Download as PDF, PPTX


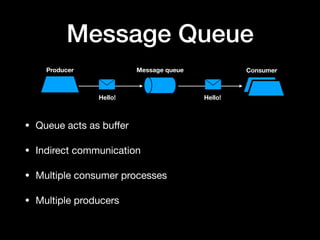
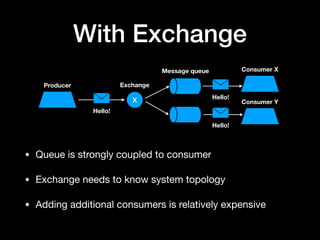
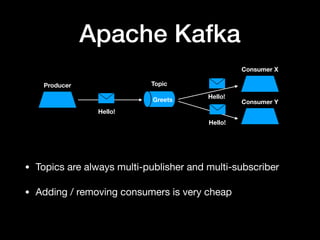

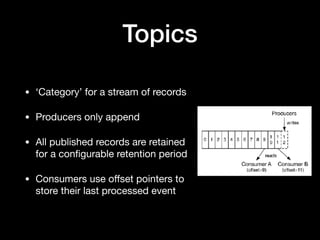

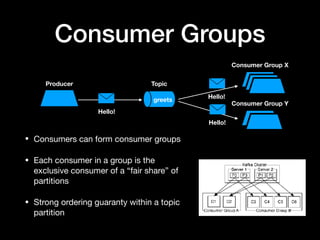


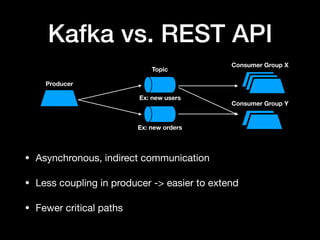
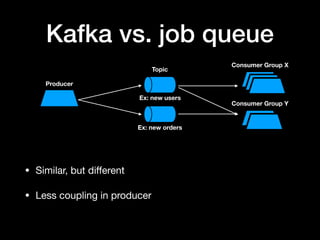








The document discusses the use of Apache Kafka as a message queue for microservices, highlighting its features like multi-publisher and multi-subscriber topics, and fault-tolerant stream storage. It contrasts Kafka with REST APIs and job queues, emphasizing benefits such as reduced coupling and easier scalability. The document also addresses challenges with using Kafka, including asynchronicity, error handling, and event loops, while providing practical tips for effective integration.



























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







