Download to read offline





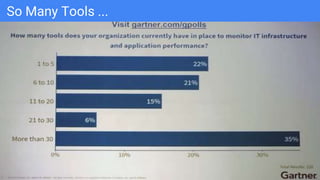







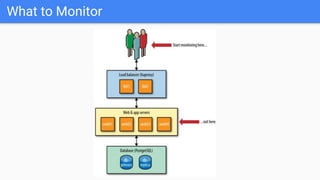
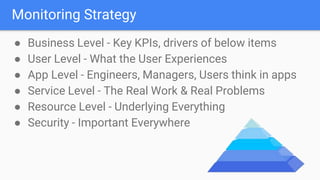










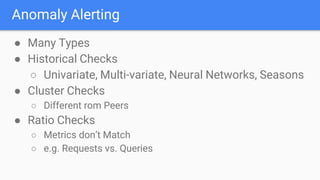









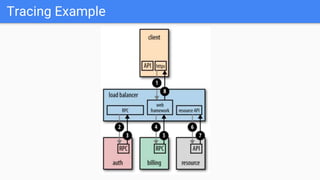














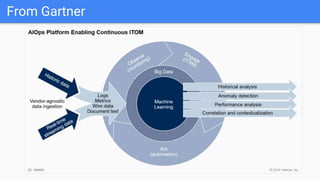



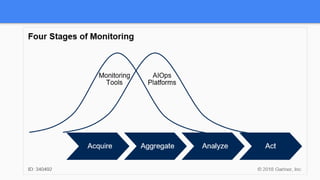







The document outlines the current state of IT operations, highlighting the challenges of diverse systems, numerous monitoring tools, and the complexity of modern environments such as cloud and microservices. It emphasizes the need for integrated monitoring solutions that provide a single source of truth and enable context-rich data collection, along with strategies for automated operations and AI-driven insights. The document discusses the rethinking of monitoring practices, including what to monitor, how to alert, and incident management to improve operational efficiency.















































