Downloaded 11 times
















![Experimental results
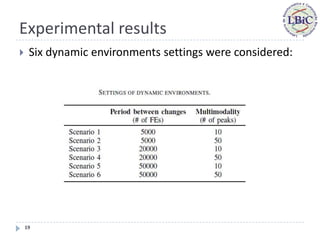
Moving Peaks benchmark (MPB) generator plus a rotation method
(Li & Yang, 2008);
Fitness surface are composed by a set of peaks that changes your
positions, heights and widths over time;
Maximization problem in a continuous space;
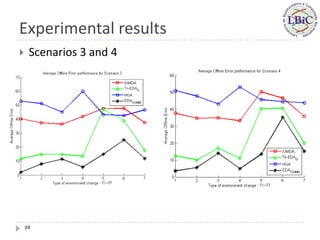
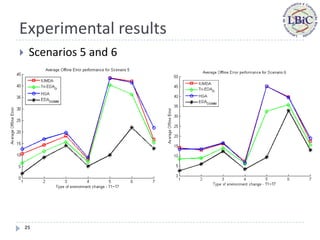
Seven types of change (T1-T7): small step, large step, random,
chaotic, recurrent, recurrent with noise and random with
dimensional changes;
There are parameters to control the multimodality of the search
space, severity of changes and the dynamism of the environment;
Range of search space: [-5,5];
Problem dimensions: 10 and [5-15].
18](https://image.slidesharecdn.com/andrecec2011-120824112441-phpapp02/85/Online-learning-in-estimation-of-distribution-algorithms-for-dynamic-environments-18-320.jpg)



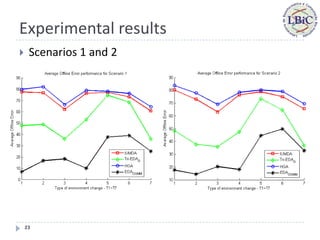







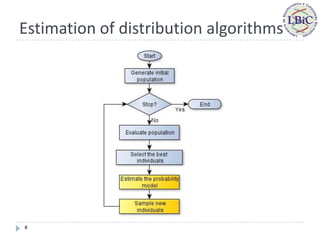
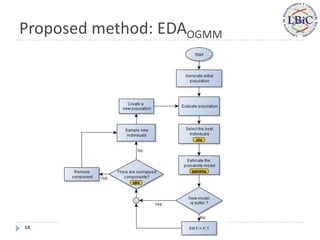
This document proposes a new estimation of distribution algorithm called EDAOGMM that uses an online Gaussian mixture model to optimize problems in dynamic environments. EDAOGMM adapts its internal model through online learning as the environment changes. It was tested on benchmark dynamic optimization problems and outperformed other state-of-the-art algorithms, especially in high-frequency changing environments. Future work includes improving EDAOGMM's ability to avoid premature convergence and further experimental testing.
























































