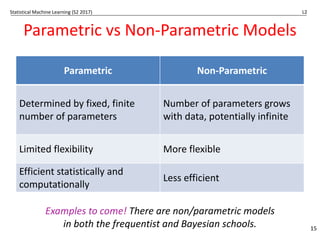
The document outlines key concepts in statistical machine learning, focusing on frequentist and Bayesian statistics. It discusses methods for parameter estimation, including maximum-likelihood estimation, and contrasts generative and discriminative models. The lecture emphasizes different evaluation metrics and the philosophical differences between frequentist and Bayesian approaches to statistical inference.




![Statistical Machine Learning (S2 2017) L2
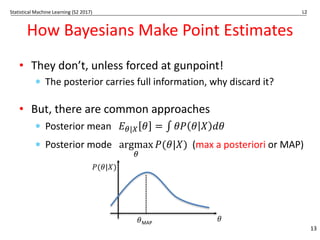
How do Frequentists Evaluate Estimators?
• Bias: 𝐵# 𝜃
3 = 𝐸# 𝜃
3 𝑋-, … , 𝑋0 − 𝜃
• Variance: 𝑉𝑎𝑟# 𝜃
3 = 𝐸# (𝜃
3 − 𝐸#[𝜃
3])=
* Efficiency: estimate has minimal variance
• Square loss vs bias-variance
𝐸# 𝜃 − 𝜃
3 =
= [𝐵(𝜃)]=
+𝑉𝑎𝑟#(𝜃
3)
• Consistency: 𝜃
3 𝑋-, … , 𝑋0 converges to 𝜃 as n gets
big
… more on this later in the subject …
4
Subscript q
means data really
comes from pq
𝜃
* still function of
data](https://image.slidesharecdn.com/02statisticalschools2-250109164259-a8400b9b/85/A-presentation-about-machine-learning-and-NN-4-320.jpg)