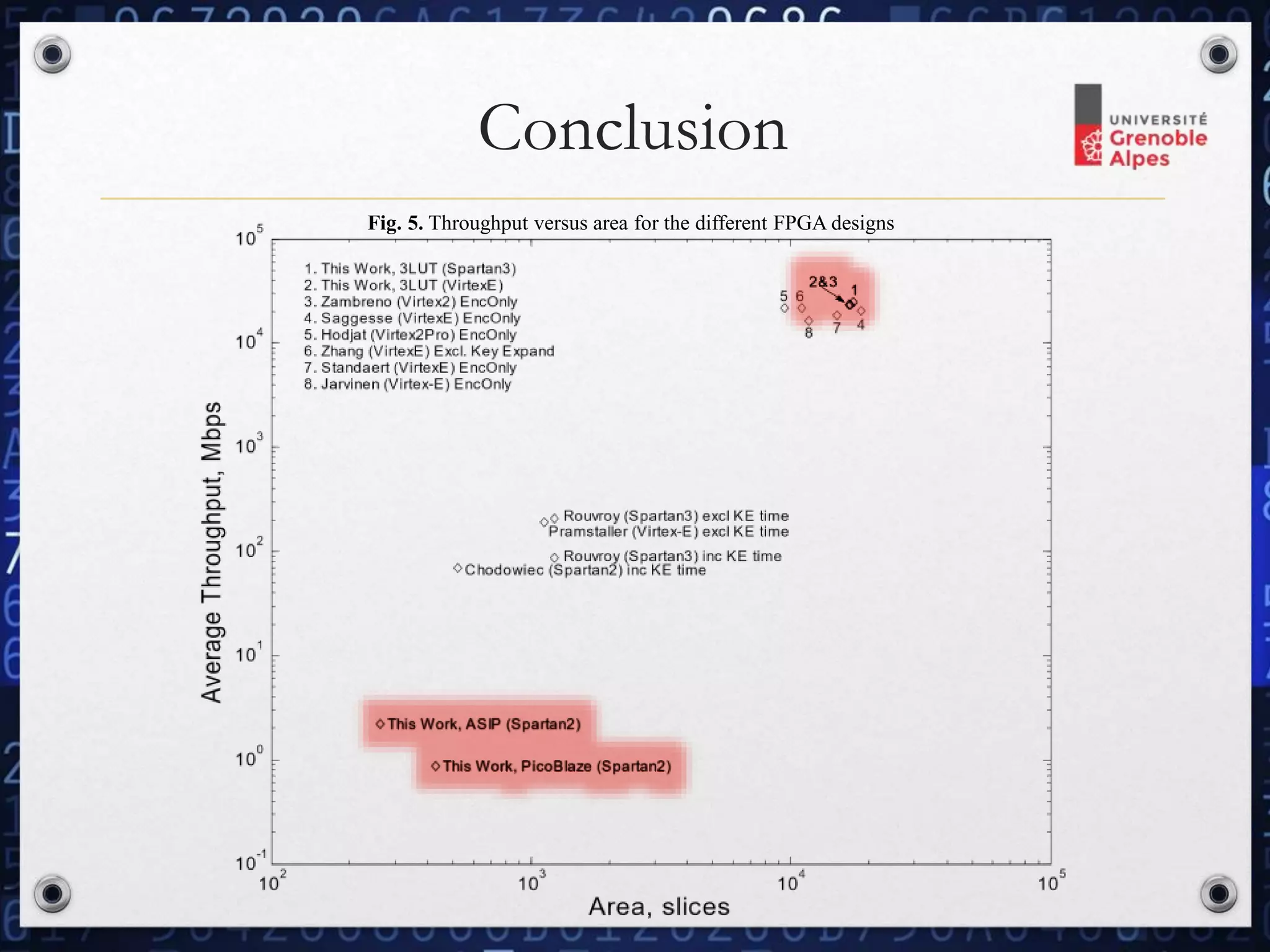
The document discusses two FPGA designs for AES implementation, focusing on a high-speed design achieving 25 Gbps throughput and a compact design utilizing only 124 slices with 2.2 Mbps throughput. The faster design allows for periodic key changes without throughput loss and dynamic switching between encryption and decryption modes, while the smaller design emphasizes efficiency with an 8-bit data path and pipelined architecture. It showcases the advantages of FPGA-specific optimizations over traditional ASIC approaches in both speed and area.