Downloaded 11 times


















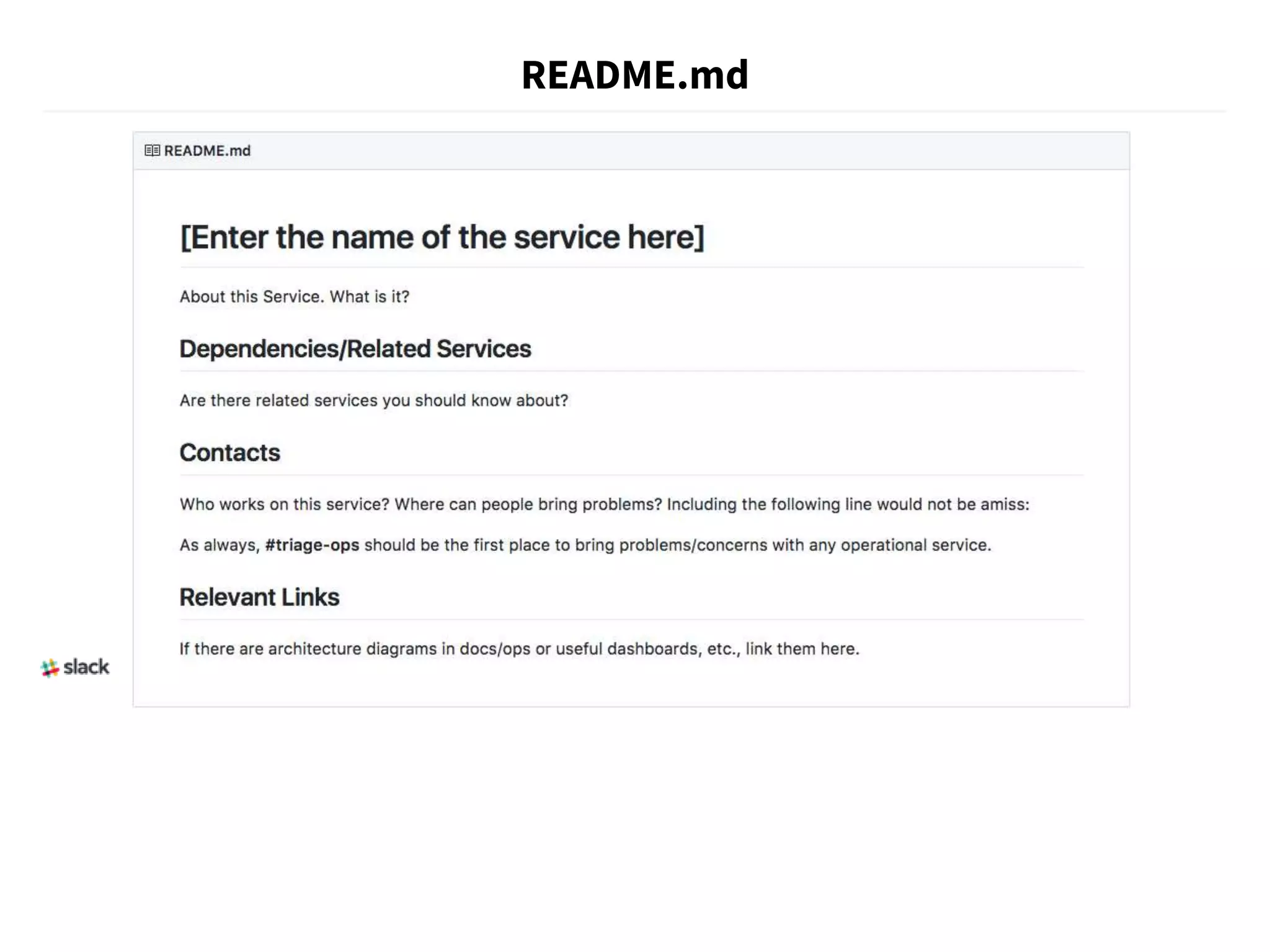
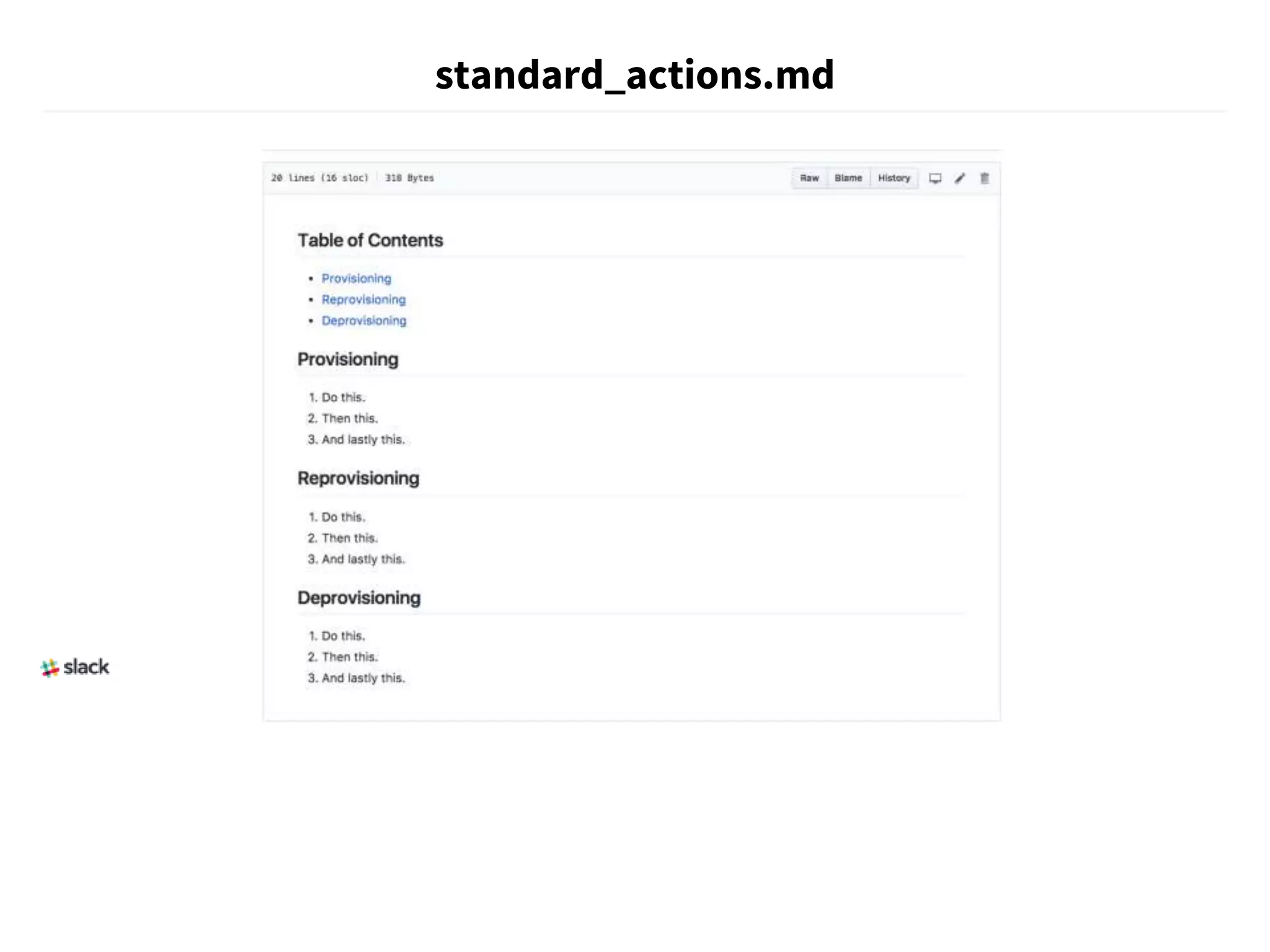
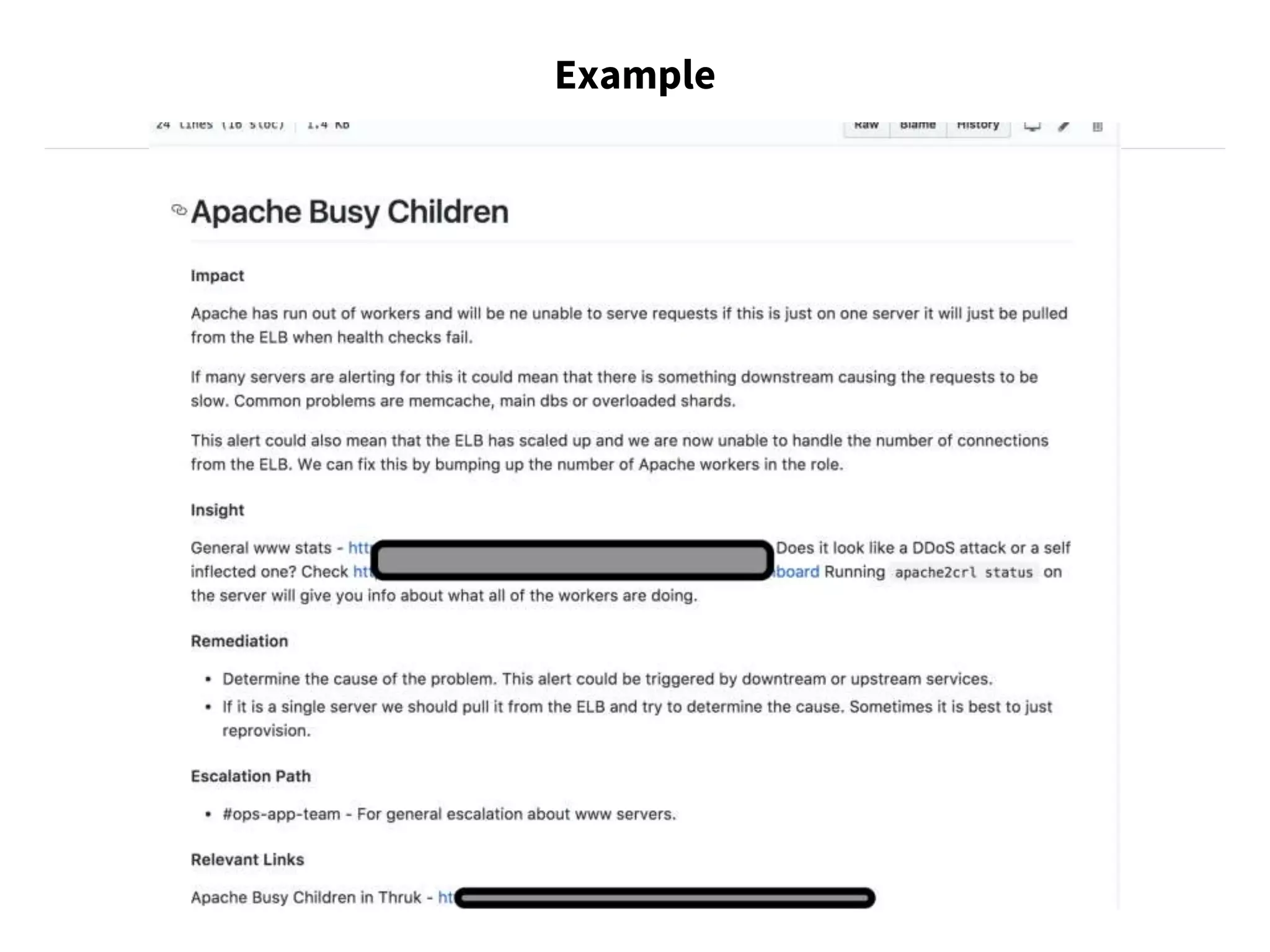













The document discusses strategies for running production services, including careful planning, extensive documentation, and good communication. It emphasizes establishing runbooks that document operational tasks and procedures. Over time, as teams grow and work expands, runbooks should be automated through scripts and tools to reduce manual effort and potential errors. Automating runbooks involves initially writing scripts for small tasks and evolving them through testing, bug fixing, and incorporating additional workflow steps. Fully automated runbooks improve reliability and allow work to be completed through execution of instructions rather than human judgement.























































































