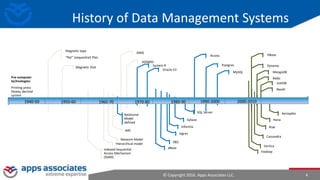
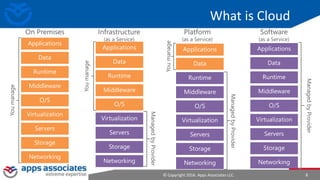
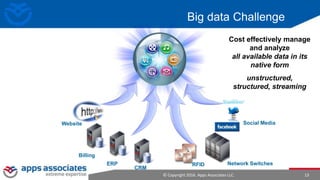
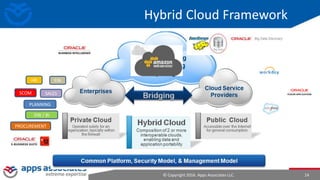
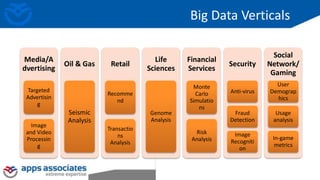
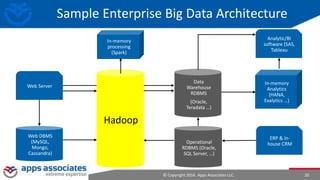
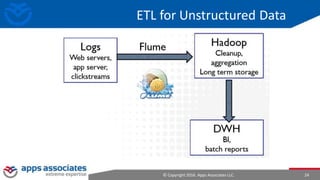
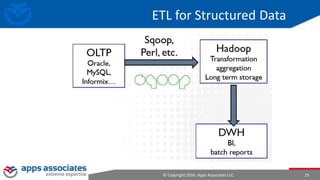
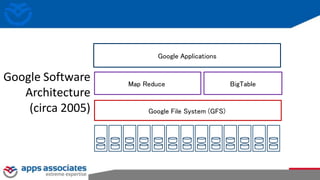
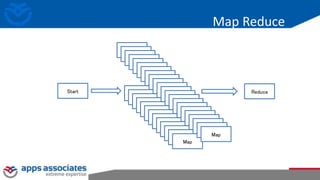
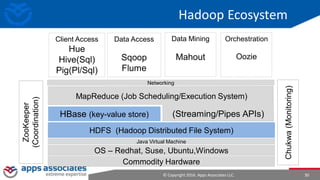
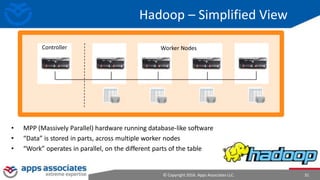
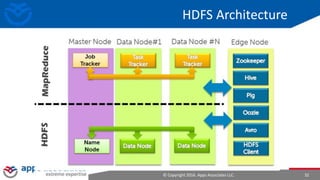
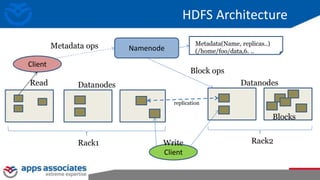
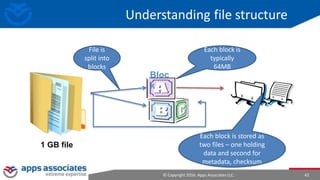
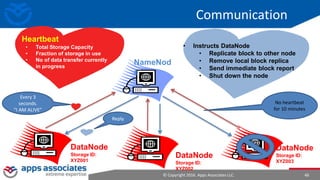
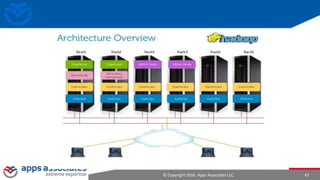
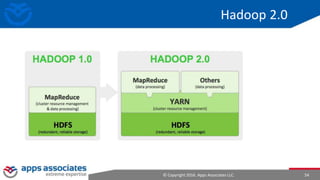
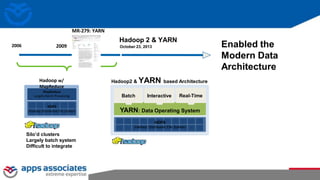
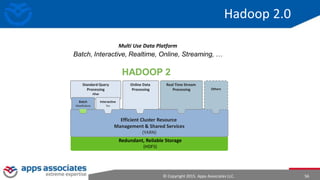
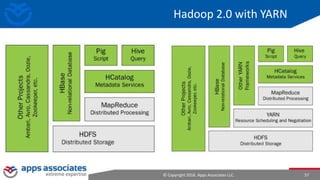
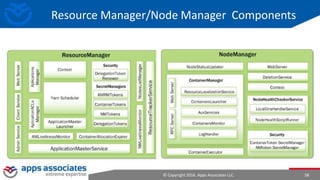
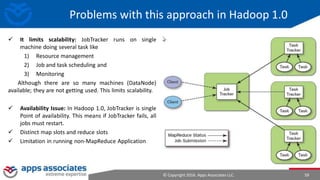
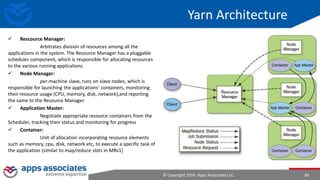
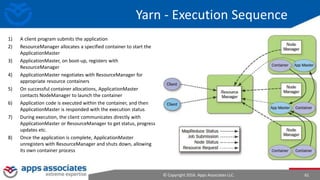
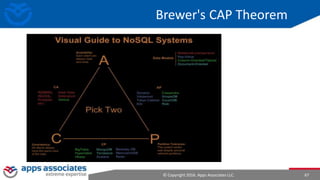
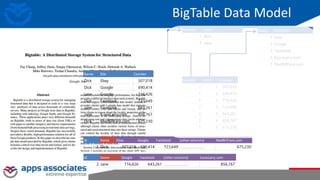
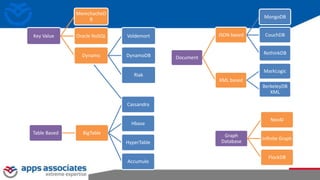
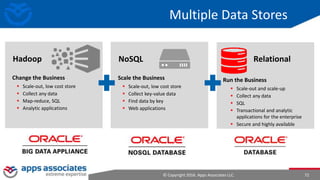
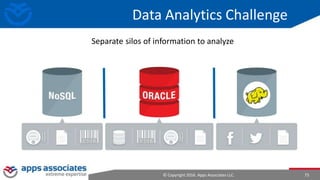
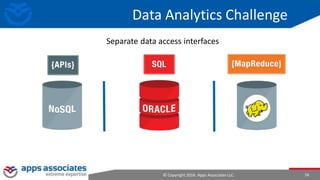
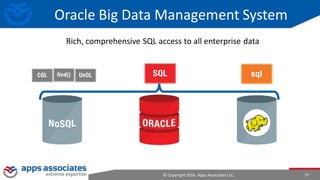
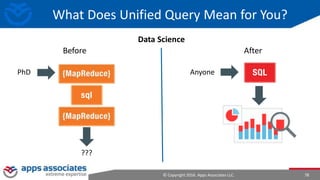
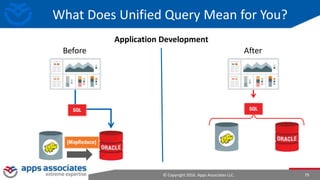
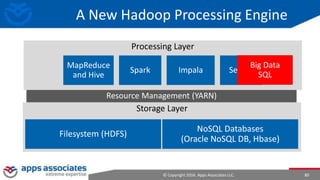
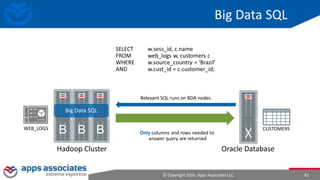
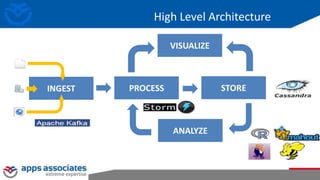
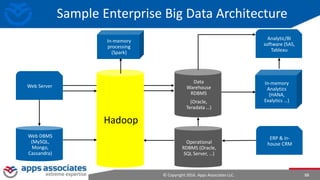
The document provides an overview of big data and Hadoop for database administrators. It discusses the history of data management systems and how the role of data is changing to focus on collecting as much data as possible. The key characteristics of big data, including volume, velocity, and variety, are outlined. An overview of the Hadoop ecosystem is provided, including components like HDFS, MapReduce, Hive, Pig, and HBase. Sample use cases and architectures for big data are also summarized.