Download as PDF, PPTX









































![[info] Benchmark Mode Samples Score Score error Units
[info] c.g.m.u.ContainsBench.listContains thrpt 3 41.033 25.573 ops/s
[info] c.g.m.u.ContainsBench.setContains thrpt 3 6.810 1.569 ops/s
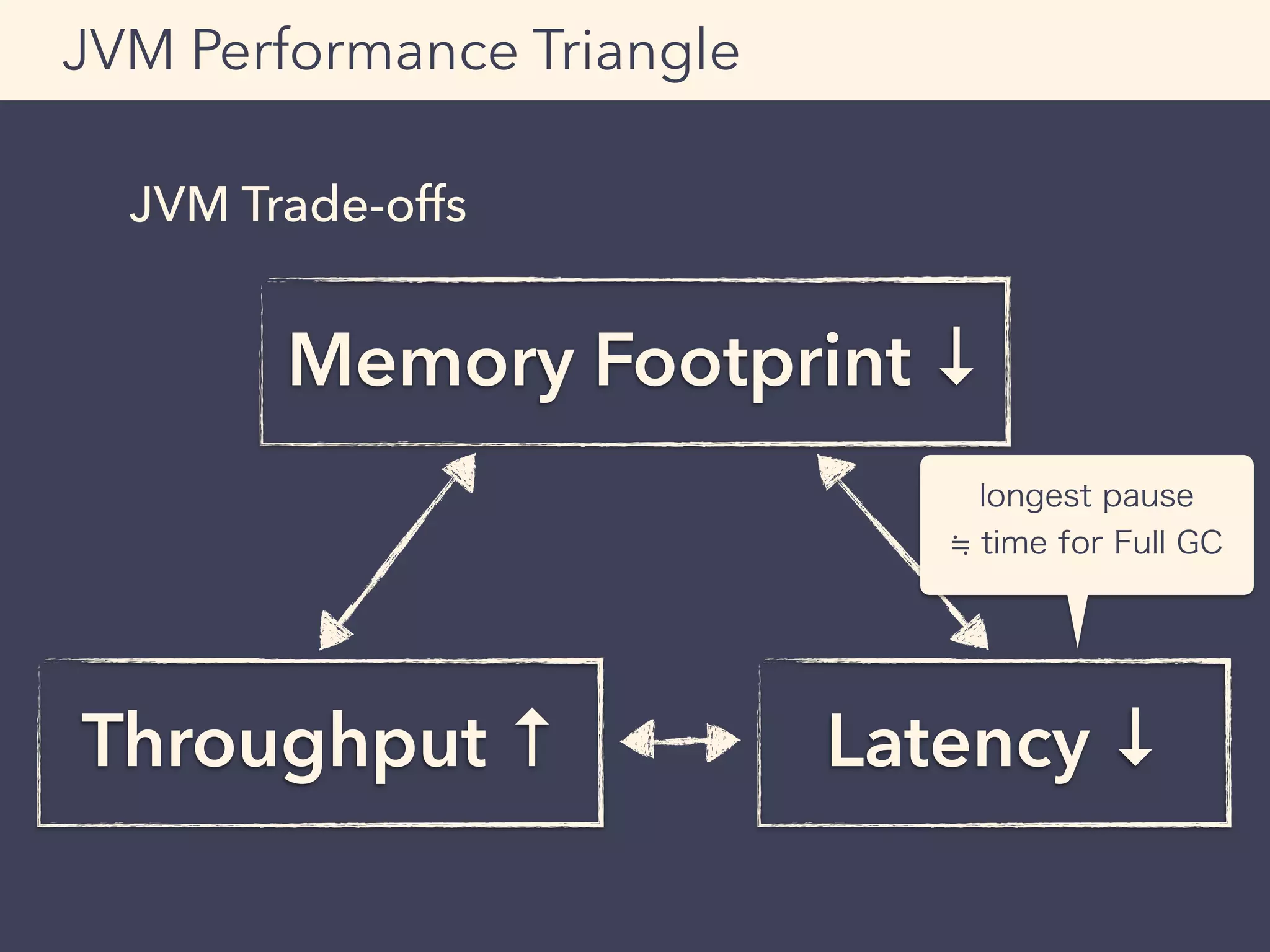
Micro Benchmark: sbt-jmh
Result (excerpted)
By default, throughput score
will be displayed.
(larger is better)
http://mogproject.blogspot.jp/2014/10/micro-benchmark-in-scala-using-sbt-jmh.html](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01-150625101523-lva1-app6892/75/Adtech-scala-performance-tuning-150323223738-conversion-gate01-56-2048.jpg)

![def f(xs: List[Int], acc: List[Int] = Nil): List[Int] = {
if (xs.length < 4) {
(xs.sum :: acc).reverse
} else {
val (y, ys) = xs.splitAt(4)
f(ys, y.sum :: acc)
}
}
Horrible and True Story pt.2
Group by 4 elements of List[Int], then
calculate each sum respectively
scala> f((1 to 10).toList)
res1: List[Int] = List(10, 26, 19)
Example](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01-150625101523-lva1-app6892/75/Adtech-scala-performance-tuning-150323223738-conversion-gate01-58-2048.jpg)


![Horrible and True Story pt.2
For your information, the following one-liner does
same work using built-in method
scala> (1 to 10).grouped(4).map(_.sum).toList
res2: List[Int] = List(10, 26, 19)](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01-150625101523-lva1-app6892/75/Adtech-scala-performance-tuning-150323223738-conversion-gate01-61-2048.jpg)





![Result example (excerpted)
ab - Apache Bench
Benchmarking example.com (be patient)
Completed 1200 requests
Completed 2400 requests
(略)
Completed 10800 requests
Completed 12000 requests
Finished 12000 requests
(略)
Concurrency Level: 200
Time taken for tests: 7.365 seconds
Complete requests: 12000
Failed requests: 0
Write errors: 0
Total transferred: 166583579 bytes
HTML transferred: 160331058 bytes
Requests per second: 1629.31 [#/sec] (mean)
Time per request: 122.751 [ms] (mean)
Time per request: 0.614 [ms] (mean, across all concurrent requests)
Transfer rate: 22087.90 [Kbytes/sec] received
(略)
Percentage of the requests served within a certain time (ms)
50% 116
66% 138
75% 146
80% 150
90% 161
95% 170
98% 185
99% 208
100% 308 (longest request)
Requests per second
= QPS](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01-150625101523-lva1-app6892/75/Adtech-scala-performance-tuning-150323223738-conversion-gate01-67-2048.jpg)



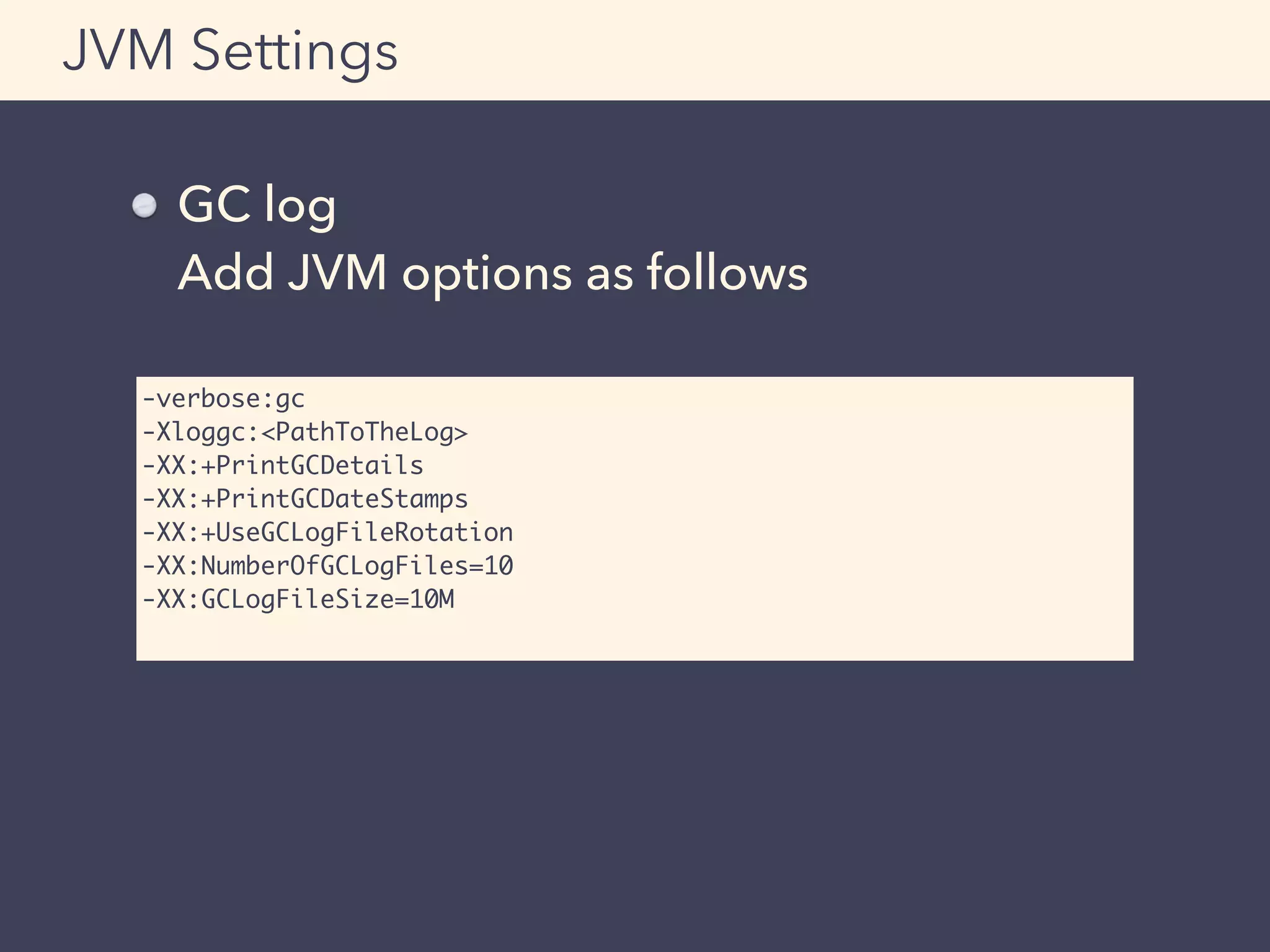

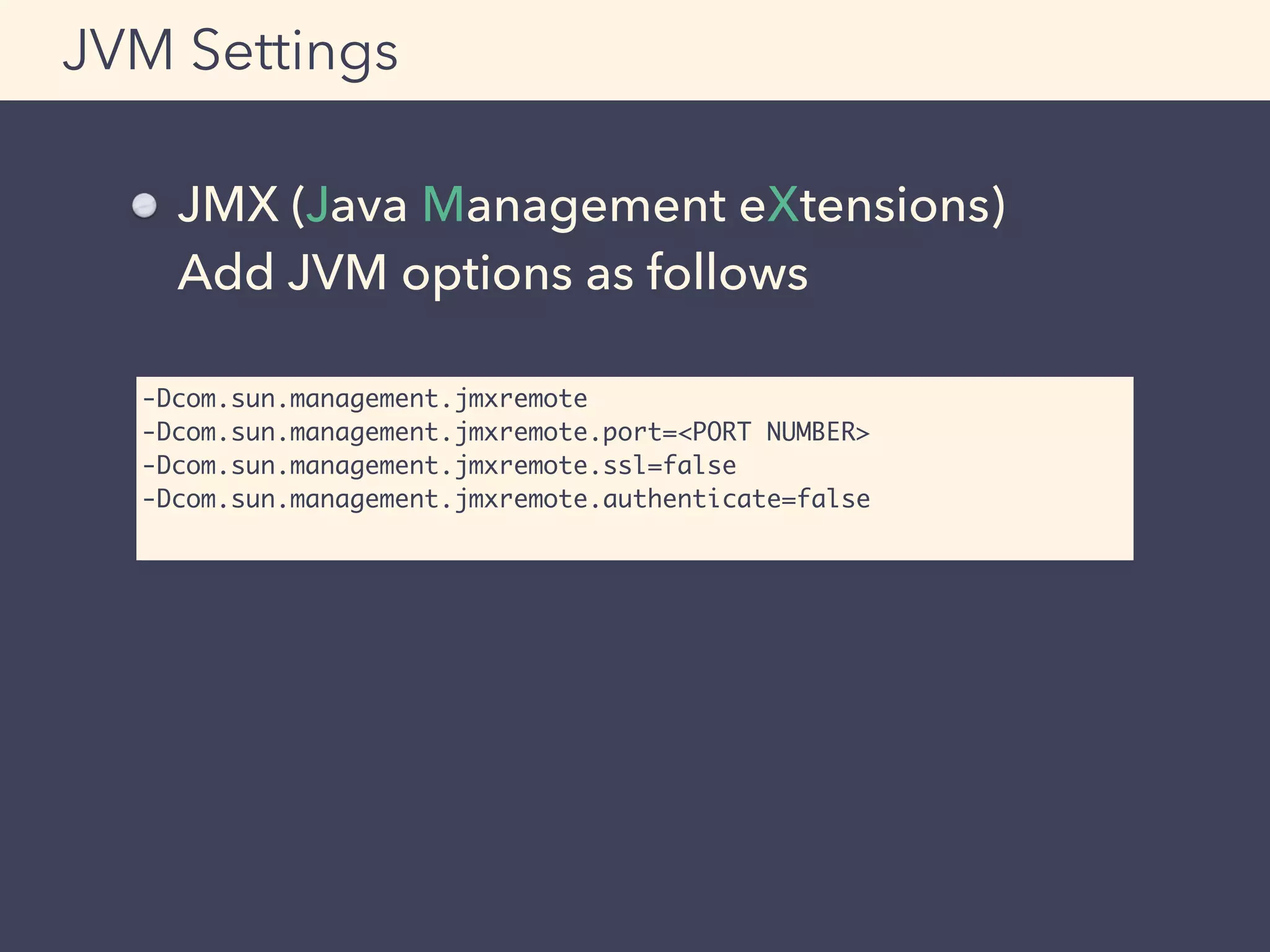
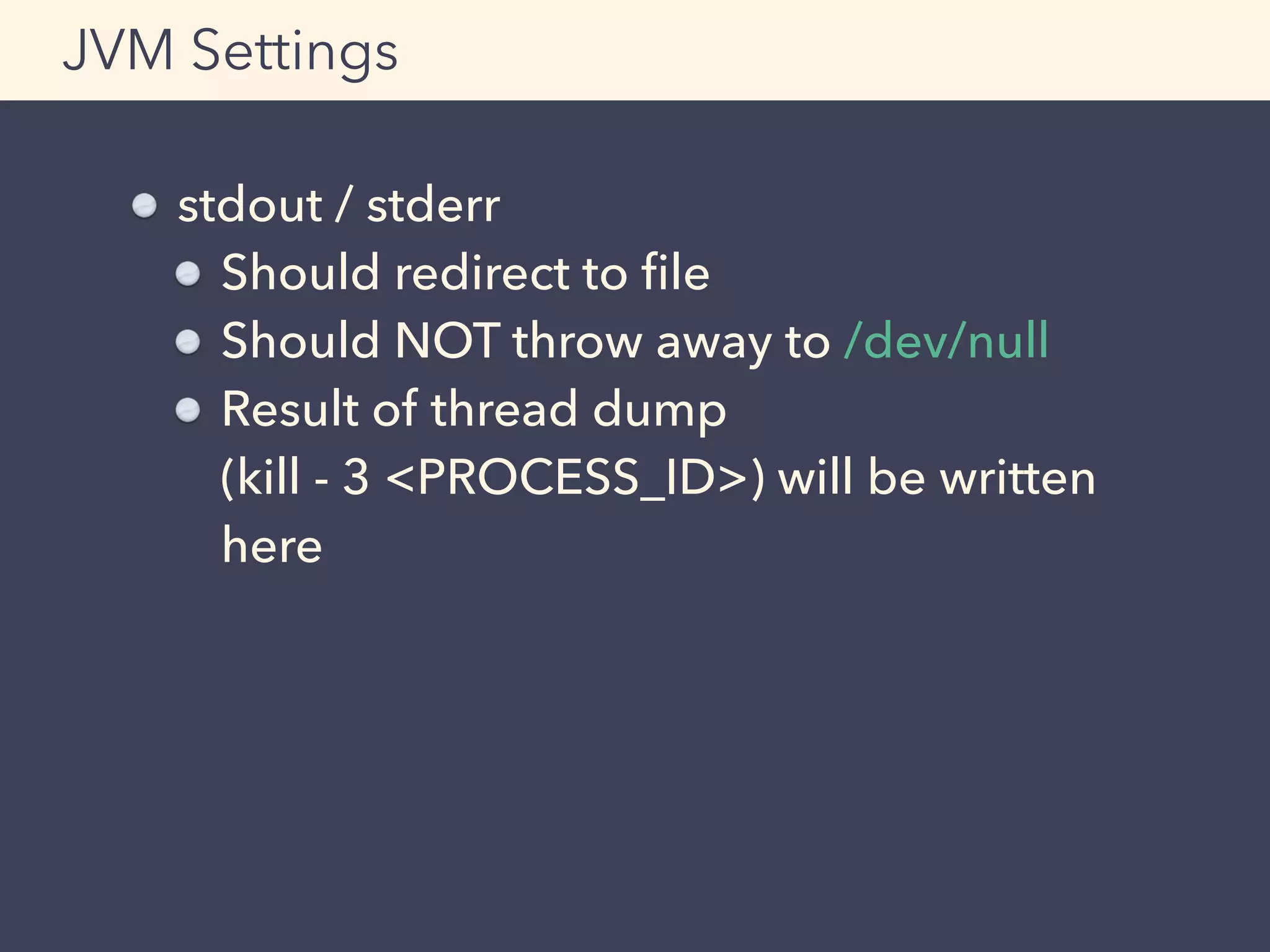

![SLF4J + Profiler
Output example
Example:
Log the result of the profiler when
timeout occurs
Profiler
+ Profiler [BASIC]
|-- elapsed time [A] 220.487 milliseconds.
|-- elapsed time [B] 2499.866 milliseconds.
|-- elapsed time [OTHER] 3300.745 milliseconds.
|-- Total [BASIC] 6022.568 milliseconds.](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01-150625101523-lva1-app6892/75/Adtech-scala-performance-tuning-150323223738-conversion-gate01-78-2048.jpg)



!["Yosuke Mizutani - Kanagawa, Japan | about.me" - http://about.me/mogproject
"mog project" - http://mogproject.blogspot.jp/
"DSS Tech Blog - Demand Side Science ㈱ の技術ブログ" - http://demand-side-
science.jp/blog/
"FunctionalNews - 関数型言語ニュースサイト" - http://functional-news.com/
"『ザ・アドテクノロジー』∼データマーケティングの基礎からアトリビューション
の概念まで∼ / 翔泳社 新刊のご紹介" - http://markezine.jp/book/adtechnology/
"オプト、ダイナミック・クリエイティブツール「unis」の提供開始 ∼ パーソナラ
イズ化された広告を自動生成し、広告効果の最大化を目指す ∼ | インターネット広
告代理店 オプト" - http://www.opt.ne.jp/news/pr/detail/id=2492
"The Scala Programming Language" - http://www.scala-lang.org/
"Finagle" - https://twitter.github.io/finagle/
"Play Framework - Build Modern & Scalable Web Apps with Java and Scala" -
https://www.playframework.com/
"nginx" - http://nginx.org/ja/
"Fluentd | Open Source Data Collector" - http://www.fluentd.org/
"Javaパフォーマンスチューニング(1):Javaパフォーマンスチューニングのルー
ル (1/2) - @IT" - http://www.atmarkit.co.jp/ait/articles/0501/29/news011.html
"パレートの法則 - Wikipedia" - http://ja.wikipedia.org/wiki/パレートの法則
"Teach Yourself Programming in Ten Years" - http://norvig.com/21-
days.html#answers
"企業が作る国際ネットワーク最前線 - [4]いまさら聞けない国際ネットワークの
基礎知識:ITpro" - http://itpro.nikkeibp.co.jp/article/COLUMN/20100119/
343461/
"Coursera" - https://www.coursera.org/course/reactive
"アースマラソン - Wikipedia" - http://ja.wikipedia.org/wiki/アースマラソン
"Hard disk drive - Wikipedia, the free encyclopedia" - http://en.wikipedia.org/
wiki/Hard_disk_drive
"Everything I ever learned about JVM performance tuning @twitter(Attila
Szegedi).pdf" - http://www.beyondlinux.com/files/pub/qconhangzhou2011/
Everything%20I%20ever%20learned%20about%20JVM%20performance
%20tuning%20@twitter%28Attila%20Szegedi%29.pdf
"Amazon.co.jp: C++ Coding Standards―101のルール、ガイドライン、ベストプ
ラクティス (C++ in-depth series): ハーブ サッター, アンドレイ アレキサンドレス
ク, 浜田 光之, Herb Sutter, Andrei Alexandrescu, 浜田 真理: 本" - http://
www.amazon.co.jp/gp/product/4894716860
"UNIX哲学 - Wikipedia" - http://ja.wikipedia.org/wiki/UNIX哲学
"ktoso/sbt-jmh" - https://github.com/ktoso/sbt-jmh
"ScalaBlitz | ScalaBlitz" - http://scala-blitz.github.io/
"Parleys.com - Lightning-Fast Standard Collections With ScalaBlitz by Dmitry
Petrashko" - https://parleys.com/play/53a7d2c6e4b0543940d9e549/chapter0/
about
"mog project: Micro Benchmark in Scala - Using sbt-jmh" - http://
mogproject.blogspot.jp/2014/10/micro-benchmark-in-scala-using-sbt-jmh.html
"Gatling Project, Stress Tool" - http://gatling.io/
"WEB+DB PRESS Vol.83|技術評論社" - http://gihyo.jp/magazine/wdpress/
archive/2014/vol83
"「Javaの鉱脈」でGatlingの記事を書きました — さにあらず" - http://
blog.satotaichi.info/gatling-is-awesome-loadtester
"Garbage Collection Tuning in the Java HotSpot™ Virtual Machine" - http://
www.oracle.com/technetwork/server-storage/ts-4887-159080.pdf
"SLF4J extensions" - http://www.slf4j.org/extensions.html
"Graphite Documentation — Graphite 0.10.0 documentation" - http://
graphite.readthedocs.org/en/latest/
"Grafana - Graphite and InfluxDB Dashboard and graph composer" - http://
grafana.org/
"Grafana - Grafana Play Home" - http://play.grafana.org/#/dashboard/db/
grafana-play-home
"不動産関係に使える 無料画像一覧" - http://free-realestate.org/information/
list.html
"AI・EPSの無料イラストレーター素材なら無料イラスト素材.com" - http://www.無
料イラスト素材.com/
"大体いい感じになるKeynoteテンプレート「Azusa」作った - MEMOGRAPHIX" -
http://memo.sanographix.net/post/82160791768
References](https://image.slidesharecdn.com/adtech-scala-performance-tuning-150323223738-conversion-gate01-150625101523-lva1-app6892/75/Adtech-scala-performance-tuning-150323223738-conversion-gate01-83-2048.jpg)

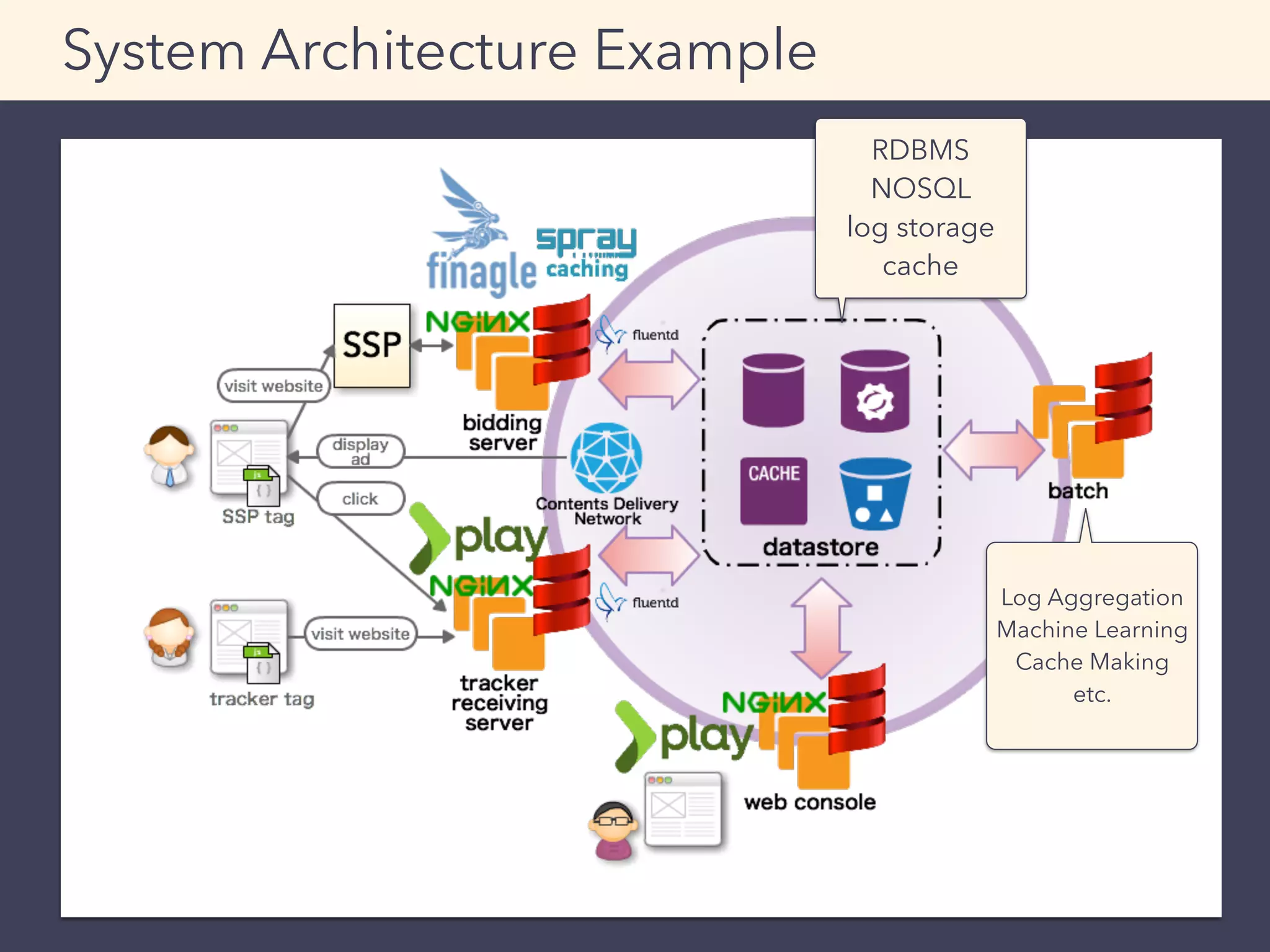
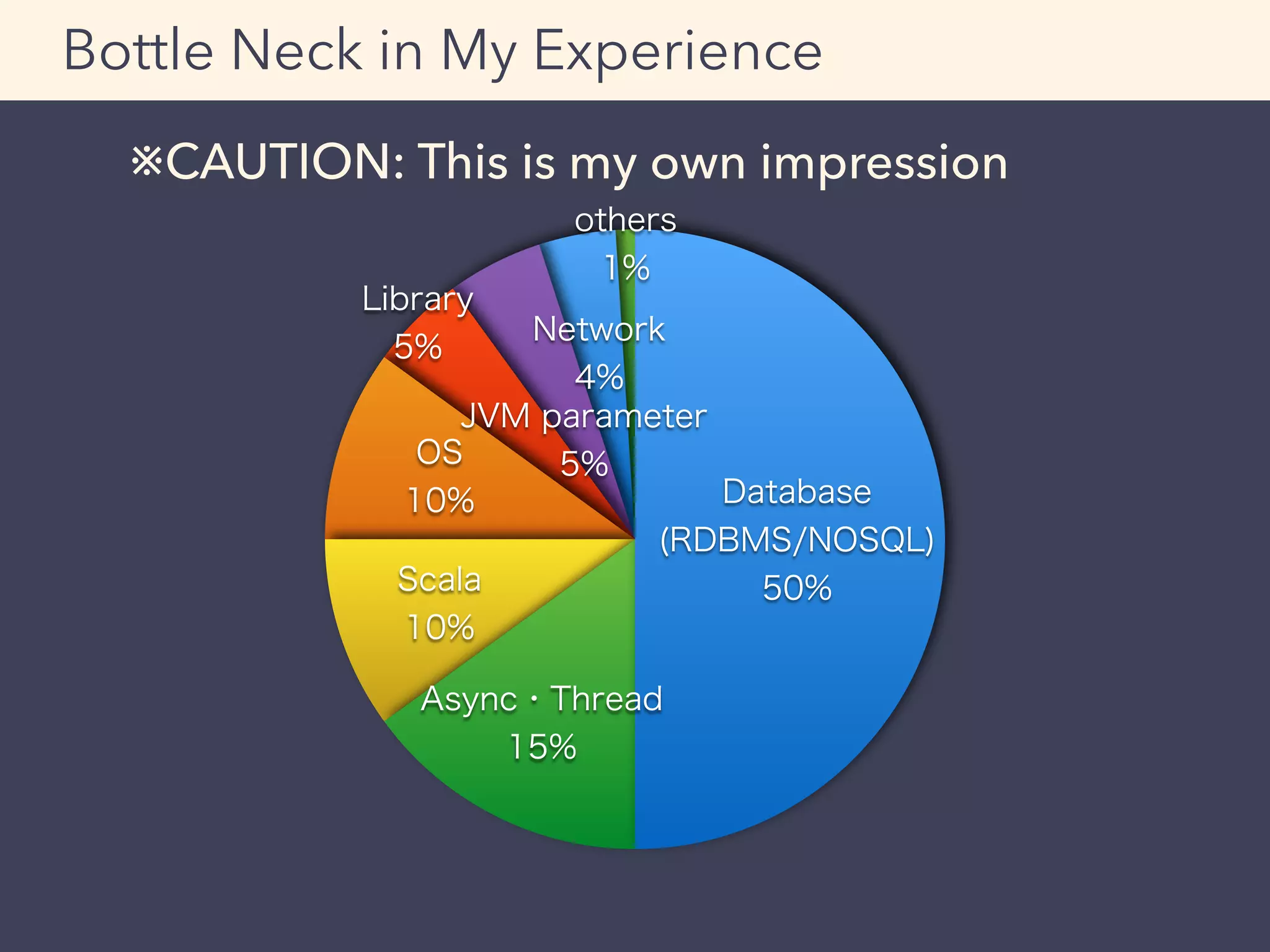
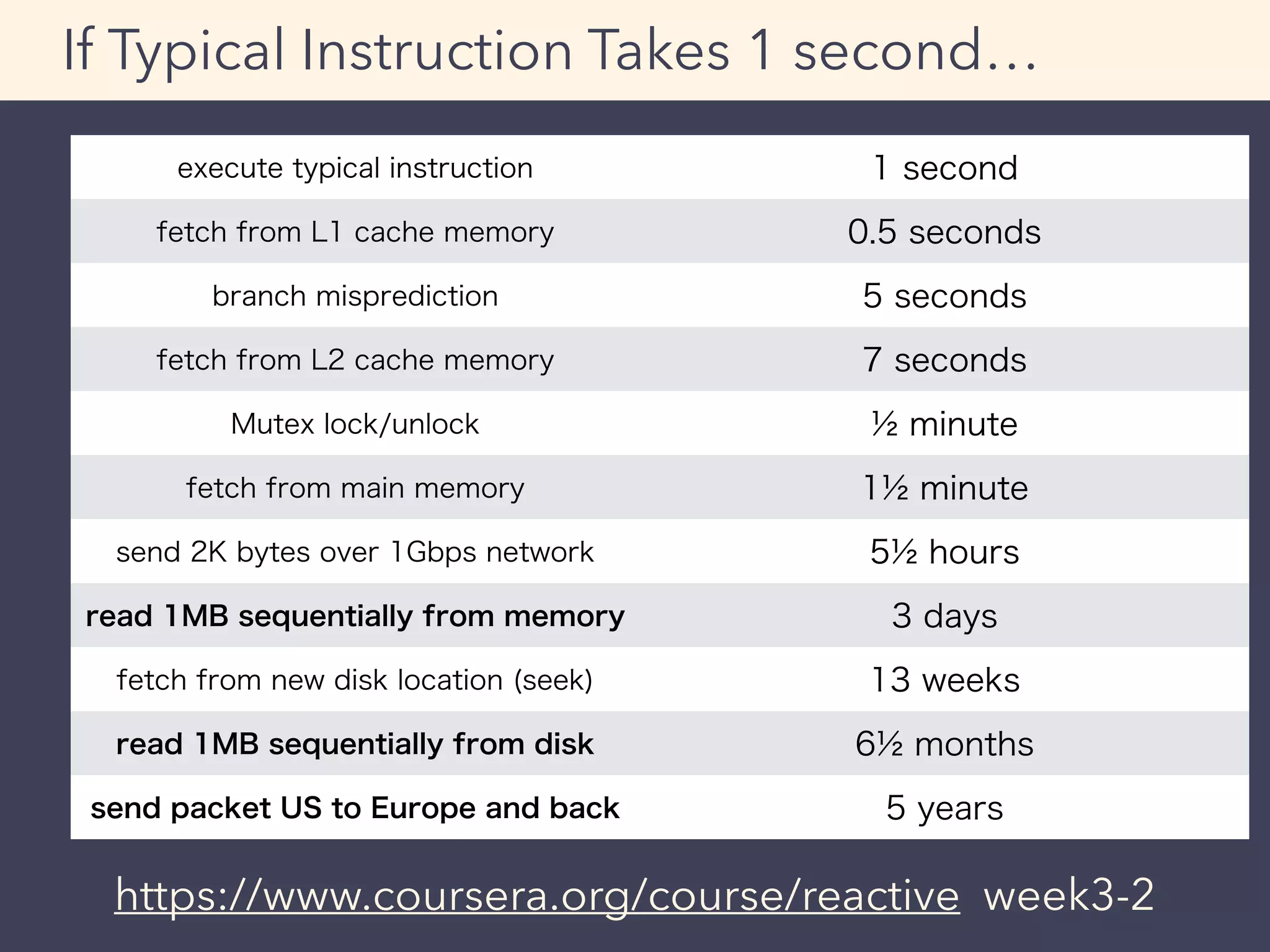
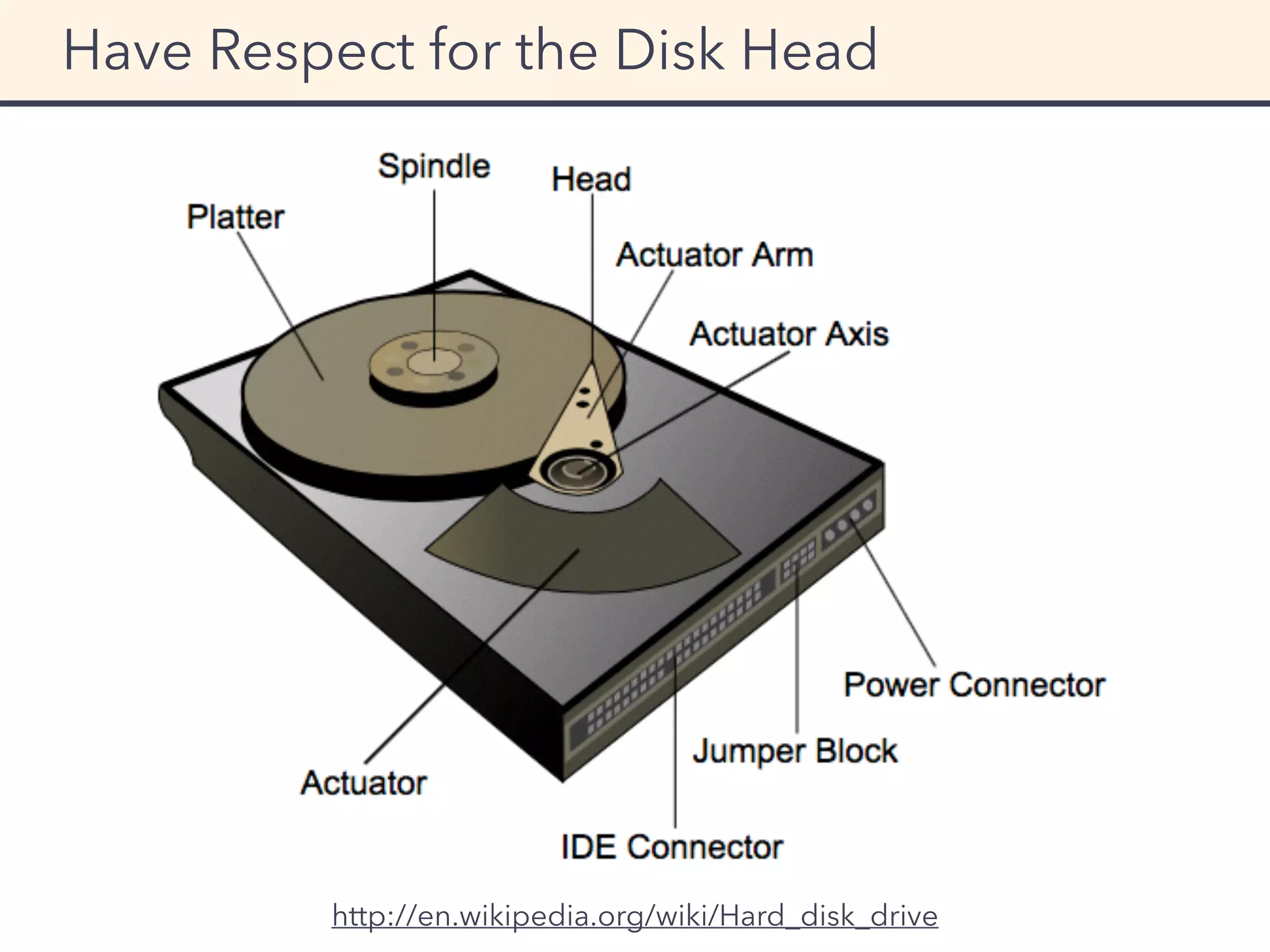
This document provides an overview of performance tuning best practices for Scala applications. It discusses motivations for performance tuning such as resolving issues or reducing infrastructure costs. Some common bottlenecks are identified as databases, asynchronous/thread operations, and I/O. Best practices covered include measuring metrics, identifying bottlenecks, and avoiding premature optimization. Microbenchmarks and optimization examples using Scala collections are also presented.















































