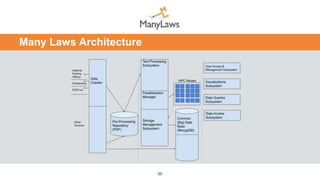
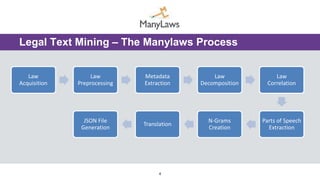
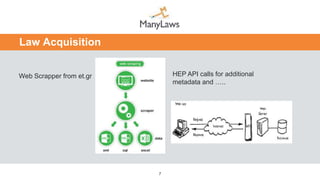
This document presents a novel method and architecture for legal text processing utilizing high performance computing, aimed at extracting and analyzing vast amounts of legal artifacts from various sources. It outlines the ManyLaws processing flow and architecture, detailing steps like law acquisition, preprocessing, metadata extraction, law decomposition, and correlation. The system is designed to handle an extensive database expected to grow significantly, enabling efficient legal text mining and analysis across multiple languages.










![Search Regexp
(e.g. ν. [0-9]{4}/[0-9]{4} )
Keep only
Law
Number
with
correlations
Generate
graphs with
Gephi
15
Law Correlation
Insert photo](https://image.slidesharecdn.com/manylawsanovelmethod-190701195512/85/A-Novel-Method-and-Architecture-for-Law-Processing-Utilising-High-Performance-Computing-Infrastructures-15-320.jpg)