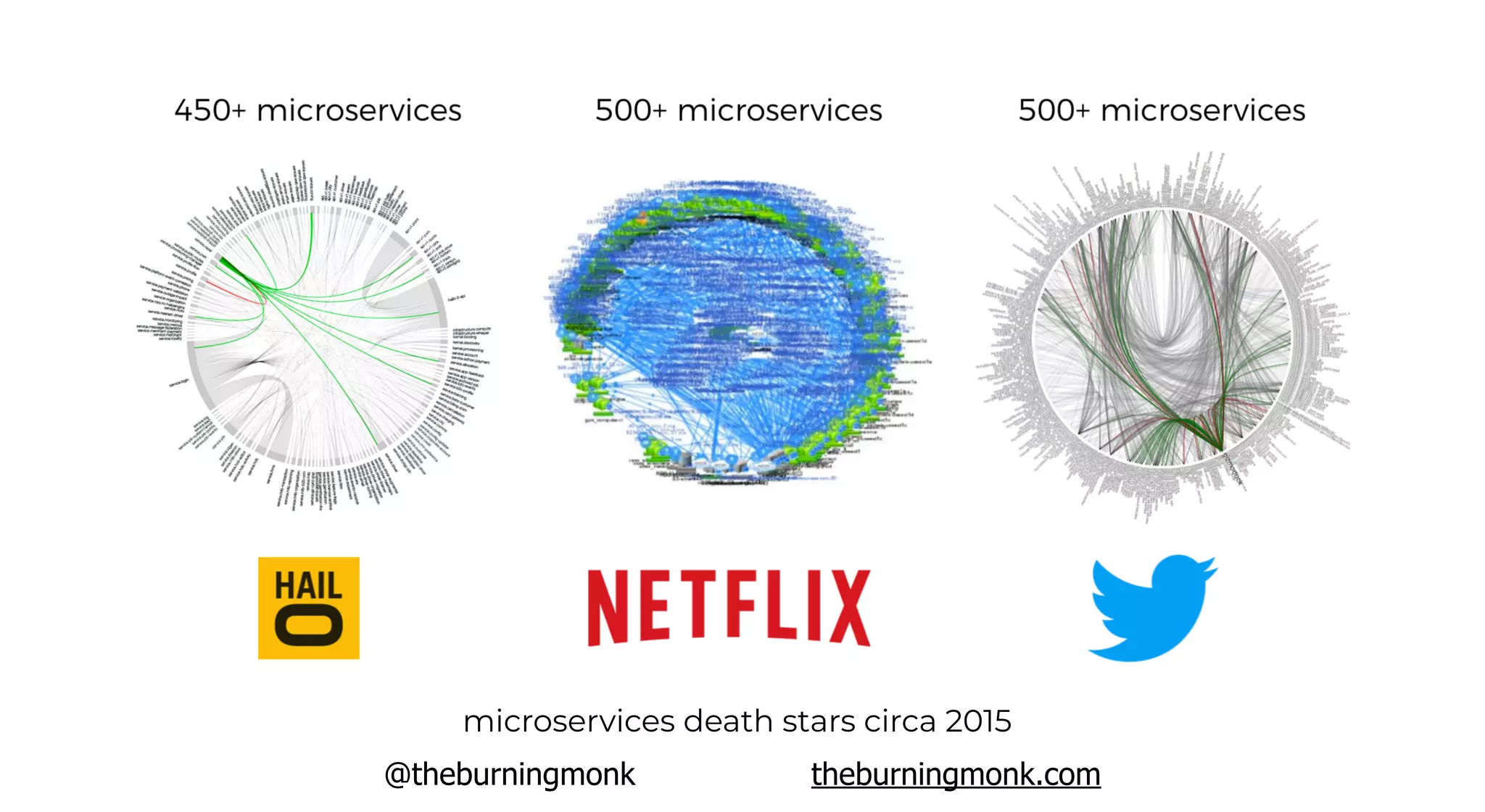

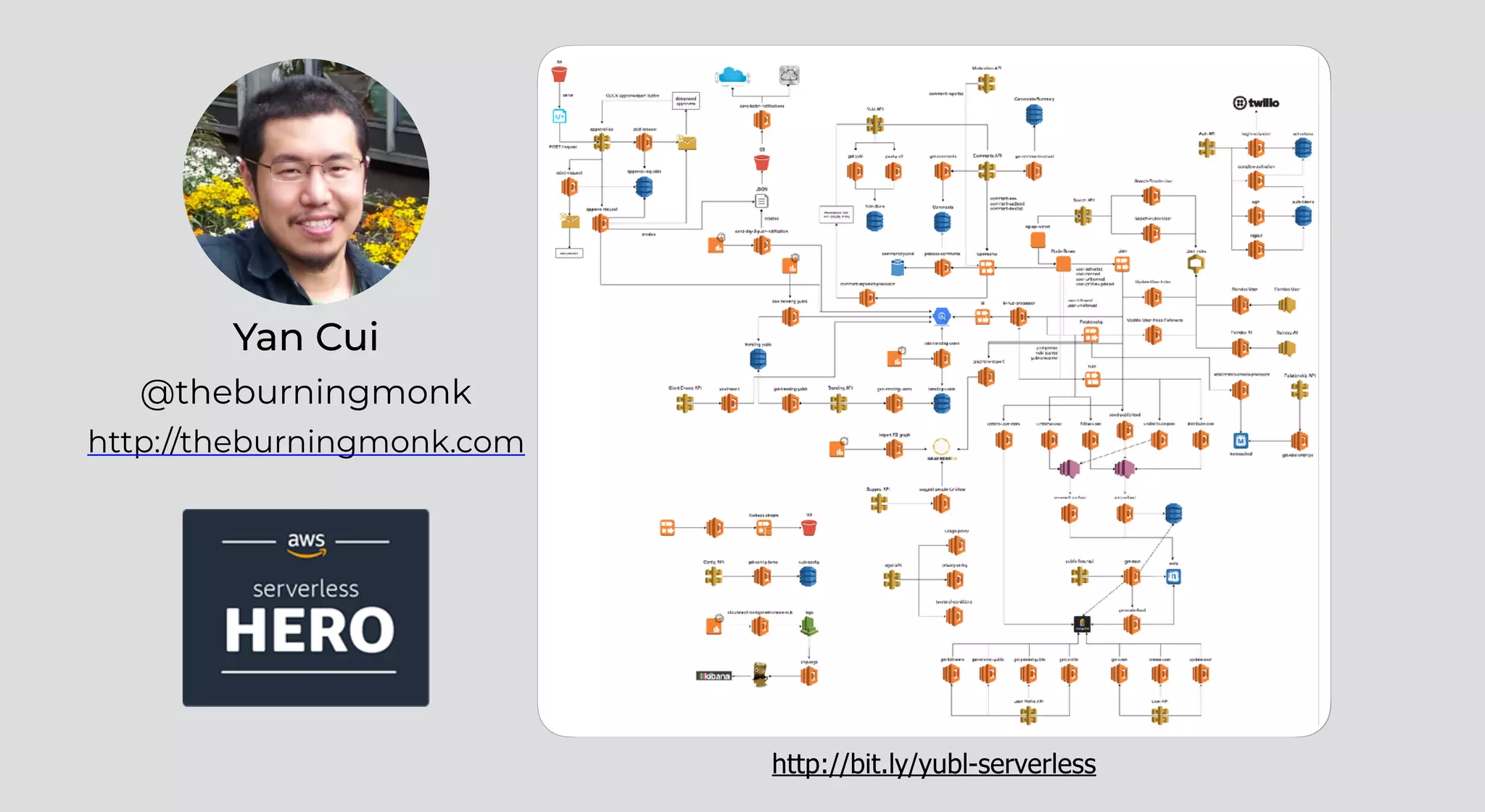

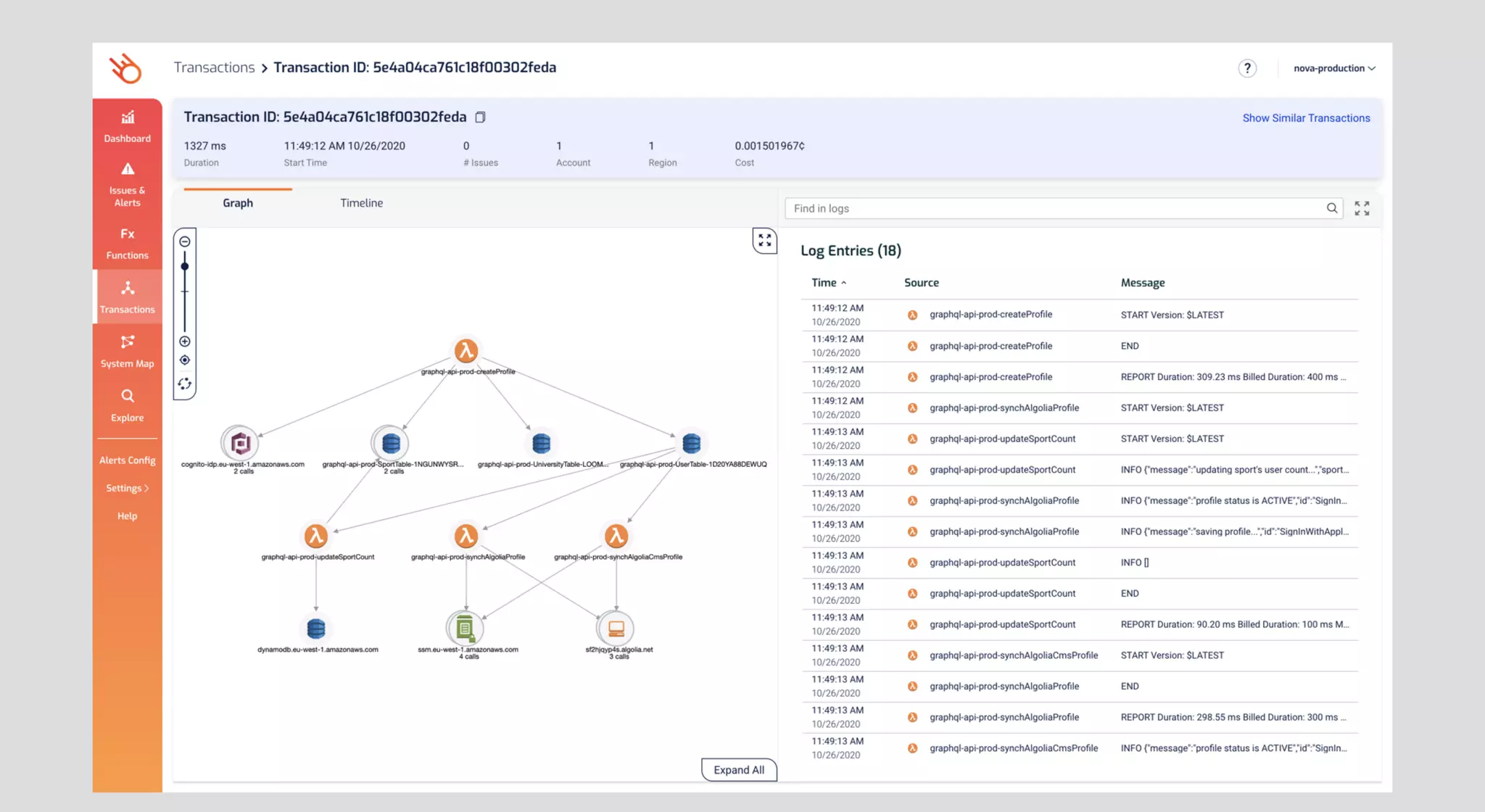

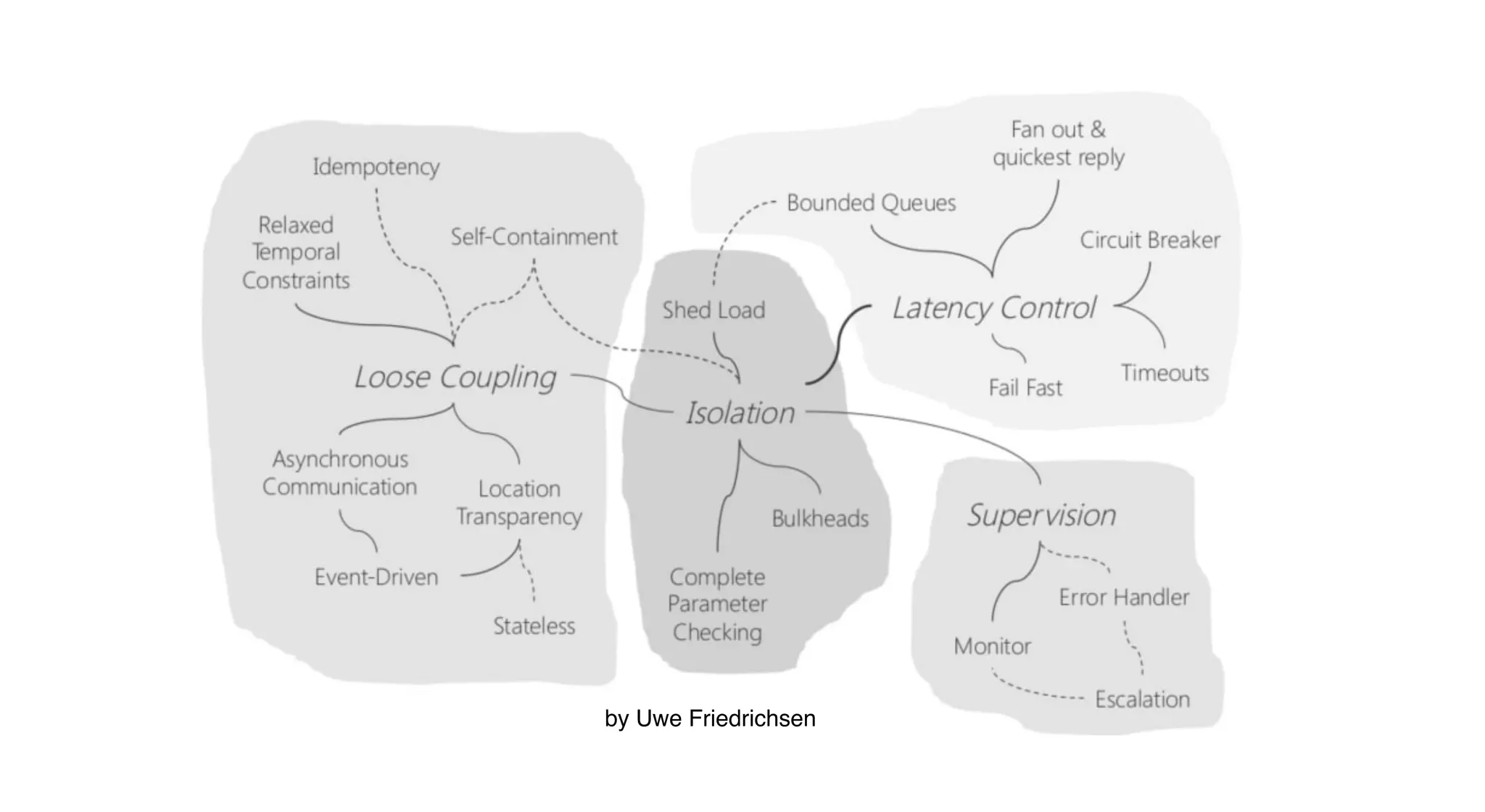
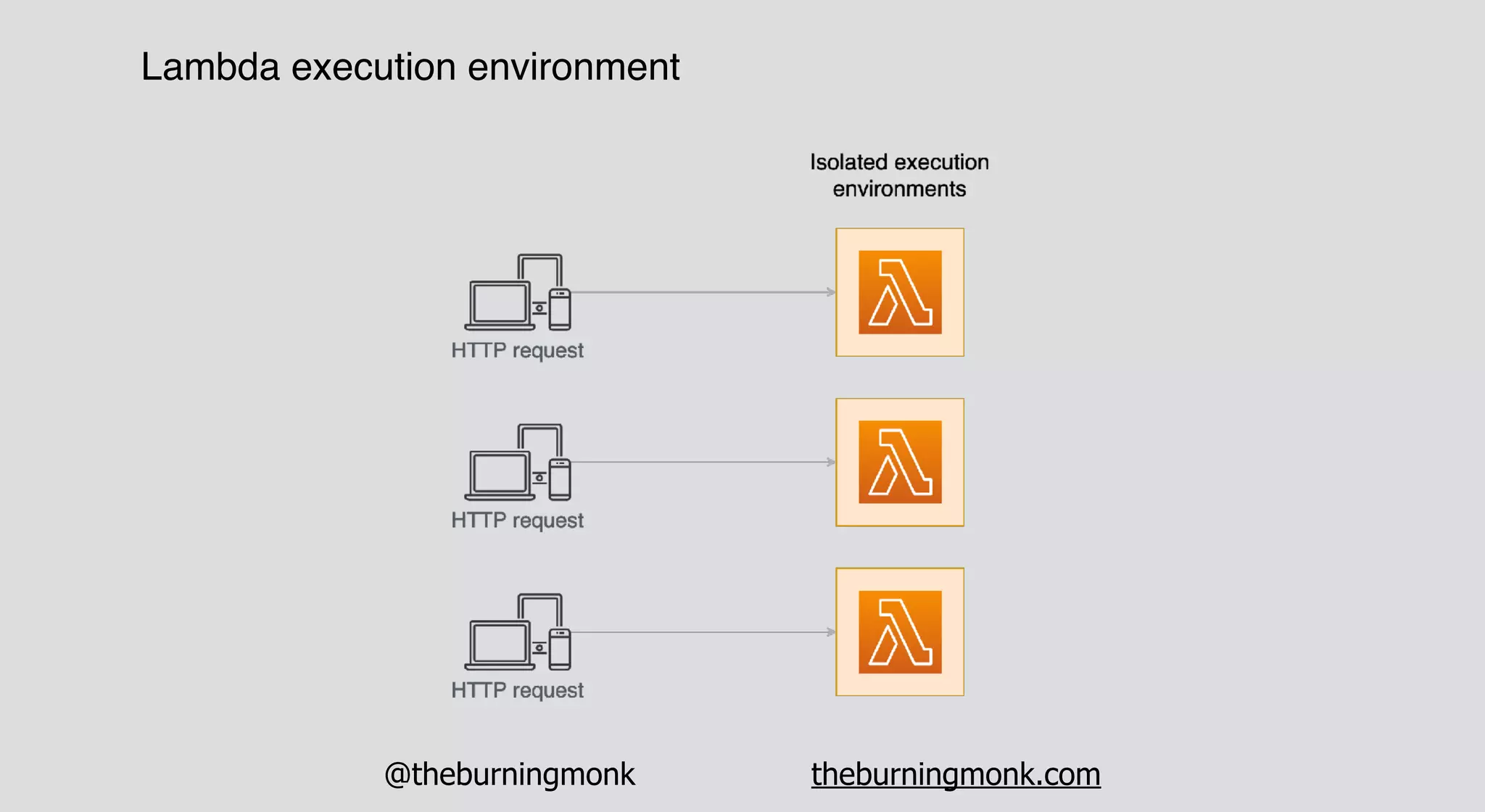


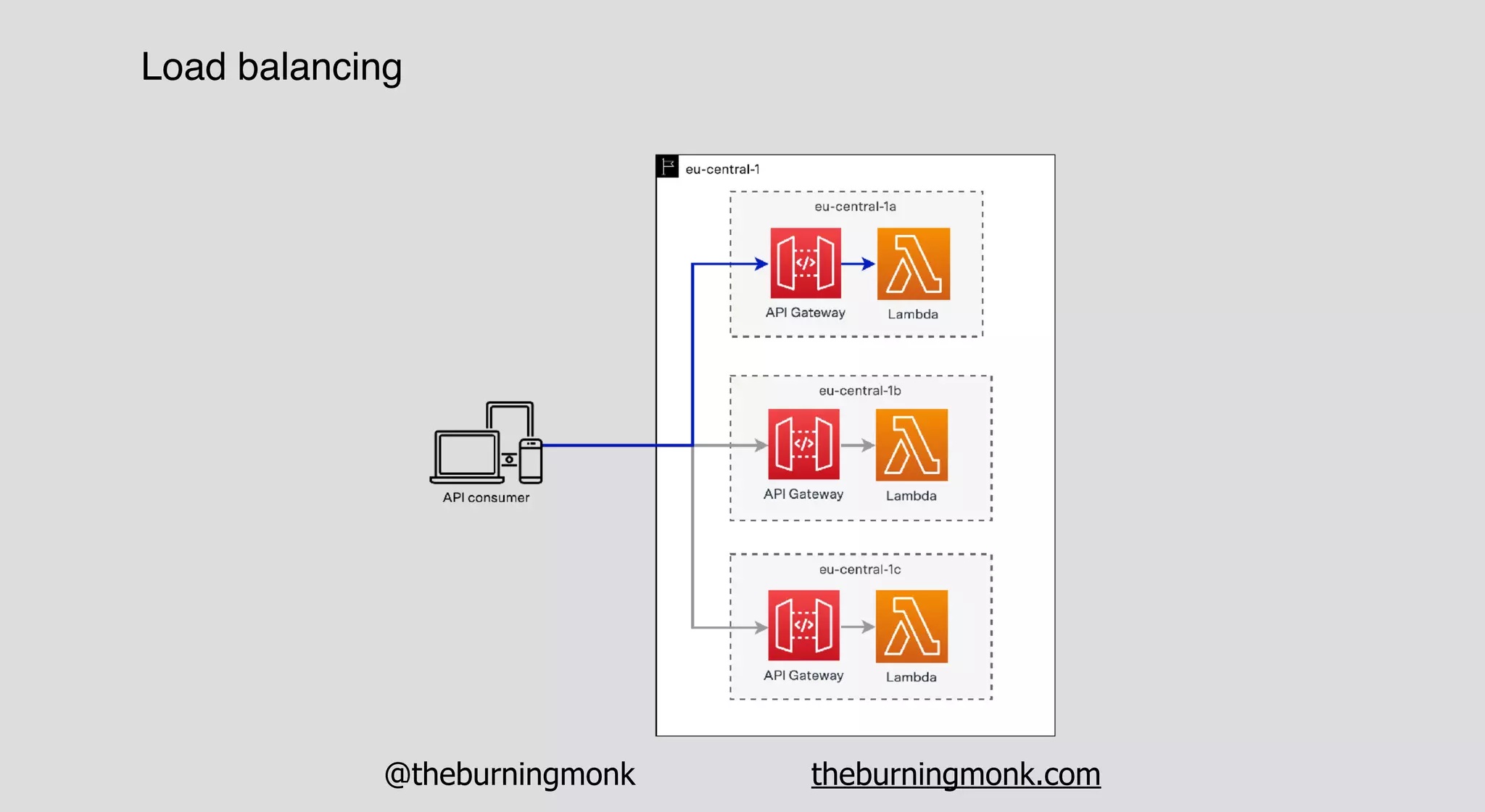
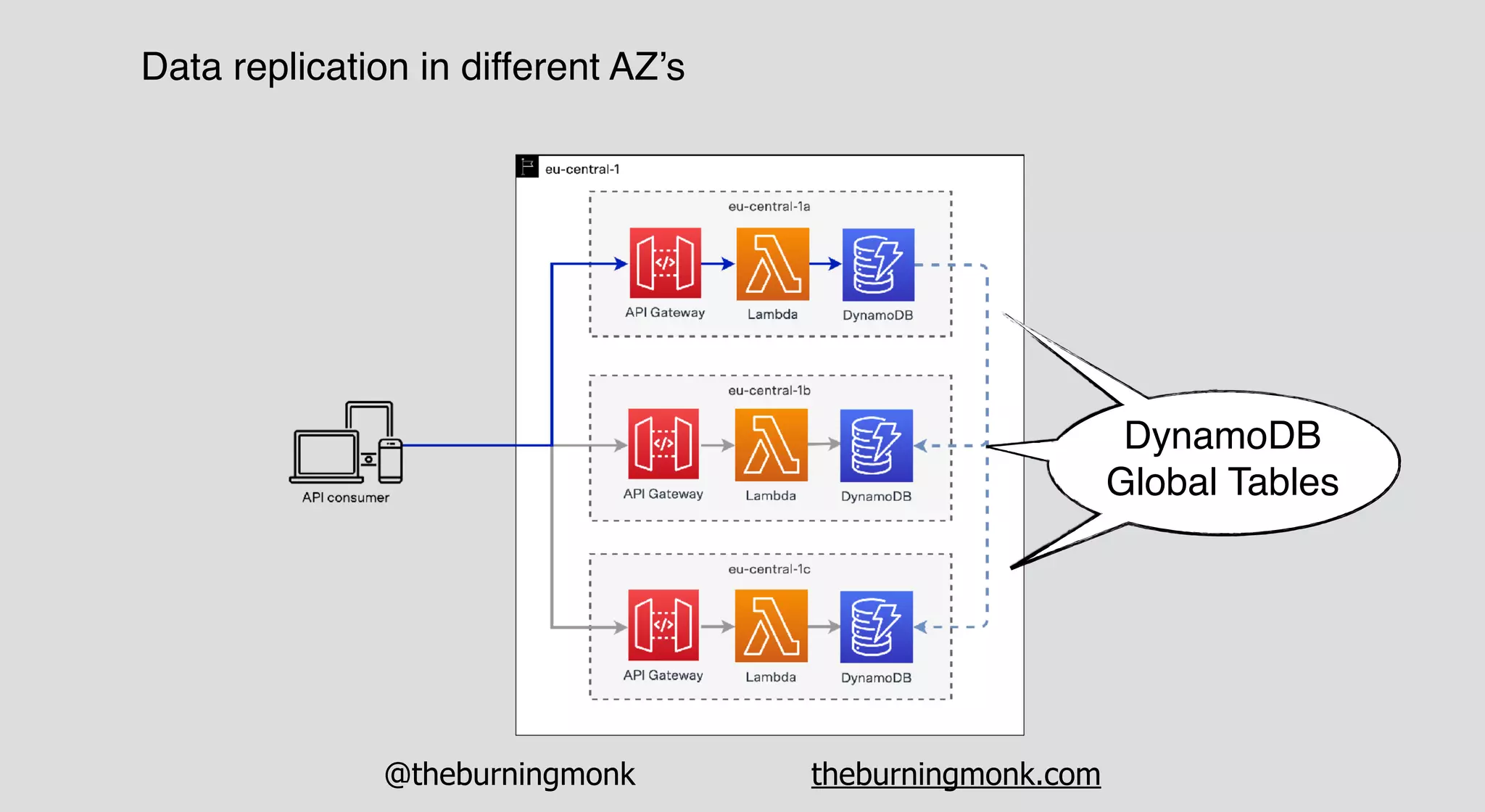
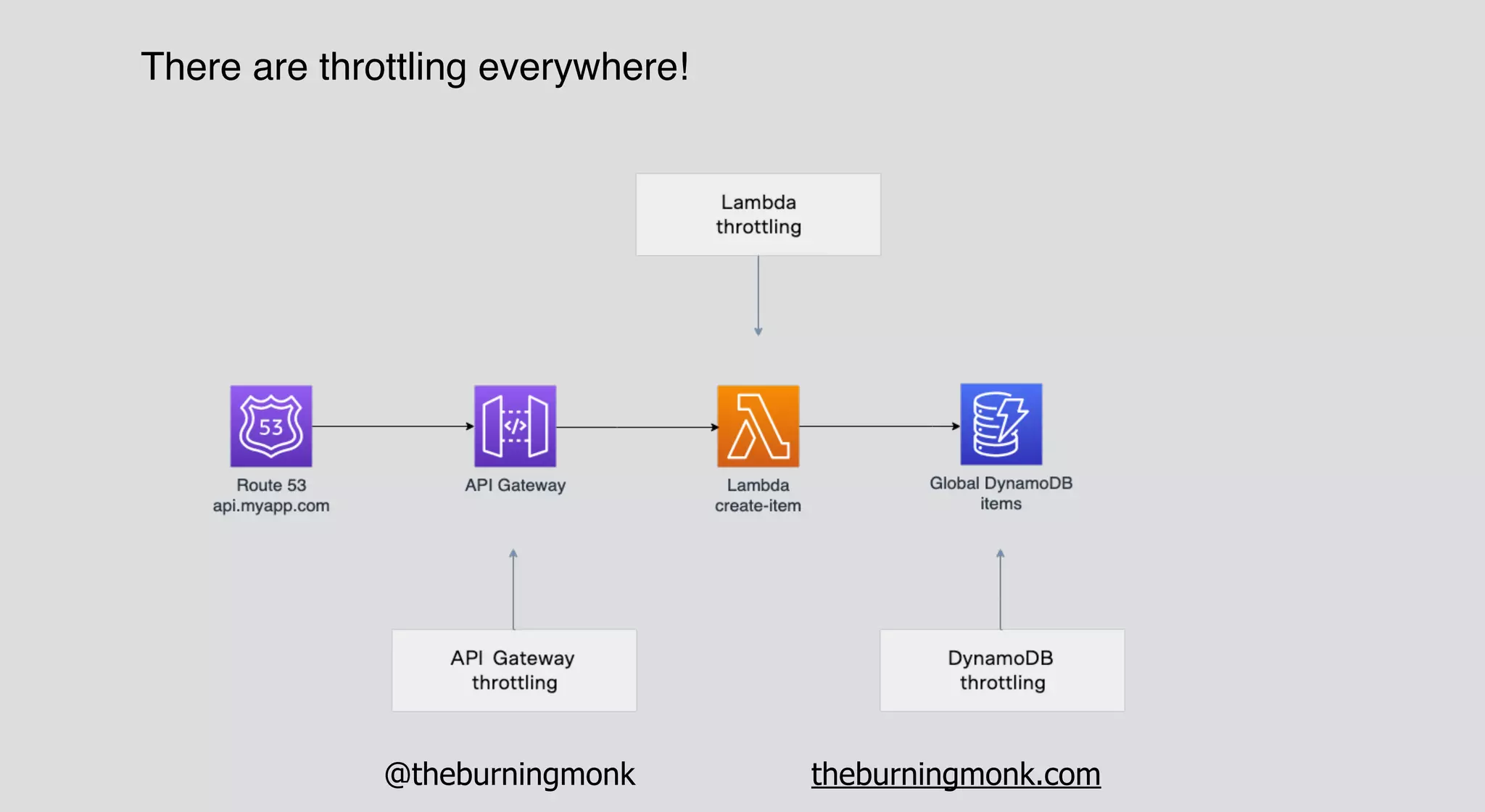



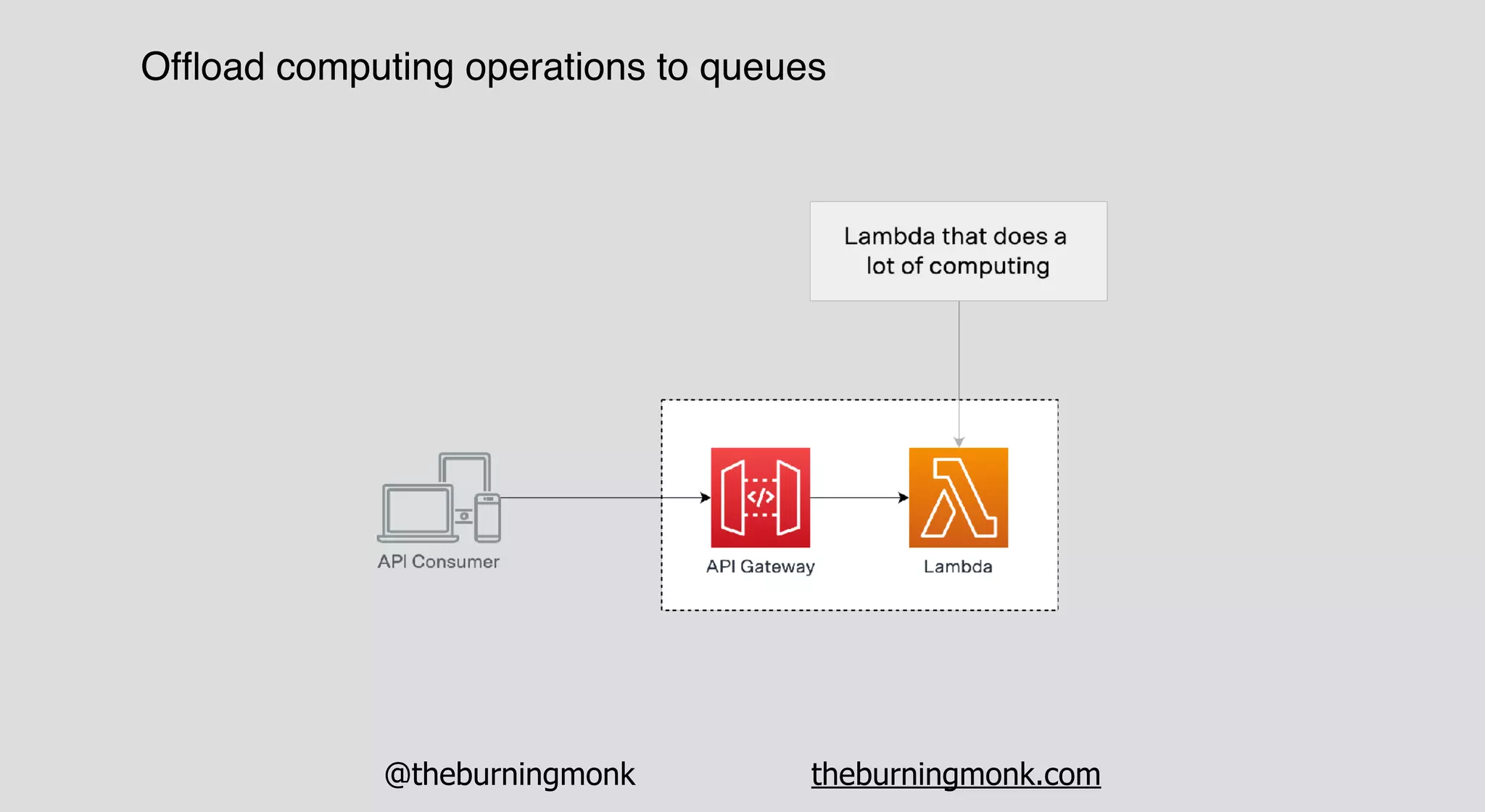
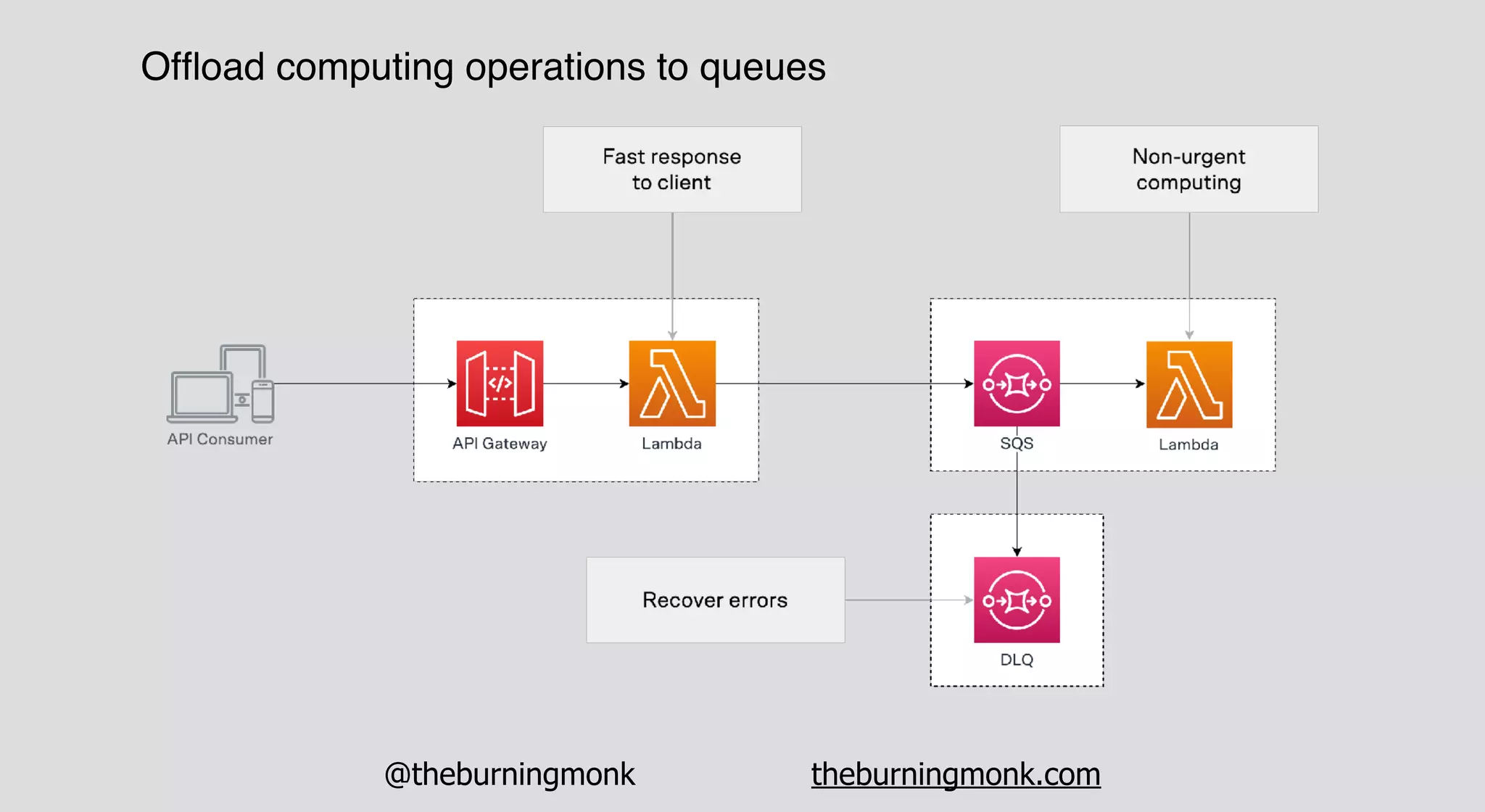
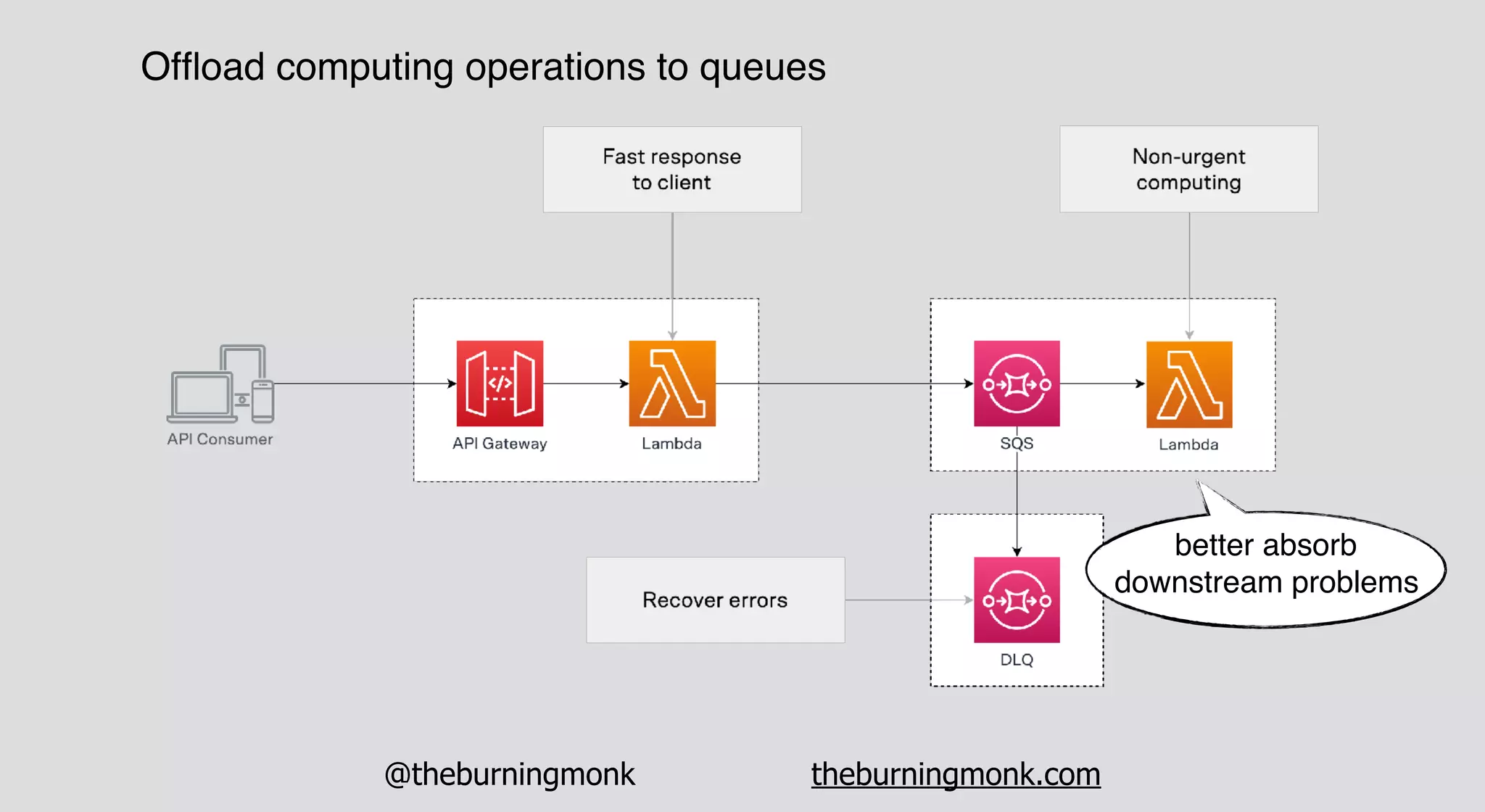
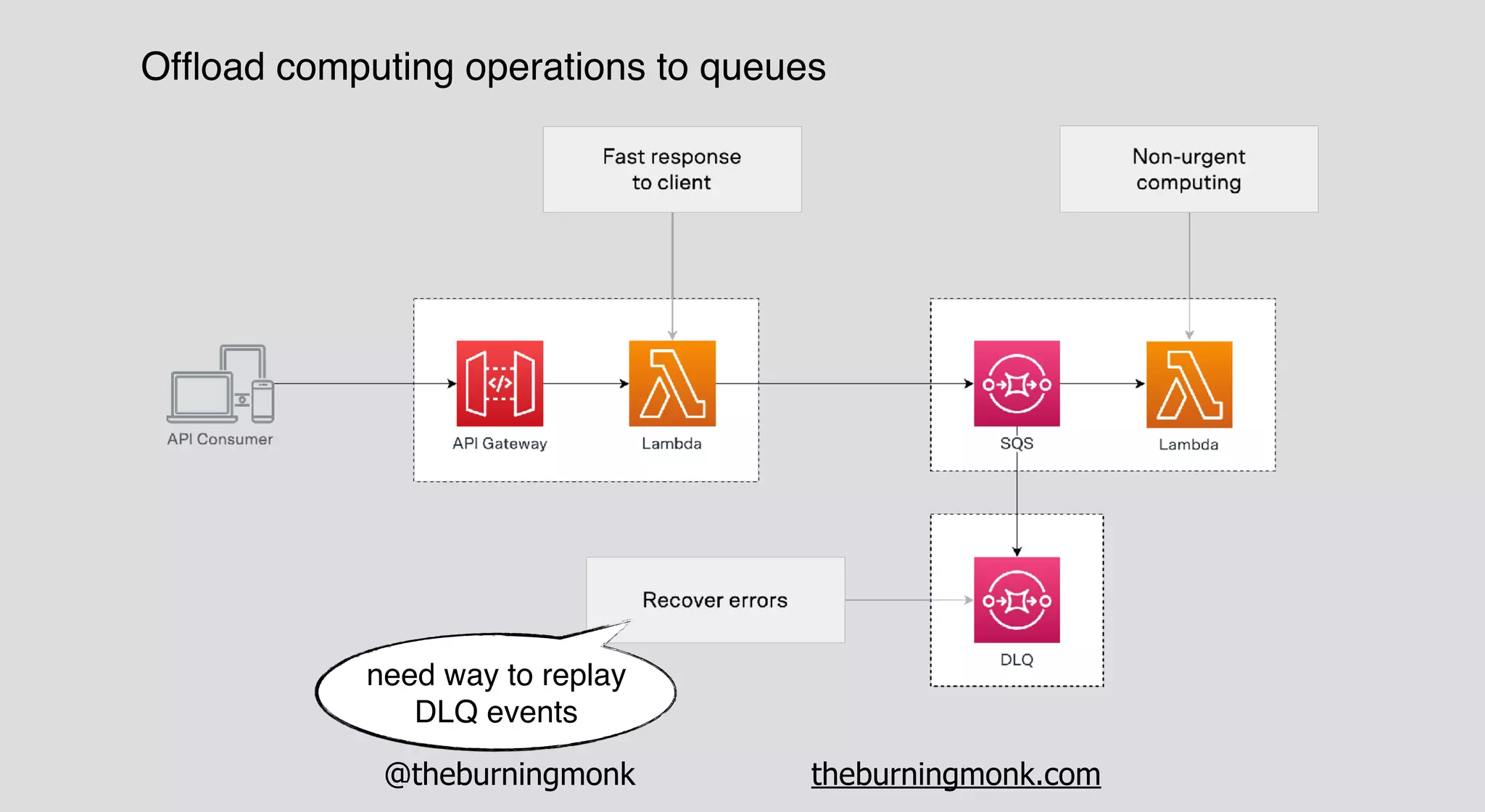
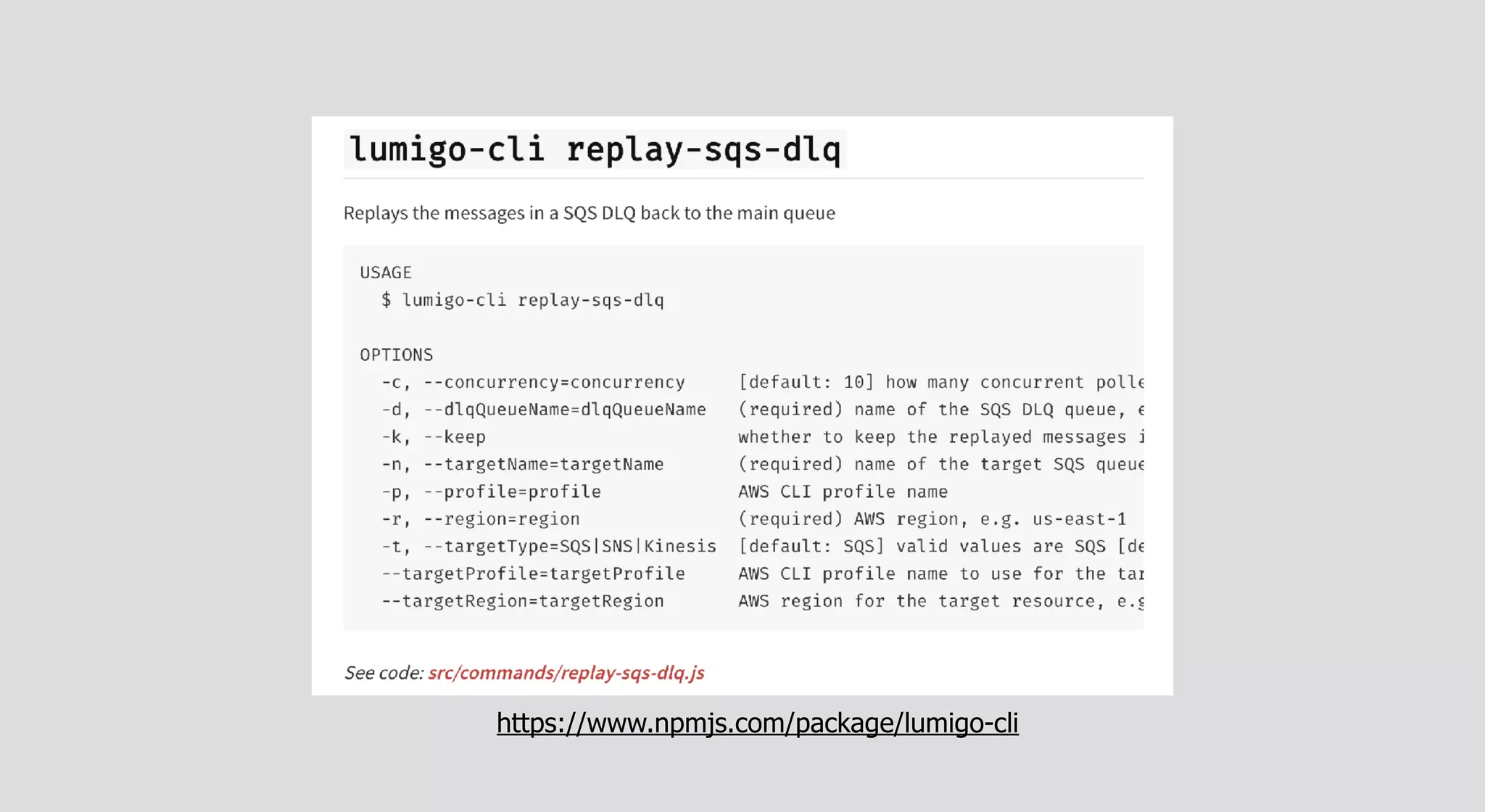
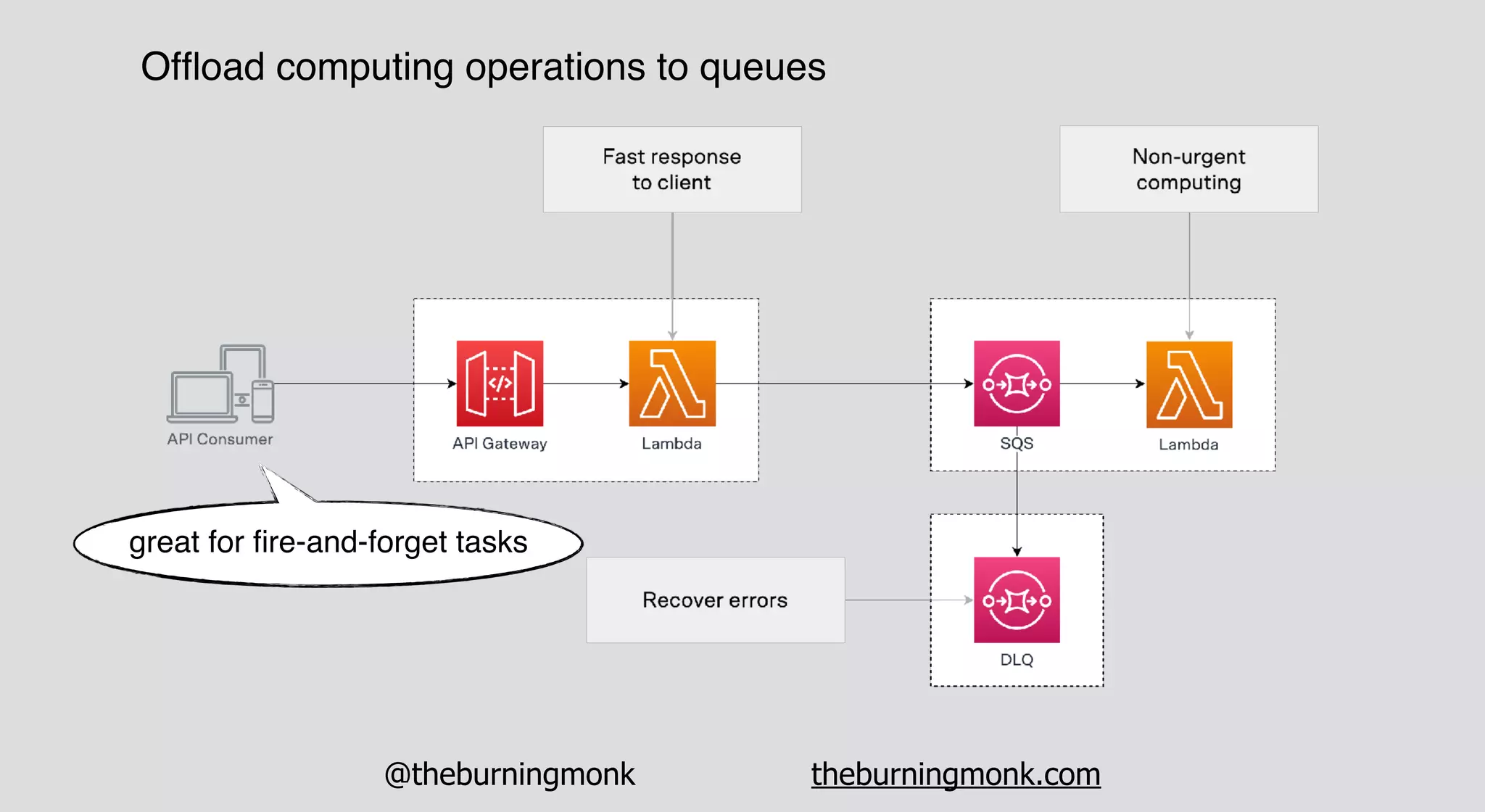

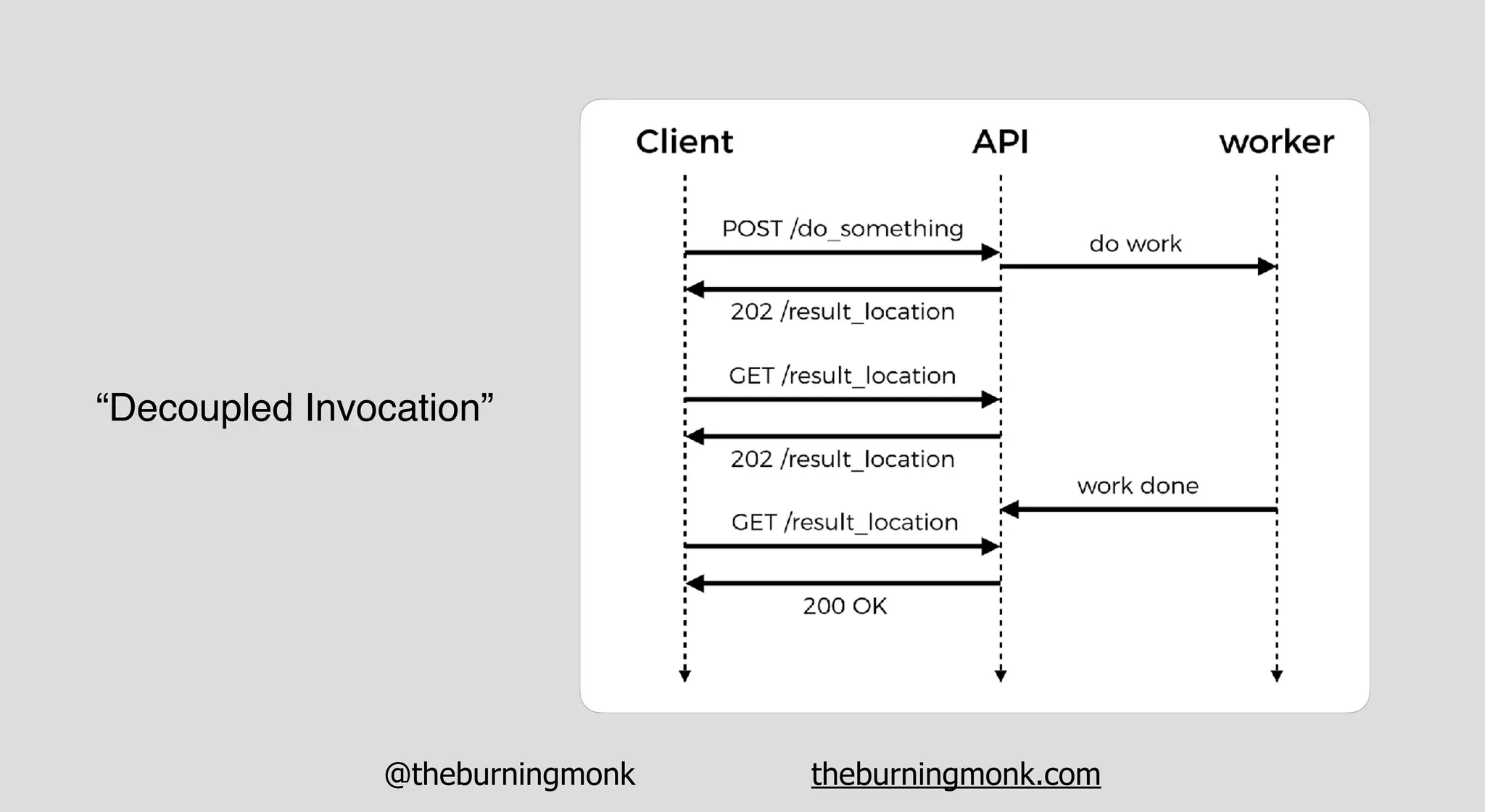


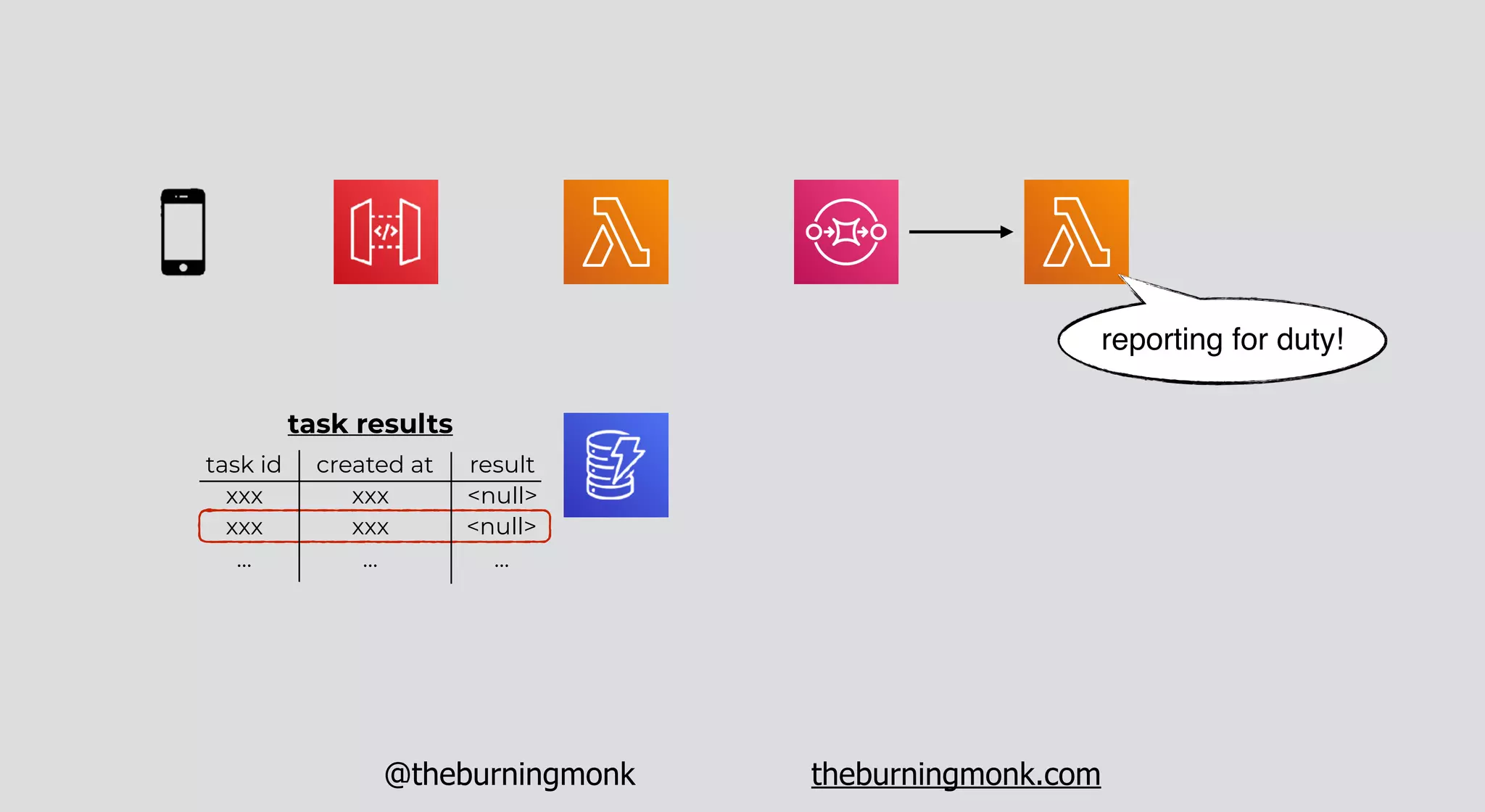

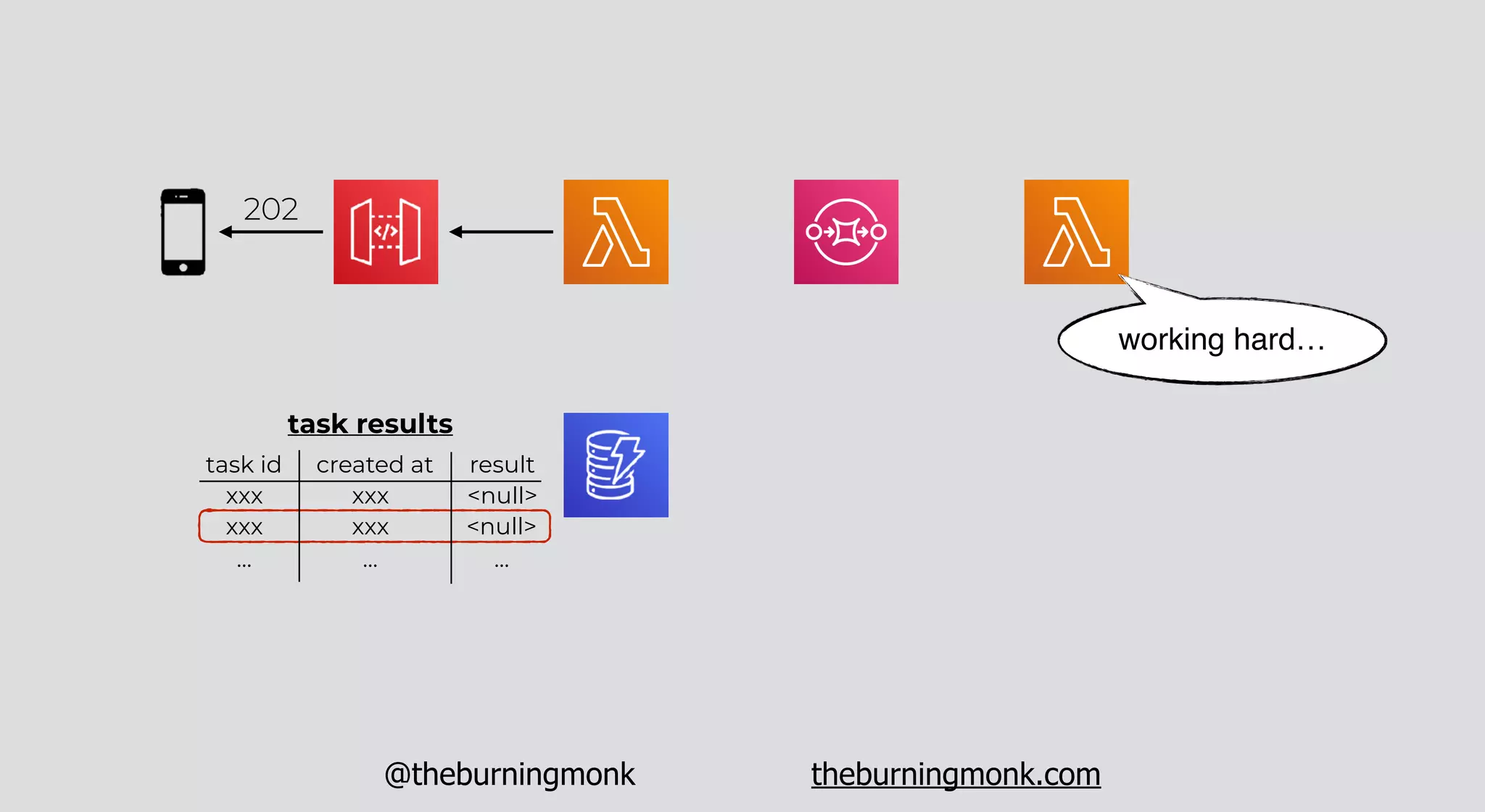
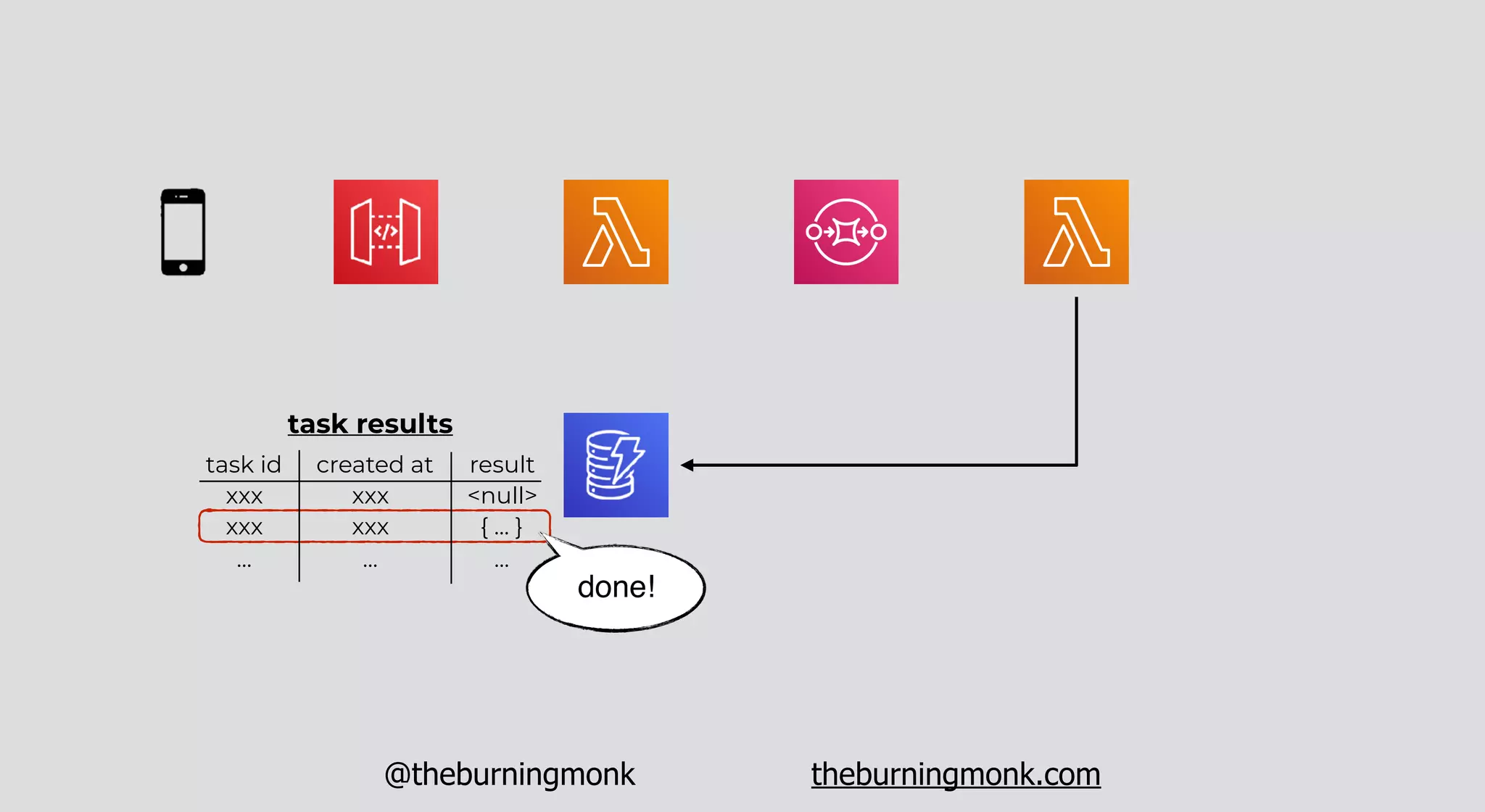
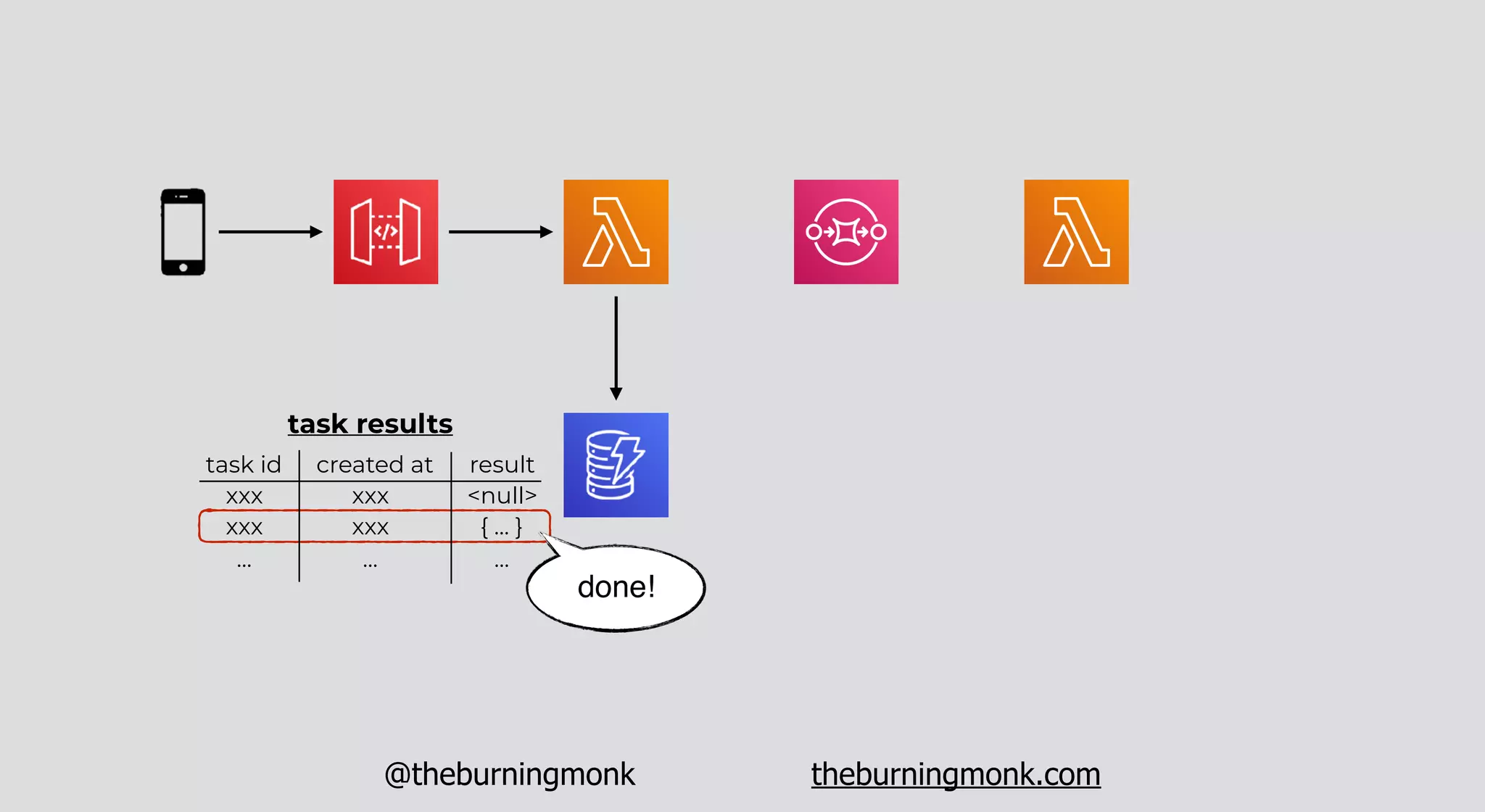


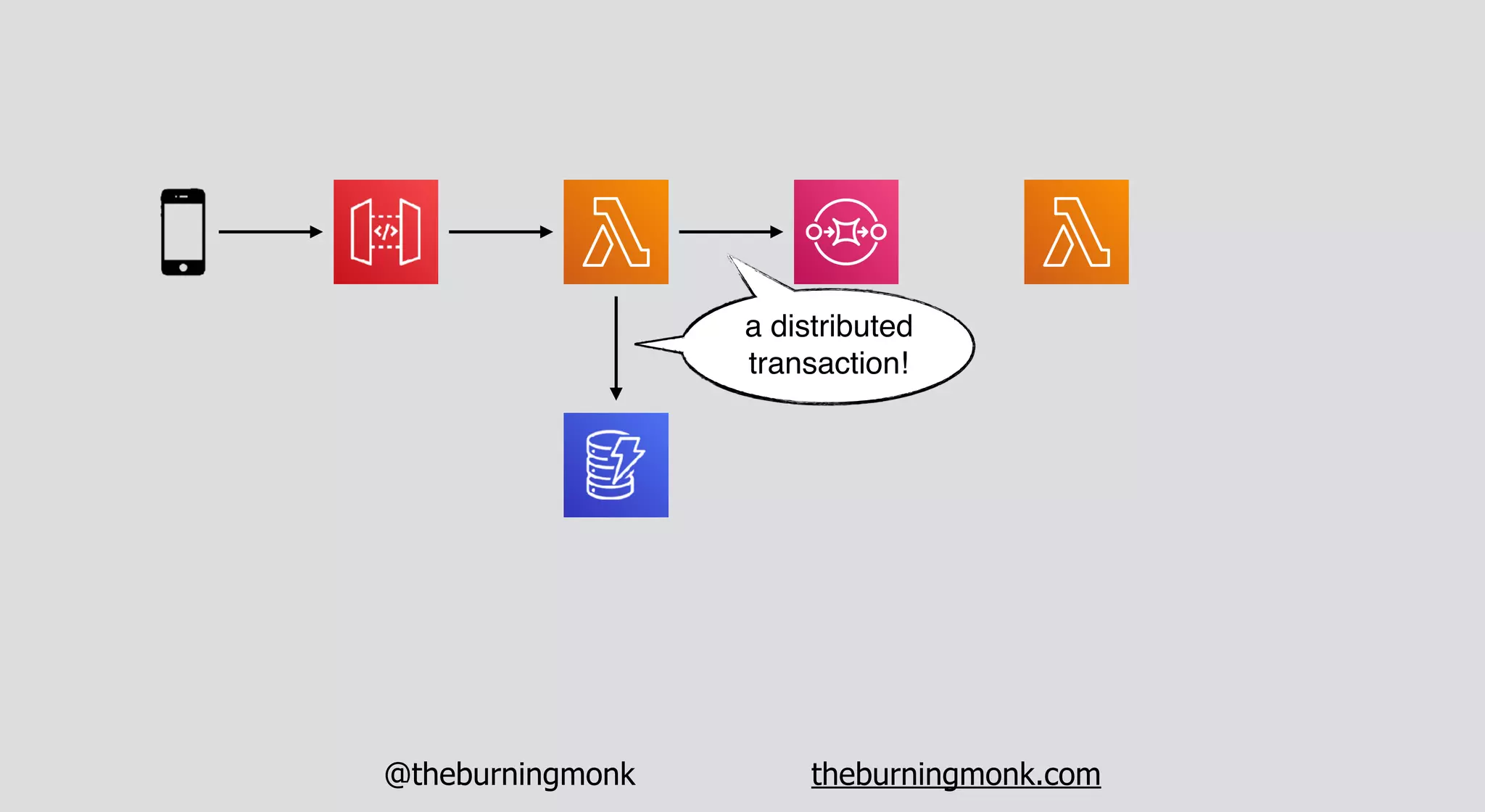
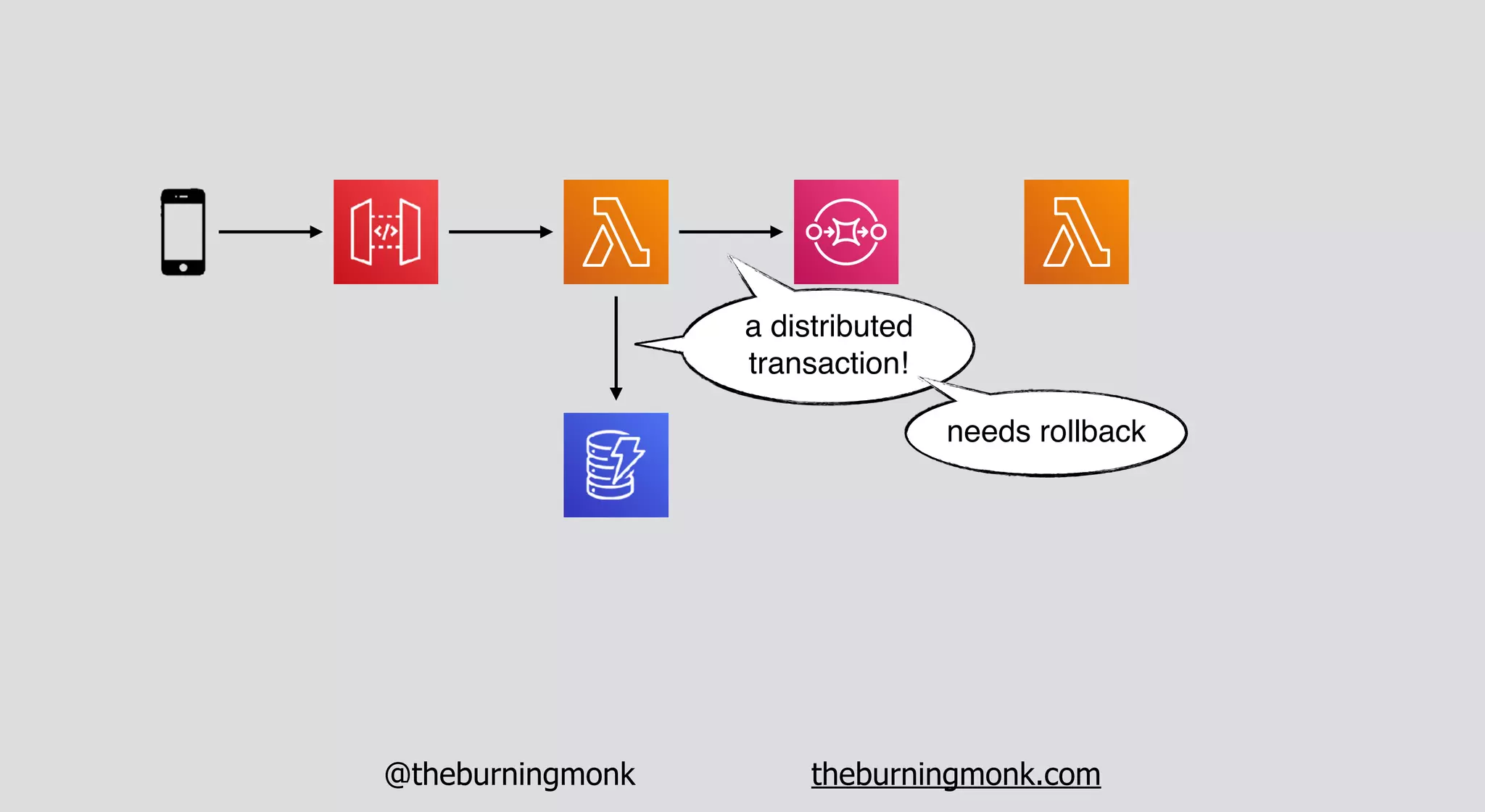





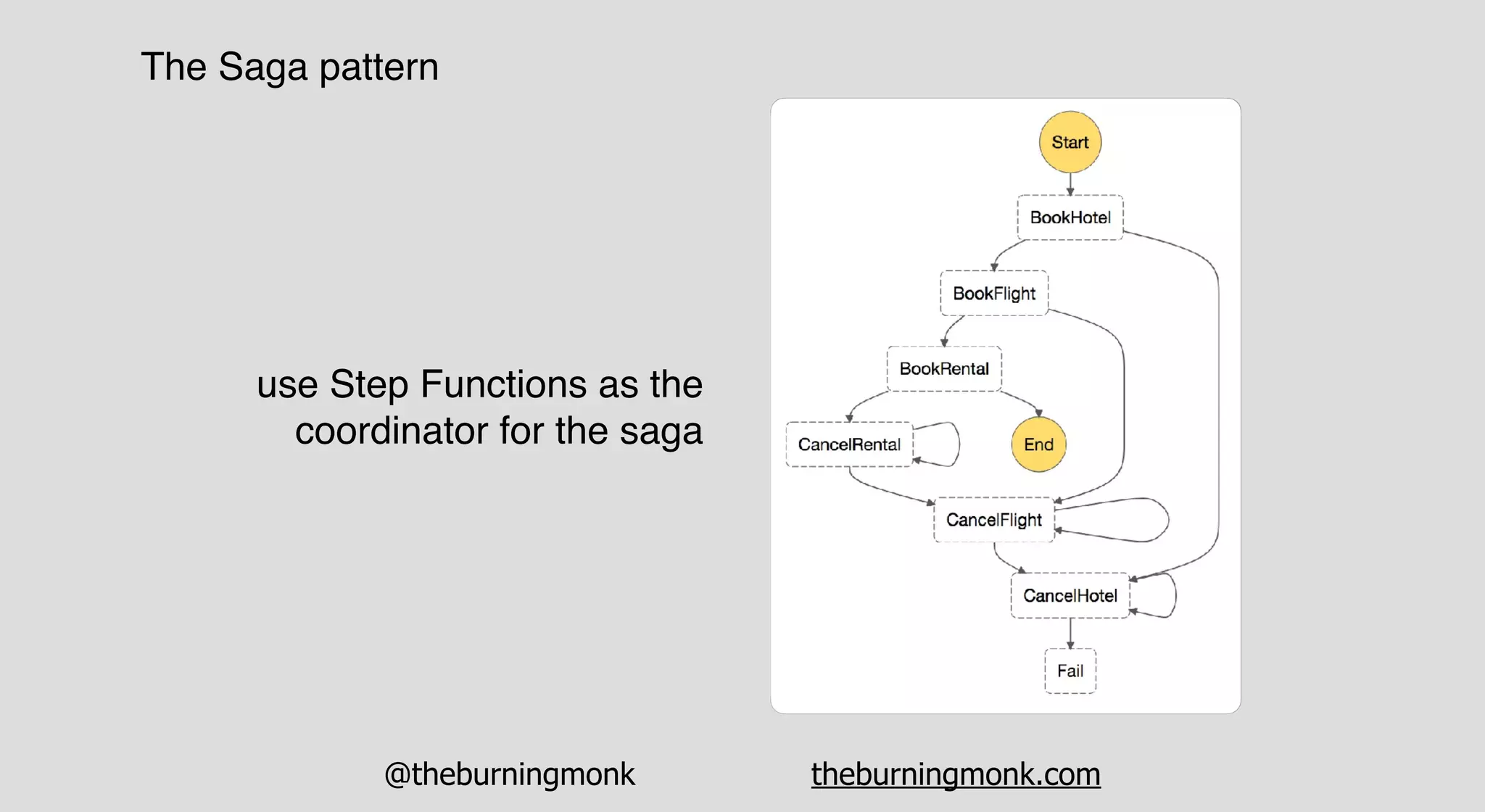

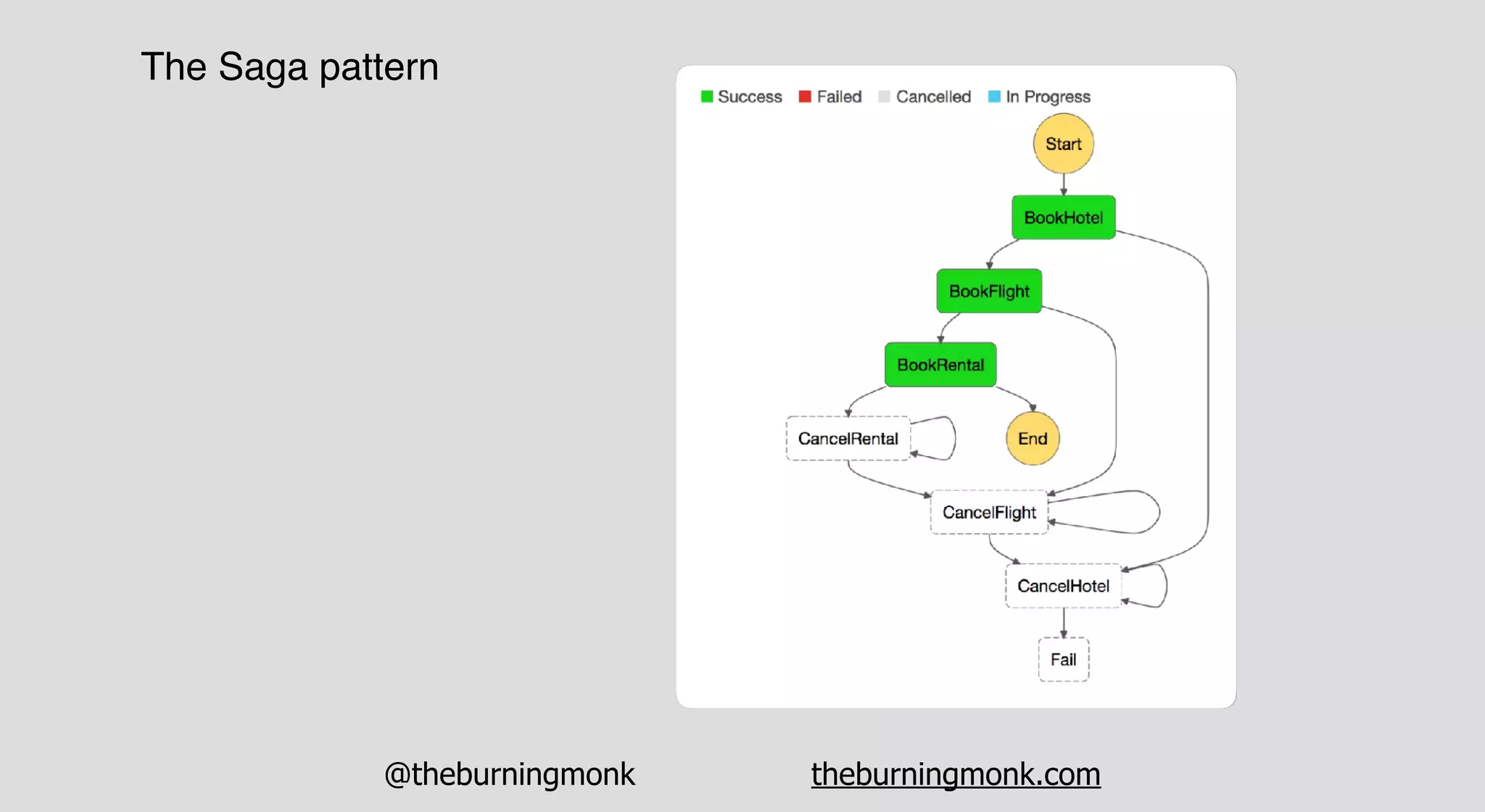
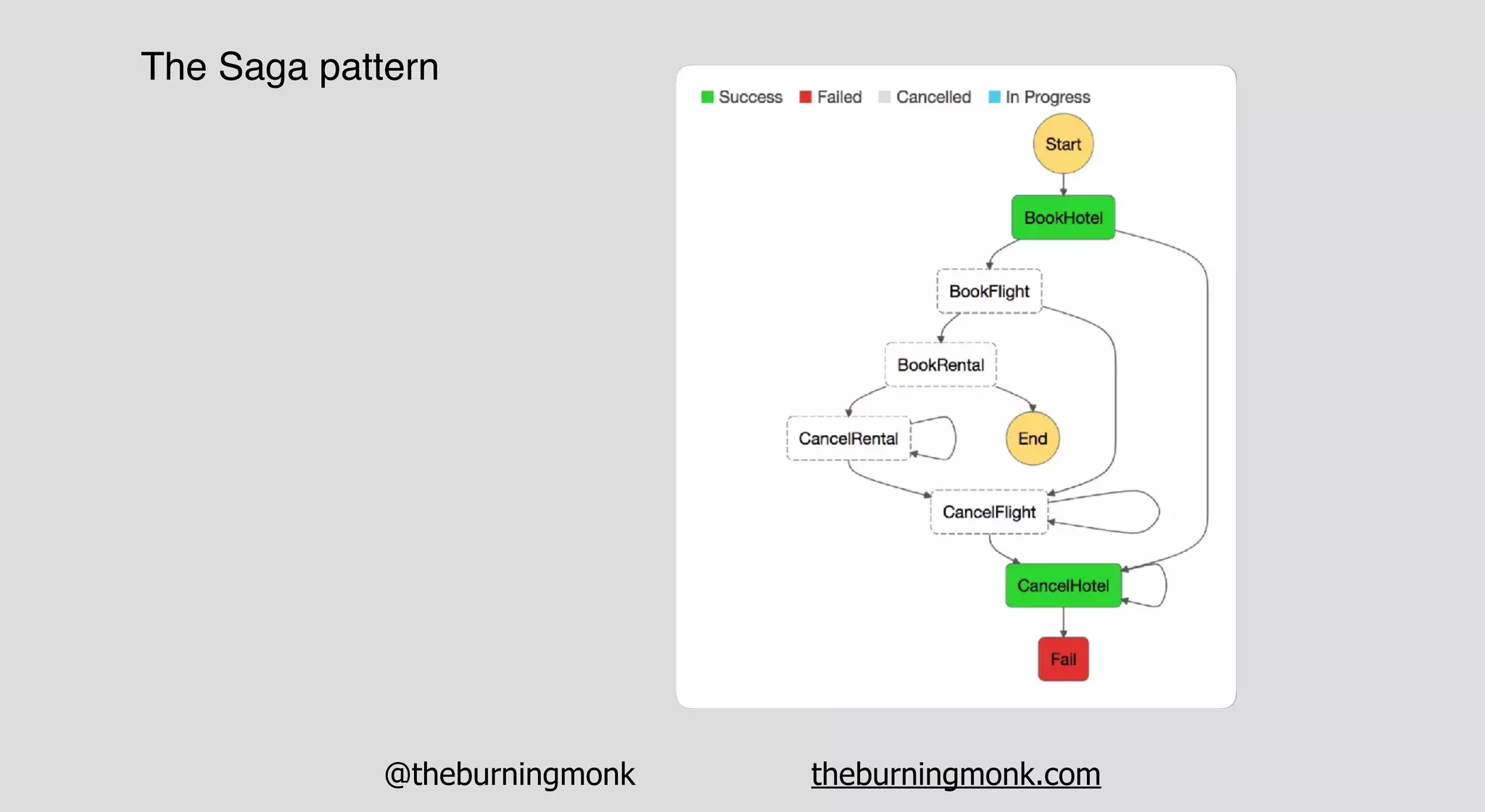
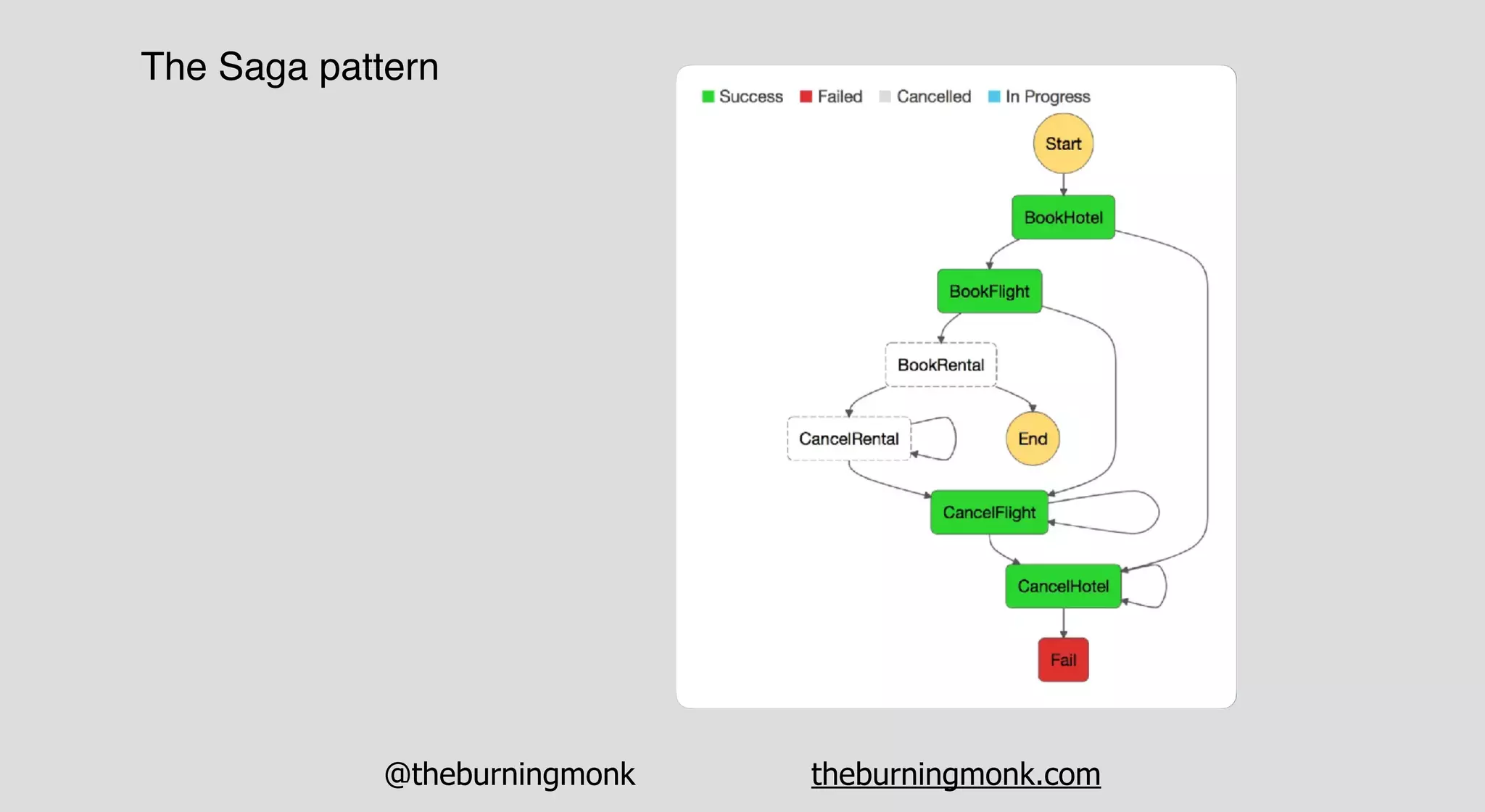
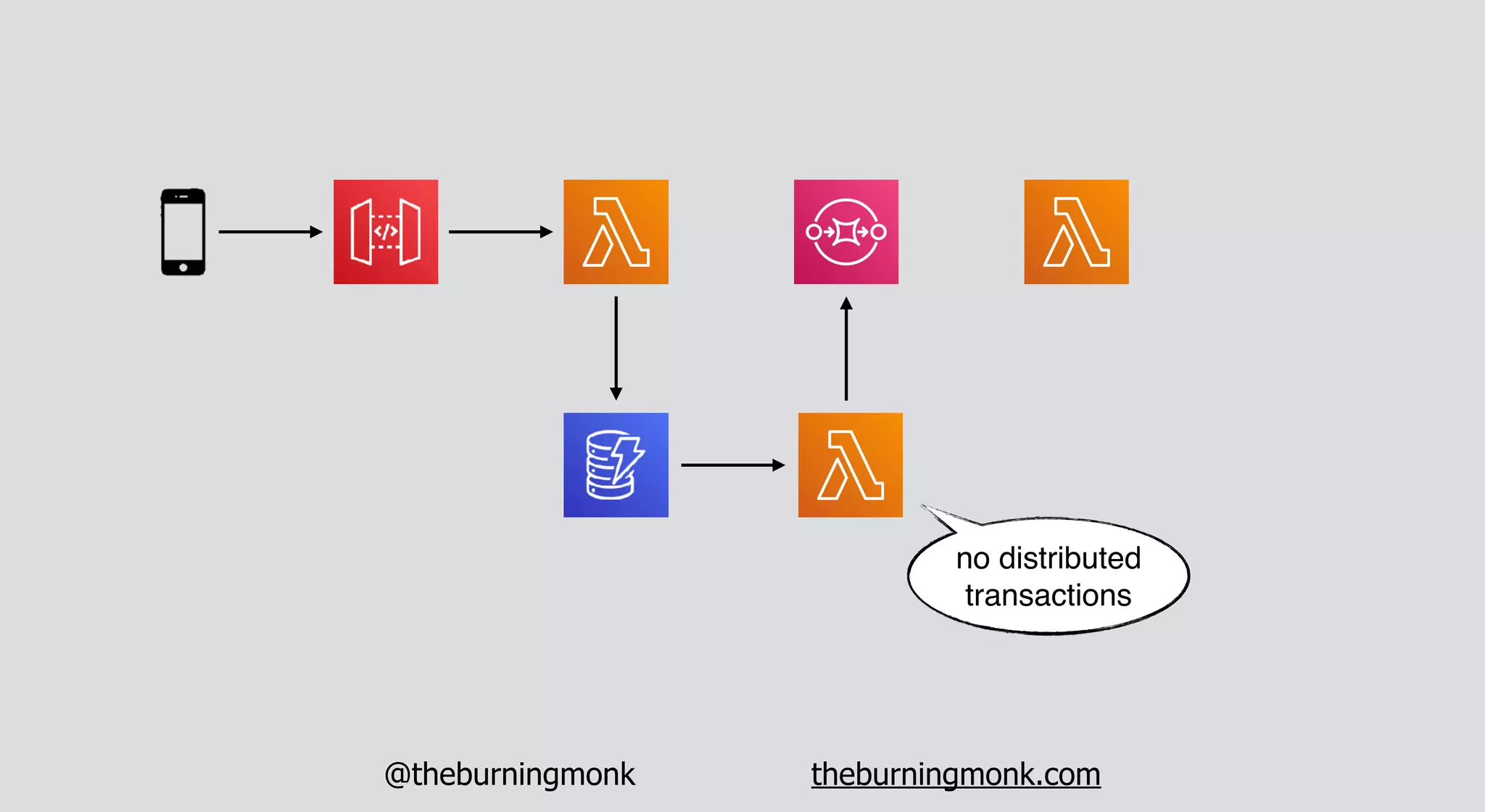
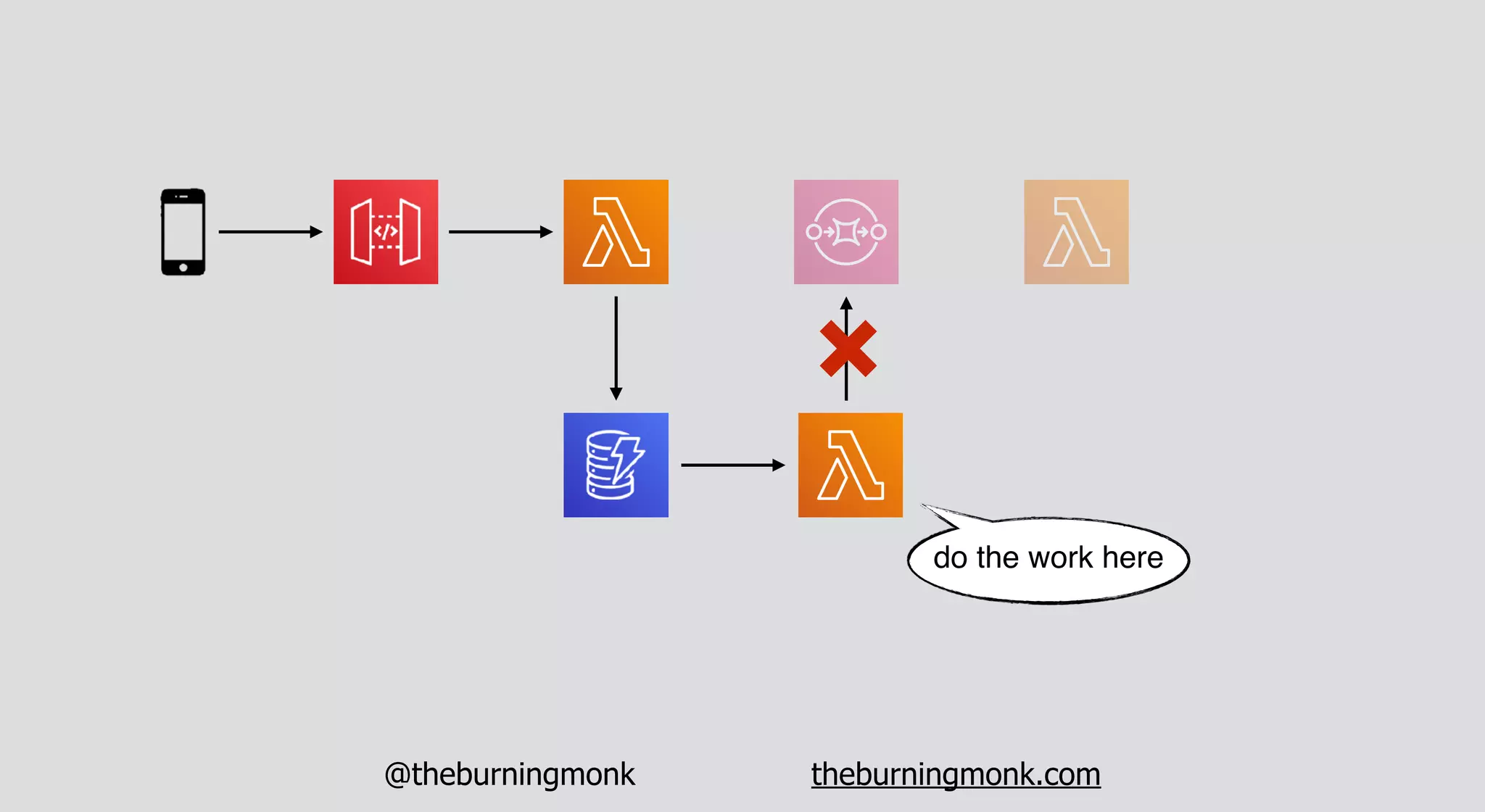
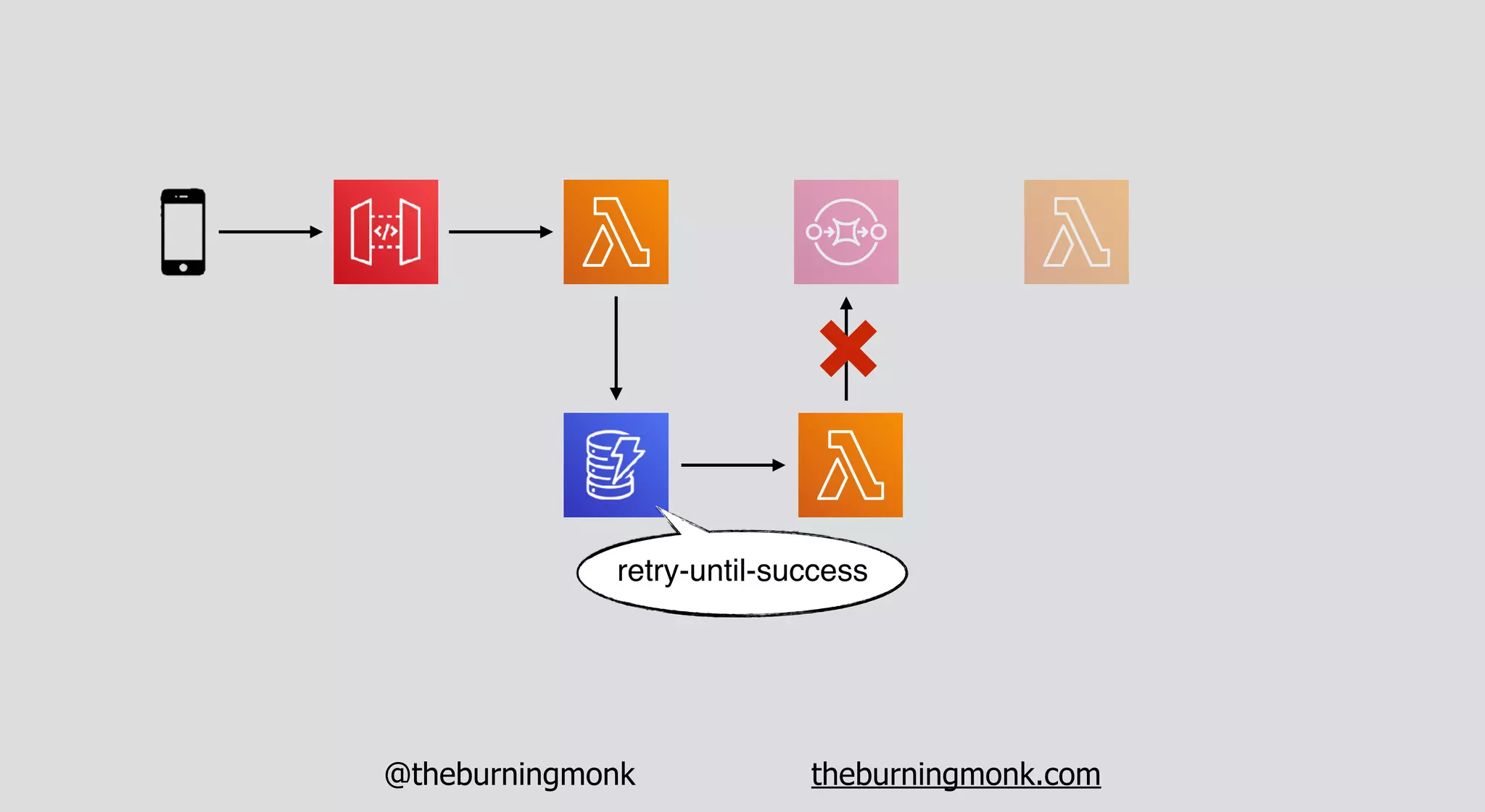
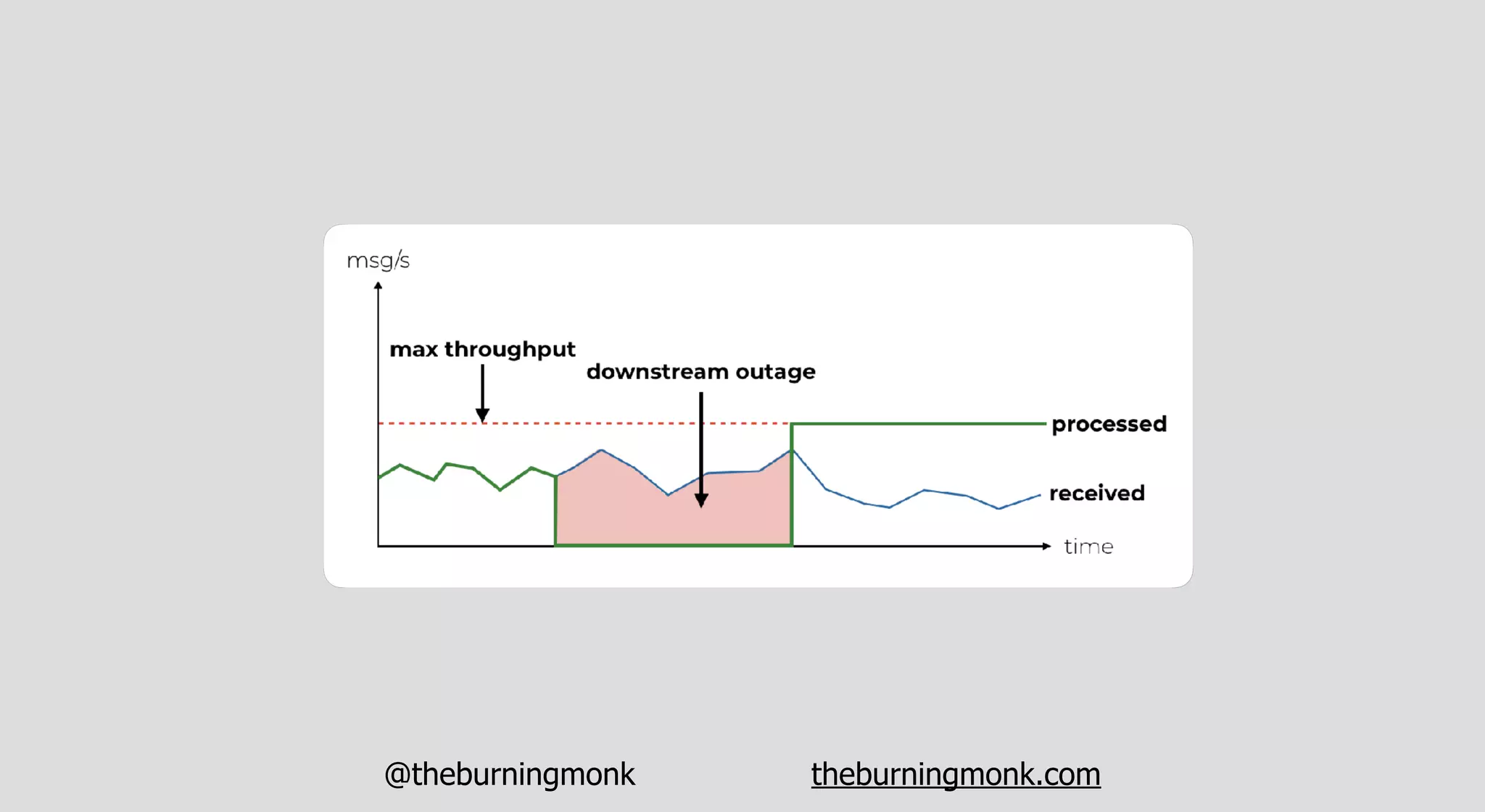
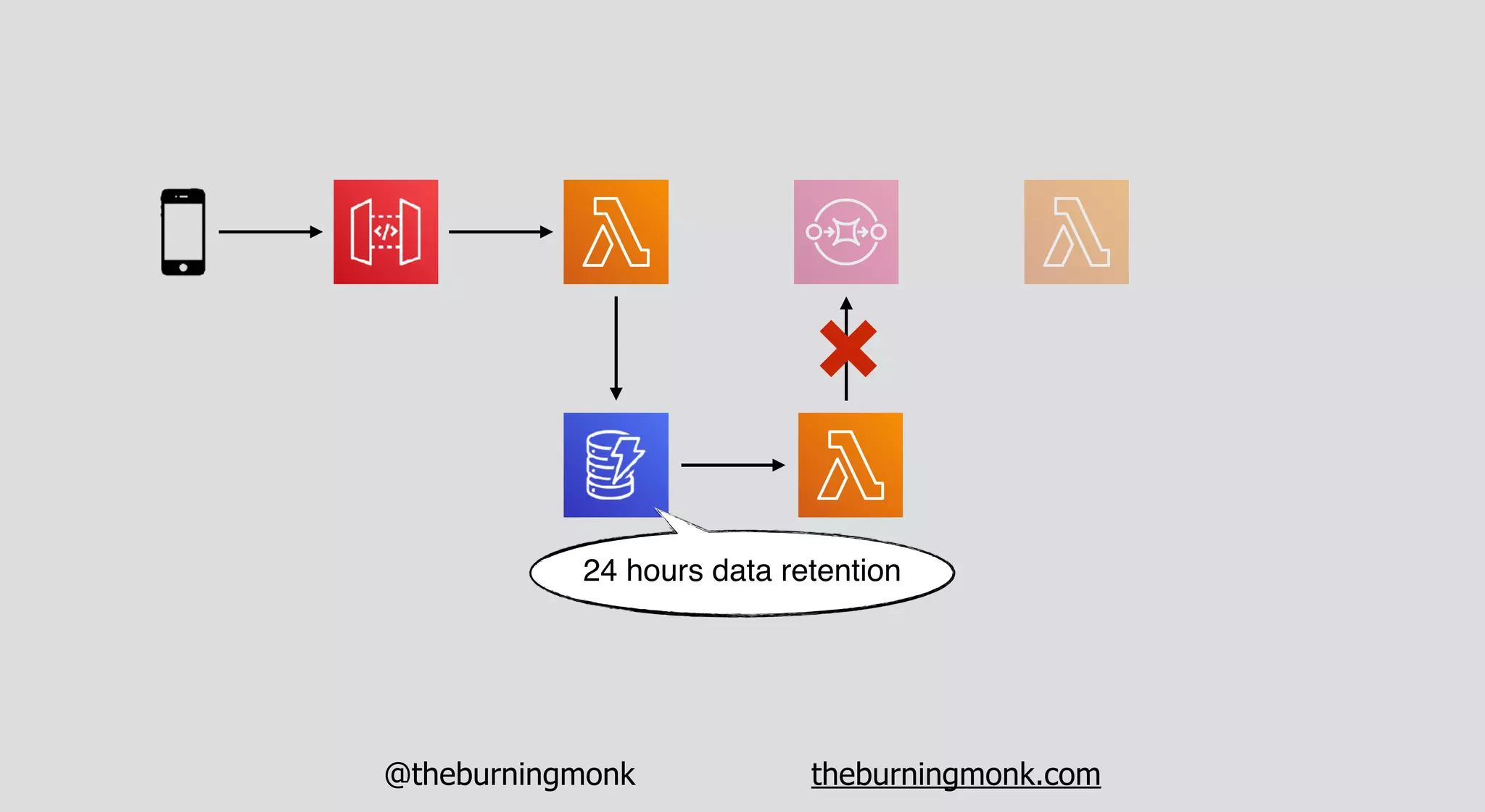
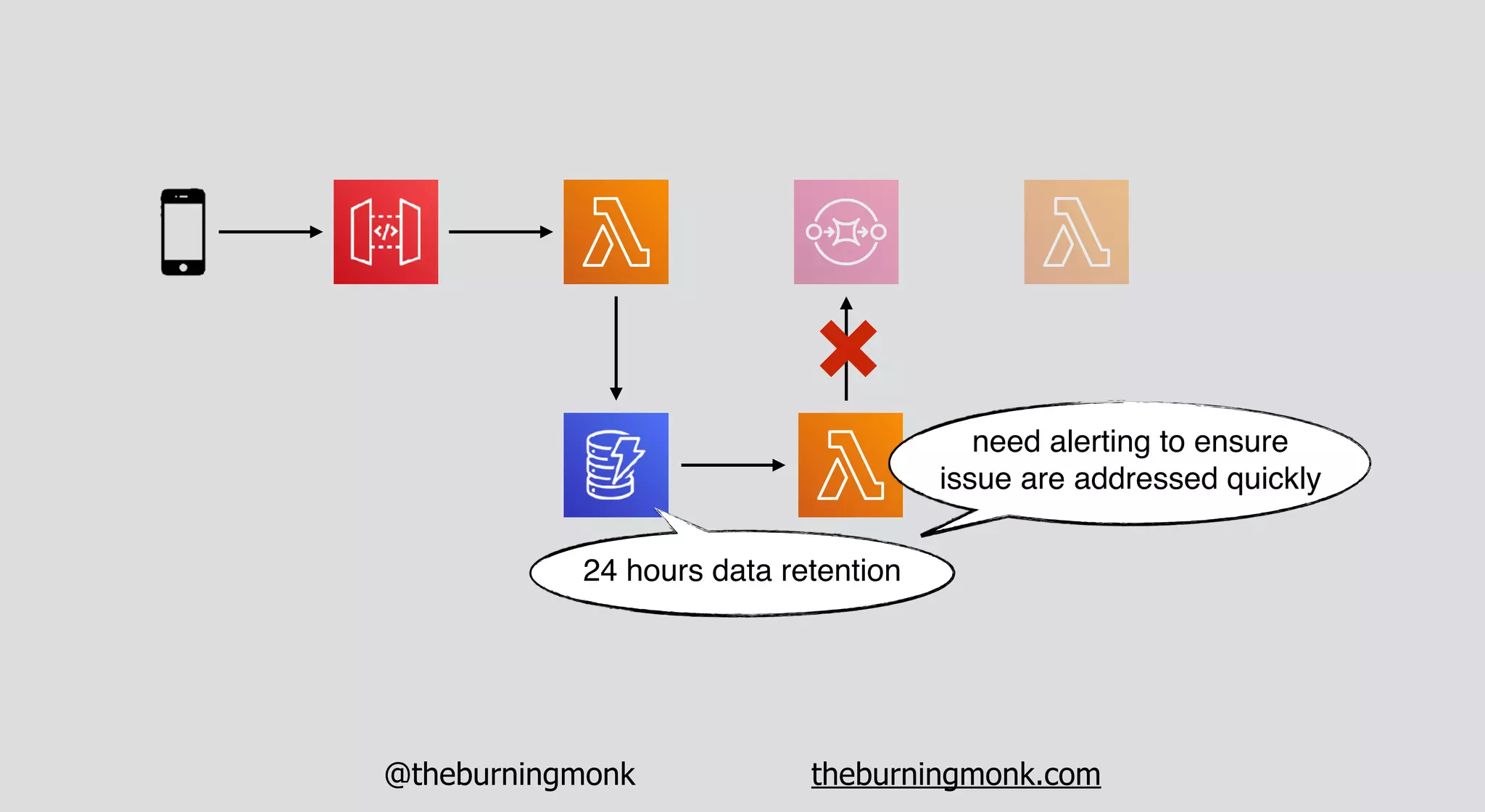
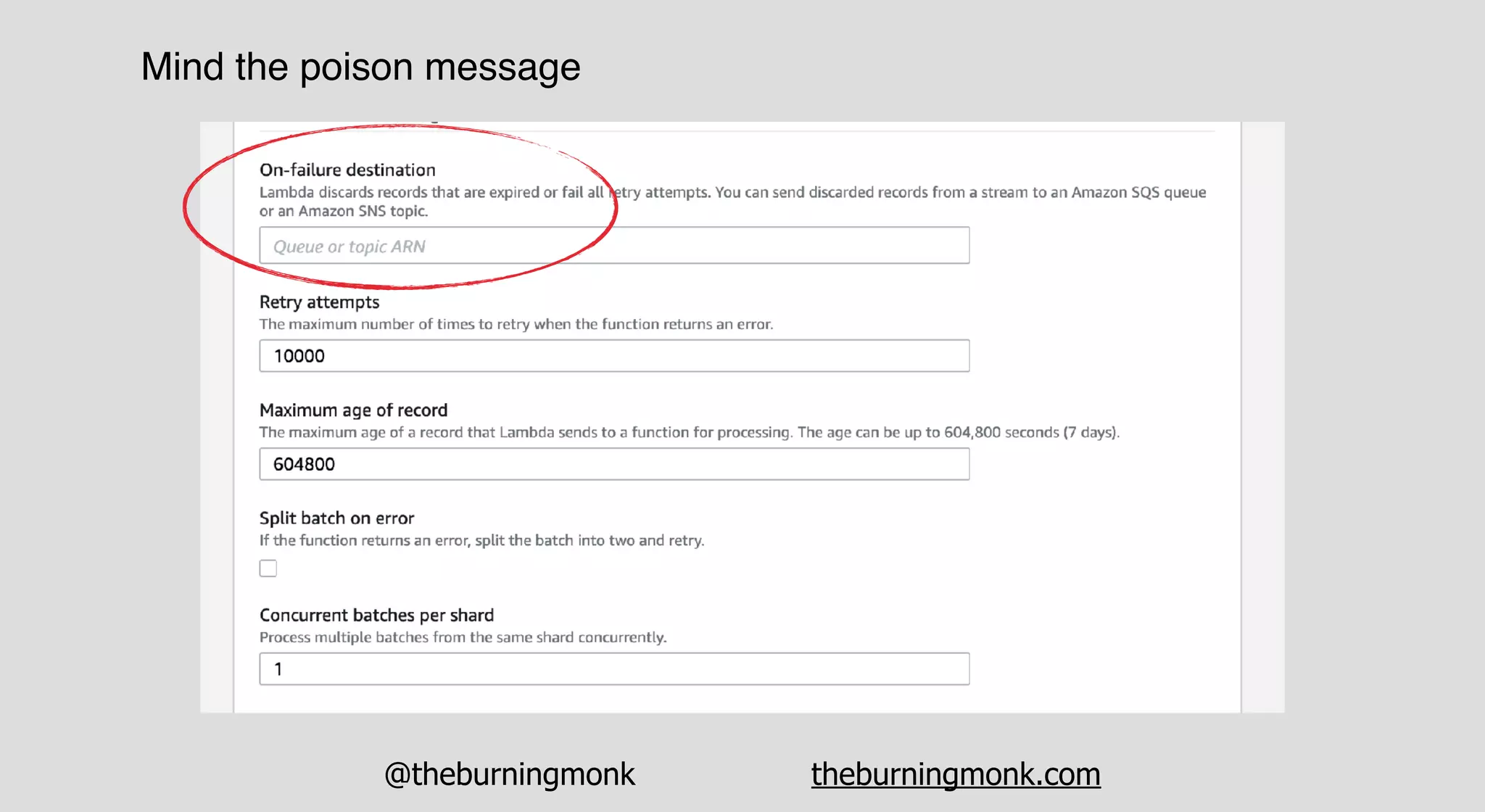
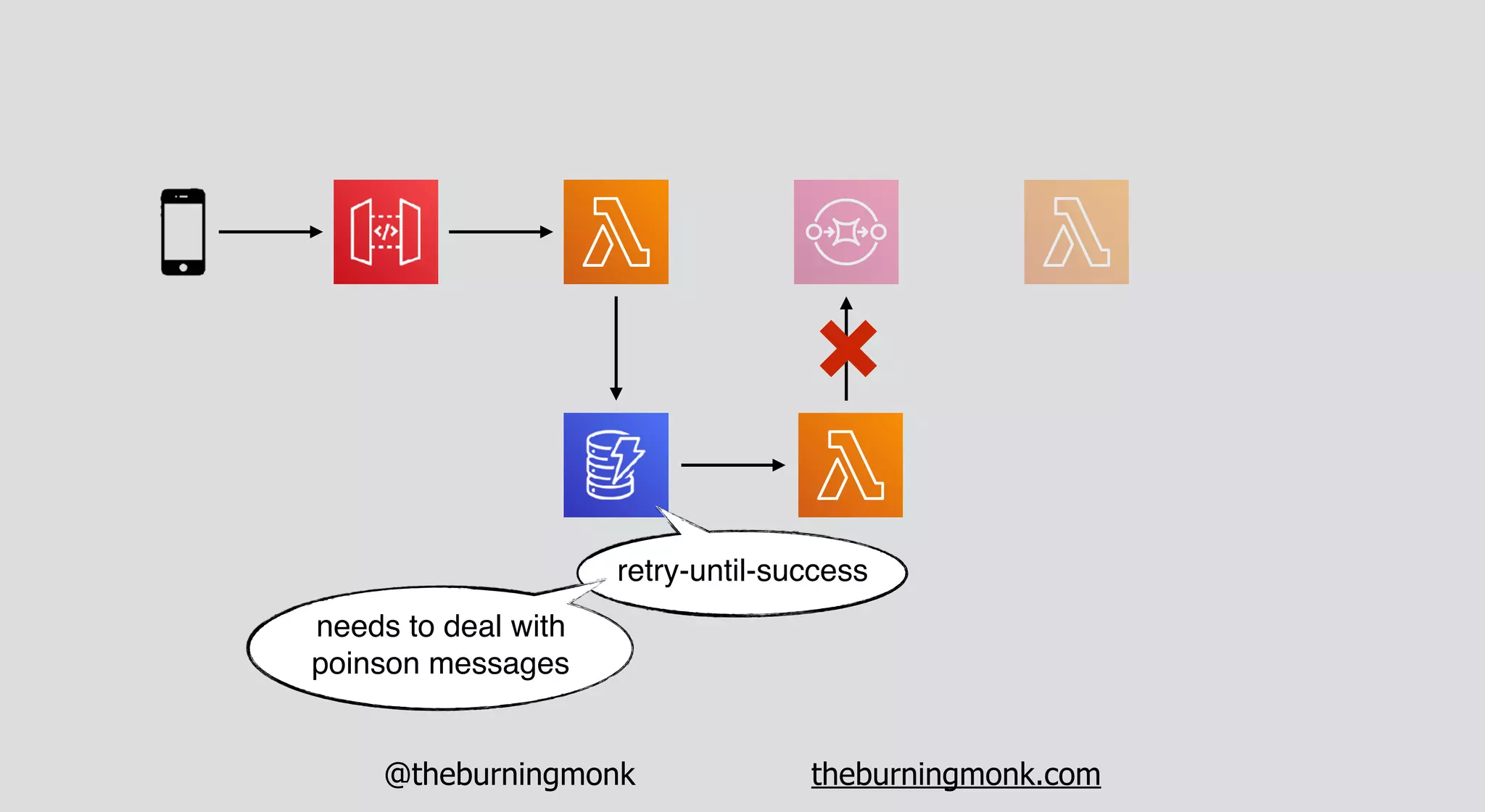



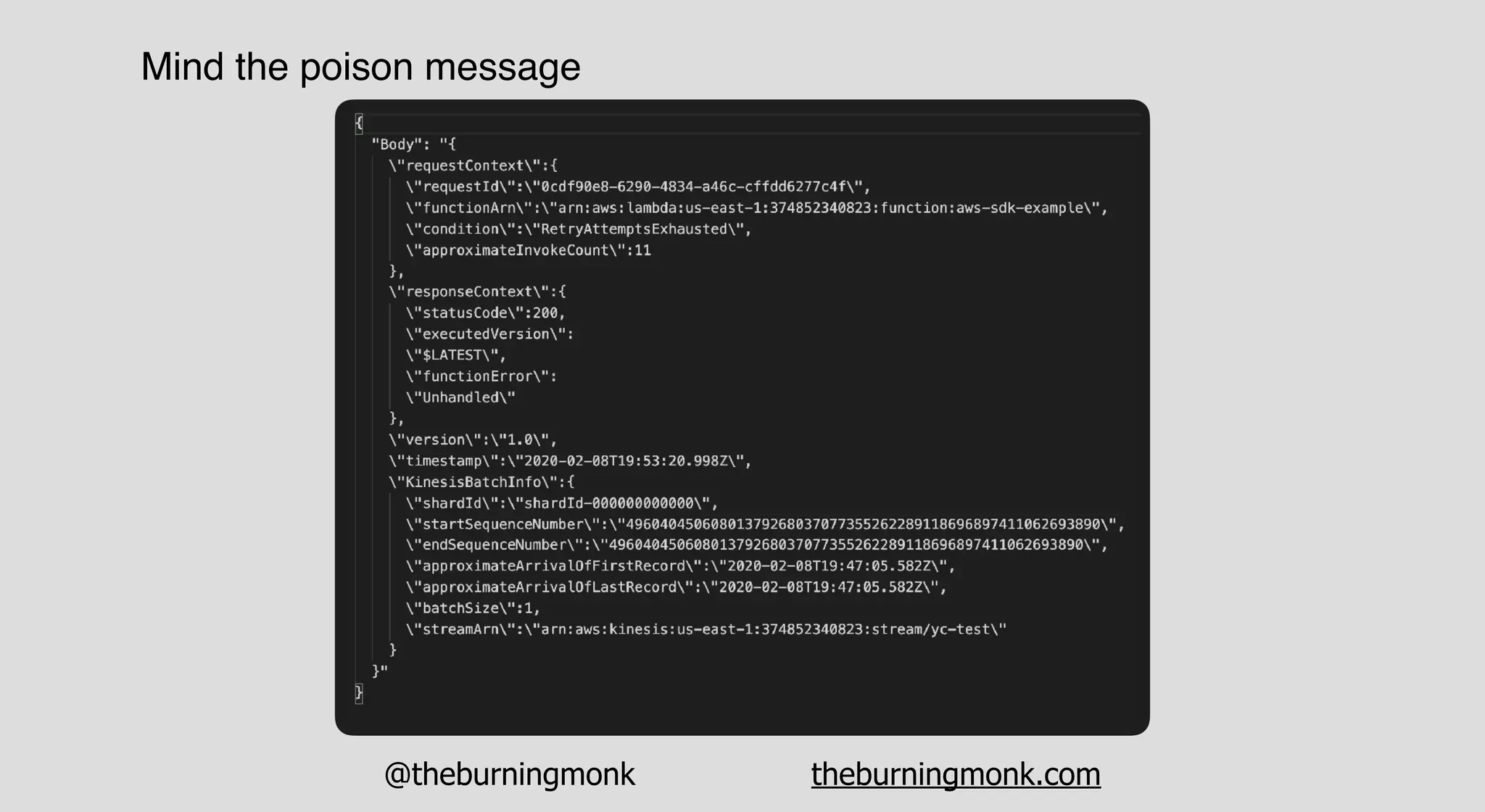
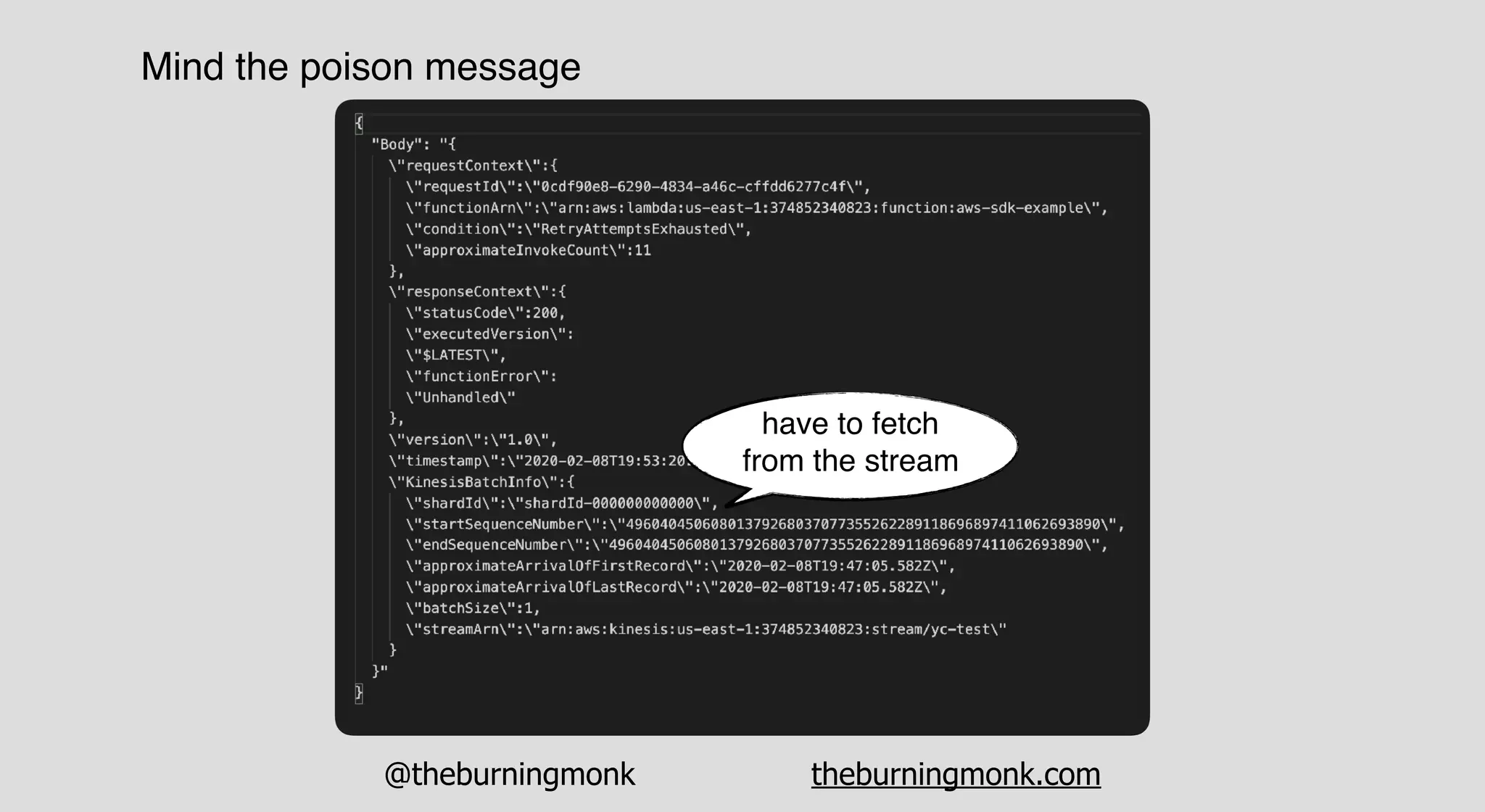


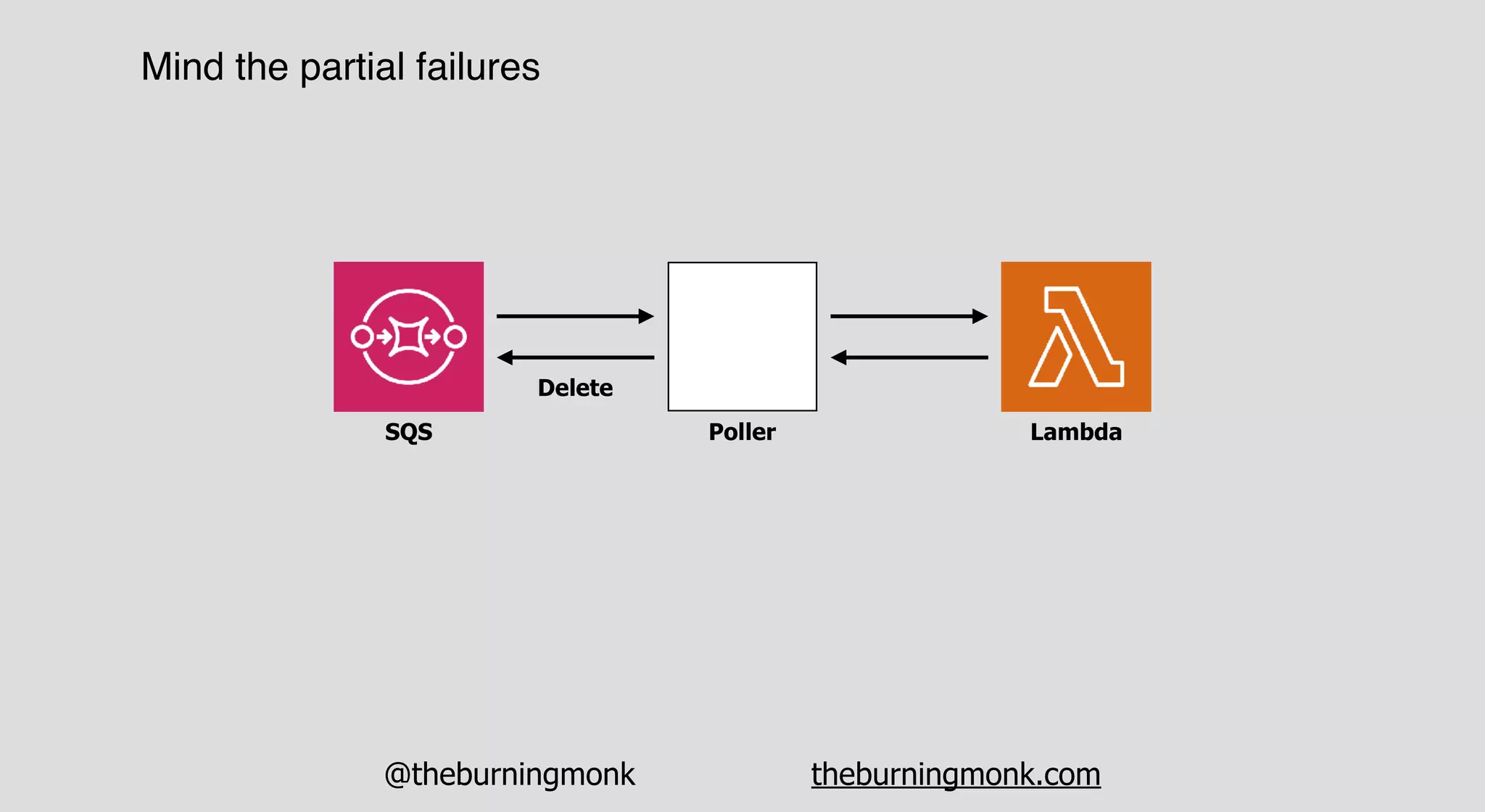
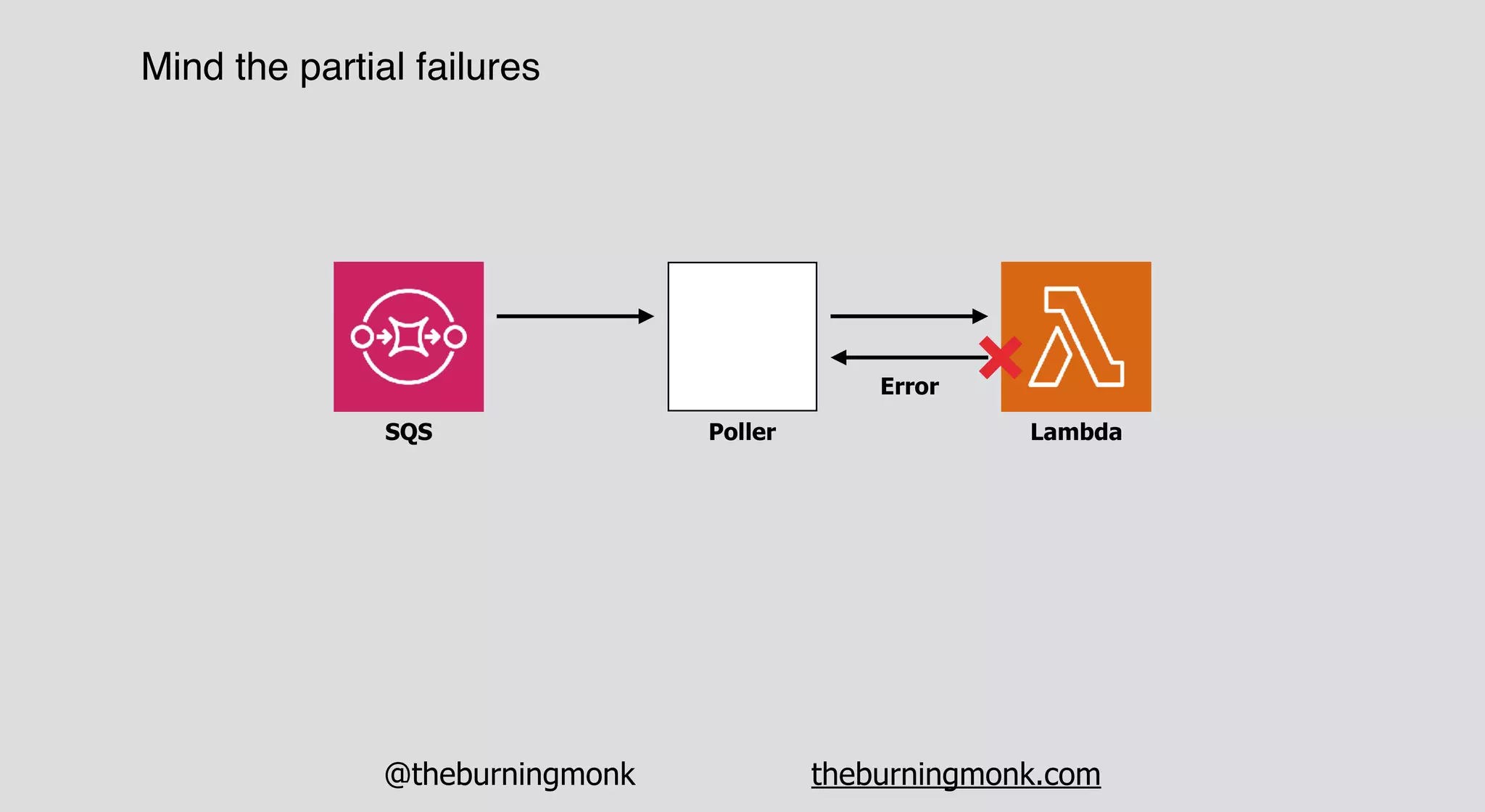
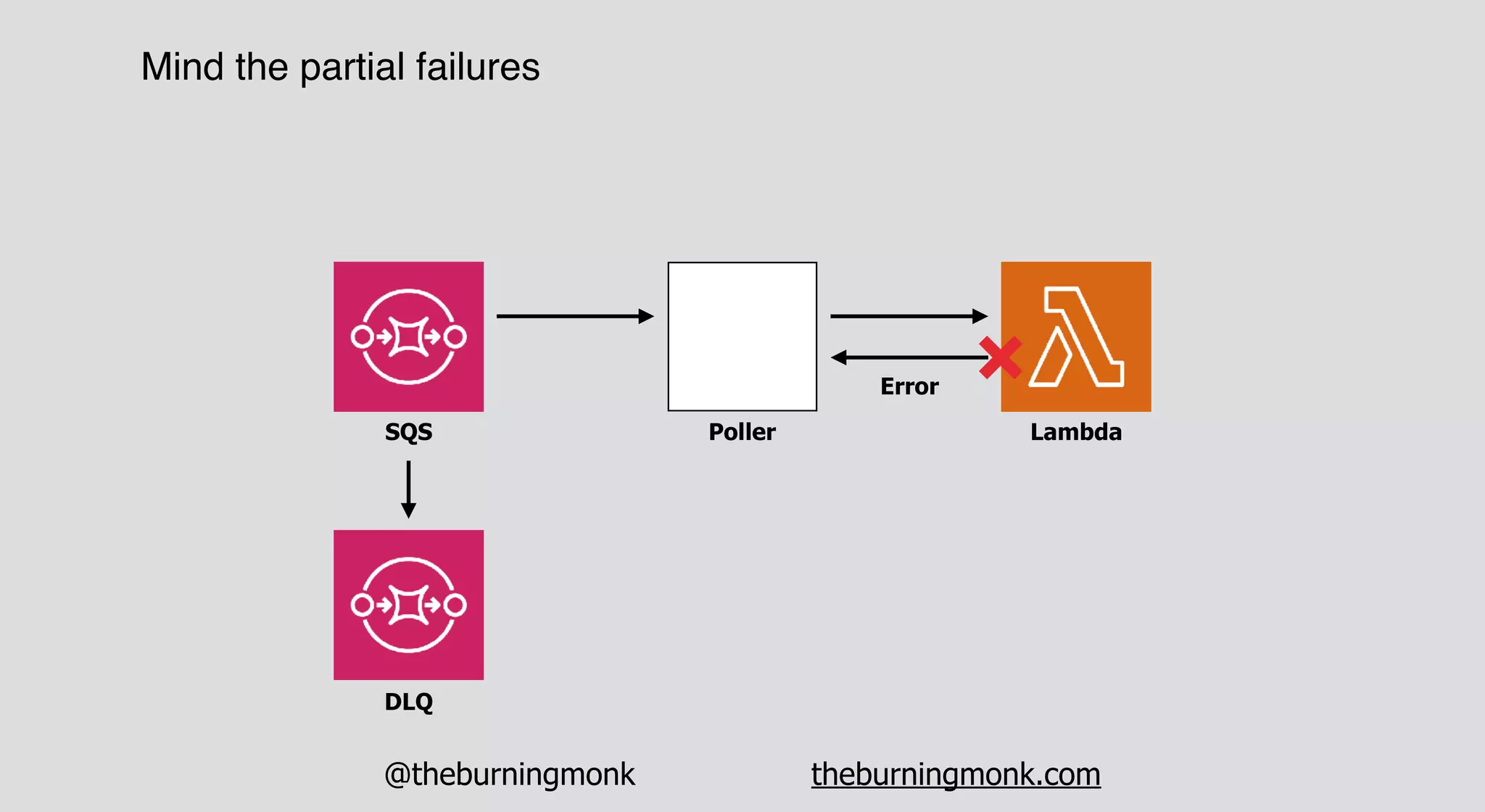
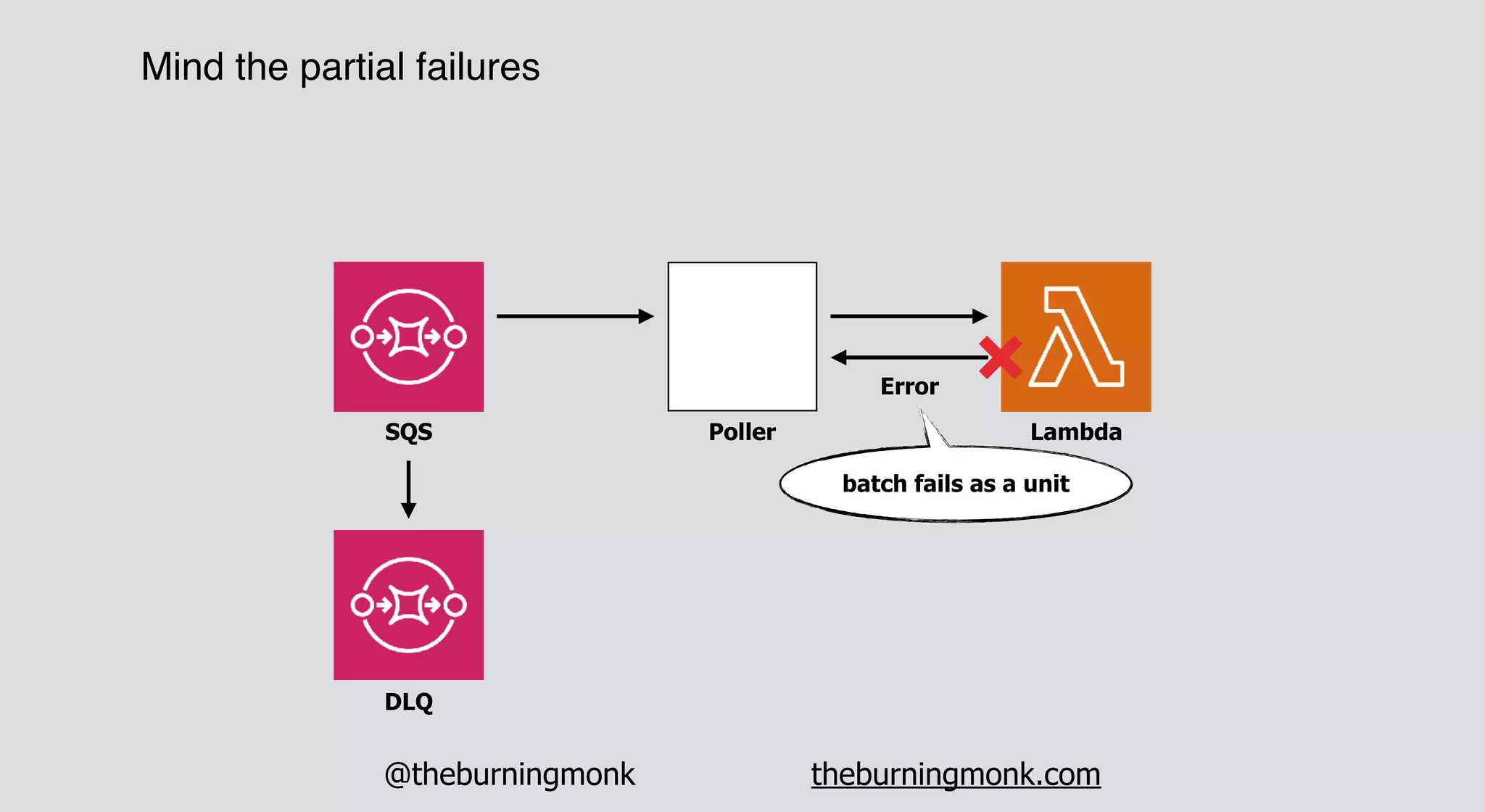




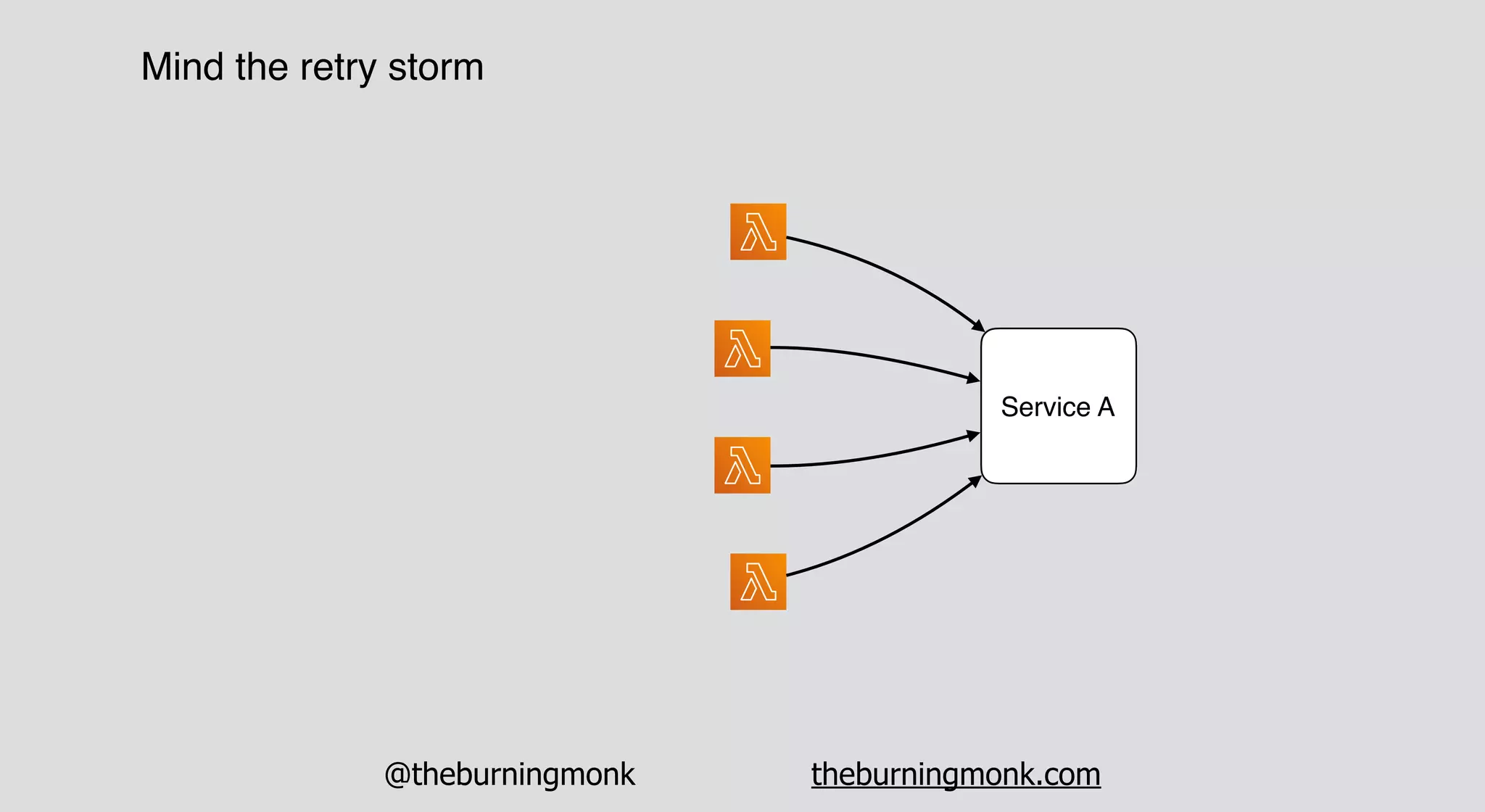
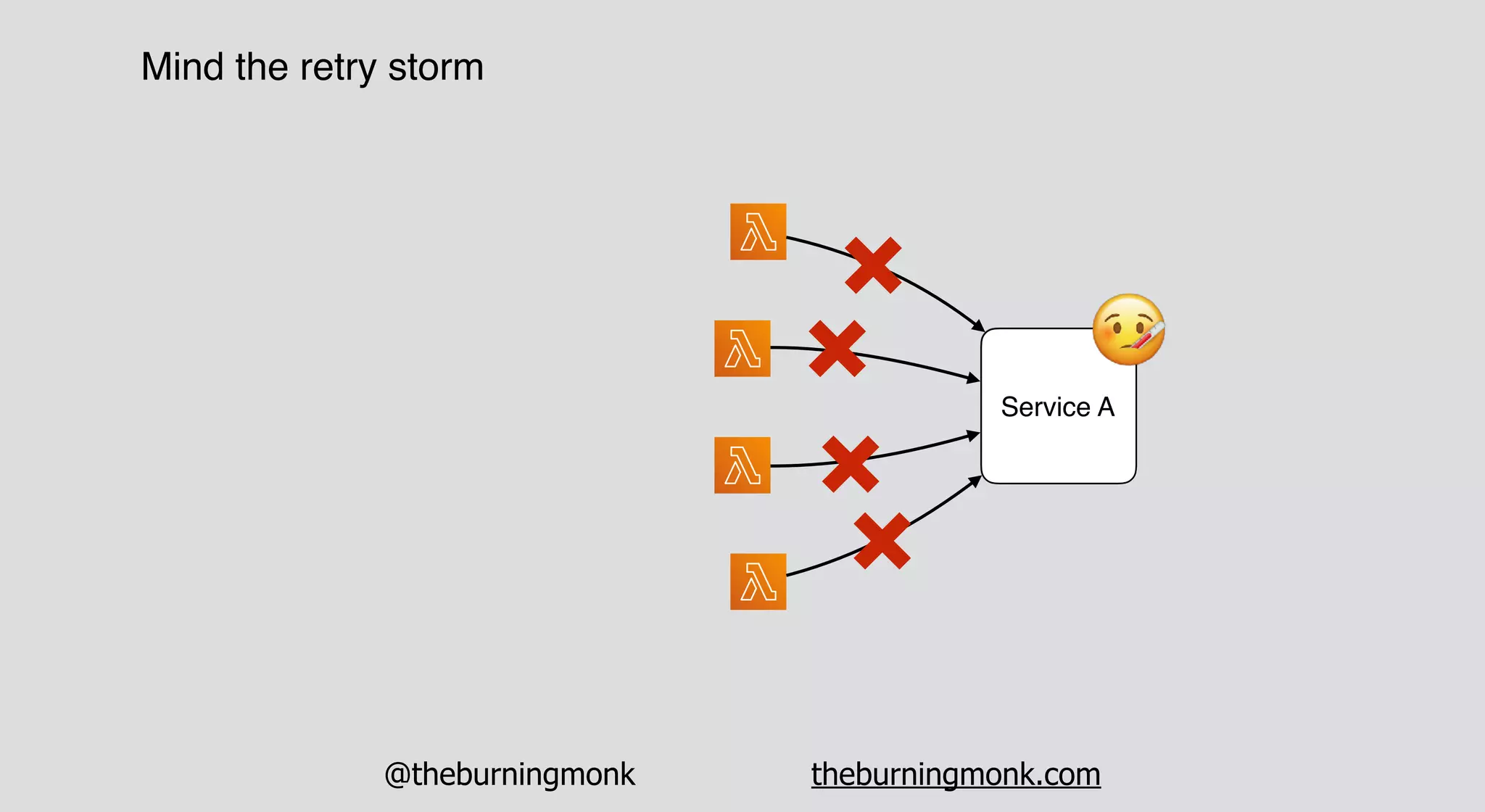
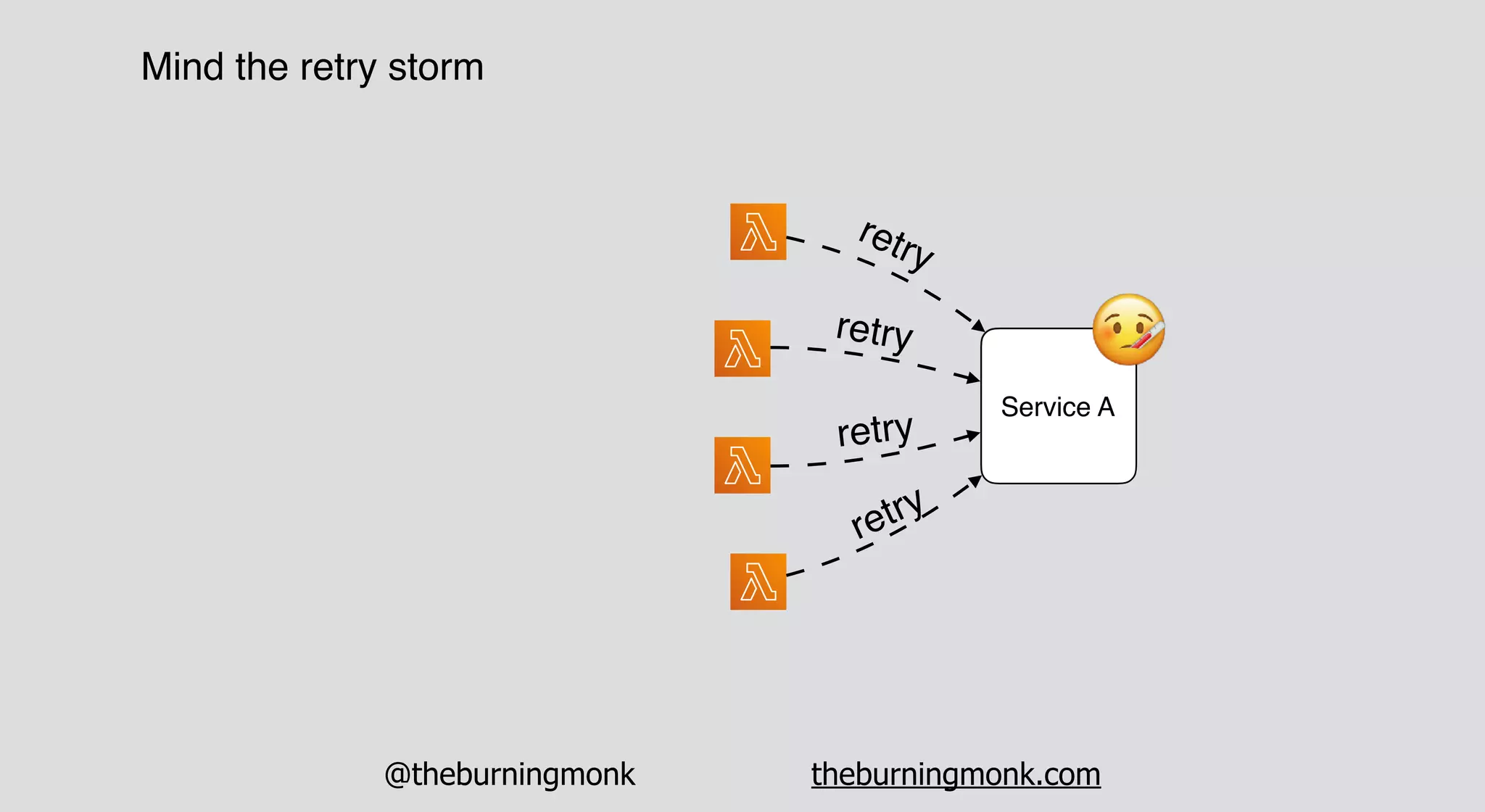
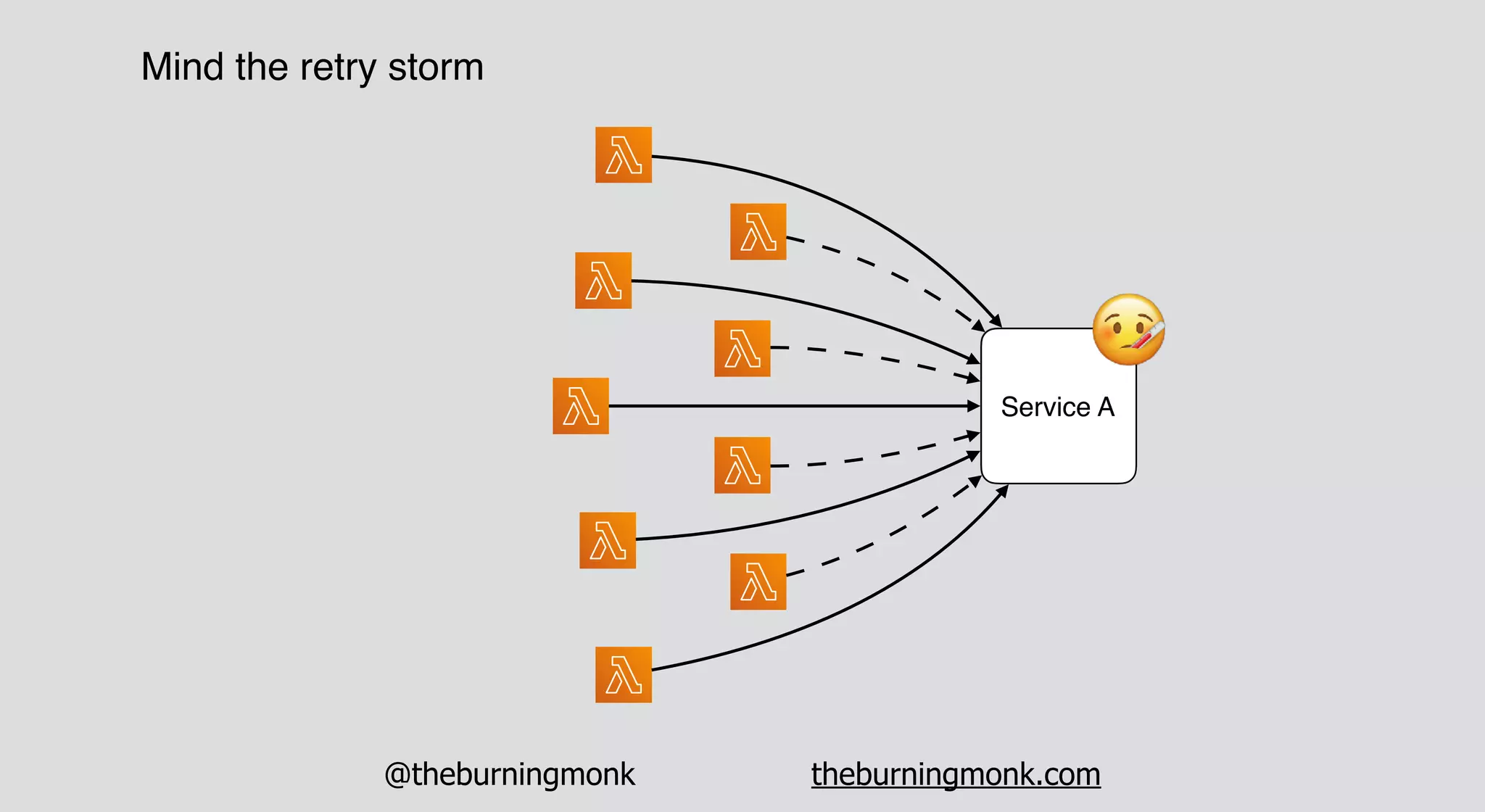
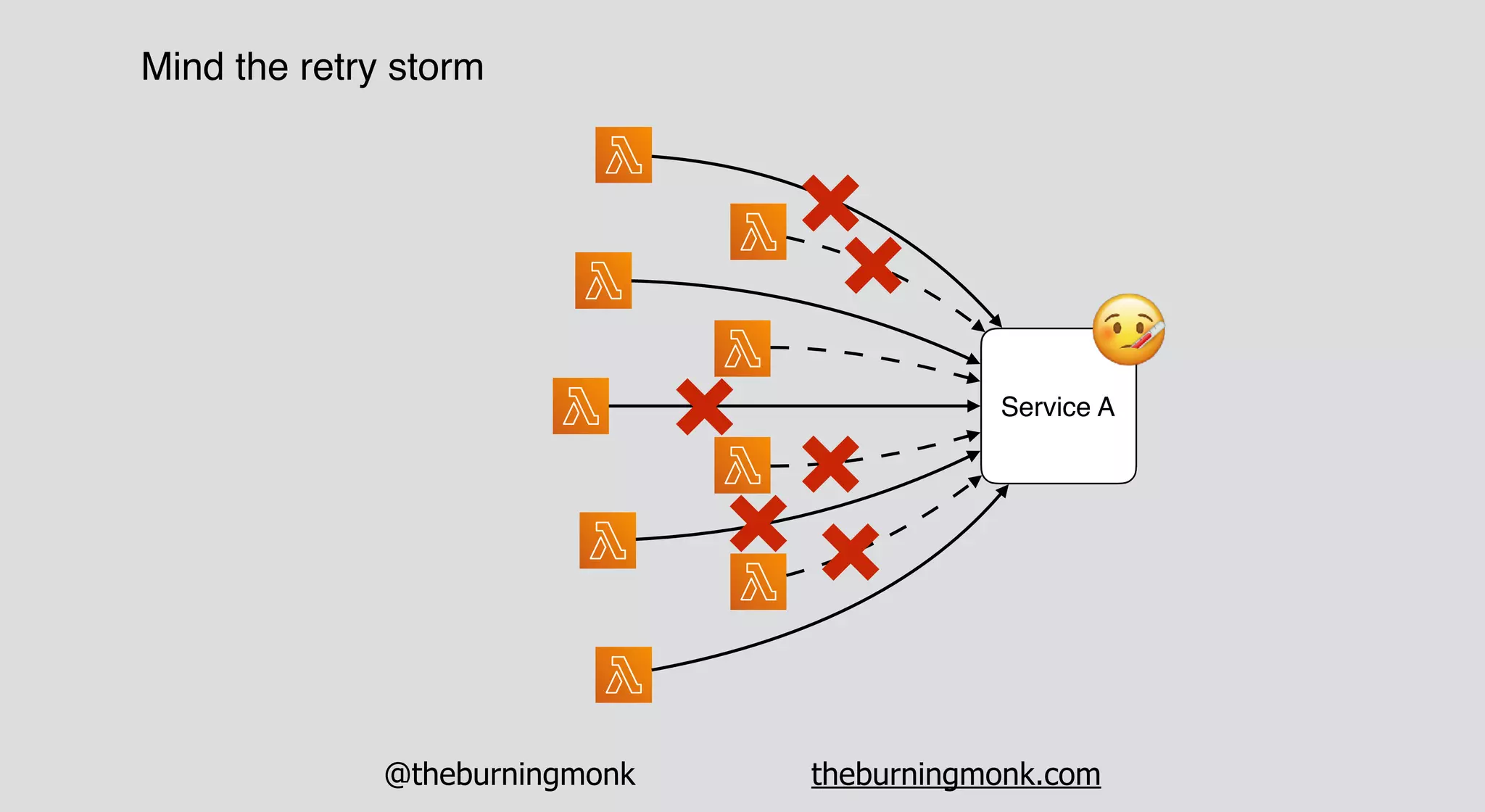
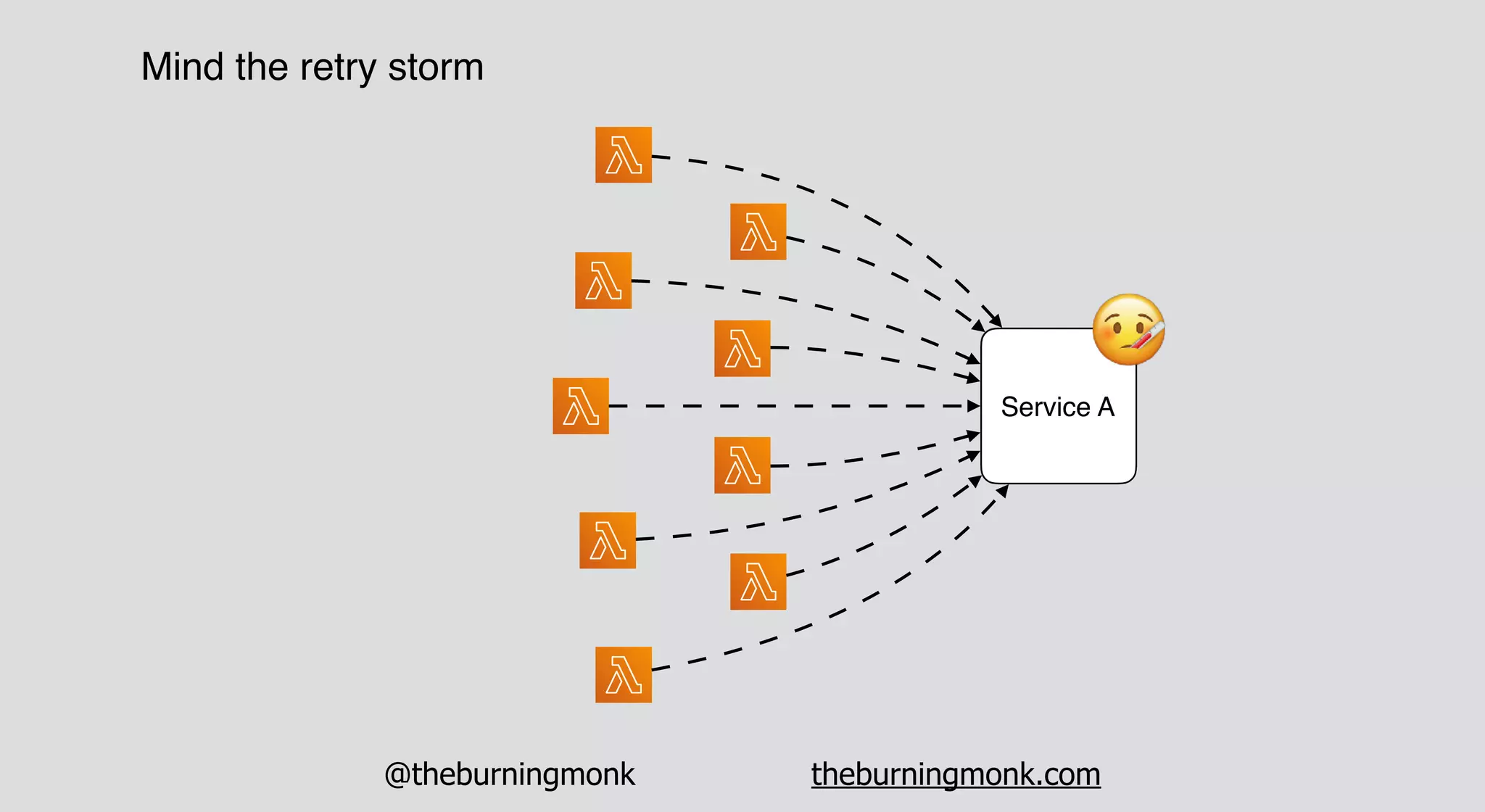
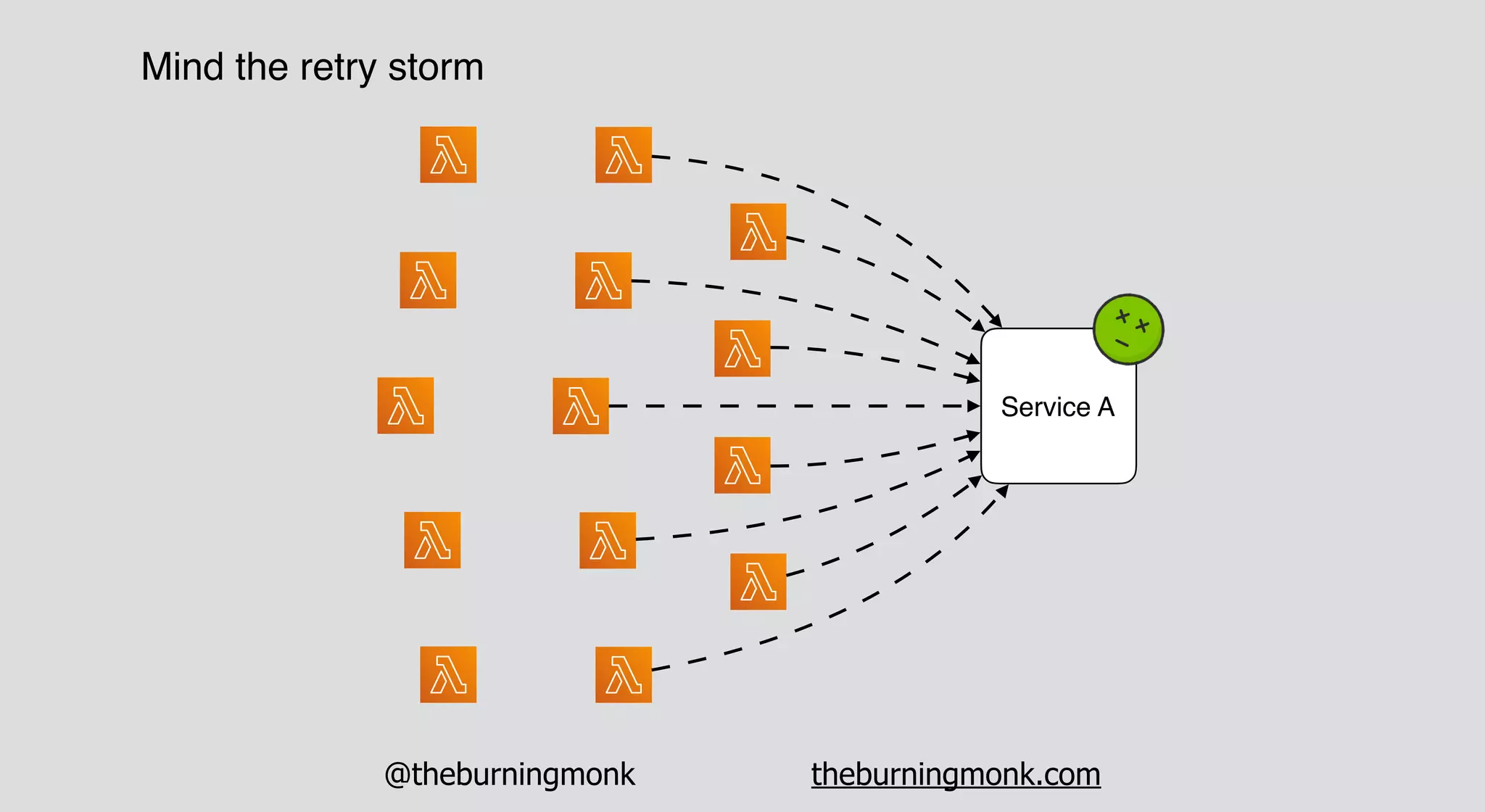










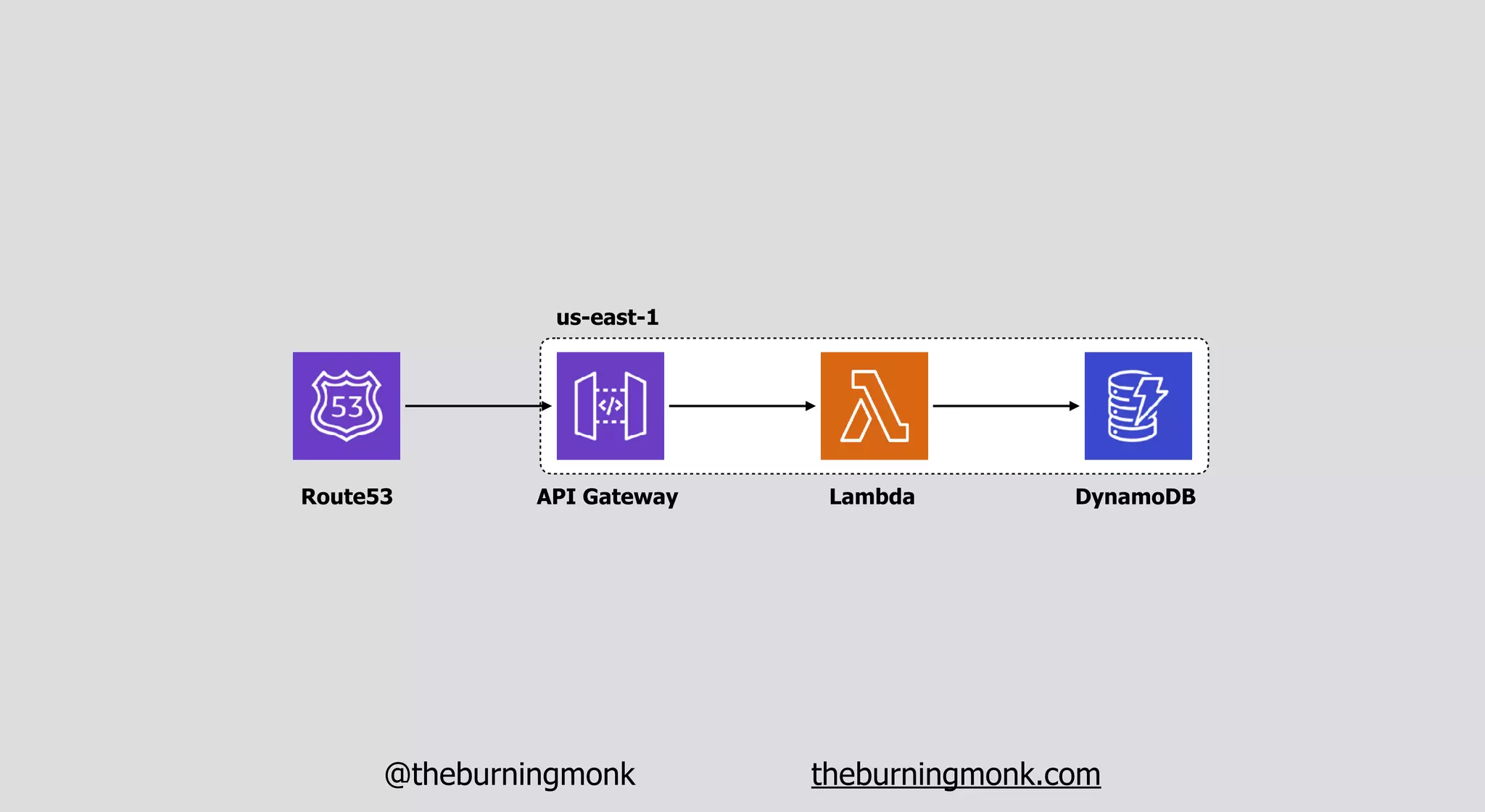
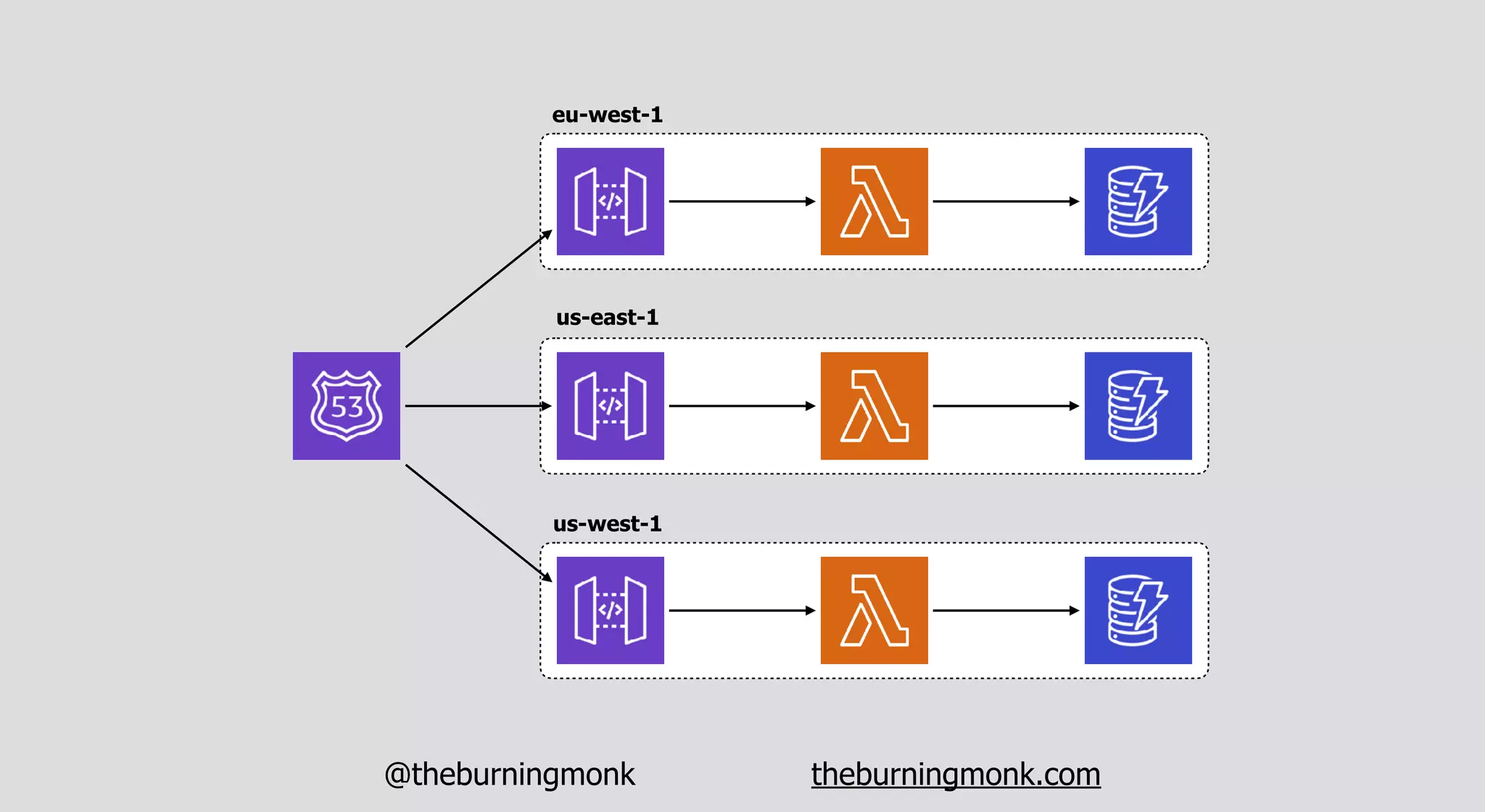
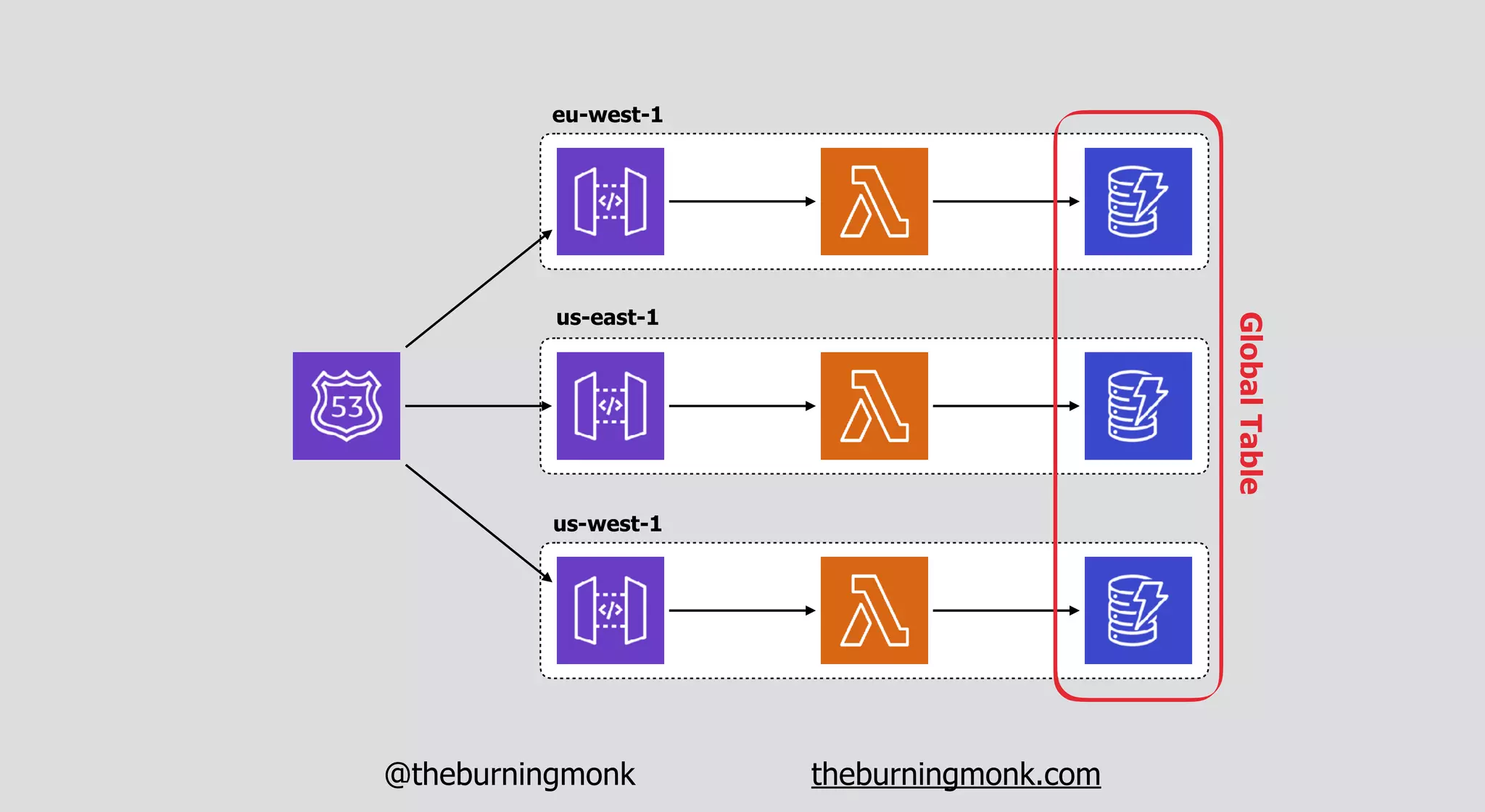
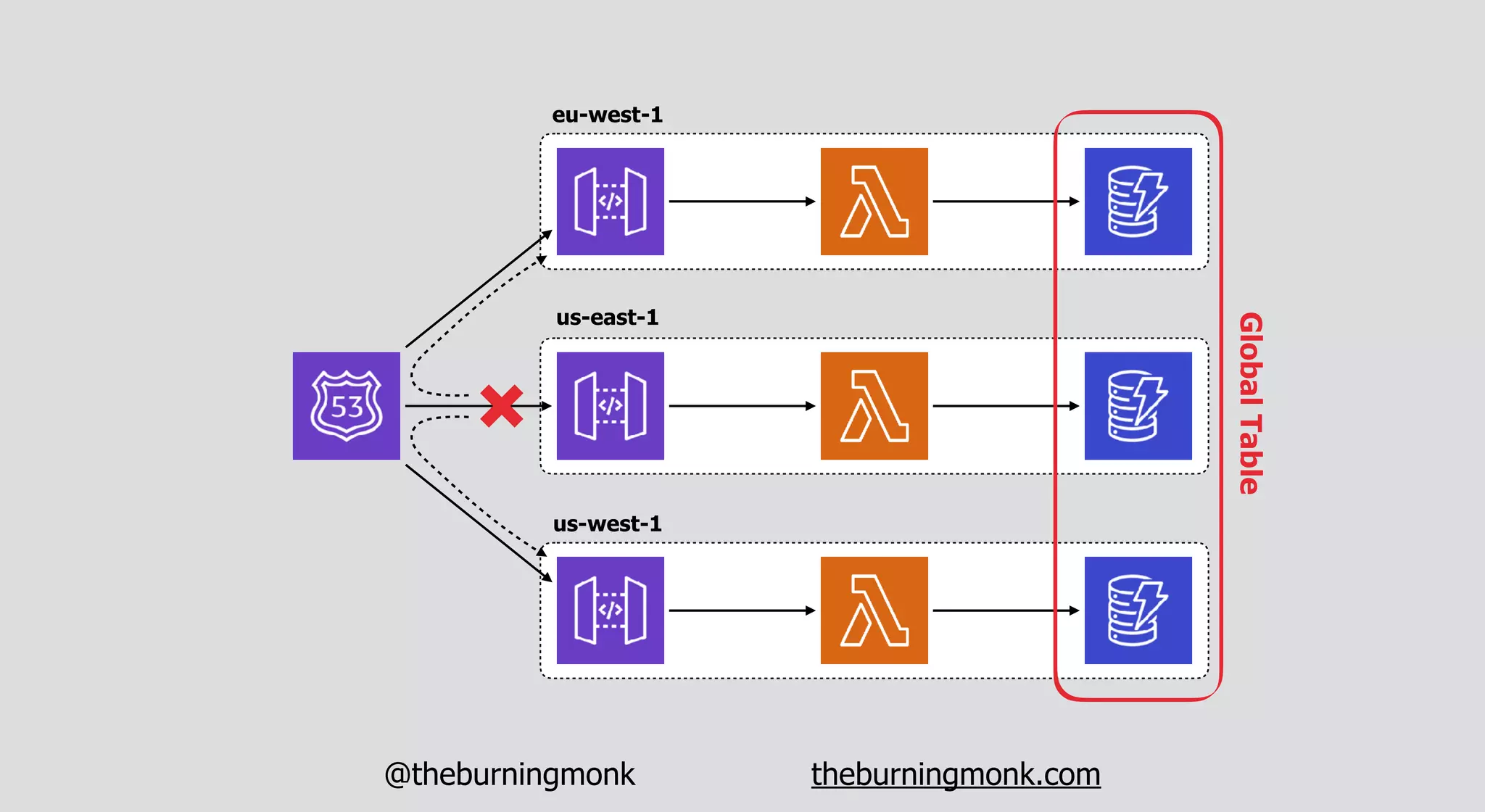
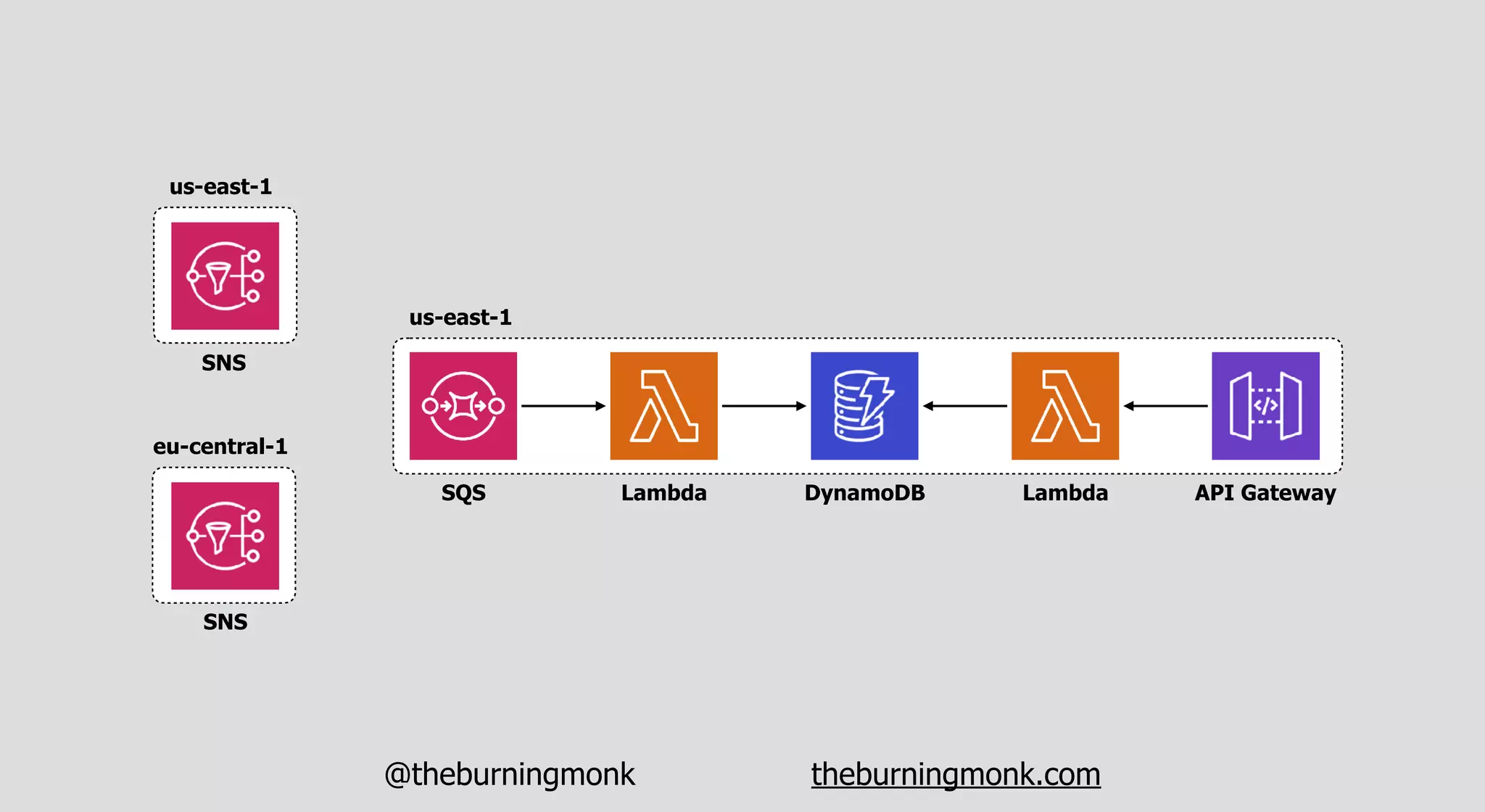
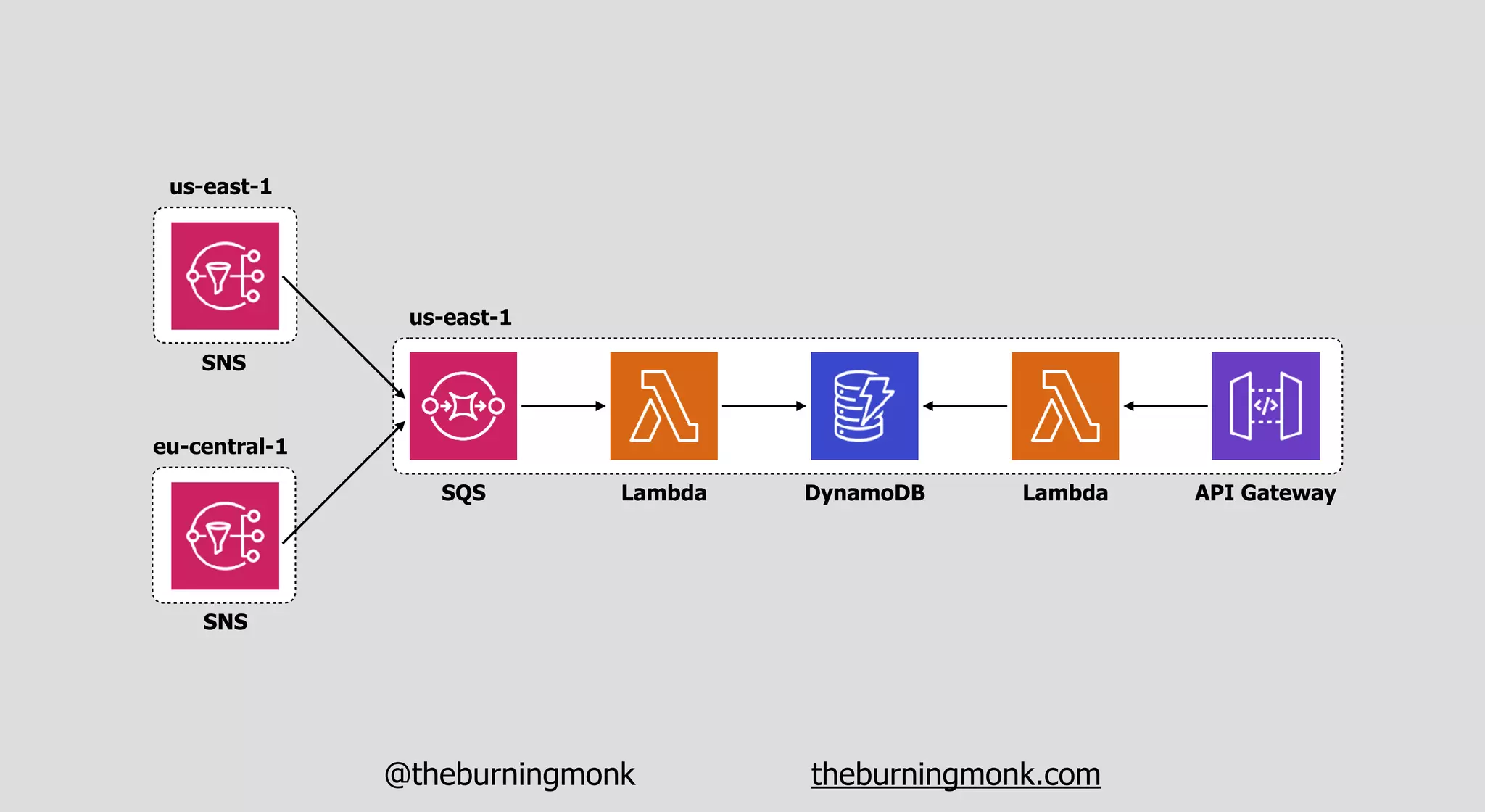
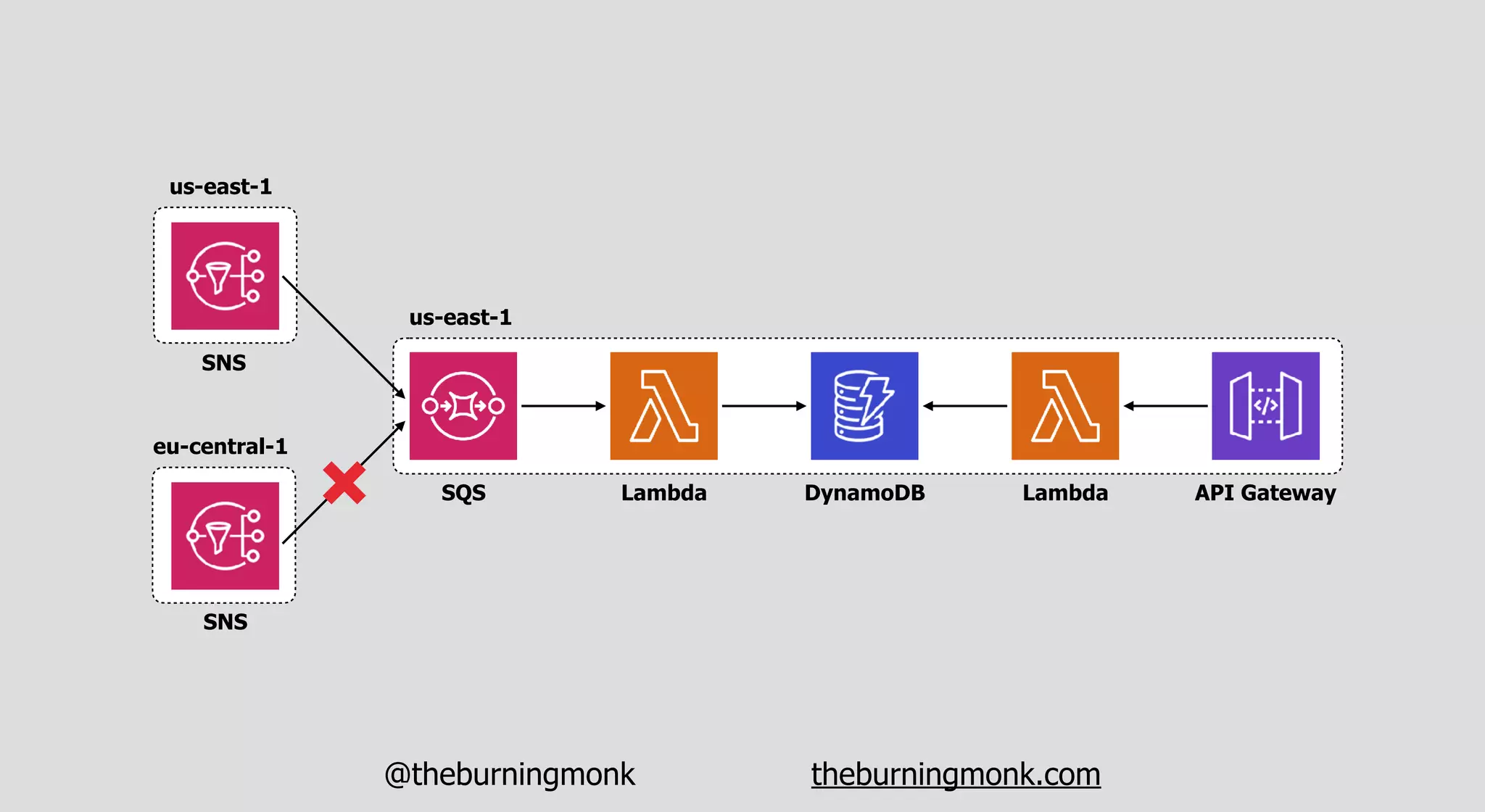
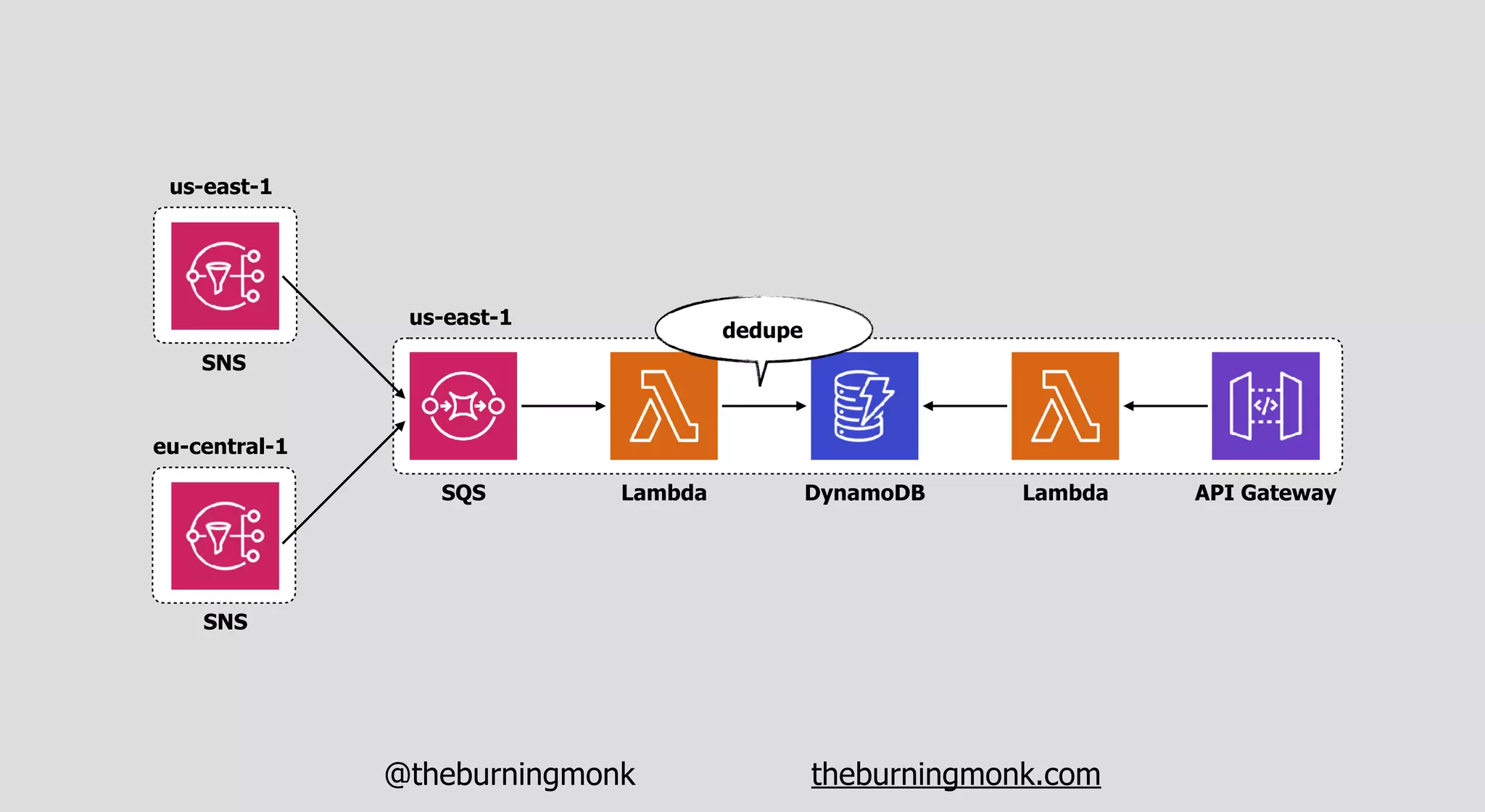
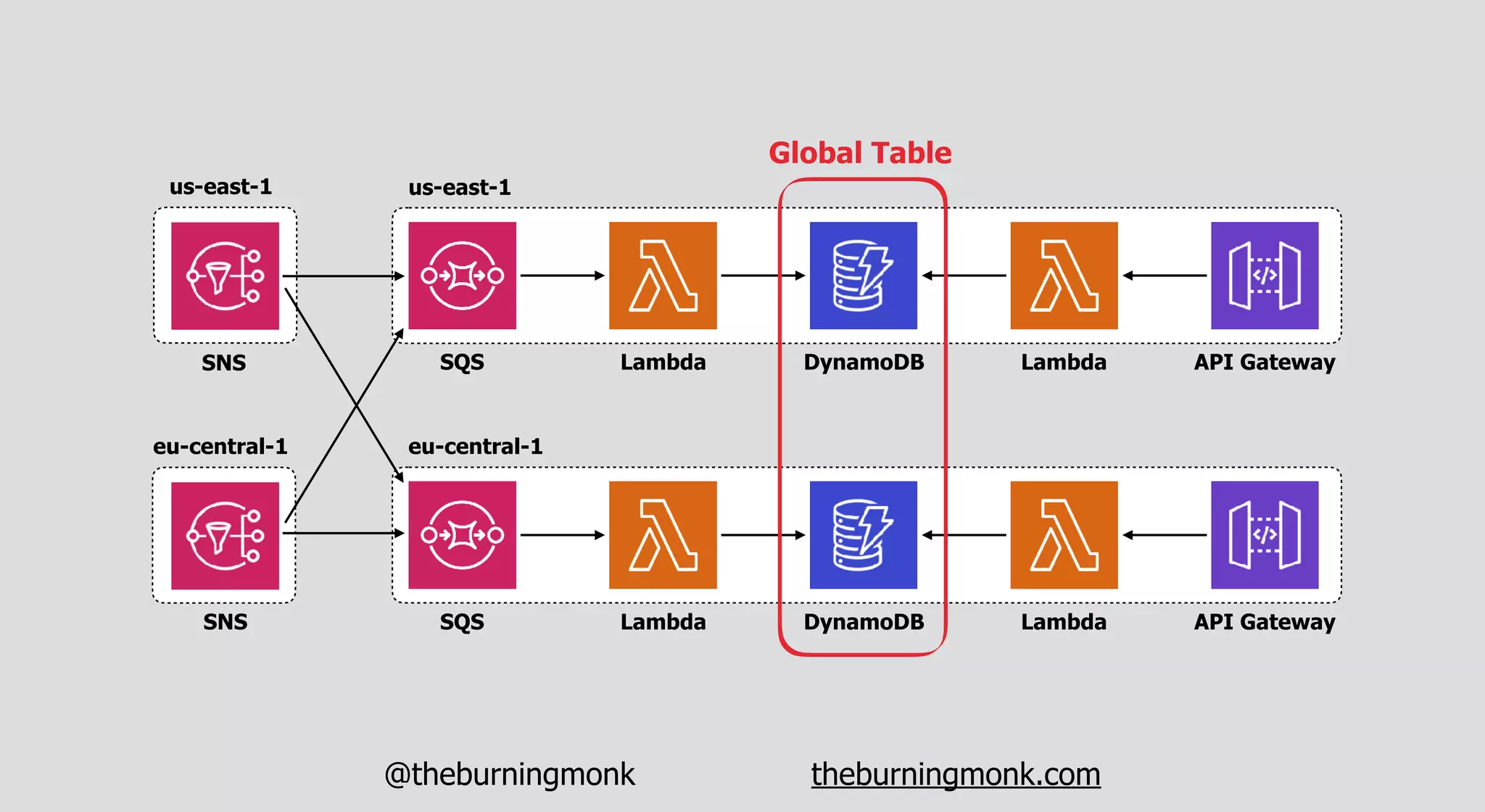
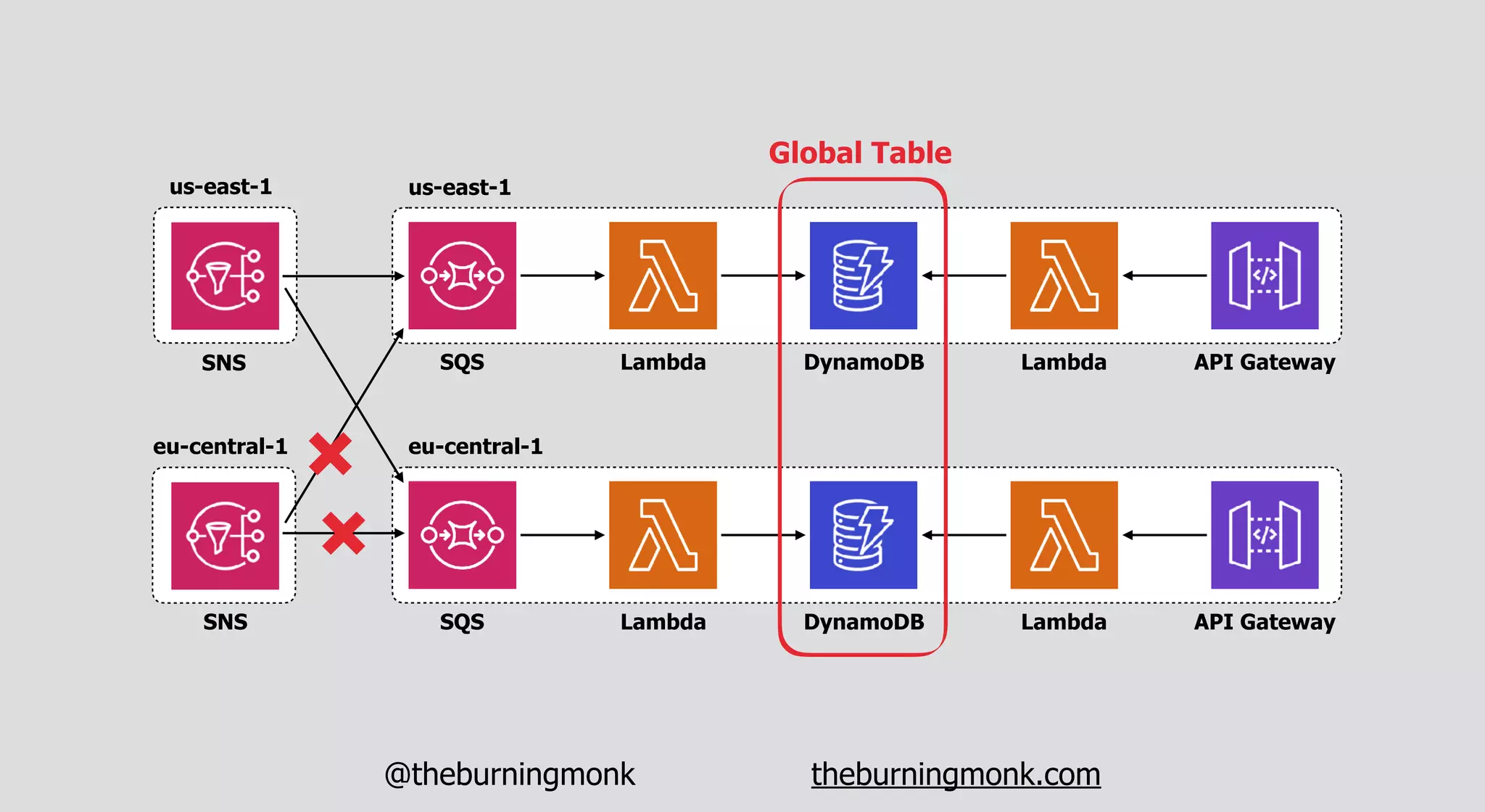
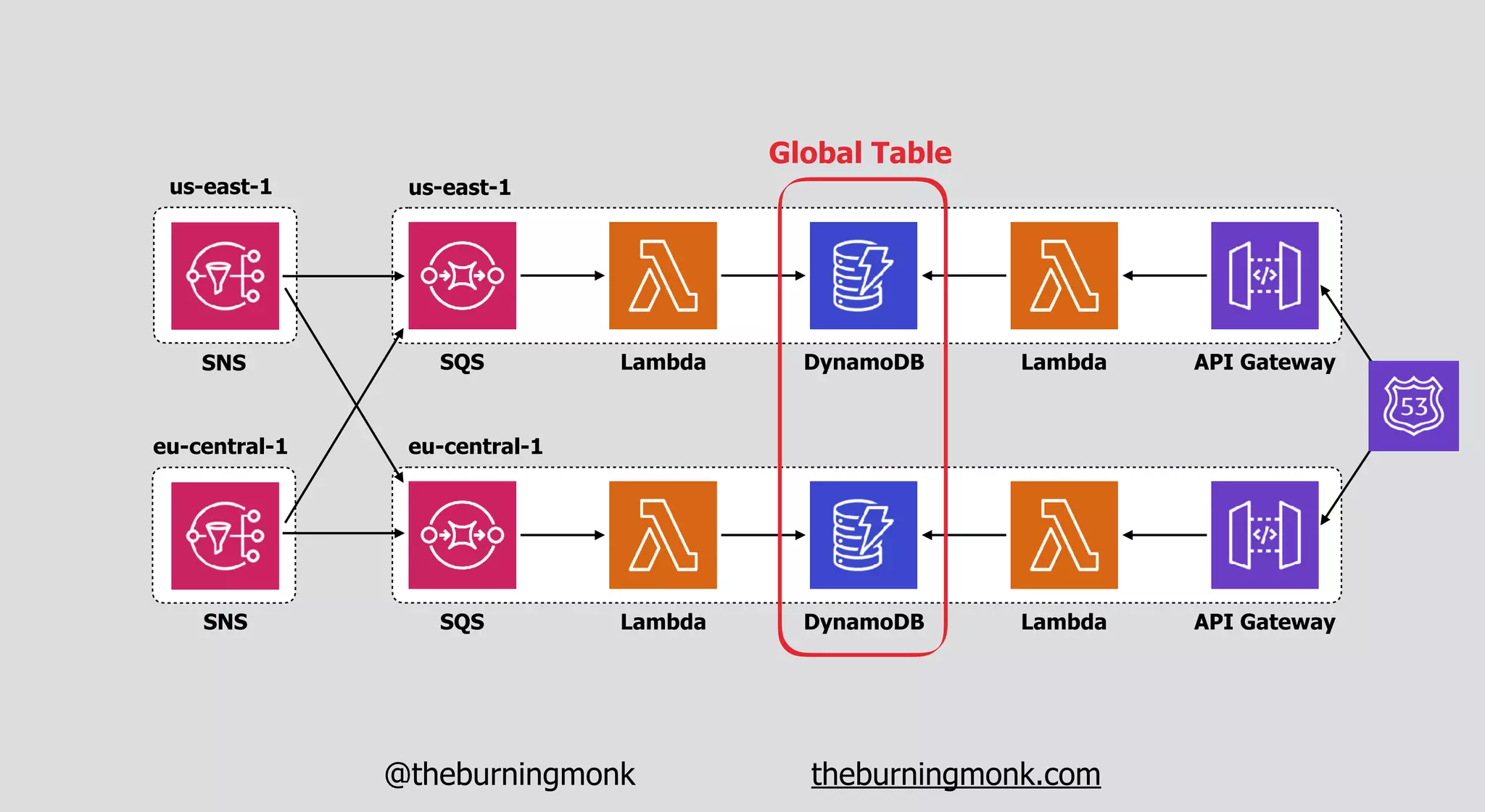
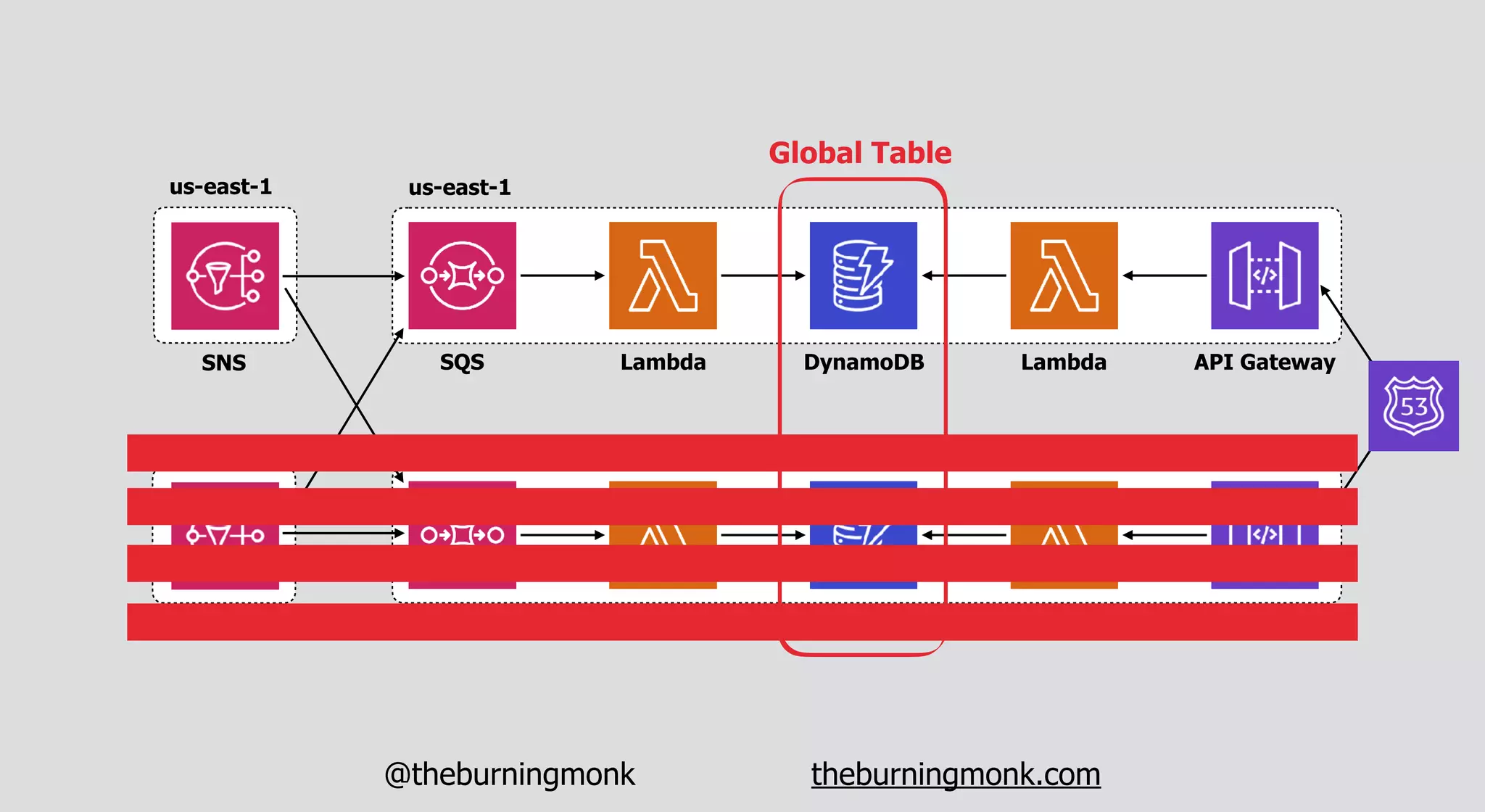





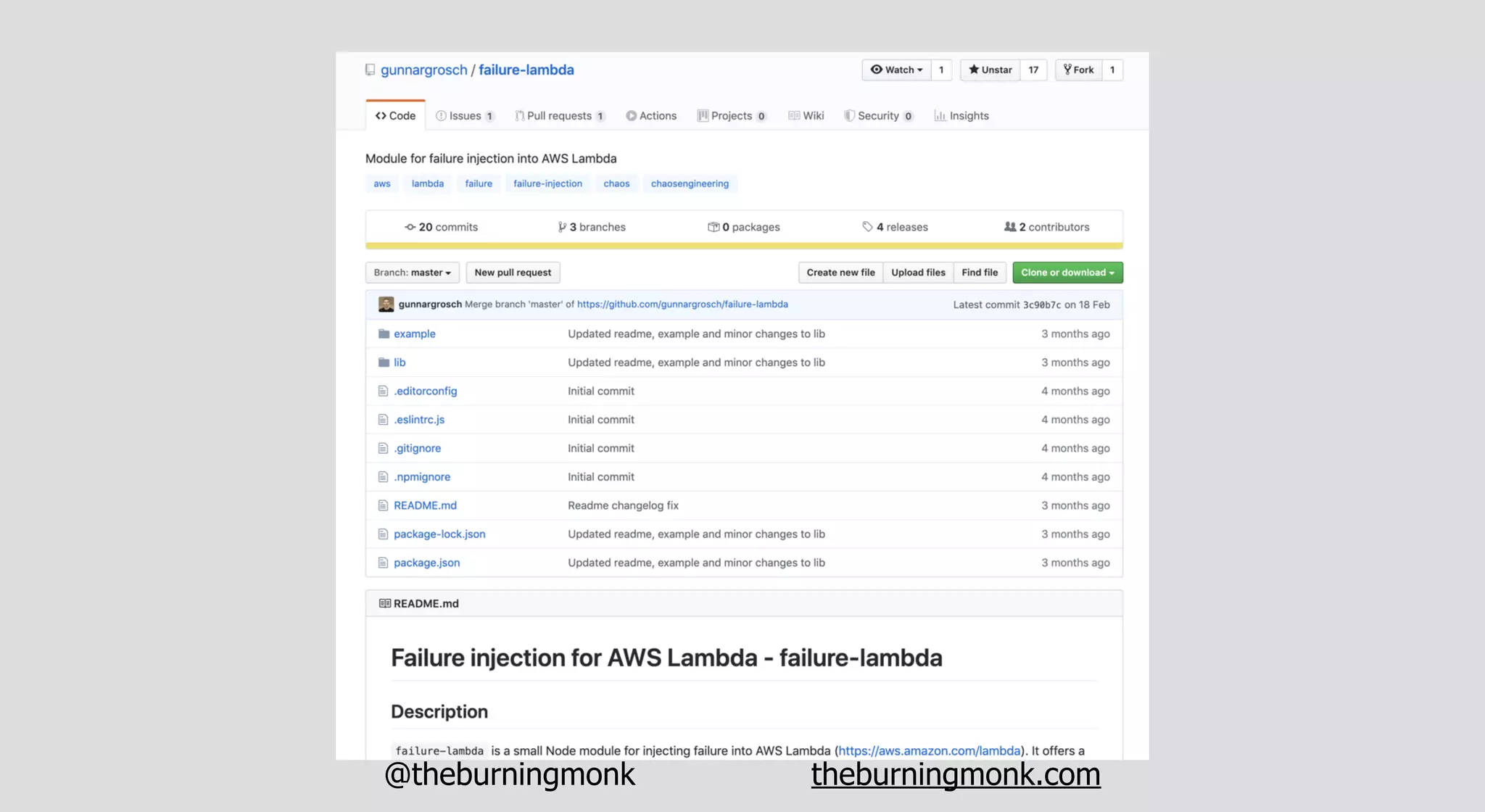









The document outlines patterns and practices for creating resilient serverless applications, emphasizing the importance of designing for failure rather than solely preventing it. Key strategies include utilizing multiple availability zones, employing the saga pattern for distributed transactions, and implementing circuit breaker patterns to manage load and errors. It also highlights the necessity of chaos engineering to prepare systems for unexpected failures and the importance of monitoring and alerting to quickly address issues.


































![[WSO2Con EU 2017] Resilience Patterns with Ballerina](https://cdn.slidesharecdn.com/ss_thumbnails/myteul0aqxm9m9aefn37-signature-25a03a0dd11bea2cb4b5d302614dc9fa369274823e87b86d7bcc419612b27068-poli-171106131830-thumbnail.jpg?width=640&height=640&fit=bounds)






























![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




