Expert Systems
Definition:
AnES is a set of programs that manipulate encoded
knowledge to solve problems in a specialized domain that
normally requires human expertise.
The expert systems are the computer applications
developed to solve complex problems in a particular
domain, at the level of extra-ordinary human intelligence
and expertise.
3.
Characteristic Features ofan Expert System:
High level Performance: The expert system provides high performance for solving any type of
complex problem of a specific domain with high efficiency and accuracy.
Understandable: It responds in a way that can be easily understandable by the user. It can take input in
human language and provides output in same way.
Reliable: It is much reliable for generating an efficient and accurate output.
Highly responsive: ES provides the results for any complex query within a very shortest period of time.
Special programming language: ES are typically within special programming languages. The use of
languages like LISP, PROCOLs in the development of ES simplifies the coding process.
Use symbolic representation: ES use symbolic representation for knowledge and perform their
inference through symbolic computations.
4.
Capabilities of ExpertSystems
Advising
Instructing and assisting human in decision
making
Demonstrating
Deriving a solution
Diagnosing
Explaining
Interpreting input
Predicting results
Justifying the conclusion
They are incapable of
Substituting human decision makers
Possessing human capabilities
Producing accurate output for inadequate
knowledge base
Refining their own knowledge
&
incapabilities
5.
Limitations of ExpertSystems
No technology can offer easy and complete solution. Large systems are costly, require significant development time, and
computer resources. ESS have their limitations which include
Limitations of the technology
Difficult knowledge acquisition
ES are difficult to maintain
Knowledge not always readily available
Difficult to independently validate expertise
High development costs
Only work well in narrow domains
Can not learn from experience
Not suitable for all problems
6.
Applications of ExpertSystem
There are several major application areas of expert system such as:
agriculture ,
education,
Environment ,
law ,
manufacturing ,
medicine power system etc.
Expert System architecture/Componentsof Expert System
The most common architecture used in ES and
knowledge based systems is the Production system
/rule based system.
This type of systems uses knowledge encoded in the
form of production rules le if-then rules.
Inference is made by chaining through the rules
recursively, either in a forward or backward directions,
until a conclusion is reached or until failure occurs.
The selection of rules used in the chaining process is
determined by matching current facts against the
domain knowledge as variables in rules and choosing
among a candidate set of rules, the ones that meet
some given criteria inference process is carried out in
an interactive mode with the user providing input
parameters needed to complete the rule chaining
process.
9.
The main componentsof a typical expert system are:
Knowledge Base
Knowledge Base contains domain-specific and high-quality knowledge i.e. it contains facts and rules
about some specialized knowledge domain. The knowledge base of an ES is a store of both, factual
and heuristic knowledge.
• Factual Knowledge - It is the information widely accepted by the Knowledge Engineers and scholars in
the task domain.
• Heuristic Knowledge - It is about practice, accurate judgement, one's ability of evaluation, and
guessing.
Example:
Facts and rules in a simple knowledge base.
Variables are identified as a symbol preceded by ?.
(al (male Bob))
(a2 (female Sue))
---
(r1 (female ?X))
10.
Inference Process
Considerthe following knowledge in working memory.
(husband Rama Sita)
And the facts and Rules in the knowledge base
(a1 (wife Sita Rama))
(a2 (father Rama Lava))
(a3 (brother Kusha Lava))
(r1(husband ?X ?Y))-> (male ?X))
(r2(wife ?X ?Y))-> (female ?X))
(r3(father ?X?Y)) (brother?Z ?Y))-> (father (?X ?Z))
(r4(wife ?X ?Y)) (father?Z ?Y))-> (mother (?X ?Z))
From the above we can add to the knowledge base
(male Rama)
(female Sita)
(father Rama, Kusha)
(mother Sita Lava)
11.
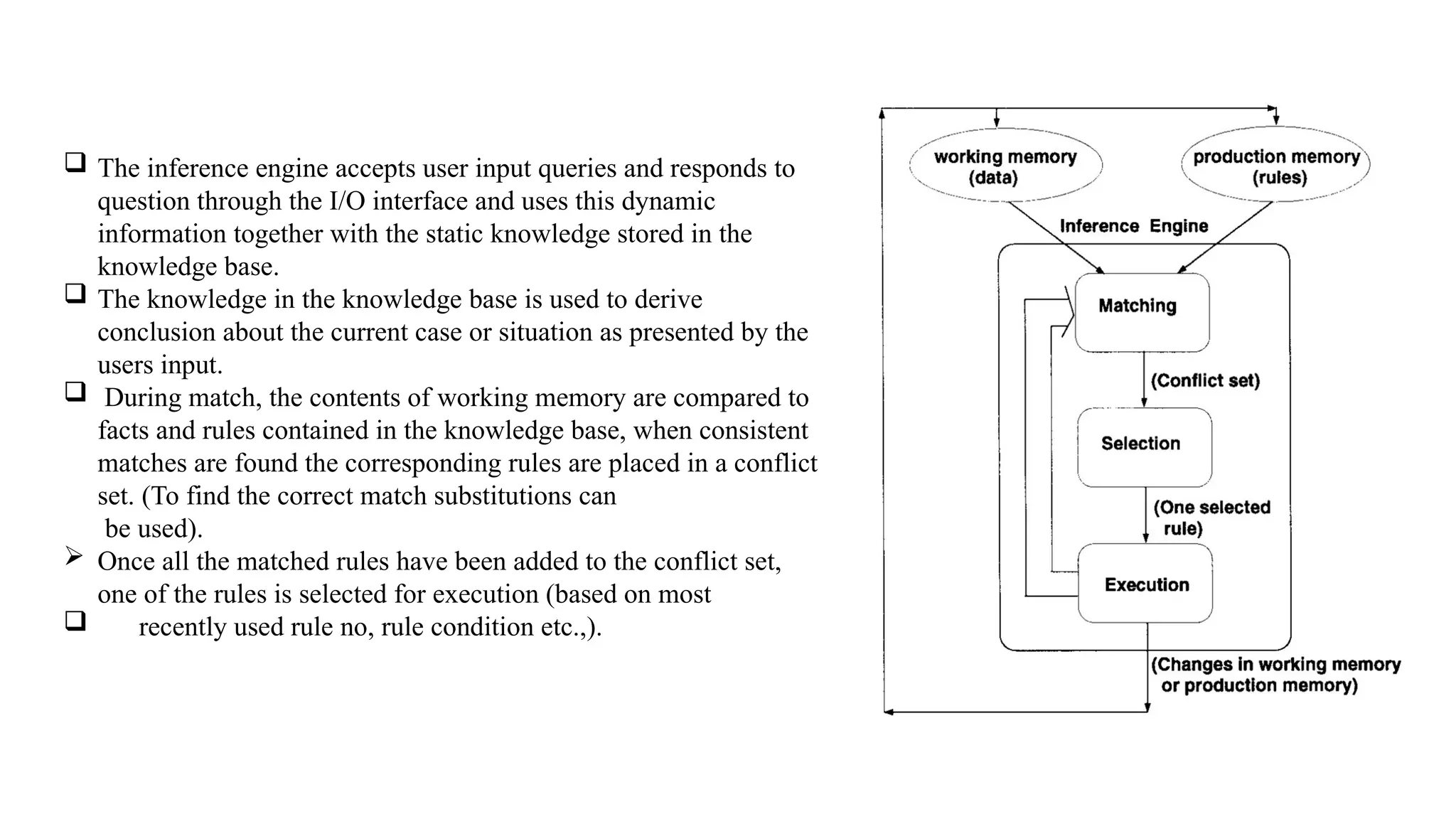
The inferenceengine accepts user input queries and responds to
question through the I/O interface and uses this dynamic
information together with the static knowledge stored in the
knowledge base.
The knowledge in the knowledge base is used to derive
conclusion about the current case or situation as presented by the
users input.
During match, the contents of working memory are compared to
facts and rules contained in the knowledge base, when consistent
matches are found the corresponding rules are placed in a conflict
set. (To find the correct match substitutions can
be used).
Once all the matched rules have been added to the conflict set,
one of the rules is selected for execution (based on most
recently used rule no, rule condition etc.,).
12.
Example:
(al (father SamBill))
(a2 (father Bill Pam))
(r1((father ?X ?Y) (father ?Y ?Z))→(grandfather ?X ?Z))
The Qurey is to find Pam's grandfather?
The clause is (grandfather?X pam)
this clause is added to the working memory and Substitutions
are made as
X-Sam, Y - Bill (Z - Pam is already known)
Therefore RHS becomes (grandfather Sam Pam)
ie. Sam is the grandfather of Pam.
The selected rule is then executed and the right hand side or action part of the rule is then carried out.
The execution step may result in the right hand clause being placed in working memory or it may be used to trigger a
message to the user.
In simple rule-based systems to recommend a solution, the Inference Engine uses the following strategies –
• Forward Chaining
• Backward Chaining
13.
Forward Chaining /Data-drivenInterface
It is a strategy of an expert system to answer the question, "What can happen next?" Here, the Inference Engine
follows the chain of conditions and derivations and finally deduces the outcome. i.e., the left side of a sequence of
rules is represented first and the rules are executed from left to right, Here input data is used to generate the directions
of the inference process.
It considers all the facts and rules, and sorts them before concluding to a solution.
This strategy is followed for working on conclusion, result, or effect.
For example, prediction of share market status as an effect of changes in interest rates.
14.
Backward Chaining/Goal-Driven Interface
With this strategy, an expert system finds out the answer to the question, "Why this happened?" On the basis of what has
already happened, the Inference Engine tries to find out which conditions could have happened in the past for this result.
This strategy is followed for finding out cause or reason.
When the right side of the rules is represented first, the left hand conditions becomes sub goals.
These sub goals may in turn cause sub goals to be established and so on until facts are found to match the
lowest sub goal conditions. This type of inference process is Backward chaining.
15.
Explanation Module
Explanation Module provides the user with an explanation of the reasoning process when requested, (how query?, why
query? ].
To respond to a how query , this module traces the chain of rules fired during a consultation with the user.
The sequence of rules that led to the conclusion is then printed for the user.
So the user can see the reasoning process followed by the system in arriving at the conclusion.
If the user does not agree with the steps presented, they may be changed using the editor.
To respond to a why query , it should explain why certain information is needed by the inference
engine to complete a step.
16.
I/O Interface
Helpsthe user to communicate with the system in a natural way. It uses simple selection
menus or
restricted language similar to natural language.
Learning Module & History File
Used to assist in building and changing the knowledge base. This is not a common
component of
expert systems.
Editor
Editor is used to build the knowledge base i.e., to add, delete, or modify the rules in
the knowledge base.
Case Studies onExpert System
MYCIN: A Quick Case Study
No course on Expert systems is complete without a discussion of Mycin. As mentioned above, Mycin
was one of the earliest expert systems, and its design has strongly influenced the design of commercial
expert systems and expert system shells.
Mycin was an expert system developed at Stanford university in the 1970s to demonstrate that a
system could successfully perform diagnoses of patients having infectious blood diseases. To do the
diagnosis "properly" involves growing cultures of the infecting organism. Unfortunately this takes
around 48 hours, and if doctors waited until this was complete their patient might be dead! So,
doctors have to come up with quick guesses about likely problems from the available data, and use
these guesses to provide a "covering" treatment where drugs are given which should deal with any
possible problem.
Mycin was developed partly in order to explore how human experts make these rough (but important)
guesses based on partial information. However, the problem is also a potentially important one in
practical terms - there are lots of junior or non-specialised doctors who sometimes have to make
such a rough diagnosis, and if there is an expert tool available to help them then this might allow
more effective treatment to be given. In fact, Mycin was never actually used in practice. This wasn't
because of any weakness in its performance - in tests it outperformed members of the Stanford
medical school. It was as much because of ethical and legal issues related to the use of computers in
medicine - if it gives the wrong diagnosis, who do you sue?
19.
MYCIN'S Knowledge baseis composed of if-then rules which are used to access various forms
of patient evidence with the ultimate goal, being the formulation of a correct diagnosis and
recommendation for a suitable therapy. A typical rule has the following form
Rule 1: If: The Stain of the organism is gram positive, and the morphology of the organism is
coccus, and the growth conformation of the organism is chains THEN: There is suggestive
evidence (0.7) that the identity of the organism is Streptococcus.
Rule 2: IF: The infection is pimary-bacteremia AND the site of the culture is one of the sterile sites
AND the suspected portal of entry is the gastrointestinal tract THEN: there is suggestive
evidence (0.7) that infection is bacteroid.
This rule would be used by the inference mechanism to help identify the offending organism. The
three conditions given in the if part of the rule refer to attributes that help to characterize and identify
organisms. When such an identification is relatively certain, an appropriate therapy may then be
recommended. The numeric value (0.7) given in the THEN part of the above rule corresponds to an
experts estimate of degree of belief one can place in the rule conclusion when the three conditions in
the if part have been satisfied. The 0.7 is roughly the certainty that the conclusion will be true given
the evidence. If the evidence is uncertain the certainties of the bits of evidence will be combined with
the certainty of the rule to give the certainty of the conclusion.
20.
Mycin was writtenin Lisp, and its rules are formally represented as Lisp expressions. The action part
of the rule could just be a conclusion about the problem being solved, or it could be an arbitary lisp
expression. This allowed great flexibility, but removed some of the modularity and clarity of rule-
based systems, so using the facility had to be used with care.
Anyway, Mycin is a (primarily) goal-directed system, using the basic backward chaining reasoning
strategy that we described above. However, Mycin used various heuristics to control the search for a
solution (or proof of some hypothesis). These were needed both to make the reasoning efficient and
to prevent the user being asked too many unnecessary questions.
MYCIN uses measures of both belief and disbelief to represent degrees of confirmation and
disconfirmation respectively in a given hypothesis. Mycin's performance improved significantly over
a several year period as additional knowledge was added. Tests indicates that MYCINs performance
now equals or exceeds that of experienced physicians. The initial Mycin knowledge base contained
only about 200 rules. This number gradually increased to more than 600 rules by the early 1980's.
The added rules significantly improved MYCINS performance leading to a 65% success record which
compared favourably with experienced physicians who demonstrated only an average of 60% success
rate.
21.
Mycin, though pioneeringmuch expert system research, also had a number of problems which were
remedied in later, more sophisticated architectures. One of these was that the rules often mixed
domain knowledge, problem solving knowledge and "screening conditions" (conditions to avoid
asking the user silly or awkward questions example, checking patient is not child before asking
about alcoholism). A later version called NEOMYCIN attempted to deal with these by having an
explicit disease taxonomy (represented as a frame system) to represent facts about different kinds of
diseases. The basic problem solving strategy was to go down the disease tree, from general classes of
diseases to very specific ones, gathering information to differentiate between two disease subclasses
(ie, if disease1 has subtypes disease2 and disease3, and you know that the patient has the disease1,
and subtype disease2 has symptom1 but not disease3, then ask about symptom1.)
There were many other developments from the MYCIN project. For example, EMYCIN was really
the first expert shell developed from Mycin. A new expert system called PUFF was developed using
EMYCIN in the new domain of heart disorders. And system called NEOMYCIN was developed for
training doctors, which would take them through various example cases, checking their conclusions
and explaining where they went wrong.
22.
Dendral Expert System
Thefirst knowledge based expert system to be competed was DENDRAL, developed at Stanford in the
late 1960's by Edward Feigenbaum and the geneticist Joshua Lederberg. DENDRAL was a chemical-
analysis expert system. The substance to be analyzed might, for example, be a complicated compound
of carbon, hydrogen, and nitrogen. Starting from spectrographic data obtained from the substance,
DENDRAL would hypothesize the substance's molecular structure.
DENDRAL used herustic Knowledge obtained from experienced chemists to help constrain the
and thereby reduce the search space. During tests DENDRAL discovered a number of
structures previously unknown to expert chemists. With DENDRAL they found how difficult it was to
elicit expert knowledge from experts. This led to the development of Meta-DENDRAL.













![ Explanation Module
Explanation Module provides the user with an explanation of the reasoning process when requested, (how query?, why
query? ].
To respond to a how query , this module traces the chain of rules fired during a consultation with the user.
The sequence of rules that led to the conclusion is then printed for the user.
So the user can see the reasoning process followed by the system in arriving at the conclusion.
If the user does not agree with the steps presented, they may be changed using the editor.
To respond to a why query , it should explain why certain information is needed by the inference
engine to complete a step.](https://image.slidesharecdn.com/bcaunit4-250328091425-d65d43e9/75/AI-system-mimicking-human-expert-decision-making-pptx-15-2048.jpg)














































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)








