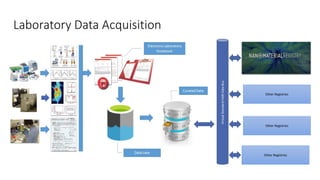
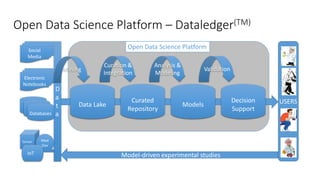
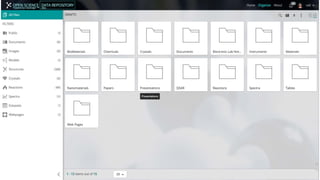
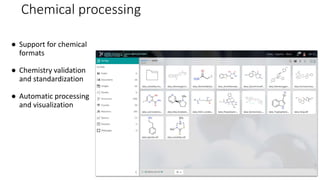
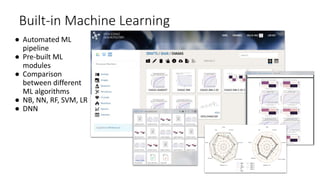
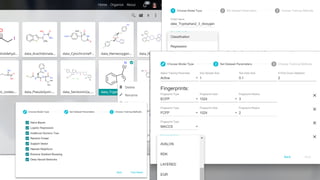
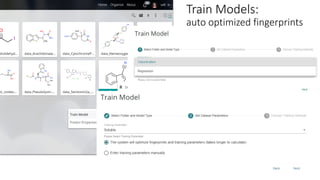
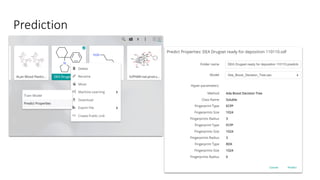
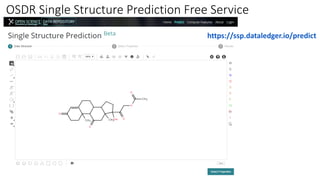
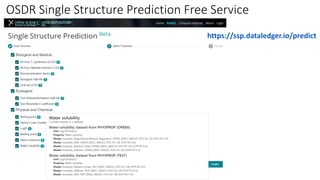
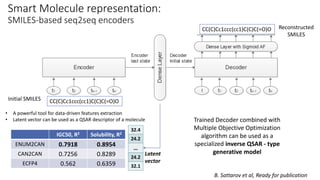
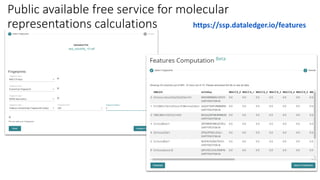
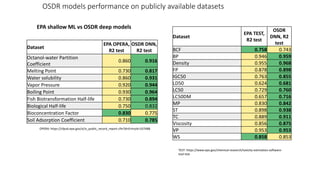
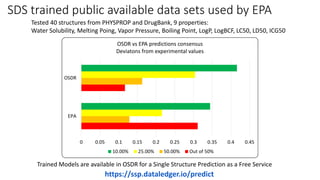
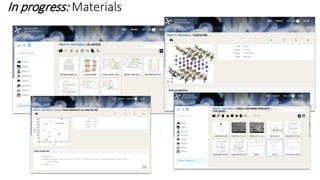
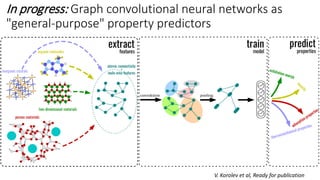
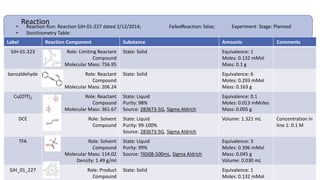
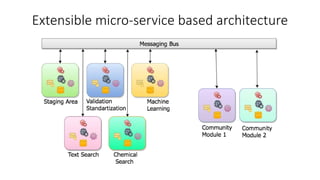
Dataledger(tm) is a research data platform that integrates data acquisition with machine learning pipelines for chemical processing and experimental studies. It supports various machine learning methods, including shallow and deep learning techniques, for tasks such as QSAR and inverse QSAR modeling, while offering free services for molecular representation and structure prediction. The platform emphasizes open data science principles, collaboration, and automation to aid in data science workflows and chemical property predictions.




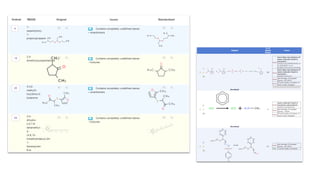








![In progress: Deep Learning approach for Ln(III)
complexation
models and model analysis
0
1
2
3
4
5
La Ce Pr Nd Pm Sm Eu Gd Tb Dy Ho Er Tm Yb Lu
Train Validation Test
0
0.2
0.4
0.6
0.8
1
La Ce Pr Nd Pm Sm Eu Gd Tb Dy Ho Er Tm Yb Lu
Train Validation Test
-1
-0.5
0
0.5
1
1.5
2
4
12
13
15
16
21
26
31
37
39
42
43
51
58
65
69
73
81
87
97
104
106
107
108
116
119
120
122
124
131
134
139
140
143
Impact,[logK]
Bit number
A. Mitrofanov, Ready for submission](https://image.slidesharecdn.com/20180927opensciencedatarepositorydataledger-researchdataplatformwithdataacquisitionandintegratedmach-190730214140/85/Open-Science-Data-Repository-Dataledger-31-320.jpg)



































![[DSC Europe 25] Andrzej Kowalczyk - AI - how to start small and grow in the f...](https://cdn.slidesharecdn.com/ss_thumbnails/oy1zmo94qv6vpcqjvno2-andrzej-kowalczyk-ai-how-to-start-small-and-grow-in-the-future-1-260119121559-cf093b23-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Egor Krasheninnikov - The Control Stack: Building Guardrails ...](https://cdn.slidesharecdn.com/ss_thumbnails/3lzcz7hxqmo51mtalv4u-the-control-stack-260119101520-ea90841a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Tamas Srancsik - How To Teach Your AI Football? An Argument f...](https://cdn.slidesharecdn.com/ss_thumbnails/bcjh1m9xtbosv20ucftb-tamas-srancsik-how-to-teach-your-ai-football-260121115910-08b53e9e-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)

