







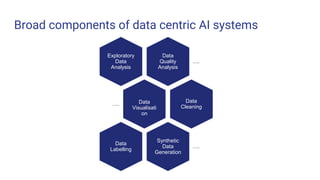
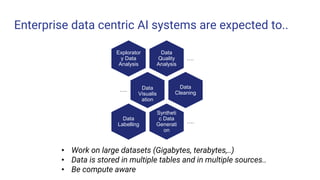
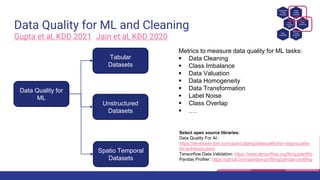








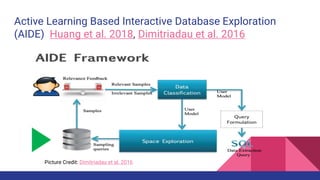
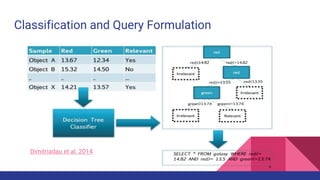



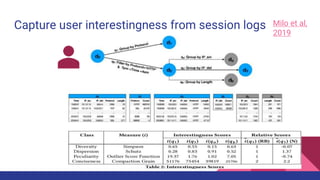



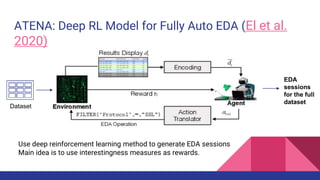









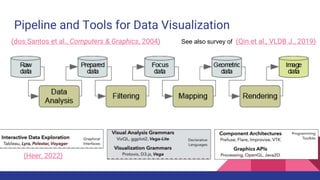



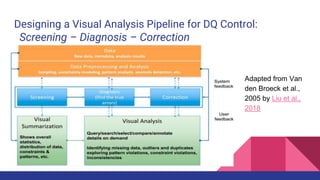

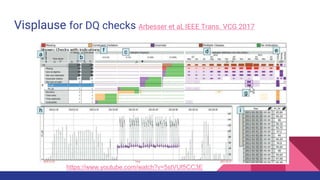



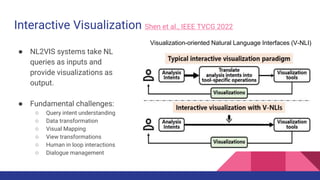
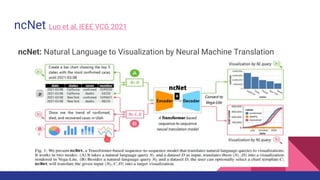
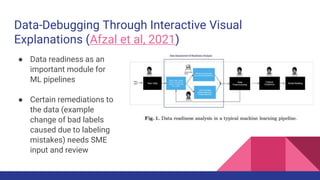
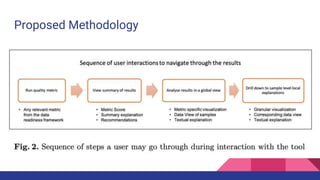




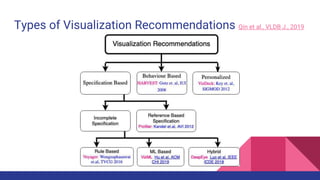


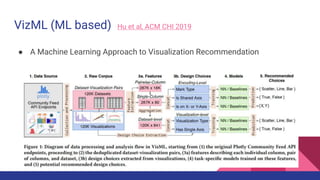



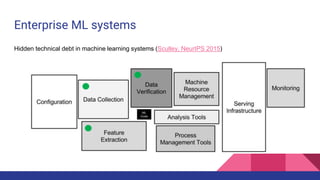


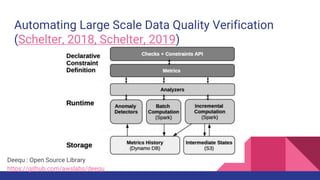

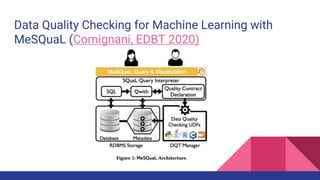





The document presents a tutorial on advances in data-centric AI systems focusing on exploratory data analysis (EDA), data visualization, and data quality. It emphasizes the importance of data preparation in AI workflows, outlines recent developments in automated EDA techniques, and discusses visualization systems, challenges, and recommendations for machine learning use cases. The tutorial is structured in four parts, covering key topics and encouraging open discussion among participants.



































































