[NS][Lab_Seminar_250609]Audio-Visual Semantic Graph Network for Audio-Visual Event Localization.pptx
1.
Audio-Visual Semantic Graph
Networkfor Audio-Visual Event
Localization
Tien-Bach-Thanh Do
Network Science Lab
Dept. of Artificial Intelligence
The Catholic University of Korea
E-mail: osfa19730@catholic.ac.kr
2025/06/09
Liang Liu et al.
CVPR 2025
2.
2
Introduction
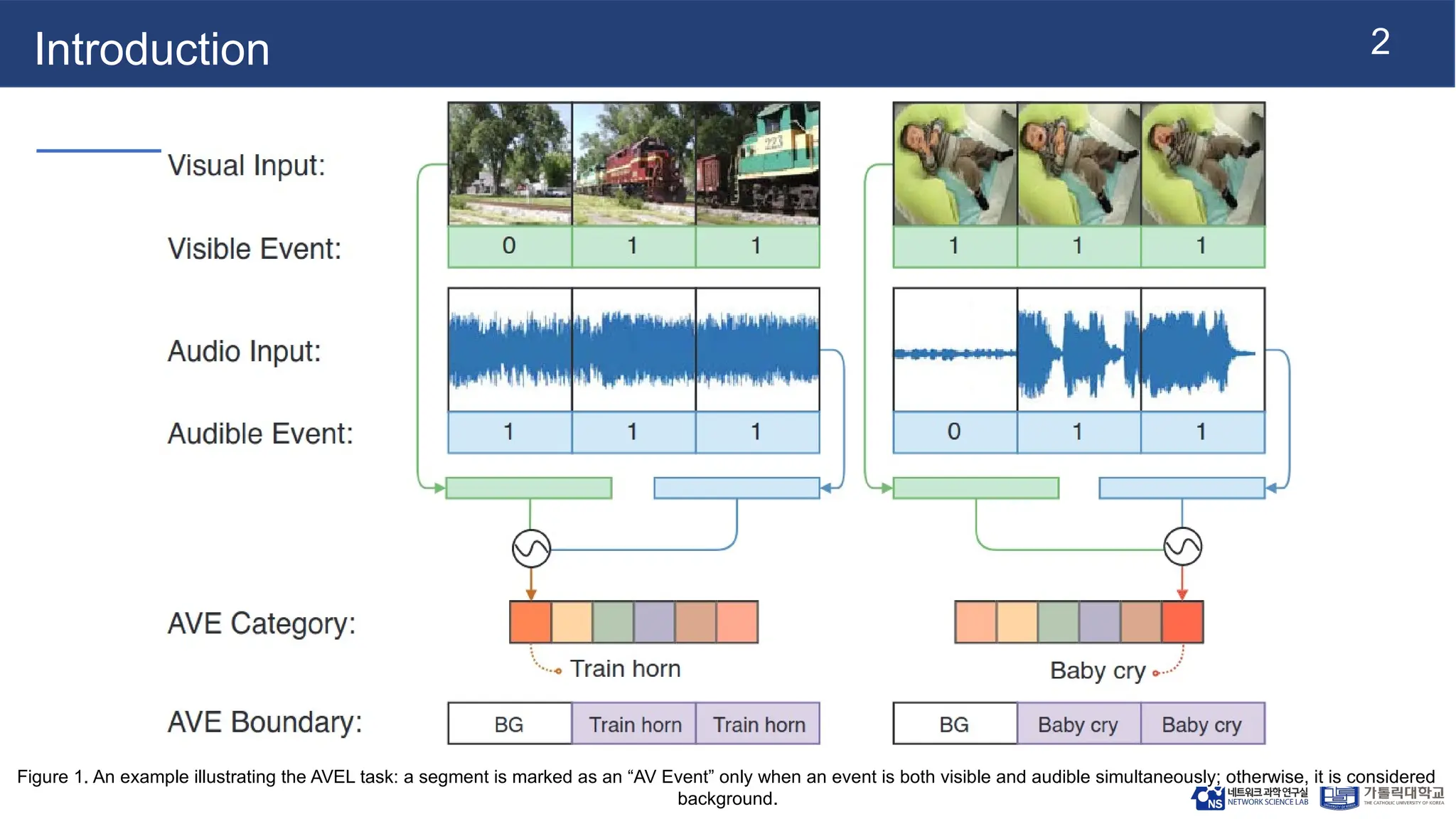
Figure 1. Anexample illustrating the AVEL task: a segment is marked as an “AV Event” only when an event is both visible and audible simultaneously; otherwise, it is considered
background.
3.
3
Introduction
Audio-Visual Event Localization(AVEL)
● Human Perception & Machine Emulation: Humans naturally integrate multiple senses, especially vision and
hearing, to understand their surroundings. Audio-visual learning aims to enable intelligent machines to emulate
this capability for perception, reasoning, and decision-making
● What is AVEL?
○ A prominent area within audio-visual learning
○ Goal: Identify events that are both audible and visible simultaneously in unconstrained videos
○ Tasks Involved:
■ Classifying event categories (e.g., "car driving," "dog barking")
■ Accurately determining their temporal boundaries
● Examples: A segment is an "AV Event" only if both visible and audible events occur simultaneously; otherwise, it's
considered background. For instance, a "Train horn" event involves both the visual presence of a train and the
audible horn
● Applications: Intelligent surveillance, human-computer interaction, and multimedia retrieval
4.
4
Introduction
Challenges
● Semantic Gap:The primary challenge is the inherent semantic gap between heterogeneous modalities (audio and
visual). This often leads to audio-visual semantic inconsistency
● Temporal Inconsistencies: Existing methods struggle with capturing cross-temporal dependencies sufficiently
● Limitations of Previous Approaches:
○ Many rely on unimodal-guided attention (e.g., audio-guided, visual-guided) which may overlook the potential
of one modality to guide the other
○ These methods can introduce redundant or event-irrelevant information
○ While multimodal adaptive fusion and semantic consistency modeling have shown effectiveness, they still
face challenges in establishing robust cross-modal semantic consistency and temporal dependencies
5.
5
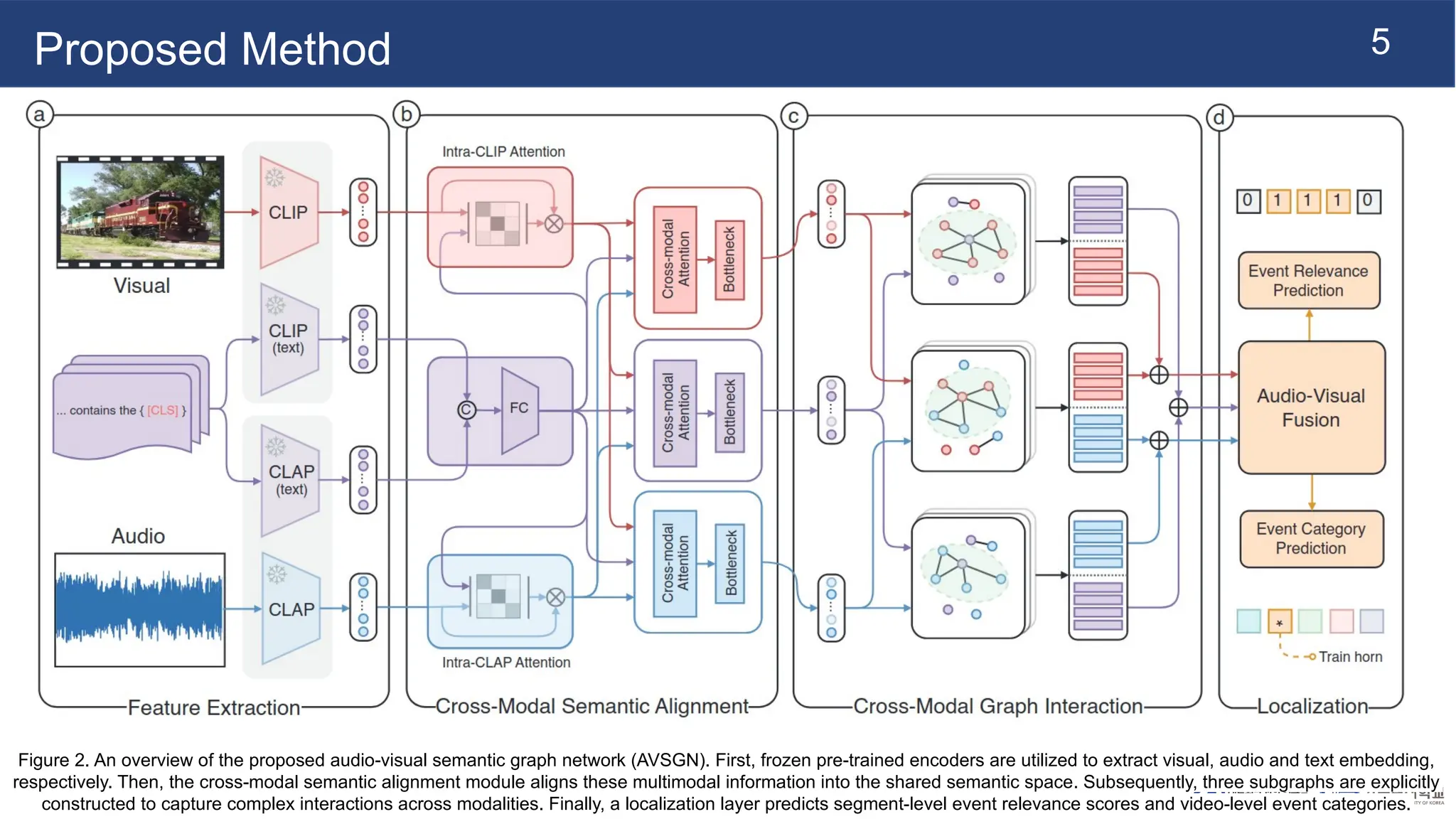
Proposed Method
Figure 2.An overview of the proposed audio-visual semantic graph network (AVSGN). First, frozen pre-trained encoders are utilized to extract visual, audio and text embedding,
respectively. Then, the cross-modal semantic alignment module aligns these multimodal information into the shared semantic space. Subsequently, three subgraphs are explicitly
constructed to capture complex interactions across modalities. Finally, a localization layer predicts segment-level event relevance scores and video-level event categories.
7
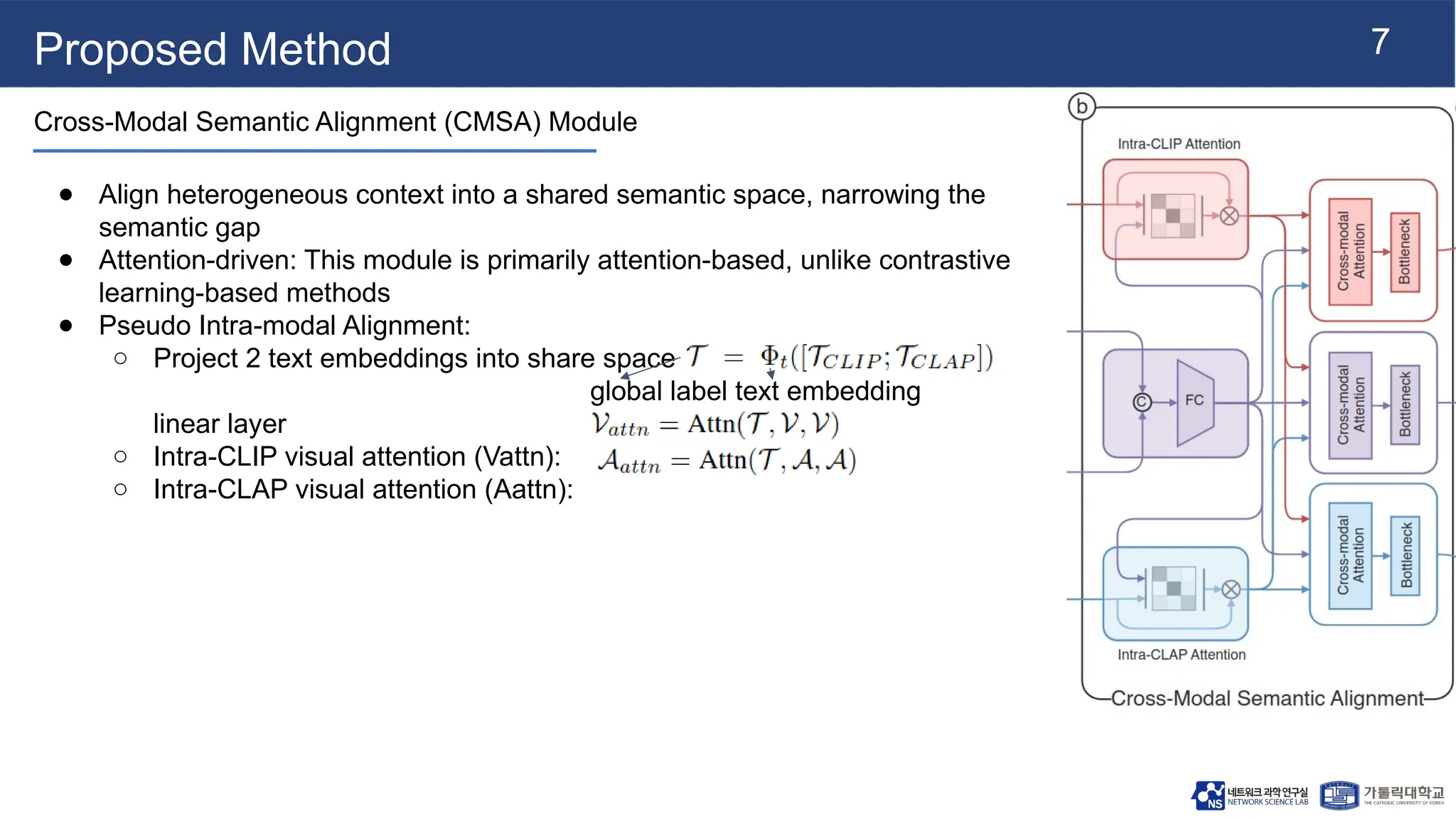
Proposed Method
Cross-Modal SemanticAlignment (CMSA) Module
● Align heterogeneous context into a shared semantic space, narrowing the
semantic gap
● Attention-driven: This module is primarily attention-based, unlike contrastive
learning-based methods
● Pseudo Intra-modal Alignment:
○ Project 2 text embeddings into share space
global label text embedding
linear layer
○ Intra-CLIP visual attention (Vattn):
○ Intra-CLAP visual attention (Aattn):
8.
8
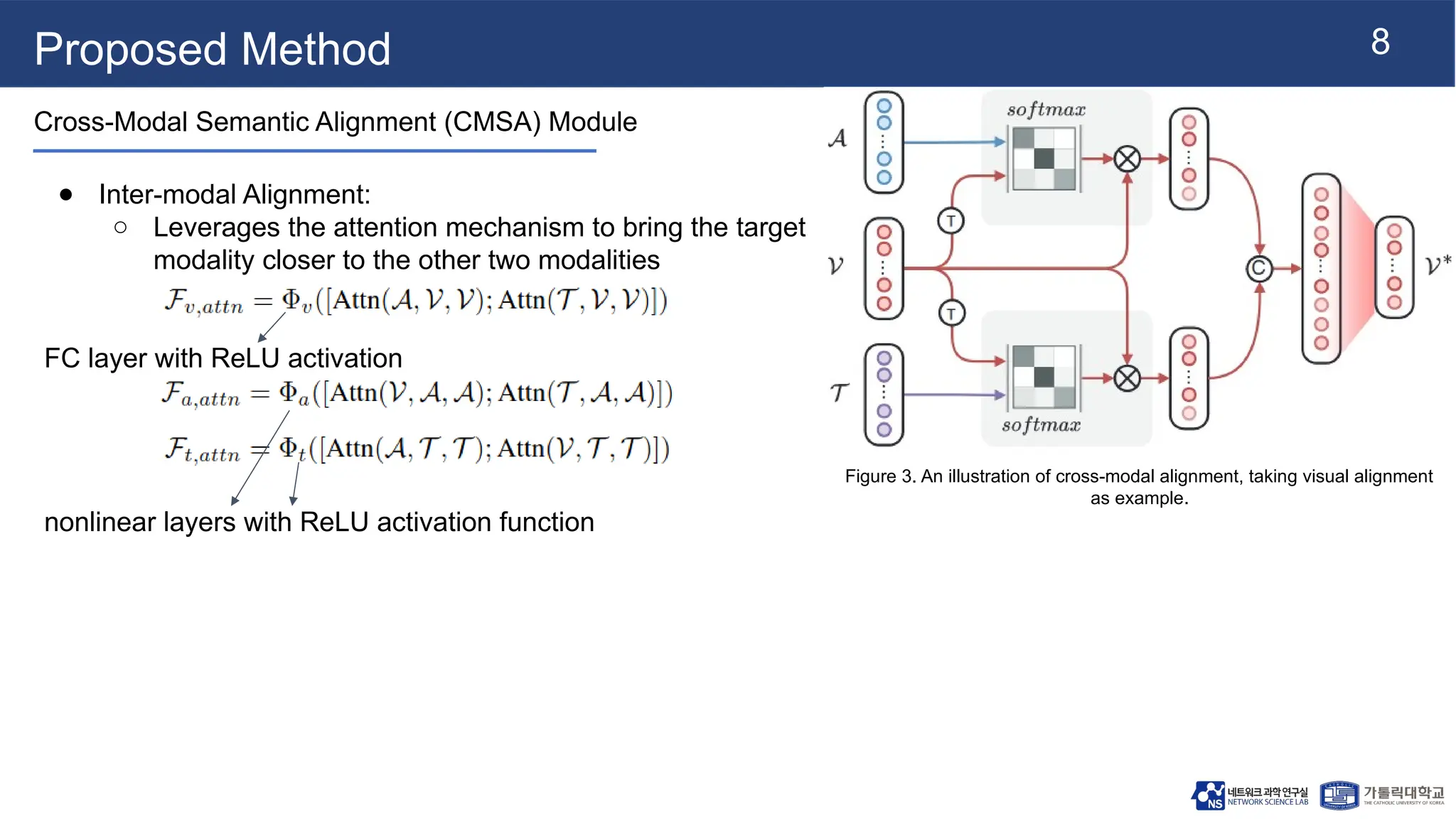
Proposed Method
Cross-Modal SemanticAlignment (CMSA) Module
● Inter-modal Alignment:
○ Leverages the attention mechanism to bring the target
modality closer to the other two modalities
FC layer with ReLU activation
nonlinear layers with ReLU activation function
Figure 3. An illustration of cross-modal alignment, taking visual alignment
as example.
9.
9
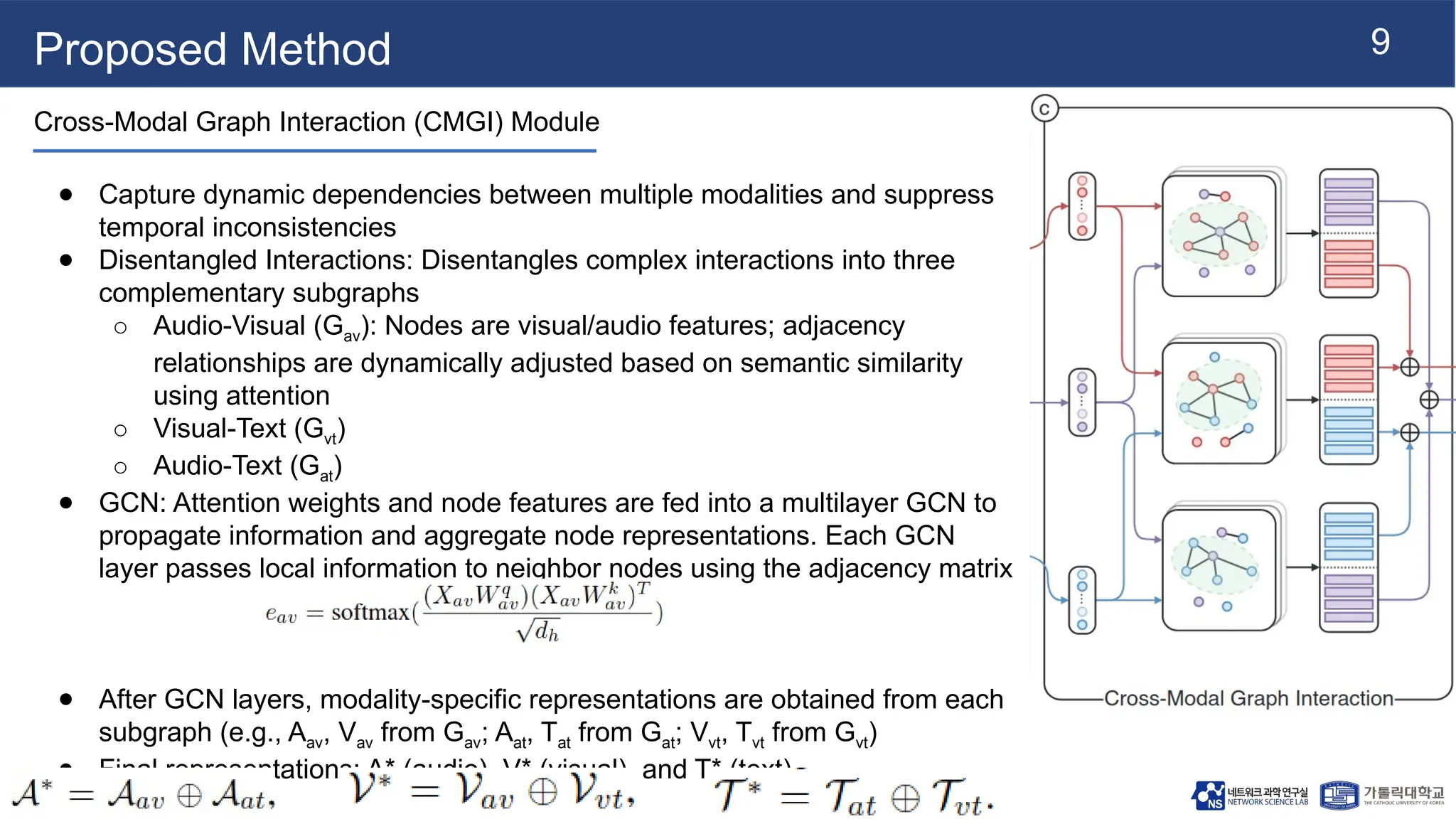
Proposed Method
Cross-Modal GraphInteraction (CMGI) Module
● Capture dynamic dependencies between multiple modalities and suppress
temporal inconsistencies
● Disentangled Interactions: Disentangles complex interactions into three
complementary subgraphs
○ Audio-Visual (Gav): Nodes are visual/audio features; adjacency
relationships are dynamically adjusted based on semantic similarity
using attention
○ Visual-Text (Gvt)
○ Audio-Text (Gat)
● GCN: Attention weights and node features are fed into a multilayer GCN to
propagate information and aggregate node representations. Each GCN
layer passes local information to neighbor nodes using the adjacency matrix
● After GCN layers, modality-specific representations are obtained from each
subgraph (e.g., Aav, Vav from Gav; Aat, Tat from Gat; Vvt, Tvt from Gvt)
● Final representations: A* (audio), V* (visual), and T* (text)
10.
10
Proposed Method
Classification
● GatedMechanism: A gated mechanism integrates complementary information from the
discriminative audio (A*) and visual (V*) embeddings
● Fully-supervised AVEL Task:
○ Video-level category prediction (sc) and segment-level relevance prediction (st)
○ Losses:
event-relevant loss event category loss
gate losssegment loss
● Weakly-supervised AVE Task:
11.
11
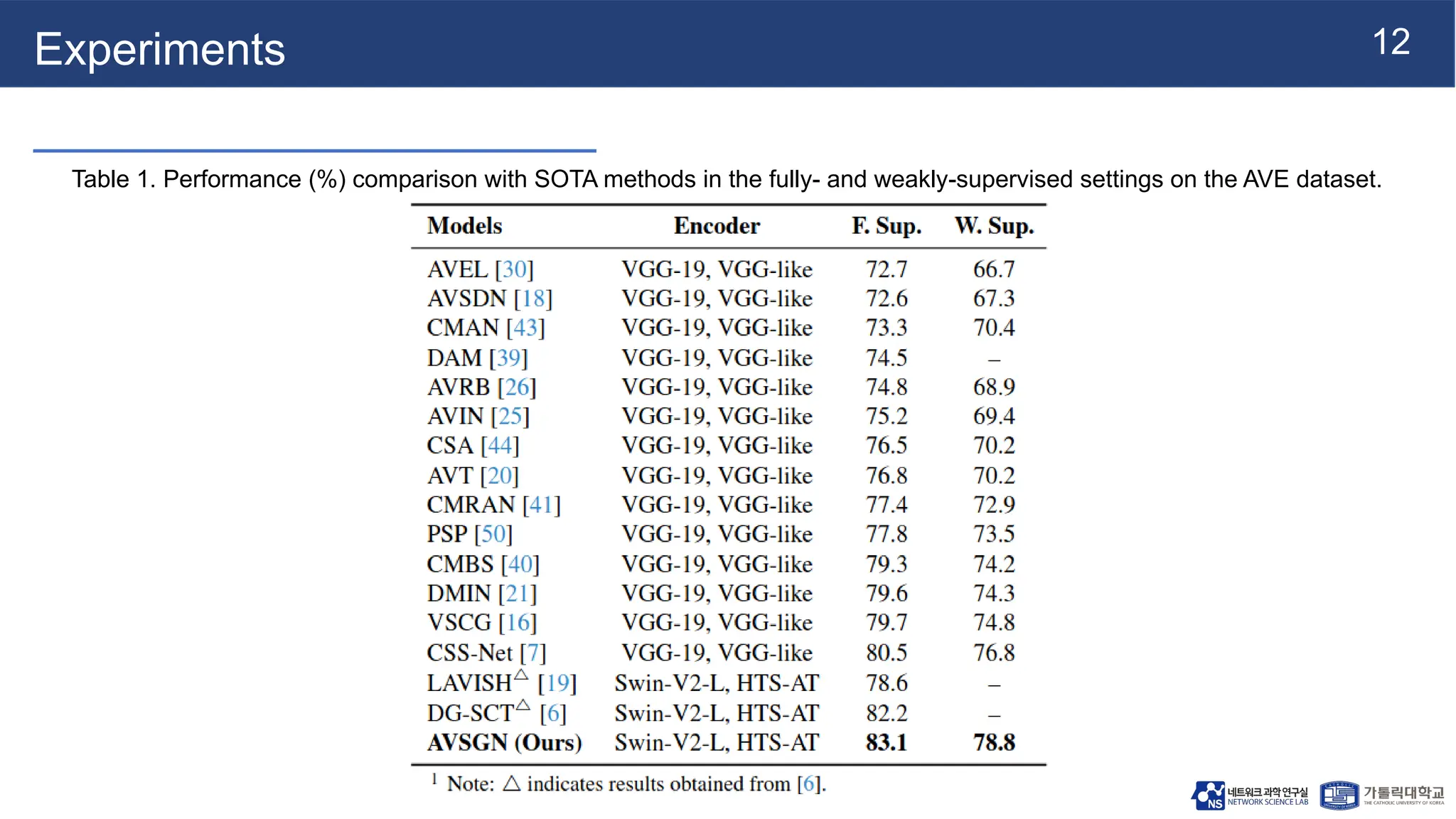
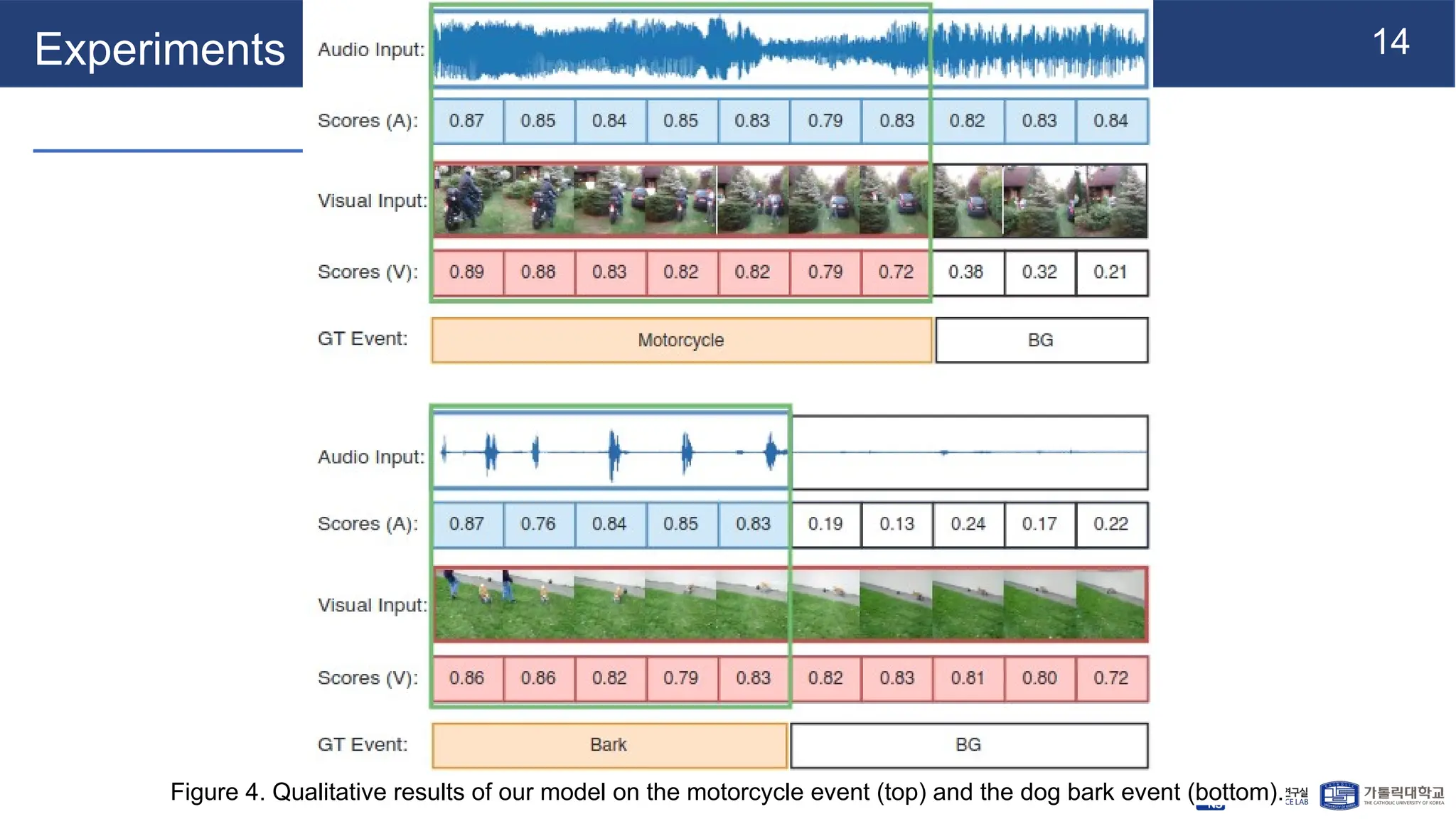
Experiments
● Dataset
○ AVEfrom AudioSet
■ 4,143 videos across 28 categories (dog barking, helicopter, acoustic guitar)
● Each video is divided into 10 one-second segments
● Provides both segment-level AVE labels and video-level event category labels
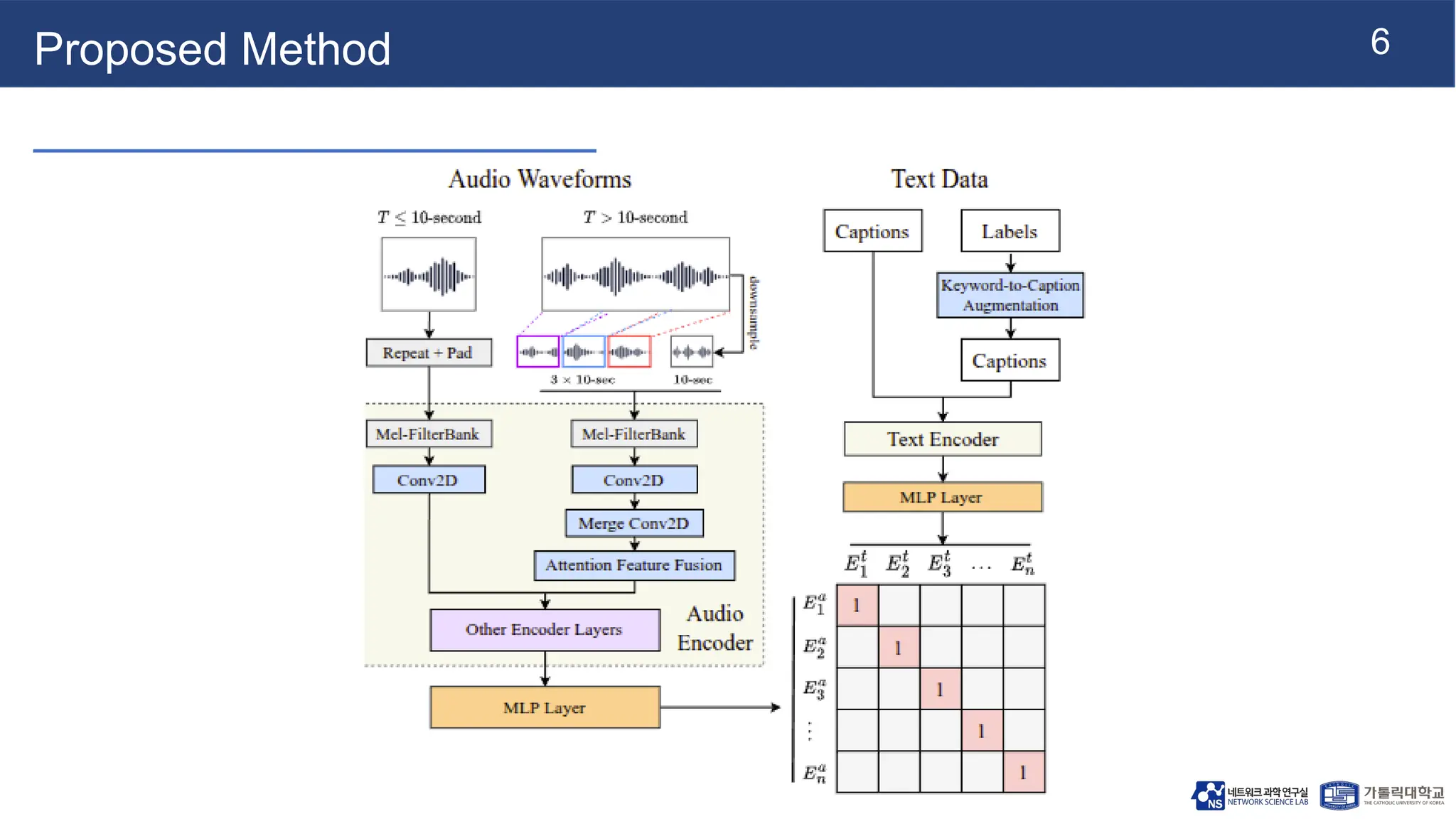
● Implementation Details:
○ Encoders: Frozen Swin-V2-L-based CLIP for visual features and HTS-AT-based CLAP for audio
features, both providing 512D embeddings. Text embeddings from CLIP and CLAP
○ Optimizer: Adam with batch size 64
○ Hyperparameters: τ (threshold) defaults to 0.6, λ (hyperparameter for semantic consistency loss)
defaults to 0.01
13
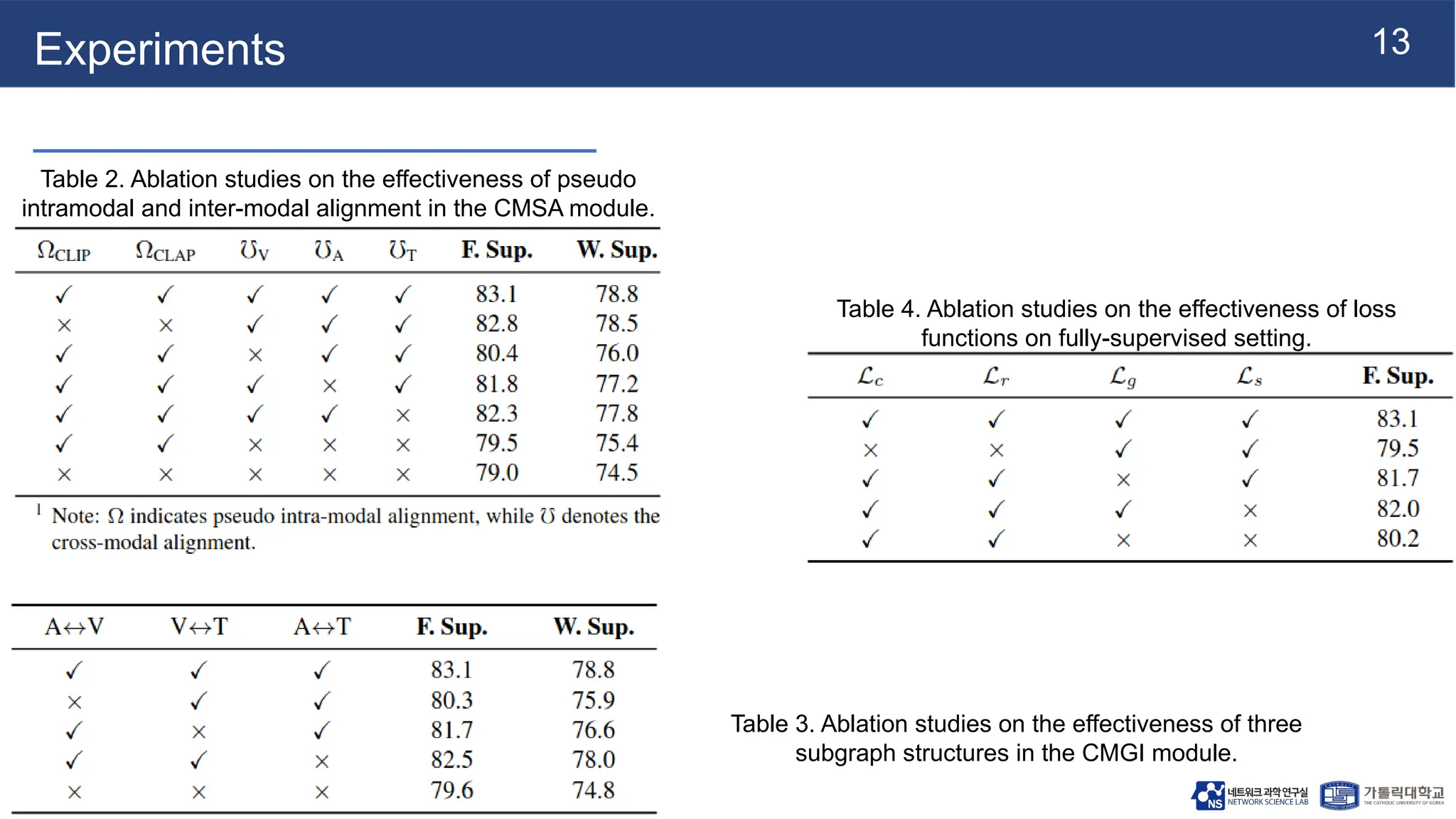
Experiments
Table 2. Ablationstudies on the effectiveness of pseudo
intramodal and inter-modal alignment in the CMSA module.
Table 3. Ablation studies on the effectiveness of three
subgraph structures in the CMGI module.
Table 4. Ablation studies on the effectiveness of loss
functions on fully-supervised setting.
15
Experiments
Figure 5. Illustrationof feature distributions using t-SNE [31] in fully-supervised learning. The first row shows the distribution of audio
features after different components, while the second row shows the distribution of visual features.
16.
16
Conclusion
● Introduces anovel Audio-Visual Semantic Graph Network (AVSGN) to address audio-visual inconsistency in
AVEL
● Cross-Modal Semantic Alignment (CMSA) module: Bridges the semantic gap by introducing shared semantic
labels, promoting multimodal representation convergence into a shared semantic space
● Cross-Modal Graph Interaction (CMGI) module: Disentangles complex interactions into three complementary
subgraphs (audio-text, audio-visual, visual-text) to effectively capture cross-temporal semantic interactions
and suppress temporal inconsistencies
● Future Directions: The framework can be extended to other related multimodal tasks, such as audio-visual
video parsing (AVVP), where the advantages of a graph-based model could more effectively handle multi-
modal, multi-instance tasks





![15
Experiments
Figure 5. Illustration of feature distributions using t-SNE [31] in fully-supervised learning. The first row shows the distribution of audio
features after different components, while the second row shows the distribution of visual features.](https://image.slidesharecdn.com/nslabseminar250609avsgn-250609200005-6fb5812c/75/NS-Lab_Seminar_250609-Audio-Visual-Semantic-Graph-Network-for-Audio-Visual-Event-Localization-pptx-15-2048.jpg)





























![251124_Thanh_LabSeminar[Hyper-YOLO].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thanhlabseminarhyper-yolo-251124113258-535062b4-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NS][Lab_Seminar_251020]HyperGLM: HyperGraph for Video Scene Graph Generation...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251020hyperglm-251020095526-46c0e264-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251201]High-Precision Mixed Feature Fusion Network Using Hyp...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251201mlf-snet-251206120538-22fa2497-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251027]From Pixels to Graphs: Open-Vocabulary Scene Graph Ge...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251027pgsg-251027105020-631aebf6-thumbnail.jpg?width=640&height=640&fit=bounds)
![251124_HW_LabSeminar[Multimodal-SCM].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124hwlabseminarmultimodal-scm-251124113300-6fad72e4-thumbnail.jpg?width=640&height=640&fit=bounds)

![251103_Thanh_LabSeminar[One Last Attention for Your Vision-Language Model].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thanhlabseminarrada-251103113308-f66fee0b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NS][Lab_Seminar_251110]ControlMLLM.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar251110controlmllm-251110090012-39bbf00d-thumbnail.jpg?width=640&height=640&fit=bounds)
![251124_Thuy_Labseminar[Vision GNN: An Image is Worth Graph of Nodes].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251124thuylabseminar-251124113257-025487fe-thumbnail.jpg?width=640&height=640&fit=bounds)

![251103_Thuy_Labseminar[Grounded Language-Image Pre-training].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103thuylabseminar-251103113311-941d56eb-thumbnail.jpg?width=640&height=640&fit=bounds)
![251110_HW_LabSeminar[WHAT TO ALIGN IN MULTIMODAL CONTRASTIVE LEARNING?].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251110hwlabseminarcomm-251110103747-14b1b798-thumbnail.jpg?width=640&height=640&fit=bounds)
![251103_SH_LabSeminar[Expressiveness of Graph Neural Networks].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251103shlabseminarppgn-251103113317-1094e696-thumbnail.jpg?width=640&height=640&fit=bounds)
![251027_Thuy_Labseminar[Scaling Language-Image Pre-training via Masking].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/251027thuylabseminar-251027105015-a1b9f3e8-thumbnail.jpg?width=640&height=640&fit=bounds)
























