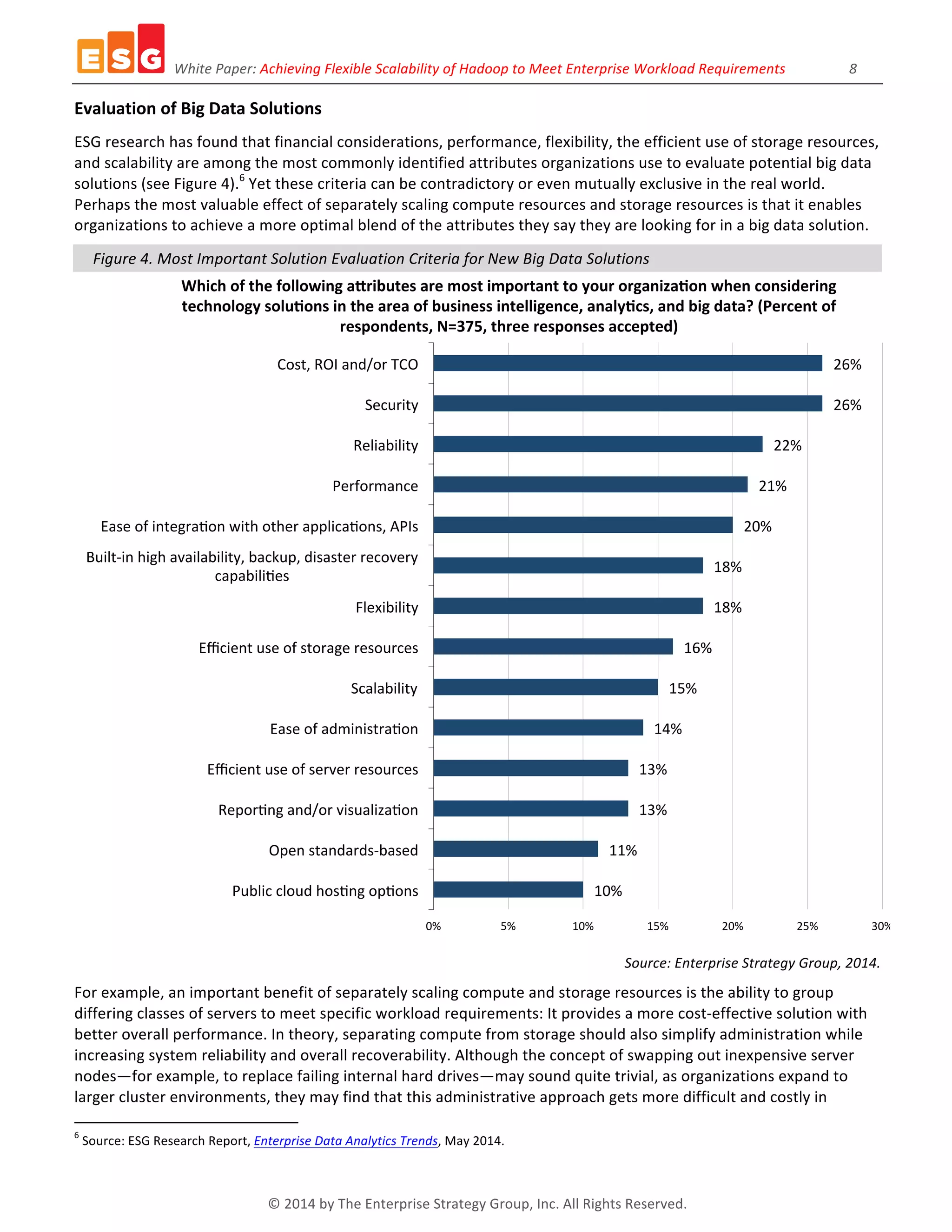
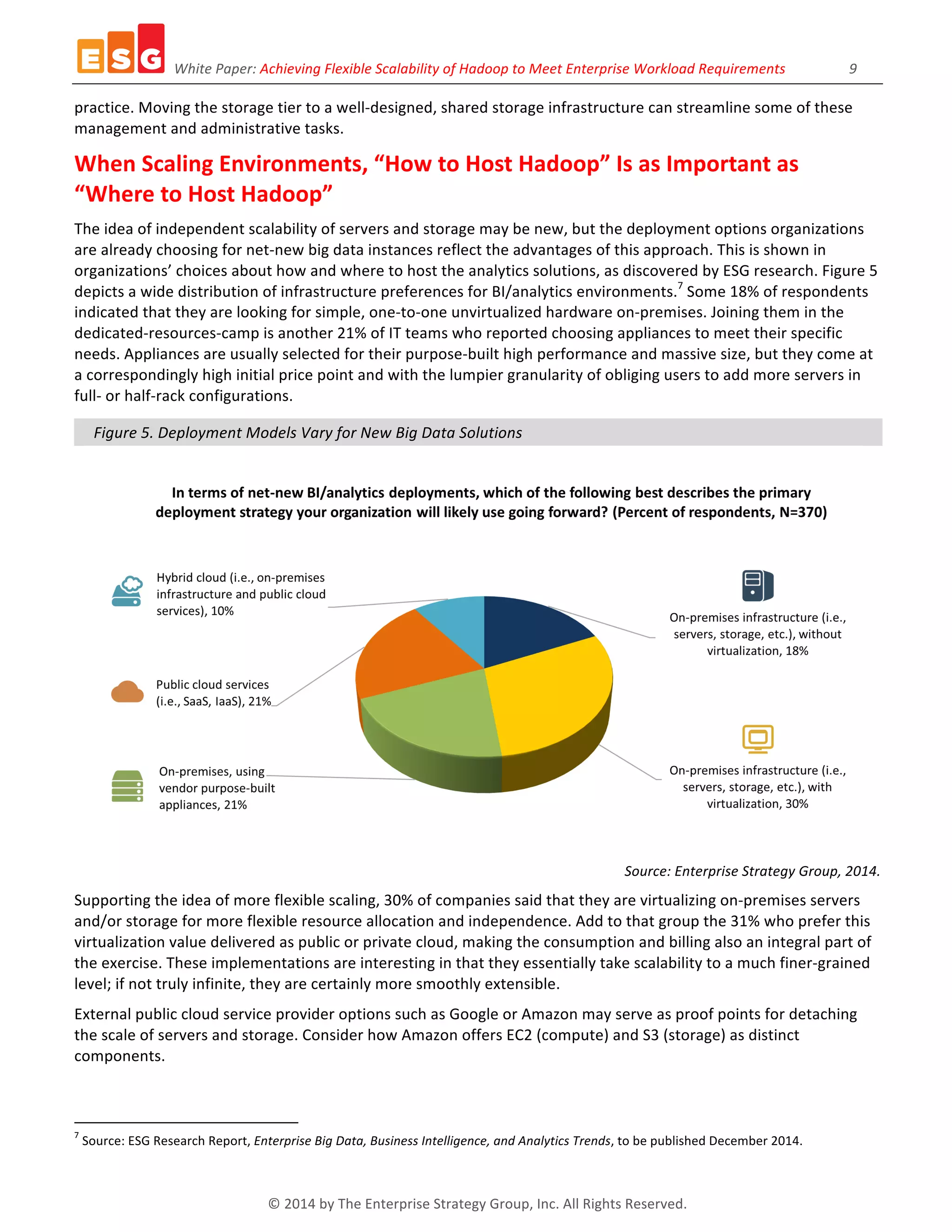
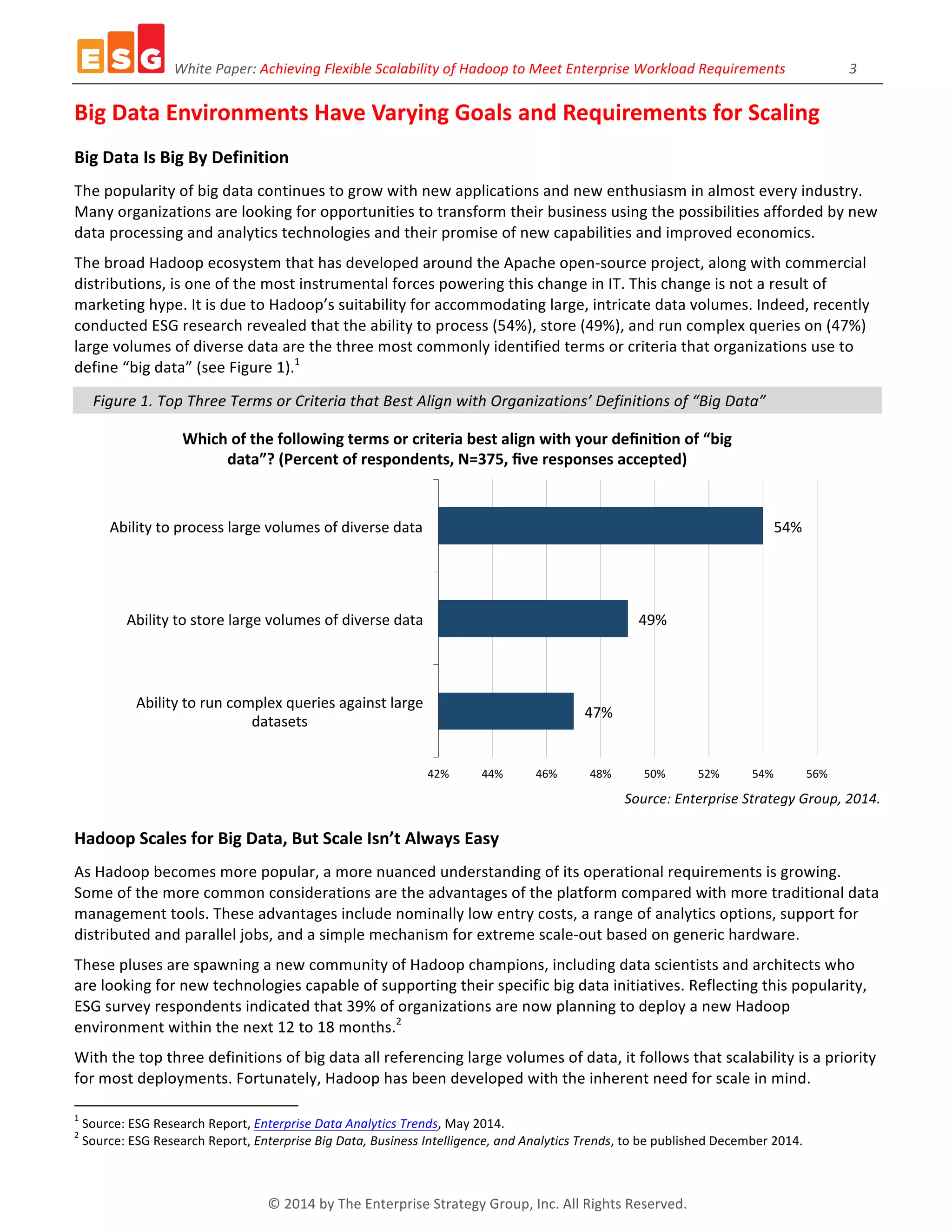
The white paper discusses the need for flexible scalability in Hadoop to meet diverse enterprise workload requirements, highlighting the complexities of scaling big data environments. It identifies challenges associated with storage, performance, and data diversity, while suggesting that independent scaling of servers and storage can optimize resource utilization. Recommendations emphasize the importance of evaluating Hadoop implementations based on specific workload demands and organizational goals.





![White
Paper:
Achieving
Flexible
Scalability
of
Hadoop
to
Meet
Enterprise
Workload
Requirements
7
©
2014
by
The
Enterprise
Strategy
Group,
Inc.
All
Rights
Reserved.
This
model,
in
which
servers
and
storage
capacity
are
embedded
together
as
“one
size
fits
all”
units
and
forced
to
scale
linearly
in
a
homogenous
cluster,
can
potentially
waste
a
lot
of
resources.
No
single
configuration
of
server
may
be
able
to
handle
the
various
workloads
(again
noting
that
particular
jobs
can
be
limited
by
system
memory,
processor
speed,
or
storage
capacity).
And
of
course,
increasing
any
one
of
these
components
will
have
an
effect
on
the
overall
price
of
each
node.
Over-‐provisioning
all
three
may
sound
good
for
performance,
but
this
“bigger
hammer”
approach
will
adversely
and
dramatically
increase
the
total
costs
of
the
environment
and
obviate
the
commodity-‐scale
benefits
of
Hadoop.
A
promising
approach
is
the
separation
of
servers
and
storage
into
pools
of
resources
to
be
drawn
on
as
needed
(see
Figure
3).
This
division
between
scaling
storage
capacity
and
computing
power
enables
more
targeted
scalability
to
satisfy
specific
demands
associated
with
different
workloads.
The
approach
may
also
require
the
adoption
of
a
shared
storage
platform,
which
is
not
the
most
common
model
for
Hadoop,
but
it
brings
with
it
many
of
the
key
qualities
organizations
say
they
want
(such
as
a
balance
across
cost,
performance,
flexibility,
and
data
protection
considerations).
And,
even
in
a
basic
MapReduce
operation,
data
is
often
migrated
and
joined
in
performing
typical
jobs
so
the
facility
can
be
accommodated,
just
with
a
different
route
for
accessing
storage.
An
independent
server-‐scaling
strategy
complements
the
many
advantages
of
centralized,
shared
storage,
which
ESG
previously
outlined
in
a
white
paper
titled
EMC
Isilon:
A
Scalable
Storage
Platform
for
Big
Data
(April
2014).
Some
benefits
of
this
approach
include
(but
are
not
limited
to)
multi-‐protocol
access,
in-‐place
analytics
(i.e.,
no
extract,
transform,
load
[ETL]),
and
better
efficiency
and
safety.
If
one
views
the
Hadoop
cluster
servers
essentially
as
virtualized
resources,
this
computing
power
then
can
be
used
to
access
different
storage
as
needed.
Effectively,
this
model
can
be
viewed
as
a
logical
independence
versus
a
necessarily
physical
distinction,
and
one
needn’t
assume
the
physical
layer
itself
is
virtualized
for
the
solution
to
be
workable.
In
fact,
this
pattern
has
arisen
in
computing
history
before,
with
isolated,
locally
embedded
storage.
The
storage
is
eventually
replaced
or
augmented
with
much
larger
centralized
pools
of
resources
shared
between
servers,
proving
that
hyper-‐convergence
doesn’t
always
lead
to
optimal
utilization.
Figure
3.
Diagram
of
Storage
Hosting
Options
for
Hadoop
Source:
Enterprise
Strategy
Group,
2014.](https://image.slidesharecdn.com/esg-emc-achieving-flexible-scaling-hadoop-141225085016-conversion-gate01/75/Achieving-Flexible-Scalability-of-Hadoop-to-Meet-Enterprise-Workload-Requirements-7-2048.jpg)