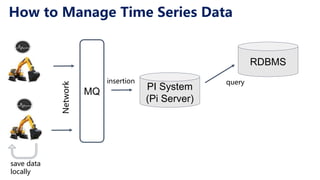
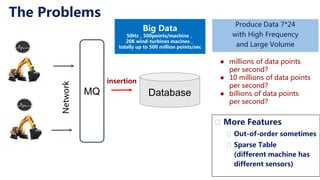
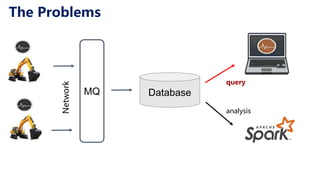
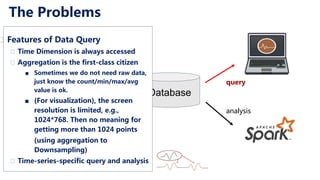
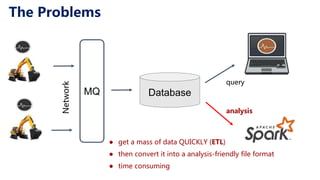
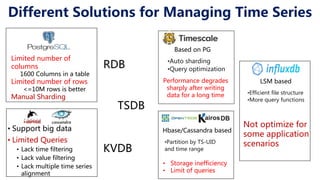
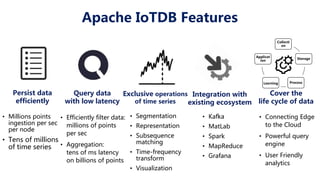
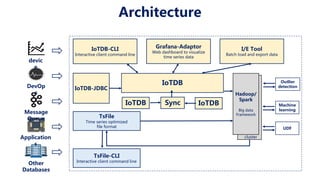
This document discusses Apache IoTDB, an open source time series database for industrial IoT applications. It describes the origins and goals of IoTDB in managing the large volumes of time-oriented machine data produced by IoT devices. Key features of IoTDB include efficient storage and querying of time series data, native support for time series operations, and integration with common data analytics ecosystems. The document outlines IoTDB's architecture, data model, query language, optimized TsFile data format, and encoding schemes.


















![Set time series group
SET STORAGE GROUP TO root.laptop.d1.s1;
Create Timeseries
CREATE TIMESERIES root.laptop.d1.s1 WITH DATATYPE=INT32, ENCODING=RLE
Insert Data
INSERT INTO (d1.s1,d1.s2,time) VALUES (1000,2000,14735235234);
Delete Data
DALETE FROM d1.s1 WHERE time < 1000;
Update Data
UPDATE d1.s1 SET VALUE = 2000 WHERE time < 2000 and time > 1000;
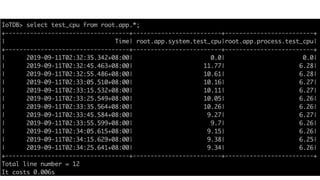
Query Data (Filter, Aggregation, Group by time interval)
SELECT d1.s1,d2.* FROM BJ.WF1 WHERE d1.s1 < 2000 and d2.s2 > 1000 and freq(d2.s3) > 0.5;
SELECT count(status), max_value(temperature) from root.ln.wf01.wt01;
SELECT count(status) ) from root.ln.wf01.wt01 group by(1h, [2017-11-03T00:00:00, 2017-11-
03T23:00:00]);
SQL in IoTDB](https://image.slidesharecdn.com/iotdb-english-apacheconeu2019-191031045422/85/Apache-IOTDB-a-Time-Series-Database-for-Industrial-IoT-27-320.jpg)






























































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)





