Download to read offline







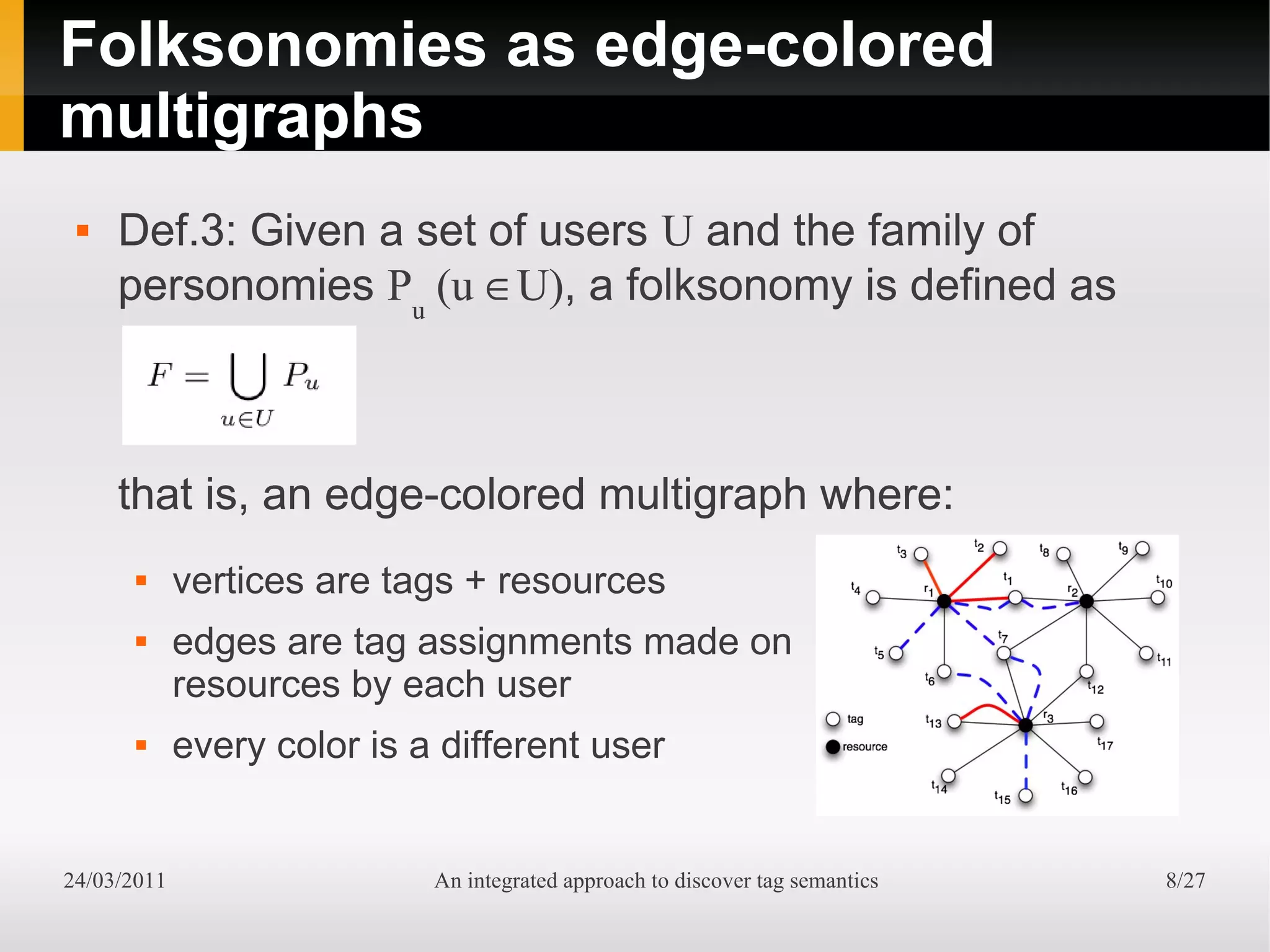
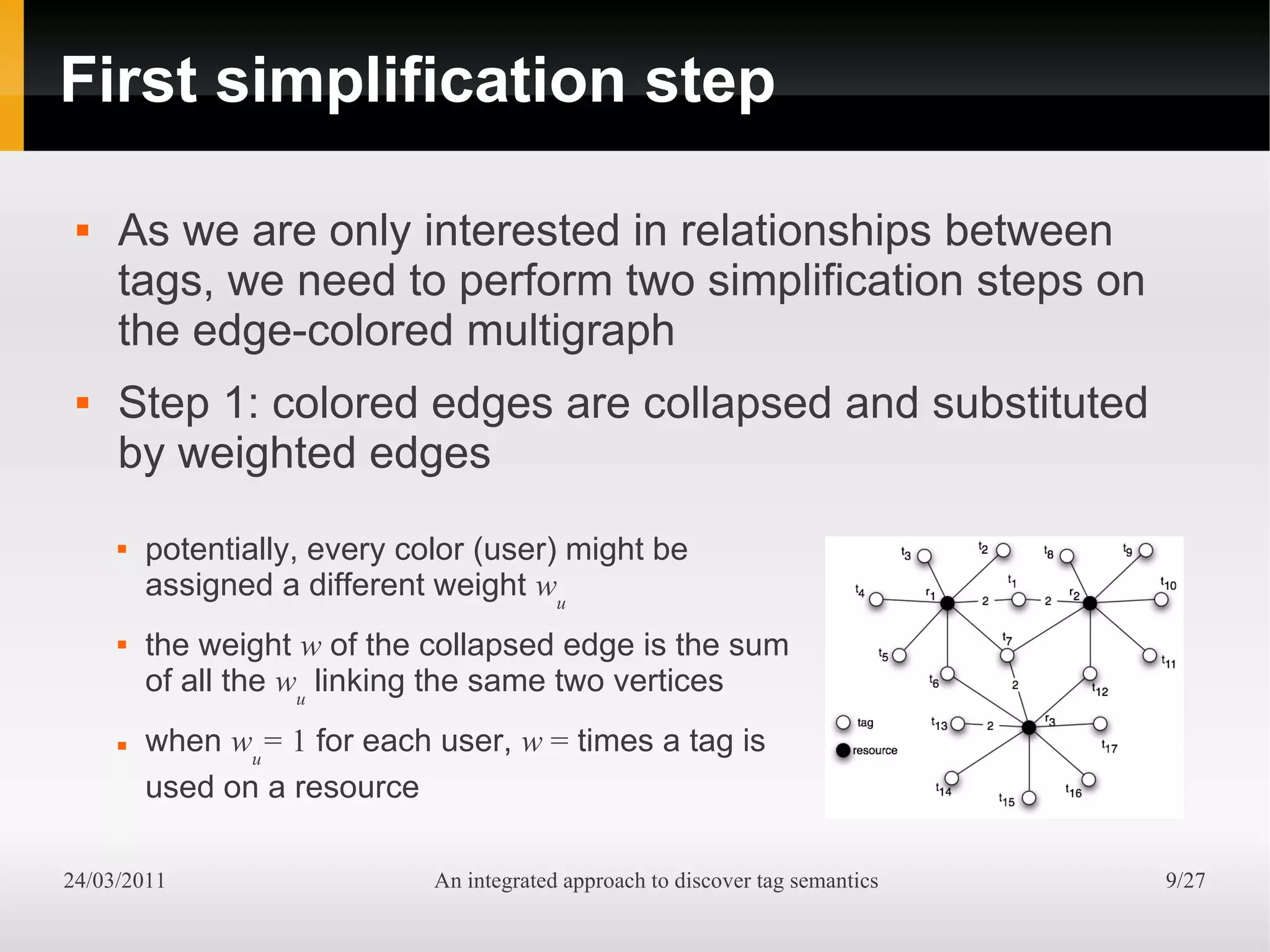
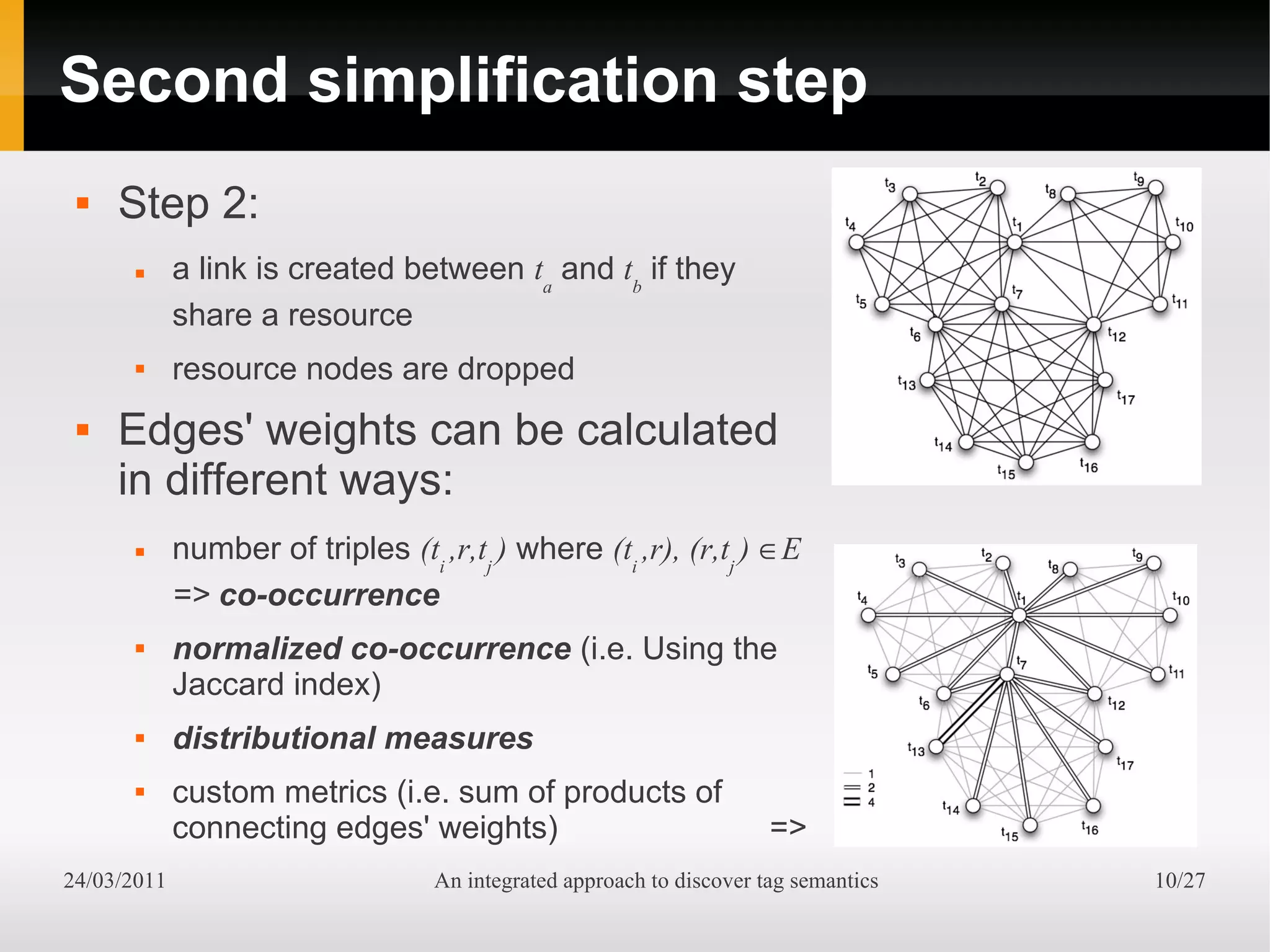
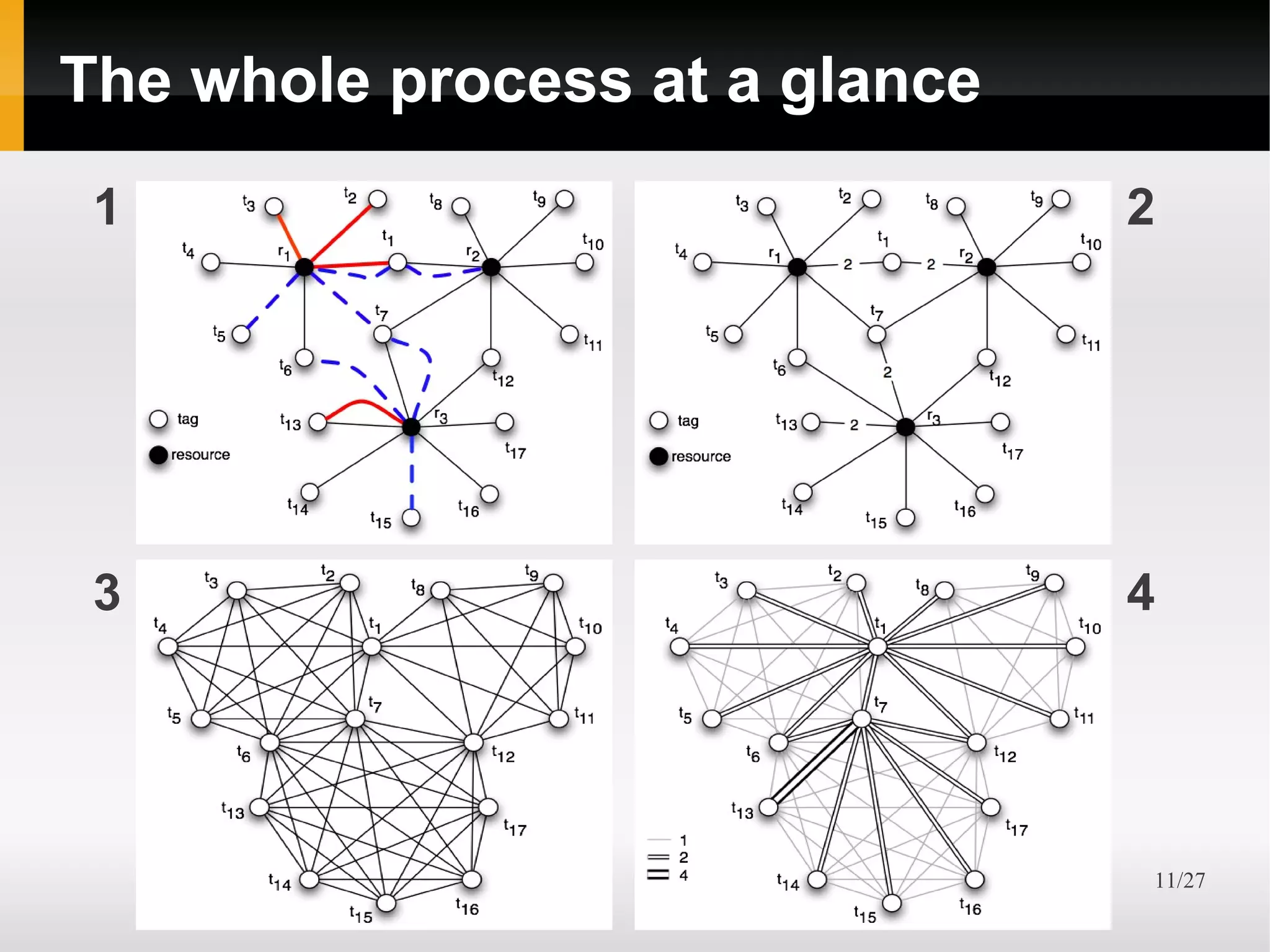
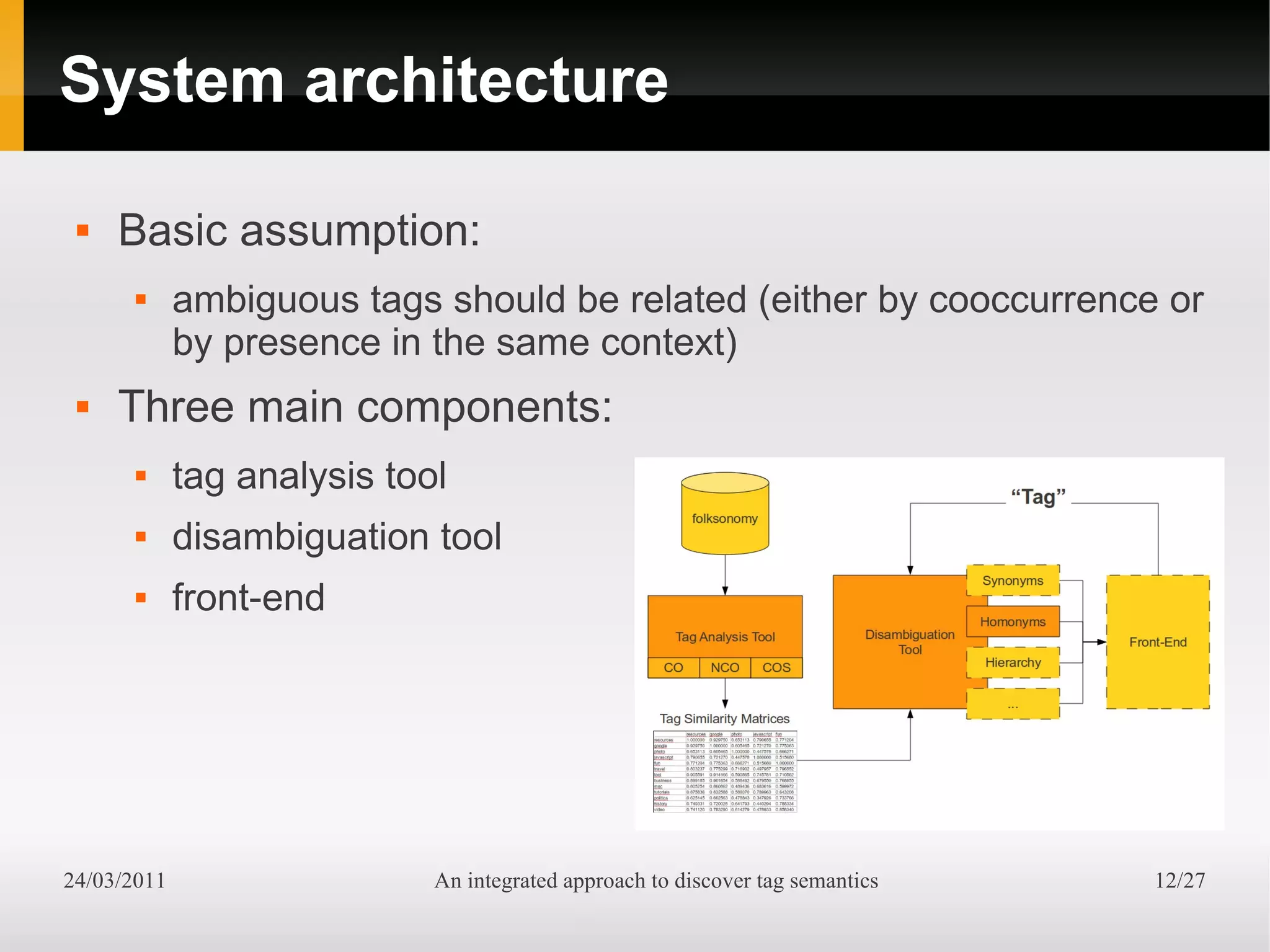






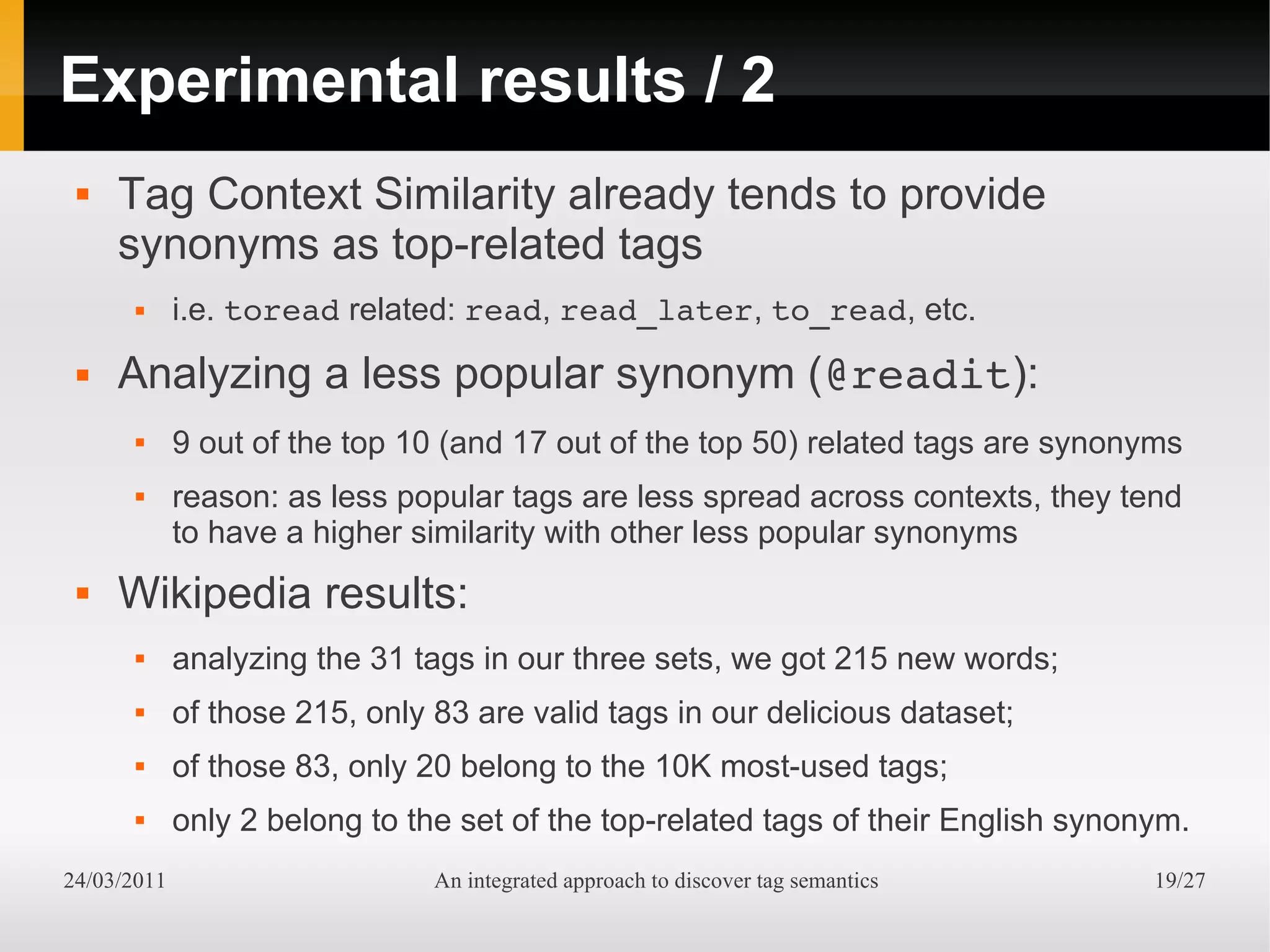





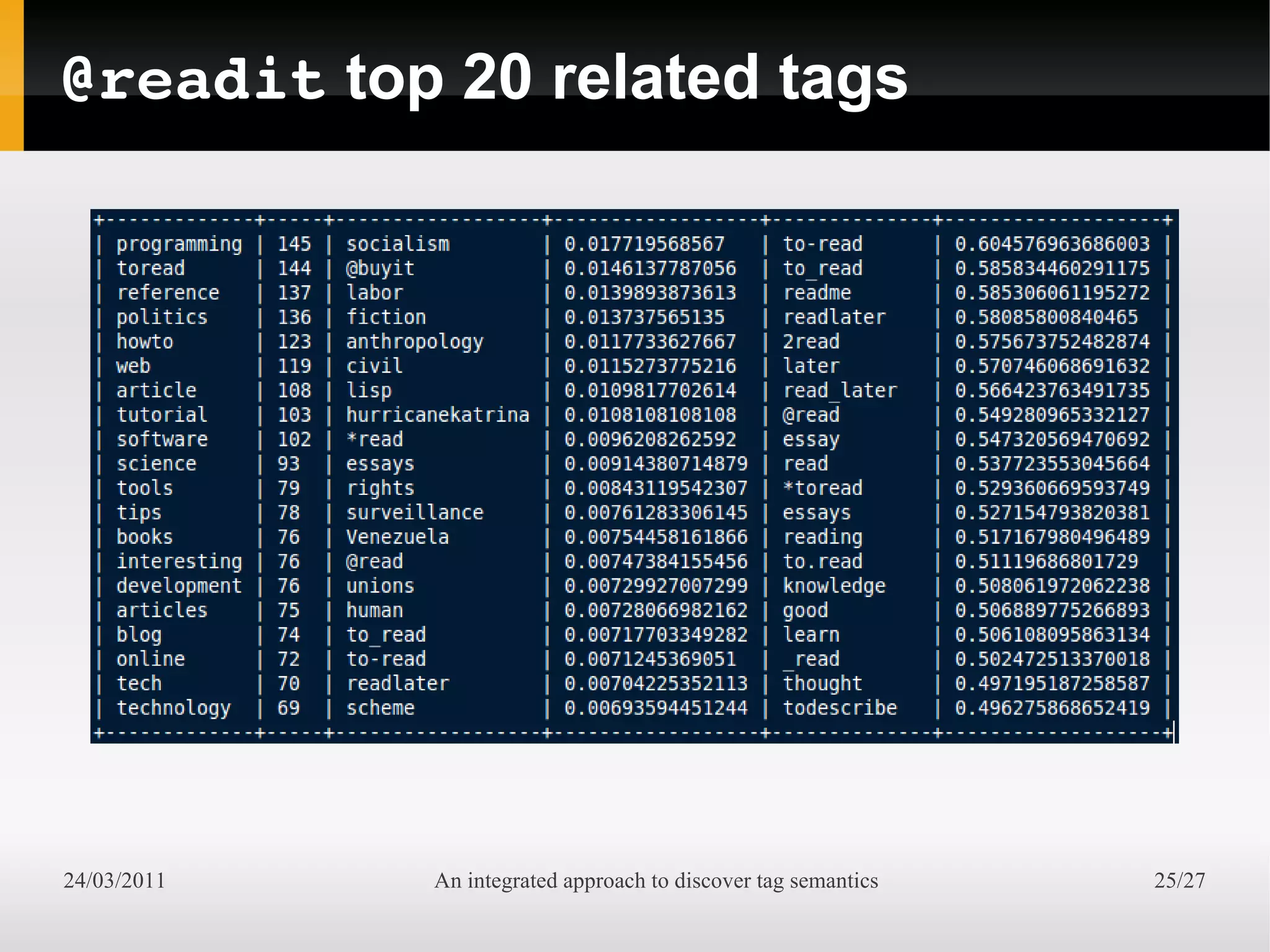



The document presents an integrated approach to understand tag semantics by addressing lexical ambiguities in folksonomies through a theoretical framework and a modular analysis tool. It explores properties of tags, offers methods for disambiguation, and discusses a prototype developed from user data. The results indicate that various metrics can provide meaningful insights into synonym and homonym detection in tagging systems.






























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)


















