Downloaded 29 times







![RDF EXAMPLES
@prefix mt: <http://localhost:8080/medical_terminology.owl#> .
<http://example.com/patient#1234> rdf:type mt:Patient .
<http://example.com/patient#1234> mt:has_mass _:hm .
_:hm rdf:type mt:Measurement .
_:hm mt:has_value "92.0"^^xsd:float .
_:hm mt:has_units mt:kg .
@prefix mt: <http://localhost:8080/medical_terminology.owl#> .
<http://example.com/patient#1234> a mt:Person ;
mt:has_mass [a mt:Measurement;
mt:has_value "92.0"^^xsd:float;
mt:has_units mt:kg] .
The original XML-
based rendering
format is also
popular.](https://image.slidesharecdn.com/oslo2015technicalintroduction-150923172837-lva1-app6892/85/A-practical-introduction-to-SADI-semantic-Web-services-and-HYDRA-query-tool-9-320.jpg)




![SERVICE INPUT CLASS
• Specifies what kind of objects (RDF descriptions) the service
expects in the input. OWL syntax is convenient for such definitions.
• Almost always just an enumeration of attributes of the input objects
the SADI service expects.
● If the input class is defined as
Person and
(has_height exactly 1
(Measurement and
(has_value exactly 1 float) and
(has_units exactly 1 {m})) and
(has_mass exactly 1
(Measurement and
(has_value exactly 1 float) and
(has_units exactly 1 {kg}))
… the service expects something
like this in the input:
patient1234 a Person;
has_height [a Measurement;
has_value “1.7"^^xsd:float;
has_units m];
has_mass [a Measurement;
has_value “92.0"^^xsd:float;
has_units kg]](https://image.slidesharecdn.com/oslo2015technicalintroduction-150923172837-lva1-app6892/85/A-practical-introduction-to-SADI-semantic-Web-services-and-HYDRA-query-tool-15-320.jpg)

![DIGRESSION: SPARQL
• W3C SPARQL - standard query language for
the RDF data model.
• SPARQL clients are programs that execute
SPARQL queries, typically on RDF triplestores.
PREFIX mt: <http://localhost:8080/medical_terminology.owl#>
SELECT ?mass
{
<http://example.com/patient#1234> a mt:Person ;
mt:has_mass [a mt:Measurement;
mt:has_value ?mass;
mt:has_units mt:kg] . }
• HYDRA is also a
SPARQL client,
but for virtual
RDF DBs.](https://image.slidesharecdn.com/oslo2015technicalintroduction-150923172837-lva1-app6892/85/A-practical-introduction-to-SADI-semantic-Web-services-and-HYDRA-query-tool-17-320.jpg)









![PRACTICAL EXAMPLE (2)
● Model data semantically: find ontologies describing your
domains and decide how your data will be expressed in the
terms of these ontologies.
➢ Create ontology clinical_terms.owl in Protégé:
➢ Classes: Person, Patient, Measurement, Units
➢ Properties: has_BMI, has_MRN, has_height, has_mass,
has_value, has_units.
➢ Individuals: m, kg.
➢ RDF data sample:
patient1234 a Patient;
has_MRN “1234”^^xsd:string;
has_height [a Measurement;
has_value “1.7"^^xsd:float;
has_units m];
. . .](https://image.slidesharecdn.com/oslo2015technicalintroduction-150923172837-lva1-app6892/85/A-practical-introduction-to-SADI-semantic-Web-services-and-HYDRA-query-tool-27-320.jpg)


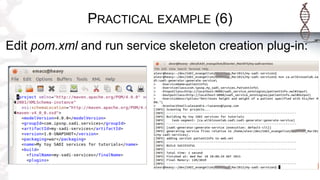
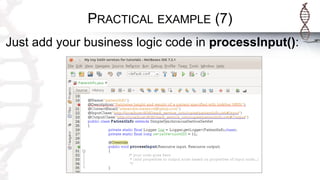
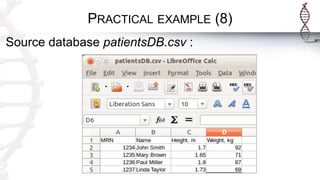



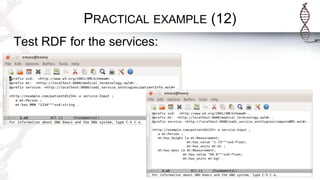

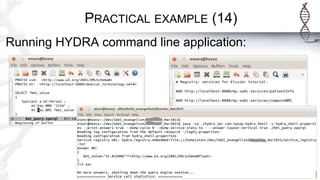



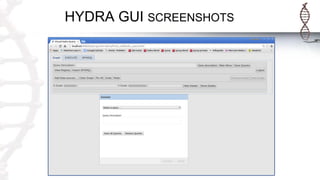
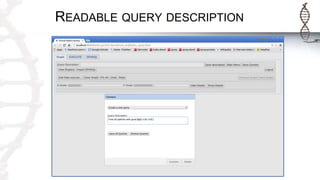

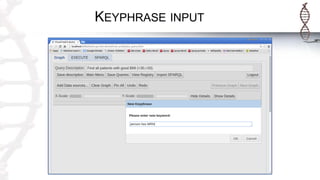
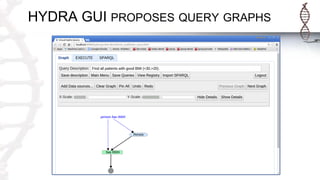
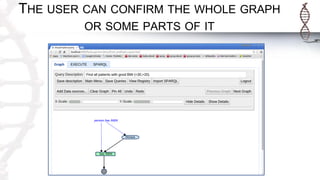
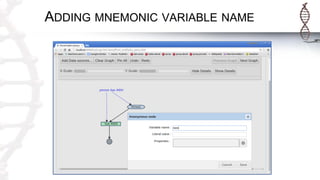

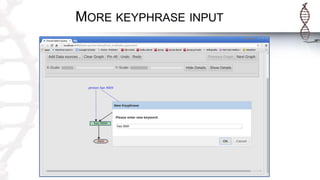
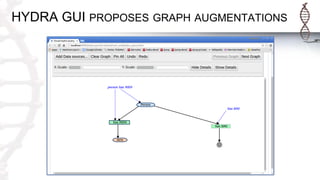

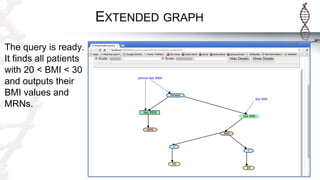
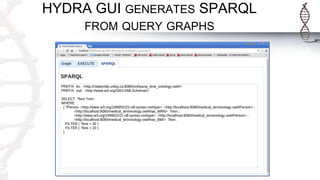
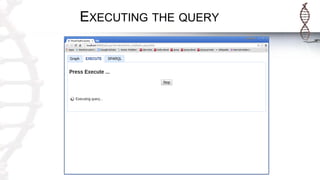
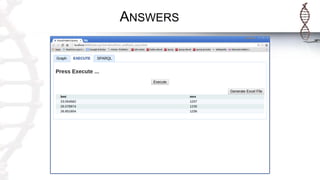


The document provides an introduction to SADI semantic web services and the Hydra query tool, detailing data federation, service publishing, and automatic service discovery using RDF and OWL. It includes examples of querying heterogeneous sources, the functionality of SADI services, and practical applications such as patient information retrieval and BMI computation. Furthermore, it discusses intelligent query execution and the potential for self-service querying through a user-friendly interface.



































































