Downloaded 572 times






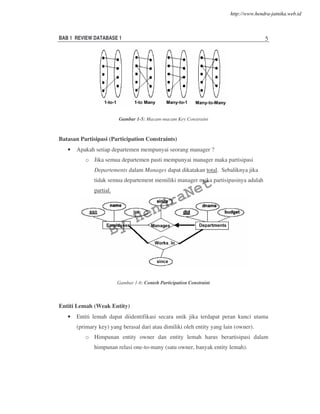






![BAB 1 REVIEW DATABASE 1 12
1.4. STRUCTURED QUERY LANGUAGE
Structured Query Language (SQL) adalah bahasa database relasional yang dibuat
berdasarkan suatu standart. Bentuk dasar dari SQL adalah sebagai berikut :
SELECT [DISTINCT] select-list
FROM from-list
WHERE qualification
Setiap query dalam SQL harus memiliki klausa SELECT, yang menentukan kolom yang
akan ditampilkan pada hasil, dan klausa FROM yang menentukan cross product table.
Klausa optional WHERE menentukan syarat-syarat seleksi pada table yang ditunjukkan
oleh FROM.
Berikut ini akan dibahas sintaksis query SQL dasar dengan lebih mendetail :
• from list pada klausa FROM adalah daftar nama table. Nama tabel dapat diikuti
oleh nama alias; nama alias berguna ketika nama tabel yang sama muncul lebih
dari sekali pada from list
• select-list adalah daftar nama kolom (termasuk ekspresinya) dari tabel-tabel
yang tercantum pada form list. Nama kolom dapat diawali dengan nama alias
dari tabel.
• Kualifikasi pada klausa WHERE merupakan kombinasi boolean atau
pernyataan kata sambung logika dari kondisi yang menggunakan eksepresi yang
melibatkan operator pembanding. Sedangkan ekspresi itu sendiri dapat berupa
nama kolom, konstanta atau aritmatika dan string.
• Kata kunci distinct bersifat pilihan yang menghapus duplikat dari hasil query.
SQL menyediakan tiga konstruksi set-manipulation yang memperluas query
dasar, yaitu UNION, INTERSECT dan EXCEPT. Juga operasi set yang lain seperti : IN
(untuk memeriksa apakah elemen telah berada pada set yang ditentukan), ANY dan
ALL (untuk membandingkan suatu nilaid engan elemen pada set tertentu), EXISTS
(untuk memeriksa apakah suatu set kosong atau isi). Operator IN dan EXISTS dapat
diawali dengan NOT.
Fitur SQL yang lain yaitu NESTED QUERY, artinya query yang memiliki query
lain di dalamnya, yang disebut dengan subquery. Nested query digunakan jika terdapat
suatu nilai yang tidak diketahui (unknown values).
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-13-320.jpg)

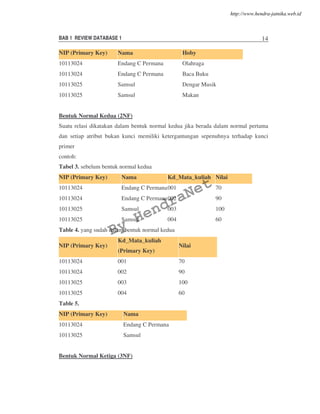

![BAB 1 REVIEW DATABASE 1 16
• Kelebihan dari model relasional adalah kesederhanaannya dalam melakukan query
atas data. Query dapat ditulis secara intuitif, dan DBMS bertanggungjawab untuk
mengevaluasinya secara efisien.
• Batasan Integritas adalah suatu kondisi yang harus bernilai benar untuk suatu
instance dalam basis data
• Structured Query Language (SQL) adalah bahasa database relasional yang dibuat
berdasarkan suatu standart, dan memiliki bentuk dasar :
SELECT [DISTINCT] select-list
FROM from-list
WHERE qualification
• Normalisasi adalah perbaikan skema database yang dibuat dengan tujuan untuk
menghindari penyimpanan informasi yang redundan.
LATIHAN SOAL :
1. Gambarlah sebuah diagram ER yang mengungkapkan informasi ini.
Perusahaan rekaman Notown memutuskan untuk menyimpan semua informasi
mengenai musisi yang mengerjakan albumnya (seperti halnya data perusahaan lain)
dalam sebuah database. Pihak perusahaan menyewa anda sebagai desainer database
(dengan biaya konsultasi sebesar $2.500 / hari).
• Tiap musisi yang melakukan rekaman di Notown mempunyai SSN, nama,
alamat dan nomer telpon. Para musisi yang dibayar lebih rendah akan
mendapatkan alamat yang sama dengan musisi lain, dan satu alamat mempunyai
satu nomer telpon.
• Tiap instrumen yang digunakan untuk merekam berbagai macam lagu di
Notown mempunyai nama (contoh : gitar, sinthesizer, flute) dan kunci musik
(contoh : C, B-flat, E-flat).
• Tiap album yang dicatata di Notown mempunyai judul rekaman, tanggal
copyright, format (contoh : CD atau MC) DAN SEBUAH INDENTIFIKASI
ALBUM.
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-17-320.jpg)
















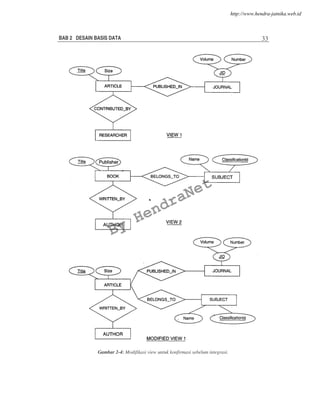































![BAB 5 DATABASE TRIGGER 65
Maka ilustrasi dari trigger timing untuk event tersebut adalah sebagai berikut :
5.5. DML STATEMENT TRIGGER
Berikut ini sintak atau cara penulisan untuk pembuatan DML Statement trigger :
CREATE [OR REPLACE] TRIGGER trigger_name
timing
event1 [OR event2 OR event3]
ON table_name
trigger_body
Berikut contoh pembuatan DML Statement trigger :
CREATE OR REPLACE TRIGGER secure_emp
BEFORE INSERT ON employees
BEGIN
IF (TO_CHAR(SYSDATE,'DY') IN ('SAT','SUN')) OR
(TO_CHAR(SYSDATE,'HH24:MI') NOT BETWEEN '08:00' AND '18:00')
THEN RAISE_APPLICATION_ERROR (-20500,'Penyisipan data pada table
EMPLOYEES hanya diperbolehkan selama jam kerja');
END IF;
END;
/
Contoh trigger diatas akan membatasi penyisipan baris baru ke dalam table
EMPOYEES diperbolehkan hanya pada jam kerja mulai hari Senin sampai Jum’at. Jika
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-66-320.jpg)

![BAB 5 DATABASE TRIGGER 67
RAISE_APPLICATION_ERROR (-20503,'You may update
SALARY only during business hours.');
ELSE
RAISE_APPLICATION_ERROR (-20504,'You may update
EMPLOYEES table only during normal hours.');
END IF;
END IF;
END;
5.7. ROW TRIGGER
Berikut ini sintak atau cara penulisan untuk membuat Row Trigger :
CREATE [OR REPLACE] TRIGGER trigger_name
timing
event1 [OR event2 OR event3]
ON table_name
[REFERENCING OLD AS old | NEW AS new]
FOR EACH ROW
[WHEN (condition)]
trigger_body
Contoh berikut ini akan dibuat row trigger dengan timing BEFORE untuk
membatasi operasi DML pada table EMPLOYEES hanya diperbolehkan untuk pegawai
yang memiliki kode pekerjaan ‘AD_PRES’ dan ‘AD_VP’ serta memiliki gaji kurang
dari 15000.
CREATE OR REPLACE TRIGGER restrict_salary
BEFORE INSERT OR UPDATE OF salary ON employees
FOR EACH ROW
BEGIN
IF NOT (:NEW.job_id IN ('AD_PRES', 'AD_VP'))
AND :NEW.salary > 15000
THEN
RAISE_APPLICATION_ERROR (-20202,'Employee
cannot earn this amount');
END IF;
END;
/
Jika kita mencoba memberikan perintah SQL sebagai berikut, maka akan ditampilkan
pesan kesalahan :
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-68-320.jpg)
































![BAB 8 BASIS DATA INTERNET 100
1.7 SPESIFIKASI DOMAIN PADA DTDs
Untuk menangani sumber-sumber data yang berlainan, dikembangkan
standarisasi DTDs untuk memungkinkan domain dapat menukar data diantara sumber-
sumber yang heterogen. Contohnya adalah domain pada DTDs untuk mengkodekan
material matematika pada web dengan menggunakan Mathematical Markup Language
(MathML). Perbedaan HTML dengan MathML dapat dilihat pada persamaan
matematika di bawah ini ;
• Dalam HTML : <IMG SRC=“xysq.gif” ALT=“(x+y)^2”>
• Dalam MathML :
<apply> <power/>
<apply> <plus/> <ci>x</ci> <ci>y</ci> </apply>
<cn>2</cn>
</apply>
<!DOCTYPE BOOKLIST [
<!ELEMENT BOOKLIST (BOOK)*>
<!ELEMENT BOOK (AUTHOR, TITLE, PUBLISHED?)>
<!ELEMENT AUTHOR (FIRST, LAST)>
<!ELEMENT FIRST (#PCDATA)>
<!ELEMENT LAST (#PCDATA)>
<!ELEMENT TITLE (#PCDATA)>
<!ELEMENT PUBLISHED (#PCDATA)>
<!ATTLIST BOOK genre (Science|Fiction) #REQUIRED>
<!ATTLIST BOOK format (Paperback|Hardcover) “Paperback”>
]>
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-101-320.jpg)














![BAB 10 DATA MINING 115
Aplikasi basis data telah banyak diterapkan dalam berbagai antara lain bidang
manajemen, manajemen data untuk industri, ilmu pegetahuan, administrasi pemerintah
dan bidang-bidang lainnya. Akibatnya data yang dihasilkan oleh bidang-bidang tersebut
sangatlah besar dan berkembang dengan cepat. Hal ini menyebabkan timbulnya
kebutuhan terhadap teknik-teknik yang dapat melakukan pengolahan data sehingga dari
data-data yang ada dapat diperoleh informasi penting yang dapat digunakan untuk
perkembangan masing-masing bidang tersebut.
Istilah data mining sudah berkembang jauh dalam mengadaptasi setiap bentuk
analisa data. Pada dasarnya data mining berhubungan dengan analisa data dan
penggunaan teknik-teknik perangkat lunak untuk mencari pola dan keteraturan dalam
himpunan data yang sifatnya tersembunyi.
Data mining diartikan sebagai suatu proses ekstraksi informasi berguna dan
potensial dari sekumpulan data yang terdapat secara implisit dalam suatu basis data.
Banyak istilah lain dari data mining yang dikenal luas seperti knowledge mining from
databases, knowledge extraction, data archeology, data dredging, data analysis dan lain
sebagainya [AGR-93].
Dengan diperolehnya informasi-informasi yang berguna dari data-data yang
ada, hubungan antara item dalam transaksi, maupun informasi informasi-yang potensial,
selanjutnya dapat diekstrak dan dianalisa dan diteliti lebih lanjut dari berbagai sudut
pandang.
Informasi yang ditemukan ini selanjutnya dapat diaplikasi kan untuk aplikasi
manajemen, melakukan query processing, peng ambilan keputusan dan lain sebagainya.
Dengan semakin ber kembang nya kebutuhan akan informasi-informasi, semakin
banyak pula bidang-bidang yang rnenerapkan konsep data mining.
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-116-320.jpg)










![BAB 10 DATA MINING 126
akhir-akhir ini dikembangkan. Klasifikasi skema yang berbeda dapat digunakan untuk
mengkategorikan metode dan sistem data mining dengan didasarkan pada jenis basis
data yang akan dipelajari, dan teknik apa yang akan digunakan.
• Jenis Basis Data yang akan dijadikan obyek.
Suatu sistem data mining dapat diklasifikasikan menurut jenis basis data
dimana proses data mining tersebut dilakukan. Sebagai contoh, sebuah sistern
adalah relationar data miner jika sistem tersebut menemukan informasi dad basis
data relasional, atau suatu object oriented data miner bila informasi diperoleh dari
basis data yang berorientasi pada obyek. Secara umum, data miner dapat
digolongkan menurut jenis basis data apa yang diolahnya seperti misalnya basis
data relasional, basis data transaksi, basis data yang berorientasi obyek, basis data
deduktif, basis data spasial, basis data multimedia, basis-data-heterogen, dan lain
sebagainya.
• Jenis informasi yang hendak dicari
Beberapa jenis informasi dapat dihasilkan dad proses data mining ini, termasuk
association rules, characteristic rules, classification rules, discriminant rules,
clustering, sequential pattern, dan deviation analysis [AGR-93]. Lebih lanjut, ada
kiasifikasi lainnya menurut level abstraksi dari informasi yang diperoleh, antara lain
generalized knowledge, primitive level knowledge dan multiple level knowledge. Suatu
sistem data mining yang fleksibel dapat menggali informasi pada berbagai level
abstraksi.
• Teknik yang hendak digunakan.
Cara kiasifikasi yang lainnya adalah berdasarkan teknik yang digunakan.
Misalnya, dikategorikan berdasarkan metode kendalinya seperti autonomous knowledge
miner, data driven miner, query driven miner dan interactive data miner. Dapat juga
dikategorikan berdasarkan pendekatan yang dipakai dalam melakukan data mining,
yaitu generalization based mining, statistics and mathematical based mining, integrated
approach mining dan lain sebagainya.Diantara berbagai macam klasifikasi yang ada,
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-127-320.jpg)

![BAB 10 DATA MINING 128
mengunjungi halaman C juga pada session yang sama, sehingga halaman C perlu diberi
direct link dari A atau B. Informasi ini dapat digunakan untuk membuat link secara
dinamik ke halaman C dari halaman A atau B sehingga user dapat melakukan direct link
ke halaman C. Informasi semacam ini digunakan untuk melakukan link ke halaman
produk yang berbeda secara dinamik berdasarkan interaksi customer.
Apa Itu Kaidah Asosiasi?
• Kaidah asosiasi penambangan
– Pertama kali diusulkan oleh Agrawal, Imielinski dan Swami [AIS93]
• Diberikan:
– Suatu database transaksi
– Setiap transaksi adalah suatu himpunan item-item
• Cari seluruh kaidah asosiasi yang memenuhi kendala minimum support dan
minimum confidence yang diberikan user.
• Contoh:
30% dari transaksi yang memuat bir juga memuat popok 5% dari transaksi
memuat item-item berikut:
– 30% : confidence dari kaidah ini
– 5% : support dari kaidah ini
• Kita berminat untuk mencari seluruh kaidah ketimbang memeriksa apakah suatu
kaidah berlaku.
Definisi Umum
• Itemset: himpunan dari item-item yang muncul bersama-sama
• Kaidah asosiasi: peluang bahwa item-item tertentu hadir bersama-sama.
oX → Y dimana X n Y = 0
• Support, supp(X) dari suatu itemset X adalah rasio dari jumlah transaksi
dimana suatu itemset muncul dengan total jumlah transaksi.
• Konfidence (keyakinan) dari kaidah X . Y, ditulis conf(X . Y) adalah
– conf(X → Y)=supp(X ∪ Y) / supp(X)
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-129-320.jpg)



![BAB 10 DATA MINING 132
• Bisakah kita membuat hipotesa?
– Chips => Salsa Lettuce => Spinach
Dasar Kaidah Asosiasi:
• Kaidah asosiasi penambangan:
– Mencari pola yang sering muncul, asosiasi, korelasi, atau struktur sebab
musabab diantara himpunan item-item atau objek-objek dalam database
transaksi, database relasional, dan penyimpanan informasi lainnya
• Kepemahaman:
– Sederhana untuk dipahami
• Kegunaan:
– menyediakan informasi yang bias ditindaklanjuti
• Efisiensi:
– ada algoritma pencarian yang efisient
• Aplikasi:
– Analisis data keranjang pasar, pemasaran silang, rancangan katalog,
analisis lossleader, clustering, klasifikasi, dsb.
• Format penyajian kaidah asosiasi yang biasa:
– popok . bir [0.5%, 60%]
– beli:popok . beli:bir [0.5%, 60%]
– "IF membeli popok, THEN membeli bir dalam 60% kasus. Popok dan
bir dibeli bersama-sama dalam 0.5% dari baris-baris dalam database."
• Penyajian lainnya (digunakan dalam buku Han):
– Beli ( x, “popok” ) beli ( x, “bir” ) [ 0.5%, 60% ]
– Major ( x, "CS" ) ^ mengambil ( x, "DB" ) grade( x,"A" ) [ 1%, 75% ]
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-133-320.jpg)



![BAB 10 DATA MINING 136
Ada beberapa cara untuk mengatasi problem dalam algoritma apriori ini berikut,
Perbaikan Kinerja Apriori :
1. Hitungan itemset berbasis hash:
Suatu k-itemset yang hitungan ember hash terkaitnya dibawah ambang tidak bisa
frequent.
2. Reduksi transaksi:
Suatu transaksi yang tidak memuat frequent k itemset apapun adalah sia-sia
dalam scan berikutnya.
3. Partisi:
Itemset apapun yang potensial frequent dalam DB haruslah frequent dalam
paling tidak satu dari partisi dari DB
4. Sampling:
Penambangan atas suatu subset dari data yang diberikan, menurunkan ambang
support suatu metoda untuk menentukan kelengkapan.
Diberikan: (1) database transaksi, (2) setiap adalah suatu daftar dari item-item
yang dibeli (dibeli seorang customer pada suatu kunjungan)
cari: seluruh kaidah dengan minimum support dan confidence
If min. support 50% dan min. confidence 50%, then A => C [50%, 66.6%], C =>
A [50%, 100%].
Langkah-langkah untuk mencari nilai minimum support dam confidence dengan
algoritma apriori
STEP 1: cari frequent itemsets: himpunan item-item yang memiliki
minimum support.
• Disebut trik Apriori: suatu subset tak hampa dari suatu frequent itemset
haruslah juga suatu frequent itemset:
- Artinya, jika {AB} adalah suatu frequent itemset, kedua {A} dan {B}
harus juga frequent itemsets.
By
HendraNet
http://www.hendra-jatnika.web.id](https://image.slidesharecdn.com/7basisdatalanjutmodul-140531181645-phpapp02/85/basis-data-lanjut-modul-137-320.jpg)






Dokumen ini membahas mata kuliah basis data lanjut di Politeknik Piksi Ganesha, mencakup materi seperti ER-model, normalisasi, SQL, dan optimasi query. Tujuan pengajaran adalah untuk memahami sistem manajemen basis data dan cara desain, pemeliharaan, serta pengambilan informasi dari database. Pembahasan juga termasuk model relasional dan batasan integritas dalam relasi, serta penggunaan SQL dalam pengelolaan data.









![T3 – Query Lanjutan [1]](https://cdn.slidesharecdn.com/ss_thumbnails/t3querylanjutan1-151216123247-thumbnail.jpg?width=640&height=640&fit=bounds)




































































