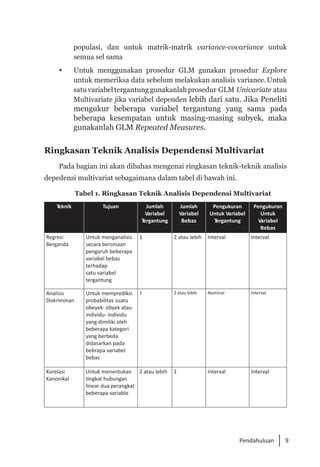
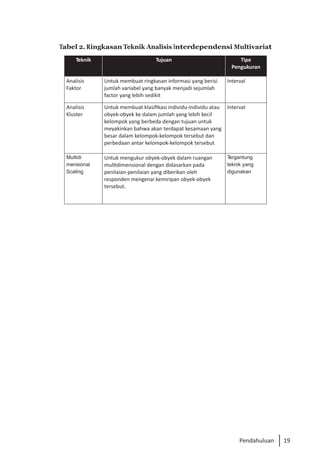
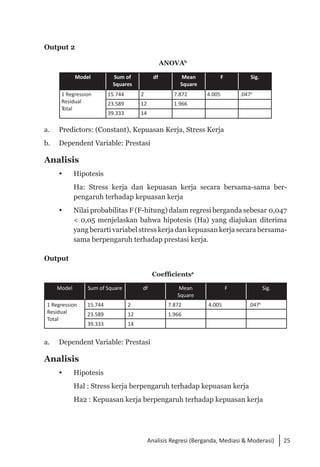
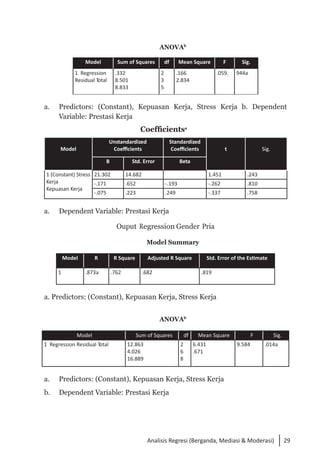
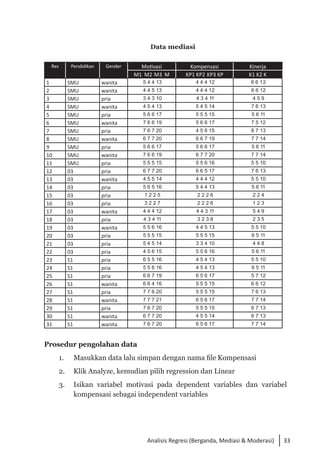
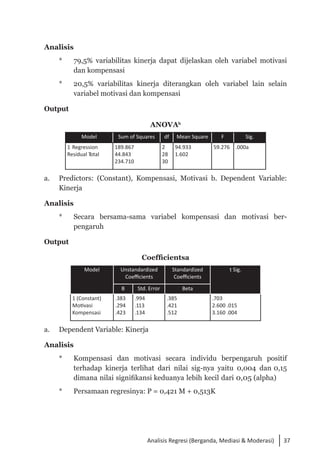
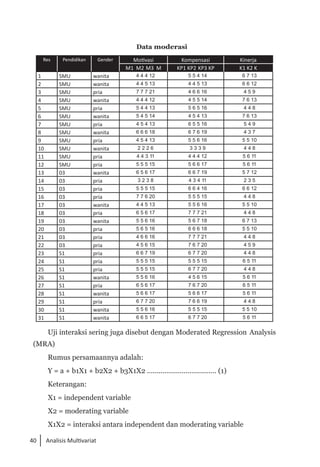
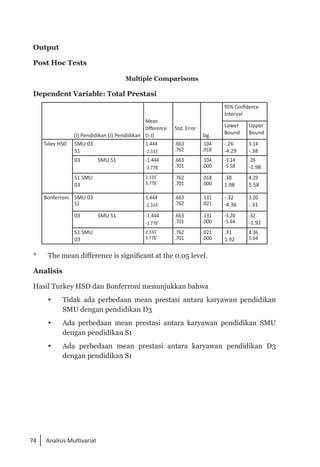
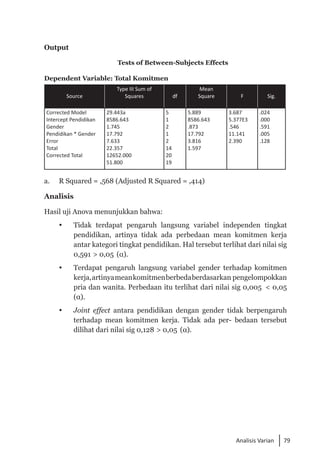
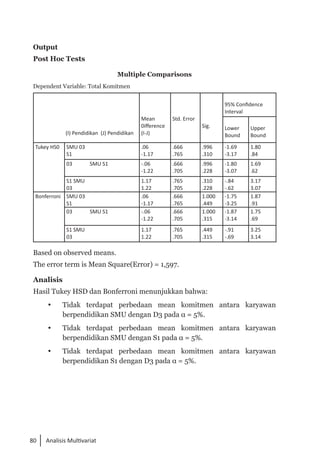
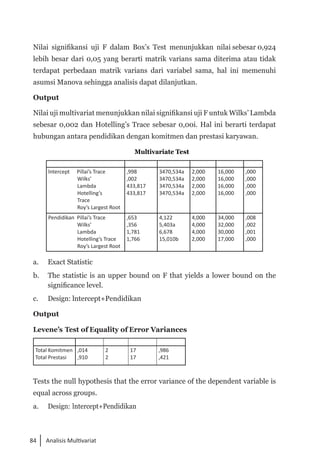
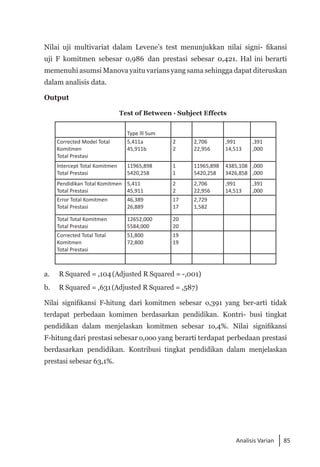
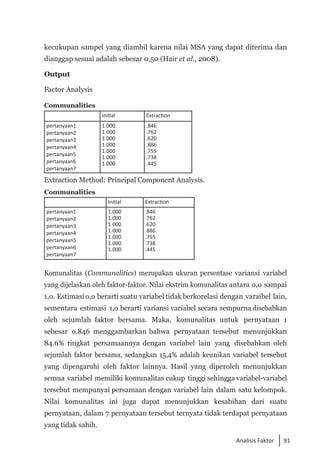
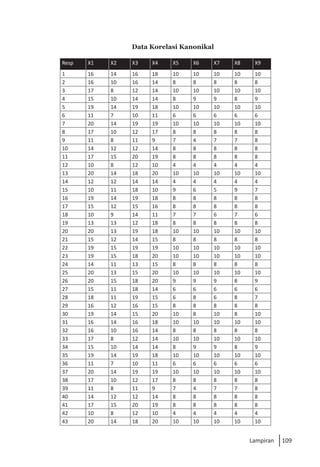
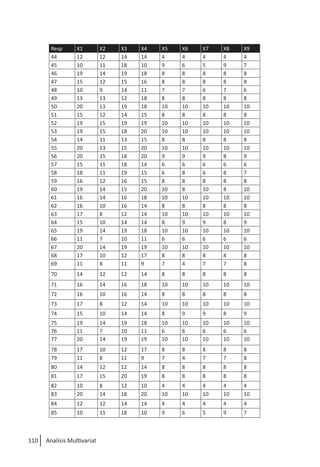
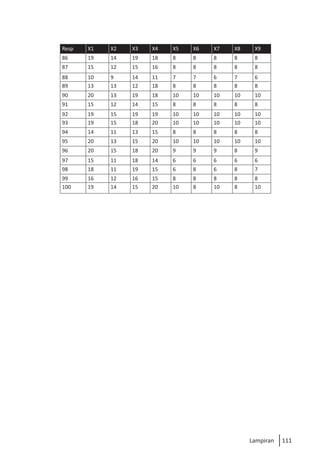
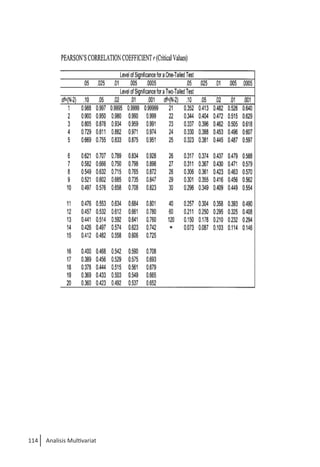
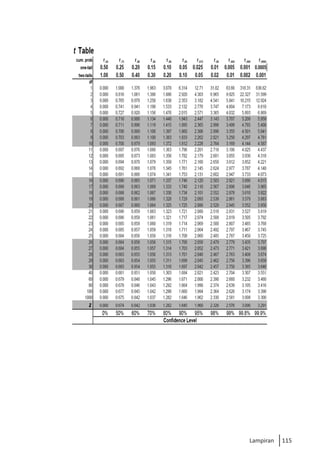
Buku ini membahas analisis multivariat dalam penelitian manajemen, mengajarkan pemahaman dan aplikasi teknik analisis data multivariat menggunakan SPSS. Teknik-teknik yang dibahas termasuk analisis regresi, diskriminan, korelasi kanonikal, dan analisis faktor, yang dirancang untuk menangani masalah penelitian kompleks dengan banyak variabel. Penulis berharap buku ini bermanfaat bagi kalangan akademis dan praktisi, meskipun juga mencatat adanya kekurangan yang bisa diperbaiki.