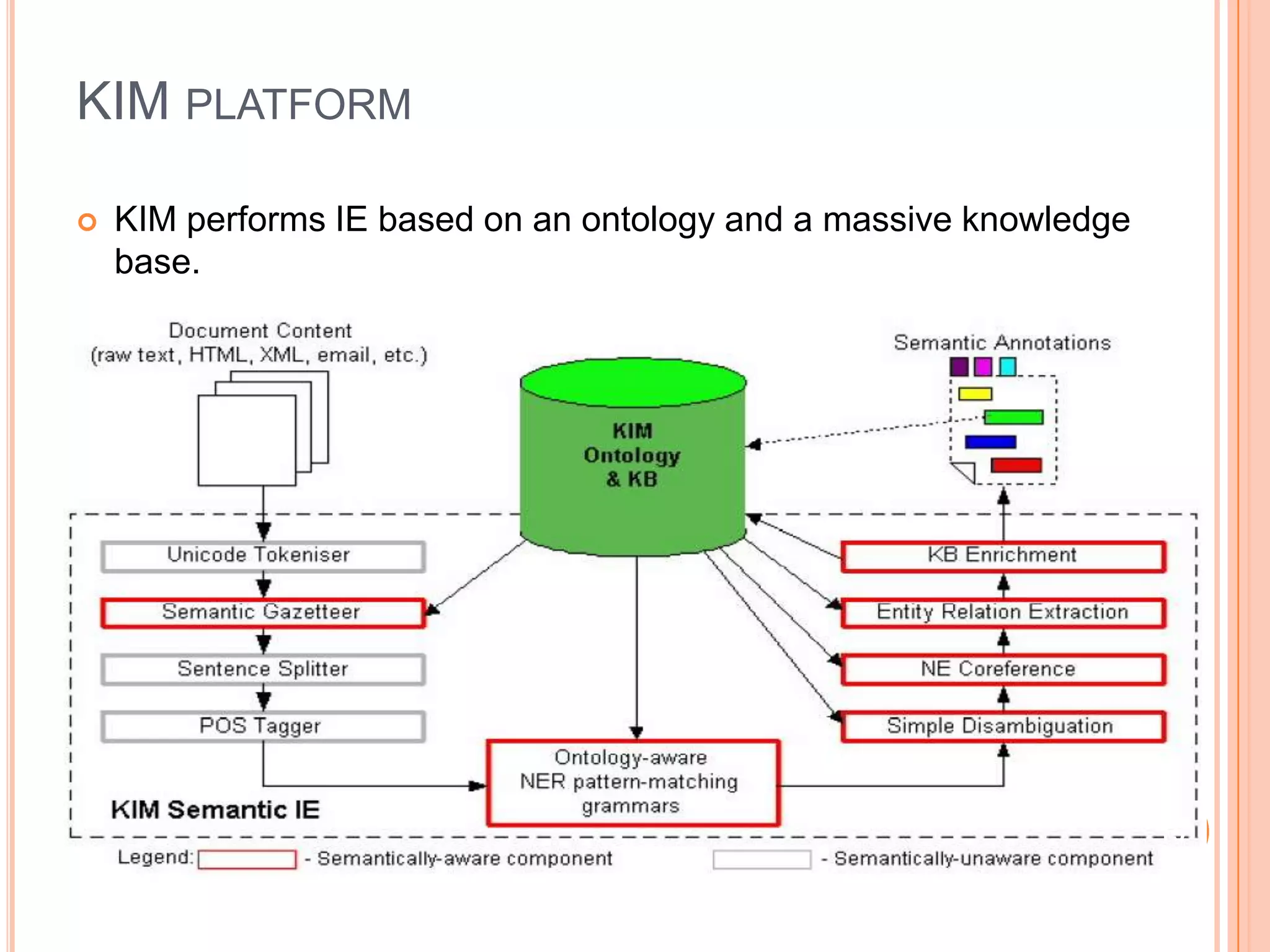
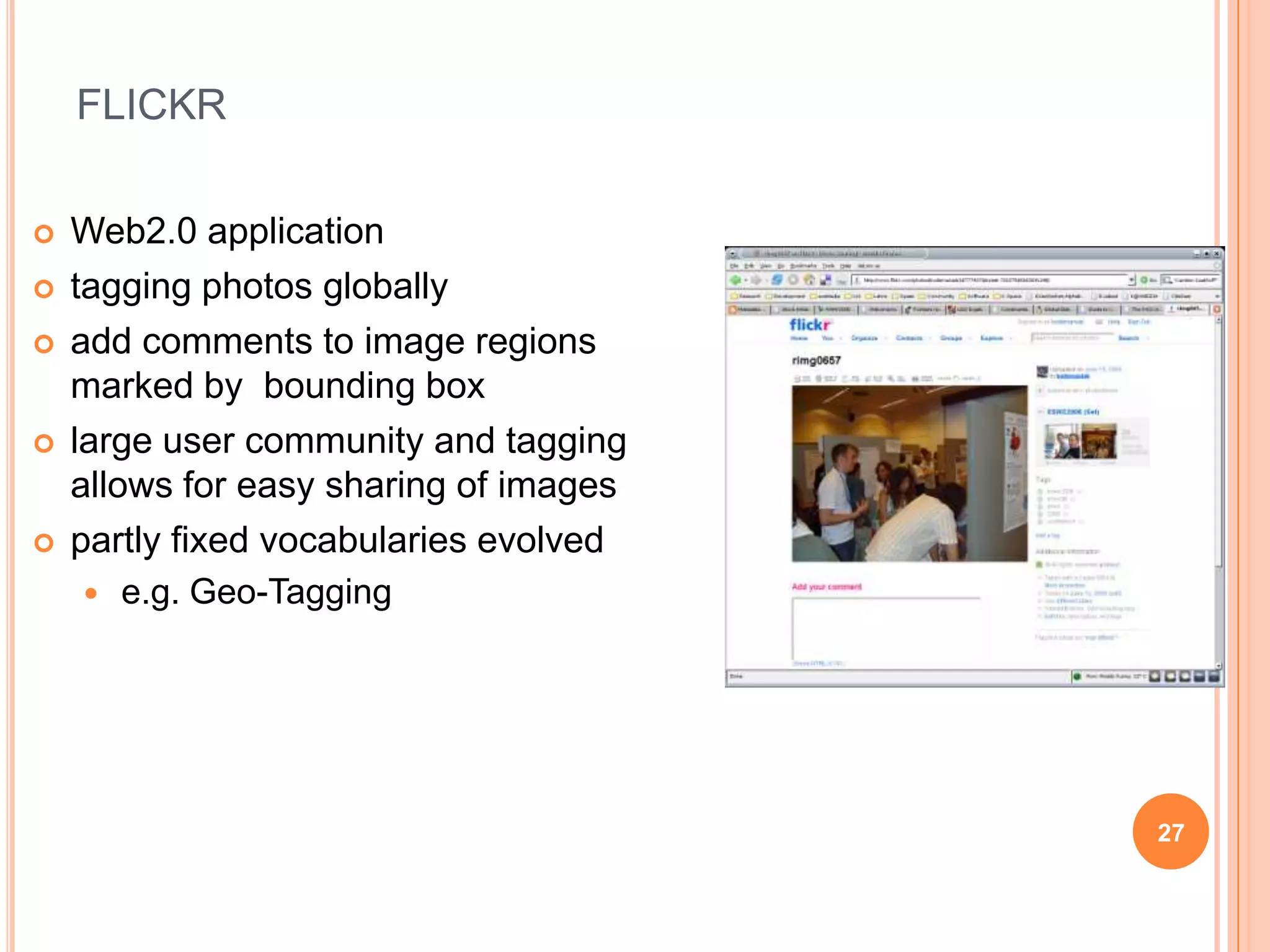
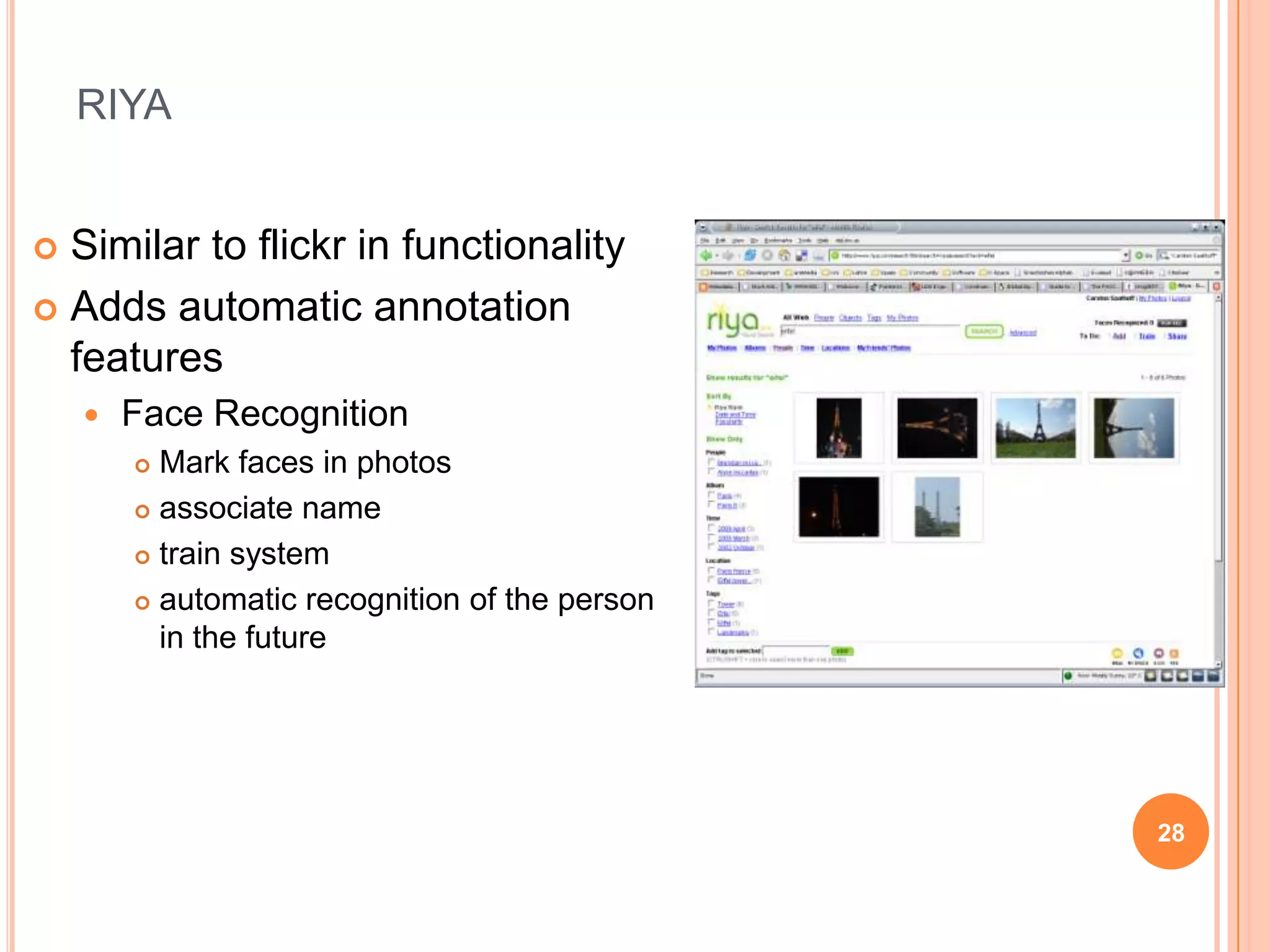
This document discusses semantic web annotation technologies. It defines annotations as metadata that can be attached to web documents to provide additional information without editing the original document. It describes several annotation methods, including manual annotation, semi-automatic annotation using tools like GATE and KIM, and fully automatic annotation. It also discusses annotation at different levels, including metadata, content-level semantic annotations, and multimedia annotations of visual features. Tools for annotation discussed include Flickr, Riya, GATE, and KIM.