Download as PDF, PPTX









![Is data cleaning always helpful for ML pipeline?
▪ Question: what is the impact of different cleaning methods on
ML models?
▪ Experiment setup:
▪ Datasets: 13 real world datasets
▪ Five error types: outliers, duplicates, inconsistencies,
mislabels and missing values
▪ Seven classification algorithms: Logistic Regression,
Decision Tree, Random Forest, Adaboost, XGBoost, k-
Nearest Neighbors, and Naïve Bayes
KDD Tutorial / © 2020 IBM Corporation
[LXJ19]
Cleaning methods used for error types
Image Source: Li et al, 2019. CleanML: A Benchmark for Joint Data
Cleaning and Machine Learning [Experiments and Analysis]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-16-320.jpg)
![Insights: Impact of different cleaning techniques
KDD Tutorial / © 2020 IBM Corporation
[LXJ19]
Impact, if cleaned* Negative Impacts*
Inconsistencies Insignificant No
Outliers Insignificant/ Positive Possible
Duplicates Insignificant Yes
Missing Values Positive If imputation is far away
from ground truth
Mislabels Positive If dataset accuracy < 50%
*based on general patterns across the datasets and different train test settings](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-17-320.jpg)
![In conclusion
▪ Data cleaning does not necessarily improve the quality of downstream ML models
▪ Impact depends on different factors:
▪ Cleaning algorithm and its set of parameters
▪ ML model dependent
▪ Order of cleaning operators
▪ Model selection and cleaning algorithm can increase robustness of impacts – no one
solution!
KDD Tutorial / © 2020 IBM Corporation
[LXJ19]
[LAU19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-18-320.jpg)

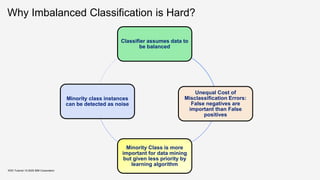
![Why it happens?
Expected in domains where data with one pattern is more common than other.
KDD Tutorial / © 2020 IBM Corporation
Source: Krawczyk et al, 2016. Learning from imbalanced data: open challenges and future direction
[Kra16]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-21-320.jpg)

![Affecting Factor: Imbalance Ratio
KDD Tutorial / © 2020 IBM Corporation
Imbalance Ratio
Learning algorithm biased towards majority class
Minority sample considered as the noise
In confusion region, priorities given to majority
Increase Increase
➔ ➔
Is the imbalance ratio only cause of performance
degradation in learning from imbalanced data? NO
➔
Source: . https://towardsdatascience.com/sampling-techniques-for-extremely-imbalanced-data-281cc01da0a8
[WP03]
[GBSW04]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-25-320.jpg)
![Affecting Factor: Overlap
KDD Tutorial / © 2020 IBM Corporation
Priority given to majority class in the overlapping region
Minority data points are considered as noise due to a
smaller number of data points from minority class in the
overlapping region
Source: Ali et al, 2015. Classification with class imbalance problem: A Review
[ALI15]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-26-320.jpg)
![Affecting Factor: Smaller sub-concepts
It is difficult to discern separate groupings
with so few examples in minority class
KDD Tutorial / © 2020 IBM Corporation
Source: Ali et al, 2015. Classification with class imbalance problem: A Review
[ALI15]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-27-320.jpg)
![Affecting Factor: Dataset Size
KDD Tutorial / © 2020 IBM Corporation
Size
Deteriorate the evaluation
measure
Underlying structure of the
minority class distributions
is difficult to understand
➔ ➔
Source: Ali et al, 2015. Classification with class imbalance problem: A Review
[ALI15]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-28-320.jpg)
![Affecting Factor: Combined Effect
KDD Tutorial / © 2020 IBM Corporation
Combined effect of varying dataset
size, overlap, and imbalance ratio
Source: Misha et al, 2010. Overlap versus Imbalance
[DT10]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-29-320.jpg)
![Modelling Strategies: Types
KDD Tutorial / © 2020 IBM Corporation
Our Focus
Source: Paula et al, 2015. A Survey of Predictive Modelling under Imbalanced Distributions
[BTR15]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-30-320.jpg)

![Bayes Impact index
KDD Tutorial / © 2020 IBM Corporation
Totally Overlapped: No
Impact
Separable: No Impact Partially Overlapped:
High Impact
Source: Yang et al, 2019. Bayes Imbalance Impact Index: A Measure of Class Imbalanced Data Set for Classification Problem
[LCT19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-32-320.jpg)



![Filter Based Approaches
▪ On the labeling correctness in
computer vision datasets
[ARK18]
▪ Published in Interactive
Adaptive Learning 2018
▪ Train CNN ensembles to
detect incorrect labels
▪ Voting schemes used:
▪ Majority Voting
KDD Tutorial / © 2020 IBM Corporation
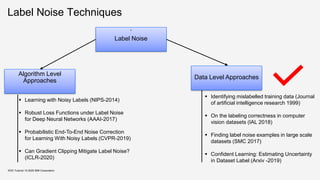
▪ Identifying mislabelled training
data [BF99]
▪ Published in Journal of
artificial intelligence research,
1999
▪ Train filters on parts of the
training data in order to
identify mislabeled examples
in the remaining training data.
▪ Voting schemes used:
▪ Majority Voting
▪ Consensus Voting
▪ Finding label noise examples in large
scale datasets [EGH17]
▪ Published in International
Conference on Systems, Man, and
Cybernetics, 2017
▪ Two-level approach
▪ Level 1 – Train SVM on the
unfiltered data. All support
vectors can be potential
candidates for noisy points.
▪ Level 2 – Train classifier on the
original data without the support
vectors. Samples for which the
original and the predicted label
does not match, are marked as
label noise.
Source: Broadley et al, 1999, Identifying mislabeled training Data](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-38-320.jpg)
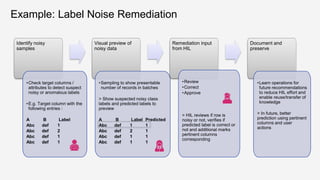
![Eliminating Class Noise in
Large Datasets – ICML 2003
Criterion for a rule to be GR:
▪ It should have classification precision on its own
partition above a threshold
▪ It should have minimum coverage on its own
partition
▪ coverage - how many examples rules
classifies (either noise or not) confidently -
that is its coverage.
KDD Tutorial / © 2020 IBM Corporation
Source: Zhu et al, 2003. Eliminating Class Noise In Large Datasets
[ZWC03]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-39-320.jpg)
![Confident Learning: Estimating
Uncertainty in Dataset Label -2019
The Principles of Confident Learning
▪ Prune to search for label errors
▪ Count to train on clean data
▪ Rank which examples to use during training
KDD Tutorial / © 2020 IBM Corporation
In case of Label Collison
Source: Northcutt et al, 2019. Confident Learning: Estimating Uncertainty in Dataset Label
[NJC19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-40-320.jpg)
![KDD Tutorial / © 2020 IBM Corporation
Confident Learning: Estimating
Uncertainty in Dataset Label -2019
Source: Northcutt et al, 2019. Confident Learning: Estimating Uncertainty in Dataset Label
[NJC19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-41-320.jpg)
![KDD Tutorial / © 2020 IBM Corporation
Confident Learning: Estimating
Uncertainty in Dataset Label -2019
Source: Northcutt et al, 2019. Confident Learning: Estimating Uncertainty in Dataset Label
[NJC19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-42-320.jpg)



![Leave One Out
KDD Tutorial / © 2020 IBM Corporation
𝑨: 𝑳𝒆𝒂𝒓𝒏𝒊𝒏𝒈 𝑨𝒍𝒈𝒐𝒓𝒊𝒕𝒉𝒎
𝑽: 𝑽𝒂𝒍𝒊𝒅𝒂𝒕𝒊𝒐𝒏 𝑺𝒆𝒕
𝑻: 𝑻𝒓𝒂𝒊𝒏𝒊𝒏𝒈 𝑺𝒆𝒕
𝒙: 𝑻𝒓𝒂𝒊𝒏𝒊𝒏𝒈 𝑫𝒂𝒕𝒖𝒎
𝑷 𝒙, 𝑨, 𝑽 : 𝑷𝒆𝒓𝒇𝒐𝒓𝒎𝒂𝒏𝒄𝒆 𝒐𝒇 𝑨 𝒐𝒏 𝑽 𝒖𝒔𝒊𝒏𝒈 𝒙
𝑽𝒂𝒍 𝒙, 𝑨, 𝑽 : 𝑰𝒎𝒑𝒂𝒄𝒕 𝒐𝒇 𝒙 𝒊𝒏 𝒑𝒆𝒓𝒇𝒐𝒓𝒎𝒂𝒏𝒄𝒆 𝒐𝒇 𝑨 𝒐𝒏 𝑽
𝑉𝑎𝑙 𝑥, 𝐴, 𝑉 = 𝑃 𝑇, 𝐴, 𝑉 − 𝑃(𝑇 − 𝑥, 𝐴, 𝑉)
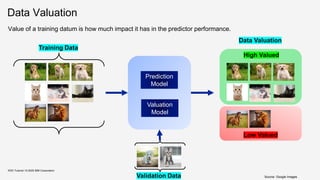
Value of training datum 𝑥
Performance of learning algorithm 𝐴 on validation set
𝑉 when trained on full data 𝑻 including 𝑥
Performance of learning algorithm 𝐴 on validation set
𝑉 when trained on full data 𝑻 excluding 𝑥
[Coo77]
Source: Cook et al, 1977. Detection of influential observation in linear regression](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-48-320.jpg)
![Example
KDD Tutorial / © 2020 IBM Corporation
𝑉𝑎𝑙( , 𝐴, 𝑉) = 𝑃( , 𝐴, 𝑉) − 𝑃( , 𝐴, 𝑉)
0.032 = 0.80 – 0.768
Source: Google Images
[Coo77]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-49-320.jpg)
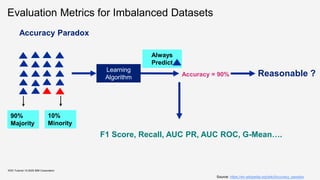
![Implications
➢ Doesn’t capture complex interactions between subsets of data
KDD Tutorial / © 2020 IBM Corporation
𝑉𝑎𝑙( , 𝐴, 𝑉) = 0
𝑉𝑎𝑙( , 𝐴, 𝑉) = 0
𝑉𝑎𝑙( , 𝐴, 𝑉) = 0
𝑉𝑎𝑙( , 𝐴, 𝑉) = 0
𝑉𝑎𝑙( , 𝐴, 𝑉) = 0
𝑉𝑎𝑙( , 𝐴, 𝑉) = 0
Reasonable ?
Source: Google Images
[Coo77]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-50-320.jpg)
![Data Shapley
KDD Tutorial / © 2020 IBM Corporation
Valuation of a datum should come
from the way it coalesces with
other data in the dataset
Valuation of is derived from its
marginal contribution to all other
subsets in the data
[GZ19]
Source: Ghorbani et al, 2019. Data shapley: Equitable valuation of data for machine learning](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-51-320.jpg)
![Shapley Values – Formulation
KDD Tutorial / © 2020 IBM Corporation
𝜙 𝑖 = 𝐶
𝑆⊆𝐷{𝑖}
𝑣(𝑆 ∪ {𝑖}) − 𝑣(𝑆)
𝑛−1
𝑆
Constant
value of 𝑖 together with 𝑆
Shapley value of datum 𝑖
value of 𝑆 alone
Iterates over all subsets in data
Source: Ghorbani et al, 2019. Data shapley: Equitable valuation of data for machine learning
[GZ19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-52-320.jpg)
![Practical Implications of Data Shapley
KDD Tutorial / © 2020 IBM Corporation
▪ Computation of Shapley value of a datum requires 2 𝐷 −1
summations
▪ In practice, we approximate Shapley values using Monte Carlo simulations
▪ The number of simulations required doesn’t scale with amount of data
Source: Ghorbani et al, 2019. Data shapley: Equitable valuation of data for machine learning
[GZ19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-53-320.jpg)
![Results using Data Shapley
KDD Tutorial / © 2020 IBM Corporation
The data points that have higher
noise receive lesser Shapley values
Source: Ghorbani et al, 2019. Data shapley: Equitable valuation of data for machine learning
[GZ19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-54-320.jpg)
![DVRL
KDD Tutorial / © 2020 IBM Corporation
Reward = Performance(selected data)
–
performance(complete data)
Data valuation is a function
from datum to its value
Sample data based on valuation
Build target model
using selected data
[YAP19]
Source: Yoon et al, 2019. Data Valuation using Reinforcement Learning](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-55-320.jpg)
![KDD Tutorial / © 2020 IBM Corporation
DVRL Results
▪ Removing high valued points affect the model performance the most
▪ Removing low valued points affect the model performance the least
Source: Yoon et al, 2019. Data Valuation using Reinforcement Learning
[YAP19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-56-320.jpg)

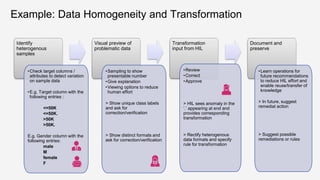
![Homogeneity score
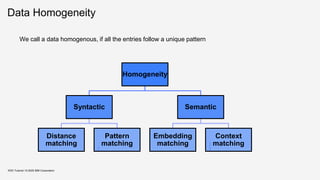
KDD Tutorial / © 2020 IBM Corporation
Desiderata for measures that characterize homogeneity
▪ Lesser the number of clusters, better the homogeneity
▪ More skewed the distribution of clusters, better the homogeneity
Homogeneity( ) < Homogeneity( )
Homogeneity ( ) < Homogeneity( )
[DKO+07]
Source: Dai et al, 2006. Column heterogeneity as a measure of data quality](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-62-320.jpg)
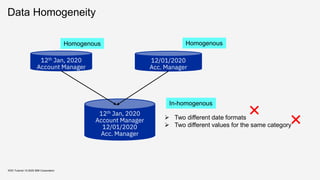
![Homogeneity score
KDD Tutorial / © 2020 IBM Corporation
Entropy Simpson’s biodiversity Index
𝐸𝑛𝑡𝑟𝑜𝑝𝑦𝑝 = 𝑝 𝑥 ln 𝑝(𝑥)
▪ Satisfies both the desiderata
▪ Not bounded 𝑅+
▪ Satisfies both the desiderata
▪ Bounded in [0,1]
𝑃 𝐶 𝑥𝑖 ≠ 𝐶(𝑥𝑗)
𝑃 is the probability distribution of the
entries among clusters
𝑥_𝑖 and 𝑥_𝑗 are two entries and
𝐶(. ) denotes the cluster index
[sim]
Source : http://www.countrysideinfo.co.uk/simpsons.htm](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-63-320.jpg)

![Semantic Homogeneity
KDD Tutorial / © 2020 IBM Corporation
Embeddings based similarity
▪ Applicable when the entries in the data are
meaningful English words
▪ Can use off the shelf embeddings like word2vec,
Glove etc.
▪ 𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦 𝑥, 𝑦 = 𝑐𝑜𝑠𝑖𝑛𝑒 𝜙 𝑥 , 𝜙 𝑦 ;
▪ 𝜙 . = 𝑤𝑜𝑟𝑑 𝑒𝑚𝑏𝑒𝑑𝑑𝑖𝑛𝑔
▪ Embeddings capture semantic information as well
[MCCD13]
Source: Mikolov et al, 2012. Efficient estimation of word representations in vector space](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-66-320.jpg)
![KDD Tutorial / © 2020 IBM Corporation
Semantic Homogeneity
Context based similarity
▪ Distributional hypothesis : words that are
used and occur in the same context tend to
purport similar meanings
▪ In Structured dataset, word ≈ an entry in a row,
context ≈ remaining entries in the row
▪ We may not be able to use off the shelf
embeddings
▪ Need to train dataset specific embeddings
▪ Entries that have similar neighborhood in their
rows tend to show higher similarities
▪ Useful in cases where
𝑠𝑖𝑚 𝑒𝑚𝑝𝑙𝑜𝑦𝑒𝑒, 𝑚𝑎𝑛𝑎𝑔𝑒𝑟 being high is not
desirable in a dataset
Source: Mikolov et al, 2012. Efficient estimation of word representations in vector space
[MCCD13]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-67-320.jpg)


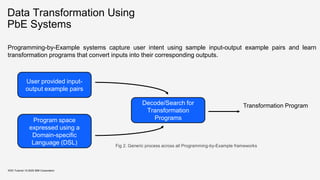

![Flash Meta – A Framework for
Inductive Program Synthesis (2015)
KDD Tutorial / © 2020 IBM Corporation
▪ Consider the transformation “(425) 706-7709” --> “425”.
▪ The output string ”425” can be represented in 4 possible ways
as concatenation of substrings ‘4’, ‘2’, ‘5’, ‘42’, ‘25’.
▪ Leaf nodes e1, e2, e3, e12, e23 are VSAs to output substrings
‘4’, ‘2’, ‘5’, ‘42’, ‘25’ respectively.
Key aspects for symbolic systems:
▪ Independence of problems:
▪ Number of possible sub-problems is quadratic:
▪ Enumerative Search:
Drawback: Takes a lot of time to look for correct
programs in the transformation space
Source: Polozov et al, 2015. Flash Meta – A Framework for Inductive Program Synthesis
[PG15]
Source: Polozov et al, 2015. FlashMeta –A FrameworkforInductiveProgram Synthesis](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-74-320.jpg)

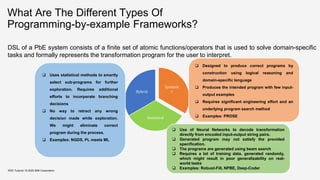
![Statistical System: Robust Fill
KDD Tutorial / © 2020 IBM Corporation
▪ DL approach based on seq-to-seq encoder-decoder networks which perform as good as conventional
non-DL based PbE approaches like Flash-Fill but with the added motivation of having the learned model
to be more robust to noise in the input data.
Domain Specific Language
Source: Devlin et al, 2017. Robust-Fill
[DUB+17]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-76-320.jpg)
![Statistical System:
KDD Tutorial / © 2020 IBM Corporation
Key aspects:
▪ Use of neural networks with no symbolic guidance unlike hybrid systems.
▪ Use of Beam-Search to decode/predict top-k most likely transformation programs based on joint
probability of decoded DSL operators
▪ Use of synthetic datasets for model training which might lead to poor generalizability in real-world
tasks.
▪ Caveat: No guarantee whether the synthesized program will compile or satisfy user-provided
specifications
[DUB+17]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-77-320.jpg)
![Statistical System:
KDD Tutorial / © 2020 IBM Corporation
Solution: Execution-guided Synthesis
▪ During Beam-Search, execute the partially constructed transformation program on the go and eliminate
ones which produce syntax errors or empty outputs
▪ Restrict DSL vocabulary at each step to enforce grammar correctness
▪ Incorporate execution guidance during training and testing so that program correctness is guaranteed by
construction.
Source: Wang et al, 2018. Execution-Guided Neural Program Synthesis
[KMP+18]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-78-320.jpg)






![Automatic Text Scoring Using Neural Networks
Objective:
Automatically assign a score to the text given a marking scale.
Approach:
1. Train a Model to learn word embeddings that capture both context and word-specific scores
2. Train an LSTM-based network using the score-specific word embeddings to output the text score
Task:
Predict the Essay scores written by students ranging from Grade 7 to Grade 10
KDD Tutorial / © 2020 IBM Corporation
[AYR16]
Source : Alikaniotis et al, 2016. Automatic text scoring using neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-85-320.jpg)
![Automatic Text Scoring Using Neural Networks
Score-Specific Word Embeddings:
▪ Learn both context and word specific scores during training.
▪ Context:
▪ For a sequence of words S = (w1,…, wt,…, wn), construct S´ = (w1,…, wc,…, wn | wc ∈ 𝕍, wt ≠ wc)
▪ The model learns word embeddings by ranking the activation of the true sequence S higher than the activation of its
‘noisy’ counterpart S´ through a hinge margin loss.
▪ Word Specific Scores:
▪ Apply linear regression on the sequence embedding to predict the essay score
▪ Minimize the mean squared error between the predicted ŷ and the actual essay score y
KDD Tutorial / © 2020 IBM Corporation
[AYR16]
Source : Alikaniotis et al, 2016. Automatic text scoring using neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-86-320.jpg)
![Automatic Text Scoring Using Neural Networks
KDD Tutorial / © 2020 IBM Corporation
Comparison:
▪ Standard Embeddings only consider context and hence place correct and incorrect spellings close to each other.
▪ Score-Specific Embeddings discriminate between spelling mistakes based on low and high essay scores, thus
separating them in the embedding space while preserving the context
[AYR16]
Source : Alikaniotis et al, 2016. Automatic text scoring using neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-87-320.jpg)
![Automatic Text Scoring Using Neural Networks
Explainability:
▪ Which words in the input text correspond to a high score vs a low score?
▪ Perform a single pass of an essay from left to right and let the LSTM make its score prediction
▪ Provide a pseudo-high score and a pseudo-low score as ground truth and measure the gradient
magnitudes corresponding to each word
KDD Tutorial / © 2020 IBM Corporation
[AYR16]
Source : Alikaniotis et al, 2016. Automatic text scoring using neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-88-320.jpg)
![Automatic Text Scoring Using Neural Networks
KDD Tutorial / © 2020 IBM Corporation
Visualizations:
▪ Positive feedback for correctly placed punctuation or long-distance dependencies (Sentence 6 “are … researching”)
▪ Negative feedback for POS mistakes (Sentence 2, “Being patience”)
▪ Incorrect negative feedback (Sentence 3, “reader satisfied”)
[AYR16]
Source : Alikaniotis et al, 2016. Automatic text scoring using neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-89-320.jpg)
![Transparent text quality assessment with
convolutional neural networks
Objective:
Automatically assign a score to the input Swedish text
Approach:
1. Train a CNN with residual connections on character embeddings
2. Utilize a pseudo-probabilistic framework to incorporate axioms on varying quality text vs high
quality text to train the model
Task:
1. Predict the Essay scores and compare against human graders
2. Qualitatively Analyze text to identify low vs high scoring regions
KDD Tutorial / © 2020 IBM Corporation Source : Östling et al, 2017. Transparent text quality assessment with convolutional neural networks
[ÖG17]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-90-320.jpg)
![Transparent text quality assessment with
convolutional neural networks
Training:
▪ For a sequence of characters S = (s1, s2,…, sn), construct the character embedding matrix 𝕍 x d
▪ Pass the character embedding matrix through the CNN
▪ Final quality score is the dot product of the output weight vector and the mean value of the outputs at the
final residual layer.
▪ Utilise pseudo-probabilistic framework P(a > b) = σ(q(a) − q(b)), where σ(x) is the logistic function and q(x)
is the network score
KDD Tutorial / © 2020 IBM Corporation
[ÖG17]
Source : Östling et al, 2017. Transparent text quality assessment with convolutional neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-91-320.jpg)
![Transparent text quality assessment with
convolutional neural networks
KDD Tutorial / © 2020 IBM Corporation
Axioms:
1. All authors (professional or not) are consistent
2. Professional authors are better than blog authors
3. All professional authors are equal
4. Blog authors are not equal
[ÖG17]
Source : Östling et al, 2017. Transparent text quality assessment with convolutional neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-92-320.jpg)
![Transparent text quality assessment with
convolutional neural networks
Explainability:
▪ Which characters in the input text correspond to a high score vs a low score?
▪ Red encodes low scores, blue encodes high scores. Faded colors are used for scores near zero.
▪ News examples are scored higher than the blog examples
▪ Informal spellings, use of smileys leads to low scores in the blog text
KDD Tutorial / © 2020 IBM Corporation
[ÖG17]
Source : Östling et al, 2017. Transparent text quality assessment with convolutional neural networks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-93-320.jpg)

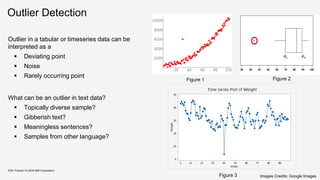
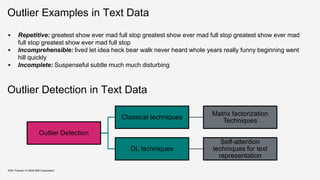
![Outlier Detection for Text Data
▪ Feature Generation – Simple Bag of Words
Approach
▪ Apply Matrix Factorization – Decompose the
given term matrix into a low rank matrix L and
an outlier matrix Z
▪ Further, L can be expressed as
▪ where,
▪ The l2 norm score of a particular column zx
serves as an outlier score for the document
KDD Tutorial / © 2020 IBM Corporation Source : Kannan et al, 2017. Outlier detection for text data
[KWAP17]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-97-320.jpg)
![Outlier Detection for Text Data
▪ For experiments, outliers are sampled from a unique class from standard datasets
▪ Receiver operator characteristics are studied to assess the performance of the
proposed approach.
▪ Approach is useful at identifying outliers even from regular classes.
▪ Patterns such as unusually short/long documents, unique words, repetitive vocabulary
etc. were observed in detected outliers.
KDD Tutorial / © 2020 IBM Corporation
[KWAP17]
Source : Kannan et al, 2017. Outlier detection for text data](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-98-320.jpg)
![Unsupervised Anomaly Detection in Text
Multi-Head Self-Attention:
KDD Tutorial / © 2020 IBM Corporation
Sentence Embedding
Attention matrix
▪ Proposes a novel one-class classification method which leverages pretrained word
embeddings to perform anomaly detection on text
▪ Given a word embedding matrix H, multi-head self-attention is used to map sentences of
variable length to a collection of fixed size representations, representing a sentence with
respect to multiple contexts
Source : Ruff et al 2019. Self-Attentive, Multi-Context One-Class Classification for Unsupervised Anomaly Detection on Text
[RZV+19]
(1)
(2)](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-99-320.jpg)
![Unsupervised Anomaly Detection on Text
KDD Tutorial / © 2020 IBM Corporation
CVDD Objective
Context Vector
Orthogonality Constraint
▪ These sentence representations are trained along with a collection of context vectors such that
the context vectors and representations are similar while keeping the context vectors diverse
▪ Greater the distance of mk(H) to ck implies a more anomalous sample w.r.t. context k
Outlier Scoring
[RZV+19]
Source : Ruff et al 2019. Self-Attentive, Multi-Context One-Class Classification for Unsupervised Anomaly Detection on Text
(1)](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-100-320.jpg)
![More Generic Text Quality Approaches
Local Text Coherence:
▪ [MS18] Mesgar et. al. "A neural local coherence model for text quality assessment." EMNLP, 2018.
Text Formality:
▪ [JMAS19] Jain et. al. "Unsupervised controllable text formalization." AAAI, 2019.
Text Bias:
▪ [RDNMJ13] Recasens et. al. "Linguistic models for analyzing and detecting biased language." ACL,
2013.
KDD Tutorial / © 2020 IBM Corporation](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-101-320.jpg)

![Identifying Non-Obvious Cases in Semantic
Similarity Datasets
Objective:
▪ Identify obvious and non-obvious text pairs from semantic similarity datasets
Approach:
1. Compare the Jenson-Shannon Divergence (JSD) of the text snippets against the median JSD of
the entire distribution
2. Classify the text snippets based on divergence from the median
Task:
▪ Analyze model performance numbers on SemEval Community Question Answering for both
obvious and non-obvious cases
KDD Tutorial / © 2020 IBM Corporation Source : Peinelt et al 2019. Aiming beyond the Obvious: Identifying Non-Obvious Cases in Semantic Similarity Datasets
[PLN19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-103-320.jpg)
![Identifying Non-Obvious Cases in Semantic
Similarity Datasets
KDD Tutorial / © 2020 IBM Corporation
Lexical divergence distribution by labels across datasets:
▪ The datasets differ with respect to the degree of lexical divergence
they contain
▪ Pairs with negative labels tend to have higher JSD scores than pairs
with positive labels
▪ Model performance numbers TPR/TNR/F1 score should be higher on
non-obvious cases compared to obvious cases.
Examples of Obvious and Non-
Obvious Semantic Text Pairs:
[PLN19]
Source : Peinelt et al 2019. Aiming beyond the Obvious: Identifying Non-Obvious Cases in Semantic Similarity Datasets](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-104-320.jpg)
![Improving Neural Conversational Models
with Entropy-Based Data Filtering
Objective:
▪ Filter generic utterances from dialog datasets to improve model performance
Approach:
▪ Device a data filtering by identifying open-ended inputs determined by calculating the entropy of the
distribution over target utterances
Task:
▪ Measure custom metric scores such as response length, KL divergence, Coherence, Bleu score
etc. for standard dialog datasets based on source/target/both filtering mechanisms
KDD Tutorial / © 2020 IBM Corporation Source: Csaky et al, 2019. Improving neural conversational models with entropy-based data filtering
[CPR19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-105-320.jpg)
![Improving Neural Conversational Models
with Entropy-Based Data Filtering
KDD Tutorial / © 2020 IBM Corporation
Examples:
1. Source = “What did you do today?”
• has high entropy, since it is paired with many different responses in the data
2. Source = “What color is the sky?”
• has low entropy since it’s observed with few responses in the data
3. Target = “I don’t know”
• has high entropy, since it is paired with many different inputs in the data
4. Target = “Try not to take on more than you can handle”
• has low entropy, since it is paired with few inputs in the data
[CPR19]
Source: Csaky et al, 2019. Improving neural conversational models with entropy-based data filtering](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-106-320.jpg)

![Understanding the Difficulty of Text Classification Tasks
Proposes an approach to design data quality metric which
explains the complexity of the given data for classification task
▪ Considers various data characteristics to generates a 48 dim
feature vector for each dataset.
▪ Data characteristics include
▪ Class Diversity: Count based probability distribution of classes in
the dataset
▪ Class Imbalance: σ𝑐=1
𝐶
|
1
𝐶
−
𝑛𝑐
𝑇𝑑𝑎𝑡𝑎
|
▪ Class Interference: Similarities among samples belonging to
different classes
▪ Data Complexity: Linguistic properties of data samples
KDD Tutorial / © 2020 IBM Corporation Source : Collins et al, 2018. Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks
[CRZ18]
Feature vector for a given dataset cover
quality properties such as
▪ Class Diversity (2-Dim)
▪ Shannon Class Diversity
▪ Shannon Class Equitability
▪ Class Imbalance (1-Dim)
▪ Class Interference (24-Dim)
▪ Hellinger Similarity
▪ Top N-Gram Interference
▪ Mutual Information
▪ Data Complexity (21-Dim)
▪ Distinct n-gram : Total n-gram
▪ Inverse Flesch Reading Ease
▪ N-Gram and Character diversity](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-108-320.jpg)
![Understanding the Difficulty of Text Classification Tasks
▪ Authors propose usage of genetic algorithms to intelligently explore the 248 possible combinations
▪ The fitness function for the genetic algorithm was Pearson correlation between difficulty score and
model performance on test set
▪ 89 datasets were considered for evaluation and 12 different types of models on each dataset
▪ The effectiveness of a given combination of metric is measured using its correlation with the
performance of various models on various datasets
▪ Stronger the negative correlation of a metric with model performance, better the metric explains data
complexity
KDD Tutorial / © 2020 IBM Corporation
[CRZ18]
Source : Collins et al, 2018. Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-109-320.jpg)
![Understanding the Difficulty of Text Classification Tasks
KDD Tutorial / © 2020 IBM Corporation
Difficulty Measure D2 =
Distinct Unigrams : Total Unigrams + Class Imbalance +
Class Diversity + Maximum Unigram Hellinger Similarity
+ Unigram Mutual Info.
Correlation = −0.8814
[CRZ18]
Source : Collins et al, 2018. Evolutionary Data Measures: Understanding the Difficulty of Text Classification Tasks](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-110-320.jpg)


![Next Steps
KDD Tutorial / © 2020 IBM Corporation
How to assess quality of NLP models independent of task?
▪ Held-out datasets are often not comprehensive
▪ Contain the same biases as the training data
▪ Real-world performance may be overestimated
▪ Difficult to figure out where model is failing and how to fix it
[RWGS20]
Source : Ribeiro et al, 2020. Beyond Accuracy: Behavioral Testing of NLP Models with CheckList](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-113-320.jpg)

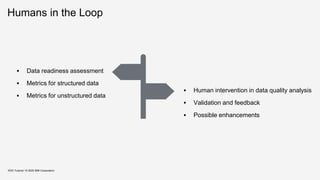
![Supporting Data Operations
Keywords:
▪ Preparation
▪ Integration
▪ Cleaning
▪ Curation
▪ Transformation
▪ Manipulation
Notable tools:
▪ Trifacta ~ Potter’s Wheel
▪ OpenRefine
▪ Wrangler
➢ How to validate that data is clean enough
➢ How to delegate sub-tasks between
respective role players / data workers
➢ How to enable reuse of human input and
codifying tacit knowledge
➢ How to provide cognitive and not just
statistical support
KDD Tutorial / © 2020 IBM Corporation
[Ham13]
[KPHH11]
[RH01]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-117-320.jpg)
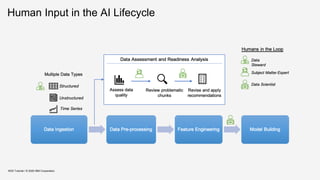
![KDD Tutorial / © 2020 IBM Corporation
Next Steps…
Shared collaborative workspace to streamline, regulate and document human input/expertise
Focus on reproducibility, traceability, and verifiability
Easy to user
specification
interface
e.g. graphical
interface, by
example or in
natural language
instead of
complex
grammars or
regular
expressions
Visual preview
appropriate
visualisation of
relevant data
chunks to see the
changes
Minimum
latency
effect of
transformation
should be quickly
visible
Clear lineage
ability to view
what changes
have been done
previously and by
whom
documentation of
operations and
observed effects
Enable
assessment of
data operations
basic analysis
using default ML
models to show
impact of
changes
Data versioning
to enable
experiments for
trial and testing
e.g. ability to
undo changes
Streamlined
collaboration
task lists based
on persona for
shared data
cleaning pipeline
[MLW+19]
[KHFW16]
[ROE+19]](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-120-320.jpg)


![References
KDD Tutorial / © 2020 IBM Corporation
[BF99] Carla E Brodley and Mark A Friedl. Identifying mislabeled training data. Journal of artificial intelligence research, 11:131–167,
1999.
[ZWC03] Xingquan Zhu, Xindong Wu, and Qijun Chen. Eliminating class noise in large datasets. In Proceedings of the 20th
International Conference on Machine Learning(ICML-03), pages 920–927, 2003.
[DLG17]J unhua Ding, XinChuan Li, and Venkat N Gudivada. Augmentation and evaluation of training data for deep learning. In2017
IEEE International Conference on Big Data(Big Data), pages 2603–2611. IEEE, 2017.
[ARK18] Mohammed Al-Rawi and Dimosthenis Karatzas. On the labeling correctness in computer vision datasets. In
IAL@PKDD/ECML, 2018.
[NJC19] Curtis G Northcutt, Lu Jiang, and Isaac L Chuang. Confident learning: Estimating uncertainty in dataset labels. arXiv preprint
arXiv:1911.00068, 2019.
[Coo77] R Dennis Cook. Detection of influential observation in linear regression.T echnometrics
[EGH17] Rajmadhan Ekambaram, Dmitry B Goldgof, and Lawrence O Hall. Finding label noise examples in large scale datasets.
In2017 IEEE International Conference on Systems, Man, and Cybernetics pages 2420–2424., 2017.](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-123-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[GZ19] Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learning. arXiv preprint
arXiv:1904.02868, 2019
[YAP19] Jinsung Yoon, Sercan O Arik, and Tomas Pfister. Data valuation using reinforcement learning. arXiv preprint
arXiv:1909.11671, 2019.
[DKO+07] Bing Tian Dai, Nick Koudas, Beng Chin Ooi, Divesh Srivastava, and Suresh Venkatasubramanian. Column heterogeneity
as a measure of data quality. 2007
[sim] http://www.countrysideinfo.co.uk/simpsons.htm.
[DHI12] AnHai Doan, Alon Halevy, and Zachary Ives. Principles of data integration. Elsevier, 2012.
[MCCD13] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space.
arXiv preprint arXiv:1301.3781, 2013
[ALI15] Aida Ali and Siti Mariyam Hj. Shamsuddin and Anca L. Ralescu. Classification with class imbalance problem: A review. SOCO
2015](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-124-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[PG15] Oleksandr Polozov and Sumit Gulwani. Flashmeta: a framework for inductive program synthesis. In Proceedings of the 2015
ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications, pages 107–126,
2015.
[DUB+17] Jacob Devlin, Jonathan Uesato, Surya Bhupatiraju, Rishabh Singh, Abdel-rahman Mohamed, and Pushmeet Kohli.
Robustfill: Neural program learning under noisy i/o. In Proceedings of the 34th International Conference on Machine Learning-Volume
70, pages 990–998, 2017.
[KMP+18] Ashwin Kalyan, Abhishek Mohta, Oleksandr Polozov, Dhruv Batra, Prateek Jain, and Sumit Gulwani. Neural-guided
deductive search for real-time program synthesis from examples. arXiv preprint arXiv:1804.01186, 2018.
[AYR16] Dimitrios Alikaniotis, Helen Yannakoudakis, and Marek Rei. Automatic text scoring using neural networks. In Proceedings of
the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 715–725, Berlin, Germany,
August 2016. Association for Computational Linguistics.
[CPR19] Richard Csaky, Patrik Purgai, and Gabor Recski. Improving neural conversational models with entropy-based data filtering.
arXiv preprint arXiv:1905.05471, 2019.](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-125-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[CRZ18] Edward Collins, Nikolai Rozanov, and Bingbing Zhang. Evolutionary data measures: Understanding the difficulty of text
classification tasks. arXiv preprint arXiv:1811.01910, 2018.
[JMAS19] Parag Jain, Abhijit Mishra, Amar Prakash Azad, and Karthik Sankaranarayanan. Unsupervised controllable text
formalization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6554–6561, 2019.
[KWAP17] Ramakrishnan Kannan, Hyenkyun Woo, Charu C Aggarwal, and Haesun Park. Outlier detection for text data. In
Proceedings of the 2017 siam international conference on data mining, pages 489–497. SIAM, 2017.
[MS18] Mohsen Mesgar and Michael Strube. A neural local coherence model for text quality assessment. In Proceedings of the 2018
Conference on Empirical Methods in Natural Language Processing, pages 4328–4339, 2018.
[ÖG17] Robert Östling and Gintar ̇e Grigonyt ̇e. Transparent text quality assessment with convolutional neural networks. In
Proceedings of the 12th Workshop on Innovative Use of NLP for Building Educational Applications, pages 282–286, 2017.](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-126-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[PLN19] Nicole Peinelt, Maria Liakata, and Dong Nguyen. Aiming beyond the obvious: Identifying non-obvious cases in semantic
similarity datasets. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2792–2798,
2019.
[RDNMJ13] Marta Recasens, Cristian Danescu-Niculescu-Mizil, and Dan Jurafsky. Linguistic models for analyzing and detecting
biased language. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long
Papers), pages 1650–1659, 2013.
[RWGS20] Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of nlp
models with checklist. arXiv preprint arXiv:2005.04118, 2020.
[RZV+19] Lukas Ruff, Yury Zemlyanskiy, Robert Vandermeulen, Thomas Schnake, and Marius Kloft. Self-attentive, multi-context one-
class classification for unsupervised anomaly detection on text. In Proceedings of the 57th Annual Meeting of the Association for
Computational Linguistics, pages 4061–4071, 2019.
[RH01] Vijayshankar Raman and Joseph M Hellerstein. Potter’s wheel: An interactive data cleaning system. In VLDB, volume 1,
pages 381–390, 2001.
[ROE+19] El Kindi Rezig, Mourad Ouzzani, Ahmed K Elmagarmid, Walid G Aref, and Michael Stonebraker. Towards an end-to-end
human-centric data cleaning framework. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics, pages 1–7, 2019.](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-127-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[Ham13] Kelli Ham. Openrefine (version 2.5). http://openrefine. org. free, open-source tool for cleaning and transforming data.
Journal of the Medical Library Association: JMLA, 101(3):233, 2013.
[KHFW16] Sanjay Krishnan, Daniel Haas, Michael J Franklin, and Eugene Wu. Towards reliable interactive data cleaning: A user
survey and recommendations. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics, pages 1–5, 2016.
[KPHH11] Sean Kandel, Andreas Paepcke, Joseph Hellerstein, and Jeffrey Heer. Wrangler: Interactive visual specification of data
transformation scripts. In ACM Human Factors in Computing Systems (CHI), 2011.
[MLW+19] Michael Muller, Ingrid Lange, Dakuo Wang, David Piorkowski, Jason Tsay, Q Vera Liao, Casey Dugan, and Thomas
Erickson. How data science workers work with data: Discovery, capture, curation, design, creation. In Proceedings of the 2019 CHI
Conference on Human Factors in Computing Systems, pages 1–15, 2019.
[BTR15] Paula Branco, Luis Torgo, and Rita Ribeiro. A survey of predictive modelling under imbalanced distributions.arXiv preprint
arXiv:1505.01658, 2015](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-128-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[DT10] Misha Denil and Thomas Trappenberg. Overlap versus imbalance. In Canadian conference on artificial intelligence, pages
220–231. Springer, 2010.
[GBSW04] Jerzy W Grzymala-Busse, Jerzy Stefanowski, and Szymon Wilk. A comparison of two approaches to data mining from
imbalanced data. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, pages 757–
763. Springer, 2004
[Jap03] Nathalie Japkowicz. Class imbalances: are we focusing on the right issue. 2003.
[JJ04] Taeho Jo and Nathalie Japkowicz. Class imbalances versus small disjuncts. ACM Sigkdd Explorations Newsletter, 6(1):40–49,
2004.
[Kra16] Bartosz Krawczyk. Learning from imbalanced data: open challenges and future directions. InProgress in Artificial Intelligence
volume, 2016.
[LCT19] Yang Lu, Yiu-ming Cheung, and Yuan Yan Tang. Bayes imbalance impact index: A measure of class imbalanced data set for
classification problem. IEEE Transactions on Neural Networks and Learning Systems, 2019
[Jap03] Nathalie Japkowicz. Class imbalances: are we focusing on the right issue. 2003.](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-129-320.jpg)
![References
KDD Tutorial / © 2020 IBM Corporation
[DT10] Misha Denil and Thomas Trappenberg. Overlap versus imbalance. In Canadian conference on artificial intelligence, pages
220–231. Springer, 2010.
[GBSW04] Jerzy W Grzymala-Busse, Jerzy Stefanowski, and Szymon Wilk. A comparison of two approaches to data mining from
imbalanced data. In International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, pages 757–
763. Springer, 2004
[JJ04] Taeho Jo and Nathalie Japkowicz. Class imbalances versus small disjuncts. ACM Sigkdd Explorations Newsletter, 6(1):40–49,
2004.
[Kra16] Bartosz Krawczyk. Learning from imbalanced data: open challenges and future directions. InProgress in Artificial Intelligence
volume, 2016.
[LCT19] Yang Lu, Yiu-ming Cheung, and Yuan Yan Tang. Bayes imbalance impact index: A measure of class imbalanced data set for
classification problem. IEEE Transactions on Neural Networks and Learning Systems, 2019
WP03] Gary M Weiss and Foster Provost. Learning when training data are costly: The effect of class distribution on tree induction.
Journal of artificial intelligence research,19:315–354, 2003](https://image.slidesharecdn.com/kddtutorial2020-210408042112/85/Overview-and-Importance-of-Data-Quality-for-Machine-Learning-Tasks-130-320.jpg)

This document discusses the importance of data quality measurement for machine learning applications. It covers quality metrics for both structured/tabular data and unstructured text data. For structured data, it discusses common data cleaning techniques and whether cleaning always helps machine learning pipelines. It also covers topics like class imbalance, label noise, data valuation, data homogeneity, and transformations. For class imbalance specifically, it describes factors that can affect imbalanced classification like imbalance ratio, overlap between classes, smaller sub-concepts, dataset size, and label noise. It also discusses different modeling strategies and resampling techniques to address imbalance. Finally, it covers label noise as another important data quality metric, how noise can be introduced in labels,




















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)














