Download as PDF, PPTX




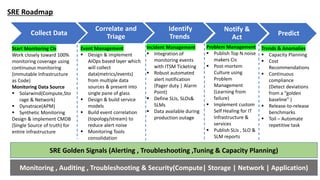
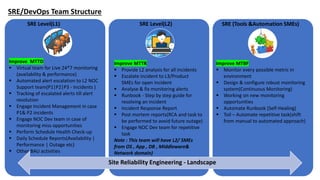
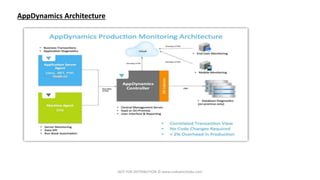
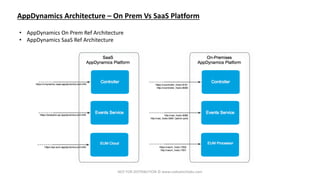




The document outlines a training session for DevOps and Site Reliability Engineering (SRE) focusing on AppDynamics, covering its architecture, installation processes, and troubleshooting techniques. It highlights challenges in traditional Network Operations Centers (NOCs) such as high alert noise and slow incident resolution, and emphasizes the importance of effective monitoring, automation, and problem management to enhance operational efficiency. The training includes hands-on practice and a walkthrough of AppDynamics features aimed at improving application performance monitoring and incident management.



































































