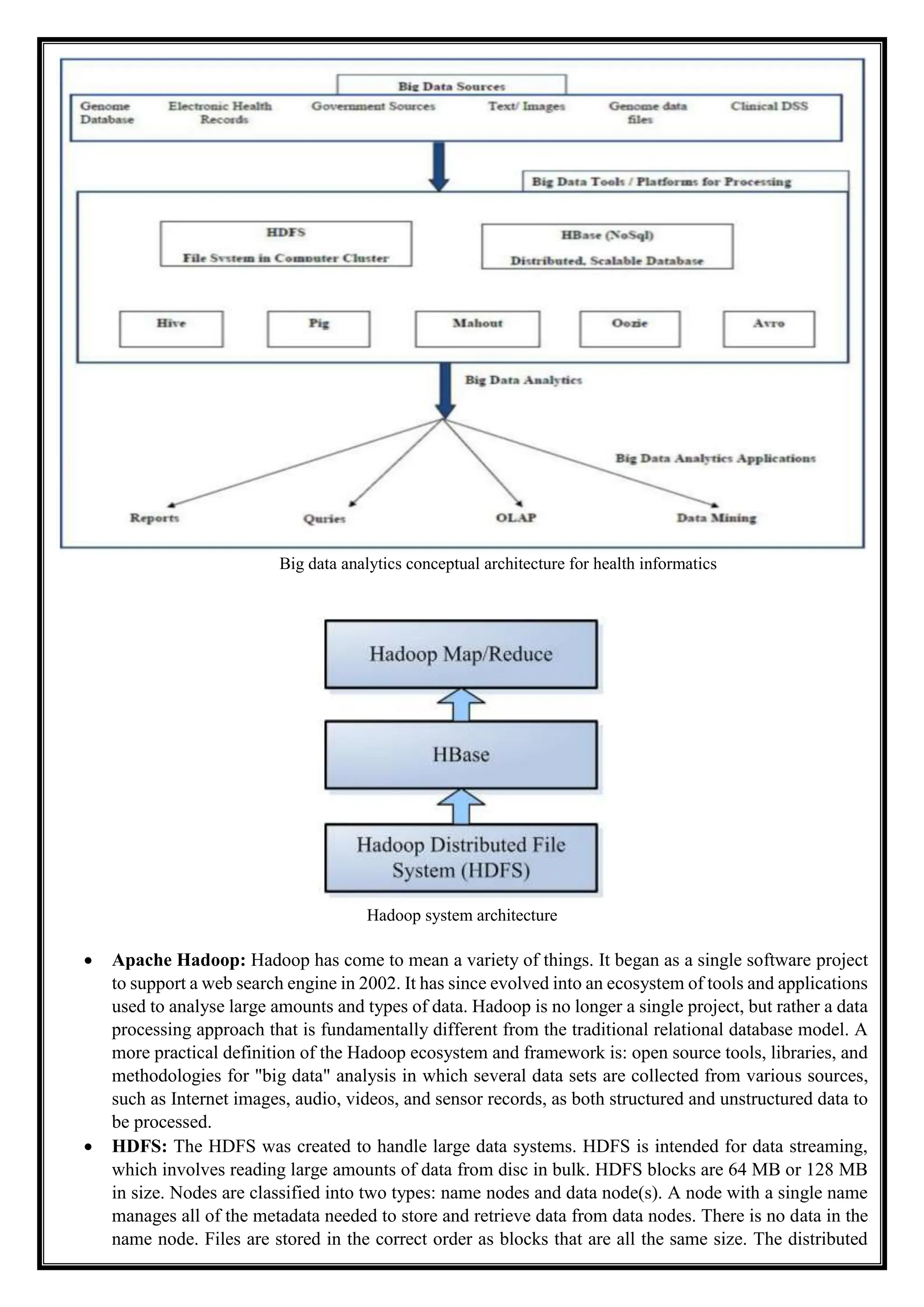
This document discusses big data analytics for the healthcare industry. It describes how big data is being generated at an alarming rate in healthcare for purposes like patient care and regulatory compliance. The four V's of big data - volume, velocity, variety and veracity - are discussed. The document outlines how big data analytics can improve patient outcomes through pathways like right living, right care, right provider, right innovation and right value. Hadoop applications that can help the healthcare sector manage and analyze large amounts of unstructured data are also presented.