Download to read offline






















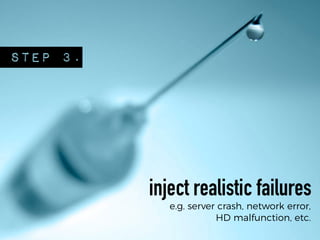
















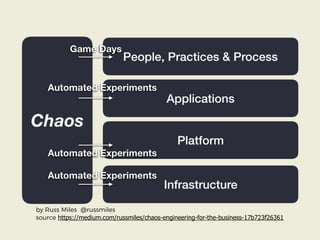







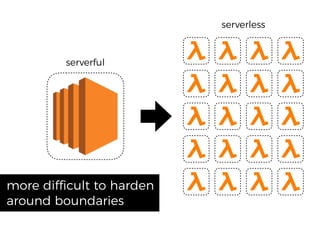
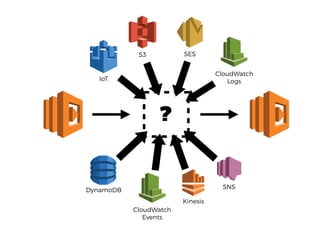
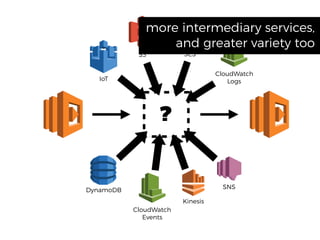
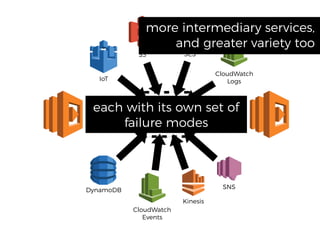
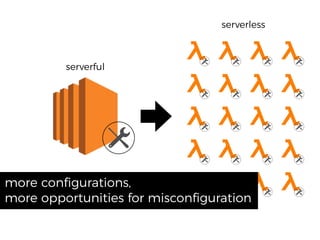


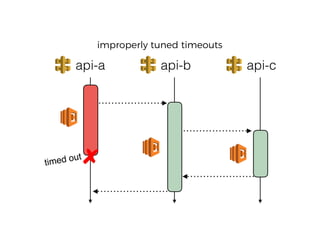
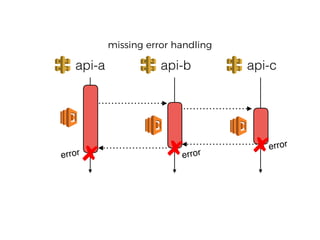
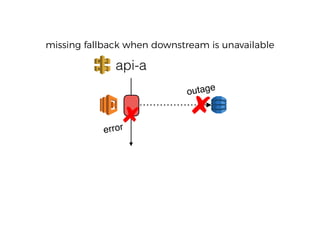

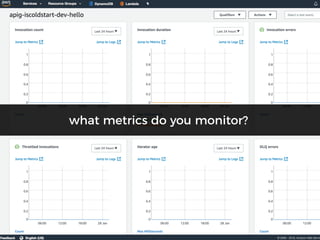



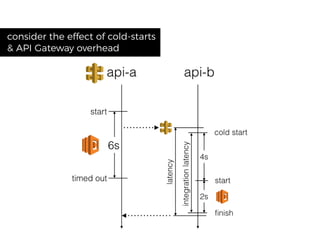






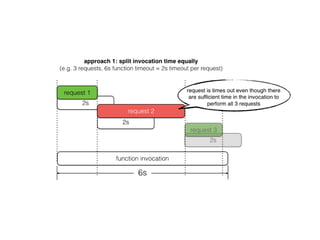
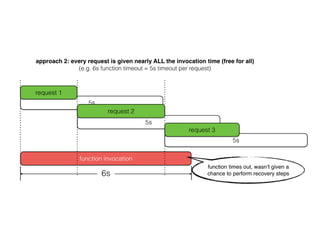

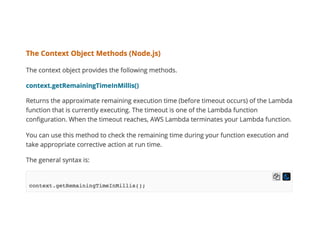
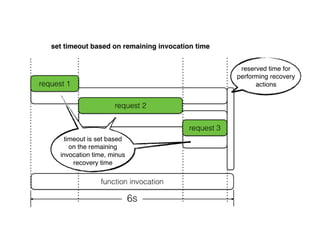
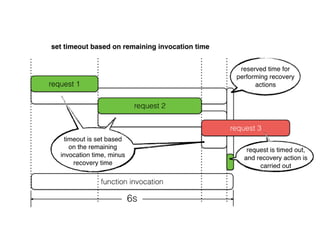


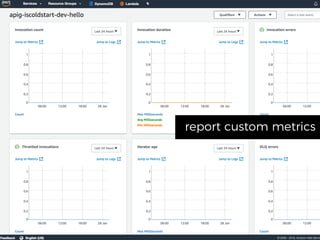
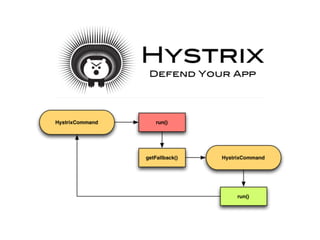

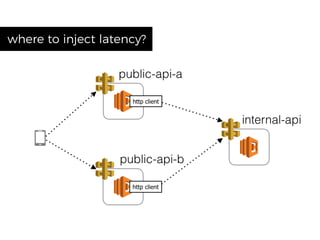

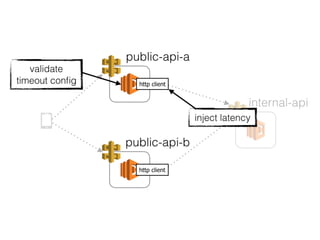

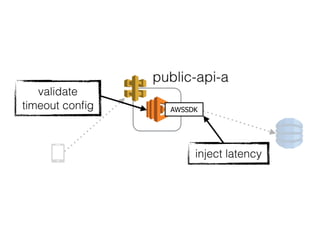

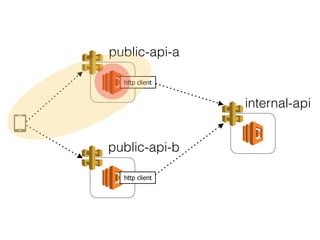

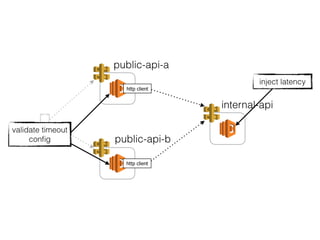
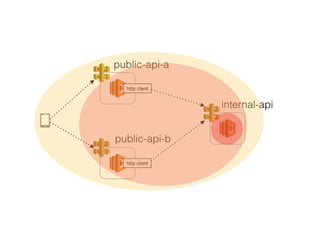







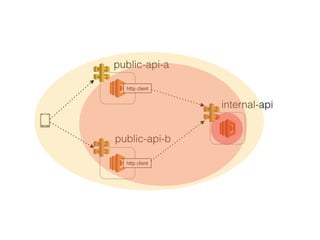


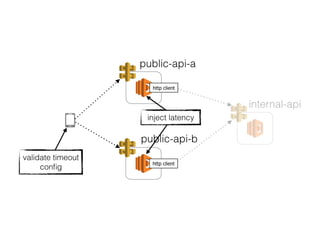
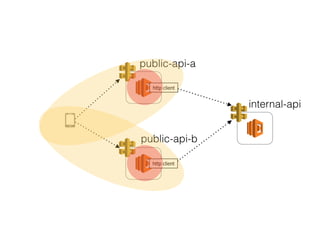

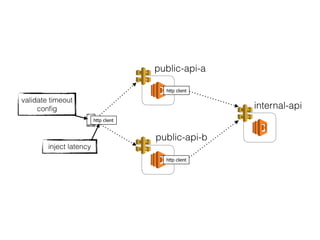





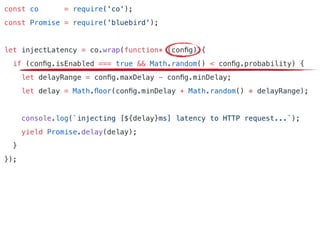
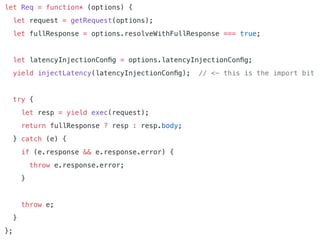
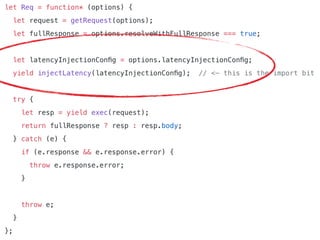
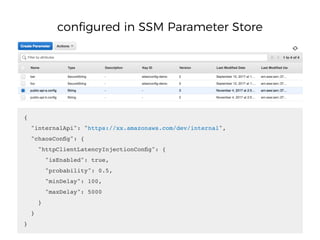

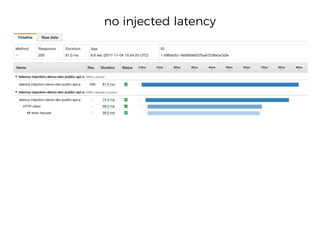
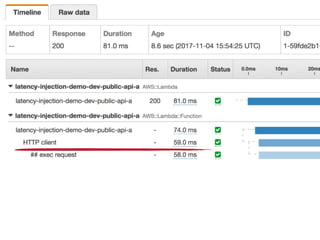
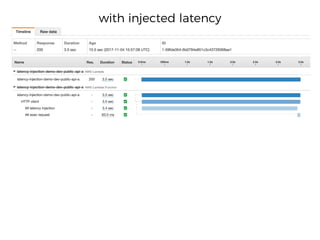
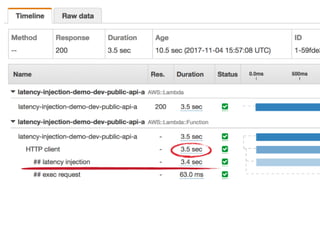

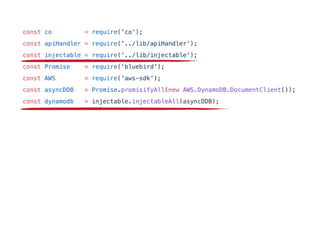

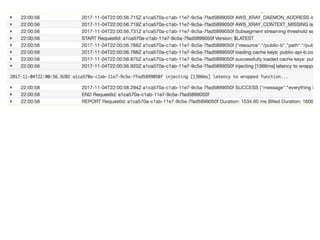
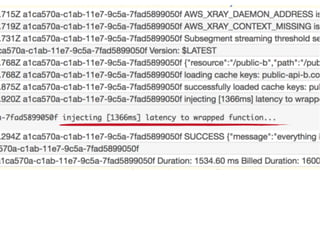










The document discusses chaos engineering principles, particularly in serverless architectures, emphasizing the importance of controlled experiments to enhance system resilience against failures. It outlines a step-by-step approach for conducting these experiments, including defining steady states, hypothesizing outcomes, injecting realistic failures, and analyzing results. Key practices include effective communication, careful timing, and assessing the impacts of various failures to improve system robustness.



































































