Download as PDF, PPTX





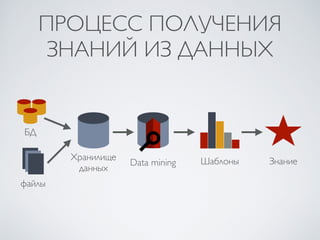






![ПРИМЕР: АНАЛИЗ АССОЦИАЦИЙ
• Менеджер рассматривает такую задачу: Найти товары,
которые часто покупаются вместе.
• Результат:
покупка(X, “компьютер”) => покупка(X, “ПО”)
[supp = 1%, conf = 50%]
т.е. 1% всех покупок включает компьютер и ПО вместе, в
50% случаев при покупке компьютера покупается и ПО.
• supp(A) - относительное количество случаев, когда
правило A выполняется (support)
• conf(A=>B) - относительное количество случаев, когда
выполняется B после A (confidence). conf(A=>B) = p(B|A)](https://image.slidesharecdn.com/1-140831143635-phpapp02/85/Data-Mining-lecture-1-2014-12-320.jpg)

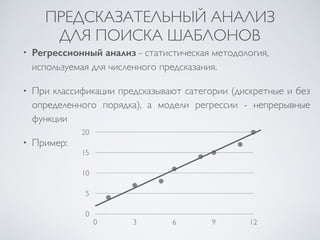
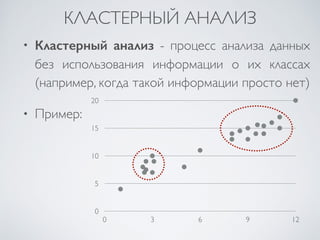
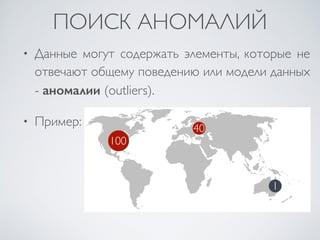

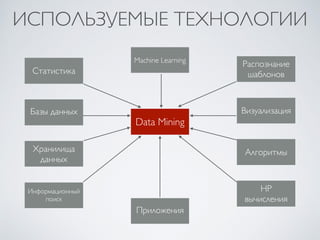








Документ представляет курс по интеллектуальному анализу данных (data mining), разработанный для студентов факультета компьютерных наук Харьковского национального университета имени В. Н. Каразина. В нем рассматриваются ключевые аспекты data mining, включая методы предсказательной аналитики, классификации, кластеризации и поиска шаблонов в данных, а также методологии и технологии, связанные с машинным обучением и статистикой. Основное внимание уделяется необходимым этапам обработки данных и взаимодействию с пользователем для достижения эффективных результатов.













































































